Are you tired of manually extracting data and information from CVs, resumes, and academic documents? Look no further! Our GitHub repo can automatically extract unstructured data and information from these documents, saving you time and effort.
Whether you are a recruiter, HR manager, or academic institution, our software can help you streamline your hiring or admissions process by quickly and accurately extracting the information you need.
Don't waste any more time sifting through stacks of resumes or academic transcripts. Try our GitHub today and experience the benefits of automated data extraction.
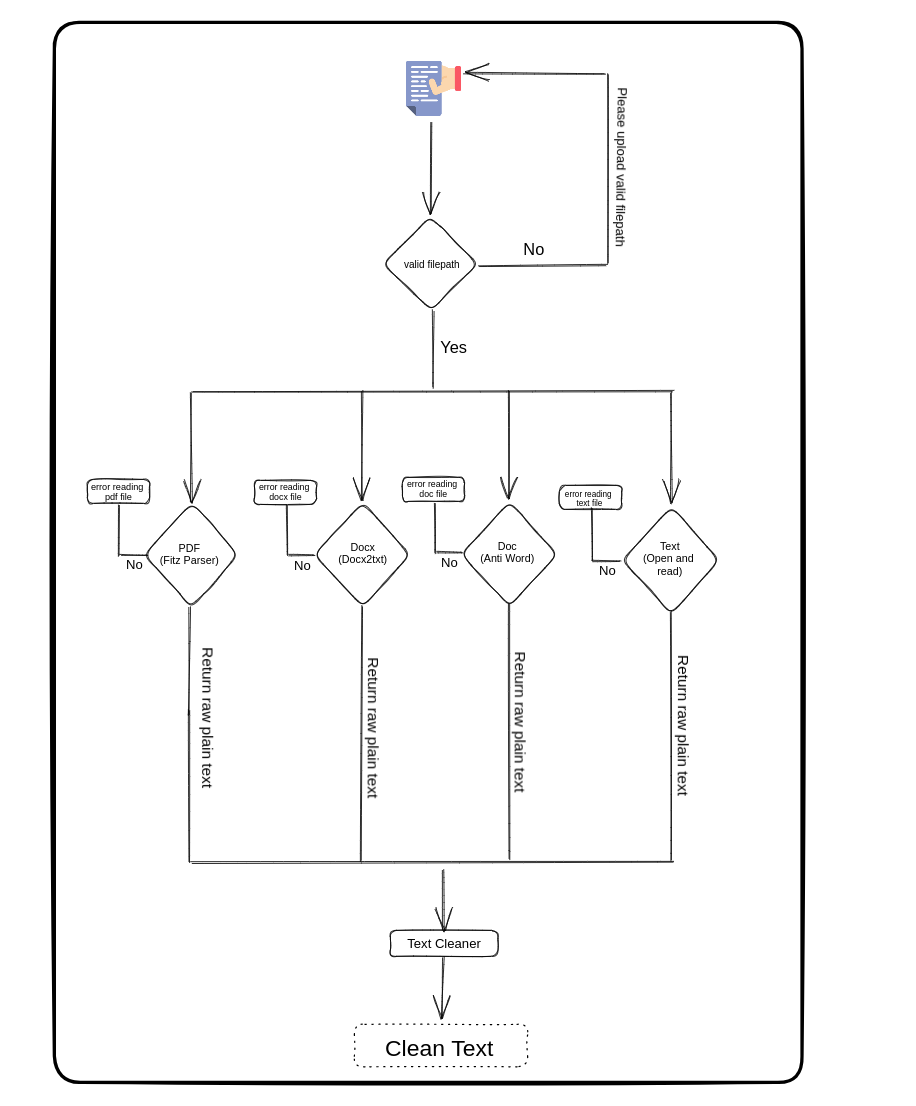
To use this repo, follow these steps:
- Clone the repo on your local machine.
- Upload the document(s) you wish to extract data from.
- Run the program and wait for it to complete the data extraction process.
- Review the extracted data and information, which will be presented in a structured format.
- Clone this repository on your local machine:
https://github.com/AI-KB/text_parsing.github.io.git
- Create a virtual environment
python -m venv venv
source venv/bin/activate # On Linux/Mac
venv\Scripts\activate # On Windows
- Install the required dependencies:
pip install -r requirements.txt
- Run the program
python paper_parser.py
Replace /path/to/your/document in paper_parser.py file with the path to the document you want to extract data from
- View the extracted data
The program will return a Python generator containing the extracted data. You can iterate over the generator to access the individual data items. Here's an example:
final_result = {}
location = ["data/paper.doc", "data/paper.pdf"]
for file_key, file_value in read(location, True):
final_result[file_key] = file_value
print(final_result)
-
Add or remove fields to extract: Depending on your specific use case, you may want to extract additional fields or remove some of the existing ones. You can modify the code in paper_parser.py file to do this.
-
Change the output format: By default, the paper parser outputs the extracted data in a dictionary format. However, you can modify the code to output the data in a different format that is more suitable for your use case. For example, you could output the data as a CSV file, or write it to a database.
-
Customize the pre-processing steps: The paper parser uses pre-processing techniques such as tokenization and stemming to extract the data. Depending on your specific use case, you may want to modify these pre-processing steps to better suit your needs. You can modify the code in
clean_textmethod inpaper_parser.pyfile to do this. -
Use different document formats: The paper parser currently supports extracting data from Microsoft Word documents and PDFs. However, you may want to extract data from other document formats, such as HTML or plain text. You can modify the code in paper_parser.py file to add support for additional document formats.
Note: To make these customizations, you will need to have some knowledge of Python programming and regular expressions. It is also recommended that you test your modifications thoroughly before using the paper parser in a production environment.
- Please open a PR for updating each parser engine (docx to text, doc to text, pdf to text, and text to text)