#include <cmath>
int x = 10;
sqrt(x); //x의 제곱근
pow(x, 2); // x의 n제곱
for(int i=2; i<sqrt(x); i++) {
if(x % i == 0) {
sosu = false;
}
}어떤 수가 소수인지 확인 하는 알고리즘
어떤 x가 소수인지 확인할 때는 2부터 x의 제곱근 까지만 나누어 보는 것으로 확인할 수 있다.
int check[1000000] = { 1, 1, 0 };
for(int i=2; i<= sqrt(n); i++) {
if(check[i] == 0) {
for(int j= i + i; j <= n; j += i) {
check[j] = 1;
}
}
}n이 주어졌을 때, 1 부터 n 까지의 모든 소수를 구하는 방법
2 부터 n의 제곱근까지 검사하여 소수들의 배수를 지워 나간다.
int check[1000000000] = { 1, 1, 0 };
for(int i=2; i<= sqrt(n); i++) {
if(check[i] == 0) {
for(int j= i + i; j <= n; j += i) {
check[j] = 1;
}
}
}
for(int i=2; i<1000000000; i++) {
if(!check[i]) v.push_back(i);
}
for(int i = 0; i < v.size(); i++) {
if(target % v[i] == 0) break;
}이 방법은 배열의 최대 크기보다 훨씬 큰 수를 소수 판별할때 사용한다.
먼저 에라토스테네스의 체를 이용하여 check배열을 초기화한다.
최대한 소수를 벡터에 담고, 구하려는 수를 소수들로 나누어주며 나누어진다면 소수가 아니다. 소수가 아닌 수들은 소수를 약수로 갖기 때문이다.
int get_gcd(int a, int b){
if(a<b){
int temp = a;
a = b;
b = temp;
}
while(b!=0){
int n = a%b;
a = b;
b = n;
}
return a;
}두 수의 최대공약수와 최소공배수를 구하는 알고리즘
for(int i=1; i<=n; i++) {
if(i + x > n) break;
sum = sum - visitors[i] + visitors[i + x];
}배열에서 연속된 구간의 연속된 합을 구하는 문제이다.
새로운 값을 구할떄는 이전 합에서 제일 첫번째 값을 빼고 그 다음 값만 더해주면 단 두번의 연산으로 구간 합을 계속 업데이트해 나갈 수 있다.
vector<int> graph[1001];
bool visited[1001] = { false };
void dfs(int now) {
cout << now << " ";
for(int i=0; i<graph[now].size(); i++) {
int next = graph[now][i];
if(visited[next] == false) {
visited[next] = true;
dfs(next);
}
}
}void findCycle(int now) {
int next = graph[now];
if(visited[next] == false) {
visited[next] = true;
findCycle(next);
} else if(done[next] == false) {
for(int i = next; i != now; i = graph[i]) {
cnt++;
}
cnt++;
}
done[now] = true;
}cycle을 찾을떄는 dfs를 사용한다. visited로 방문여부를 체크하면서 넘어가는건 dfs와 같지만,
더이상 이 노드를 방문하지 않을 것이란 걸 done배열로 관리한다.
방문을 했지만, done이 false인 경우는 cycle이 생성되었다는 것과 같다.
5 → 6 → 7 → 5 에서 7이 다시 5를 방문했을 때는 visited는 true지만 done은 false이므로 cycle이다.
4 → 5 → 6 → 3 에서 3에서 끝나기 때문에 모두 done과 visited가 true가 되면서 dfs를 빠져나오고, 4, 5, 6, 3은 다시 확인하기 않아도 된다.
이렇게 하면 노드별로 한번씩만 방문하는 O(N)시간안에 해결할 수 있다.
vector<int> graph[1001];
bool visited[1001] = { false };
int main() {
int n,m,v;
cin >> n >> m >> v;
for(int i=0; i<m; i++) {
int a,b;
cin >> a >> b;
graph[a].push_back(b);
graph[b].push_back(a);
}
for(int i=0; i<n+1; i++) {
sort(graph[i].begin(), graph[i].end());
}
queue<int> q;
q.push(v);
visited[v] = true;
while(!q.empty()) {
int now = q.front();
cout << now << " ";
q.pop();
for(int i=0; i<graph[now].size(); i++) {
int next = graph[now][i];
if(visited[next] == false) {
q.push(next);
visited[next] = true;
}
}
}
}while(!q.empty()) {
int x = q.front().first;
int y = q.front().second;
q.pop();
for(int i=0; i<4; i++) {
int nx = x + dx[i];
int ny = y + dy[i];
if(nx >= 0 && ny >= 0 && nx < n && ny < m && miro[nx][ny] == 1) {
if(visited[nx][ny] == false) {
visited[nx][ny] = true;
distance[nx][ny] = distance[x][y] + 1;
q.push({ nx, ny });
}
}
}
}보통 최단경로에는 dfs보단 bfs를 사용한다.
dfs로 하면 재귀함수의 호출이 너무 많아지기 때문이다.
DFS는 해가 하나인 경우에 유리합니다. 즉, 목표 노드가 하나인 경우에는 DFS를 사용하여 해를 찾을 수 있습니다. DFS는 목표 노드를 찾으면 탐색을 종료하기 때문에, 해가 하나인 경우에는 BFS보다 효율적입니다.
이전 경로까지의 거리를 +1 해나가며, 다음 경로까지의 거리를 계산해나간다.
- 노드와 간선이 주어지지 않는다면? 백준 9205 - 맥주 마시면서 걸어가기
void backTracking(int depth) {
if(depth == n) { // 범위의 끝에 다달았을때 return
return;
}
for(int i=0; i<graph[now].size(); i++) {
int next = graph[now][i];
if(visited[next] == false) {
visited[next] = true;
backTracking(next);
visited[next] = false;
}
}
}dsf와 똑같이 규칙이 존재하지 않아 모든 경우를 따져야할때 backtracking을 사용한다.
backtracking과 dfs가 다른점은 dfs는 한번 간곳은 visited를 true로 두어서 다신 방문하지 않지만,
백트래킹의 경우 조건에 맞지 않다면 다시 false로 바꾸어 주어서 재방문 한다는 점이다.
백트래킹의 경우 memozation기법을 항상 염두하자. 깊이와 값이 같다면 재방문 하지 않아도 된다.
dp와 백트래킹은 재방문 여부에 따라 한끗 차이인 것이다.
#include <algorithm>
vector<int> perm(n);
for(int i = 1; i <= n; i++)
perm.push_back(i);
do {
for(int i = 0; i < perm.size(); i++){
cout << perm[i] << " ";
}
cout << "\n";
} while(next_permutation(perm.begin(), perm.end()));backtracking을 사용해야하지만, vector와 algorithm의 next_permutation으로 구현할 수 있다.
#include <algorithm>
vector<int> perm(n), comb(n);
for(int i = 1; i <= n; i++)
comb.push_back(i);
for(int i = 0; i <= k; i++)
perm.push_back(1);
do {
for(int i = 0; i < perm.size(); i++){
if (perm[i] == 1) {
cout << comb[i] << " ";
}
}
cout << "\n";
} while(next_permutation(perm.begin(), perm.end()));위의 순열을 구하는 방식으로 k개의 1, n개의 0을 순열을 구해서 1인 것만을 출력하면, 조합이 된다.
dynamic programming의 기본원리는 한 번 계산한 값은 다시 계산하지 않는다에 있다 기억하자.
dp문제 풀이에서 보았는데 문제를 보았을때 바로 풀이 방법이 생각나지 않는다면 dp를 의심하라고 하였다.
dp를 의심하고 문제를 작은 문제로 쪼개어 생각하자. 그렇다면 해답이 나올 것이다.
int dp[100] = { 0,};
int fibonacci(int n) {
if (n <= 1) {
return n;
} else {
if (dp[n] > 0) {
return dp[n];
}
dp[n] = fibonacci(n-1) + fibonacci(n-2);
return dp[n];
}
}fibonacci(10)을 구하려면 fibonacci(10)을 fibonacci(9), fibonacci(8)로 나누고 1이 될때까지 이를 계속 나누어 fibonacci(10)을 구하여 dp배열에 저장한다음, 다음 재귀함수에서 fibonacci(10)이 나왔을때, 바로 꺼내어 return해주는 방식이다.
top-down방식은 끝까지 결과를 내어야 답을 도출 할 수 있을때 사용한다. 이 방식은 완전탐색과 거의 유사한 방식이 되는데, depth를 지정해주고 3차원 dp를 사용하여 이미 지나간 값에 대한 중복처리를 하여 시간을 줄인다.
Dynamic Programming 기본 코드 (top-down 방식) int dp[100] = { 0,};
int fibonacci(int n) {
dp[0] = 0;
dp[1] = 1;
int i;
for (i=2; i<=n; i++) {
dp[i] = dp[i-1] + dp[i-2];
}
return dp[n];
}dp[0]과 dp[1]을 이용해 dp[2]를 구하고 dp[1]과 dp[2]를 이용해 dp[3]을 구하면서 원하는 수까지 다다르는 bottom-up방식이다.
이렇게 풀면 연산 수도 줄어들면서, 재귀함수로 인한 overhead가 없기 떄문에 효율적이다. dp문제는 되도록 bottom-up방식으로 풀도록 하자.
for(int i = 3; i<=n; i++) {
dp[i] = max({ dp[i-1], dp[i-3] + arr[i-1] + arr[i], dp[i-2] + arr[i] });
}대표 적인 문제는 3개의 계단은 연속해서 오를 수 없고, n번째 계단에서의 최댓값을 구하는 문제인데
처음엔 점화식을 도출하는게 너무 어려웠다.
절대 3계단을 동시에 오르지 않게 경우의 수를 따져 점화식을 세워 주면 된다.
만약 현재 계단을 오르지 않았다면 dp[현재] = dp[현재 - 1]
만약 현재 계단을 올랐다면 dp[현재] = dp[현재 - 2] + arr[현재]
이렇게 두개를 선택하면 절대 3계단을 오르는 경우가 나오지 않는다.
그런데 이 경우엔 이전계단와 지금계단을 같이 오르는 경우가 포함되어 있지않다.
그럼데 이전계단과 지금계단을 같이오르려면 이전전계단을 오를 수 없으므로
**dp[현재] = dp[현재-3] + arr[현재-1] + arr[현재]**가 되고
dp[현재]는 위 세가지 값 중, 가장 큰 값을 선택해 주면 된다.
for(int i=1; i<n; i++) {
dp[i] = max(dp[i-1] + arr[i], arr[i]);
if(ans < dp[i]) ans = dp[i];
}줄지어진 숫자들이 있을때, 가장 합이 긴 연속된 구간의 합을 구하는 문제이다.
이전의 dp값과 현재 값을 비교하여, 현재 값이 더 크다면 과감히 이전 값들은 다 버린다.
여기서 dp는 지금까지의 가장 큰 값이 아니다. 정답은 ans에 저장되어있다.
10 10 -1 -2 -3 이렇게 나올경우, dp[4]는 14이지만 정답은 20이기 때문이다.
이 유형은 충분히 응용되어 나올 수 있으니, 방식을 이해하고 외워두자.
int dp[100][100] = { 0, }
int coin[100] = { 1, 2, 5 }
int target = 10;
for(int i=0; i<n; i++) {
for(int j=coin[i]; j<target; j++) {
dp[i][j] = dp[i-1][j] + dp[i][j-coin[i]]
}
}
정해진 동전들의 조합으로 특정 가격을 만드는 경우의 수를 찾는 문제이다.
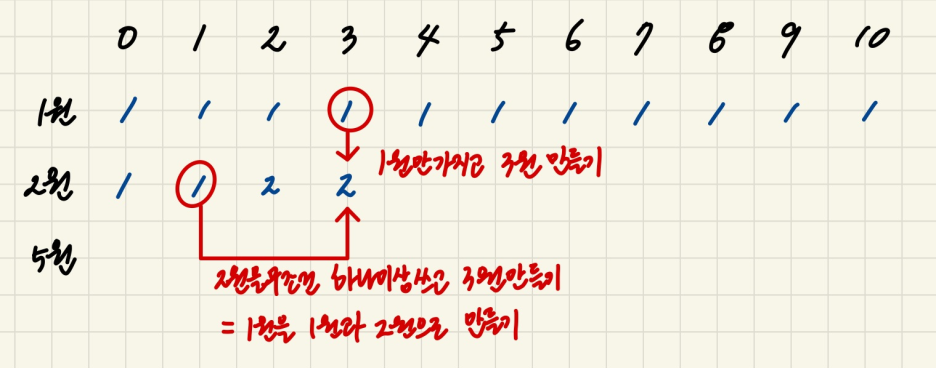
예를들어 1원, 2원, 5원의 동전을 조합하여 10원을 만드는 경우의 수를 생각해보자.
1열은 1원으로만 1원, 2원, 3원… 10원을 만드는 경우의 수 이고,
2열은 1원과 2원으로 1원, 2원 … 10원을 만드는 경우의 수,
3열은 1원 2원 5원을 모두 조합하여 1원, 2원.. 10원을 만드는 경우의 수이다.
그럼 dp[2][4]는 1원과 2원을 가지고 4원을 만드는 경우의 수 라고 해석할 수 있겠다.
그럼이건 dp[1][4] ( 1원만 가지고 4원을 만들기 ) + dp[2][4-2] ( 2원을 하나 무조건 사용하고 나머지 2원 만들기 )의 경우로 나눌 수 있고
최종 점화식은 **dp[i][j] = dp[i-1][j] + dp[i][j-coin[i]]**로 구할 수 있다.
1차원 dp만 사용하려면 **dp[i] += dp[i][j-coin[i]]**로 작성할 수 있다.
for(int i=1; i<=n; i++) {
int wei = v[i-1].first;
int val = v[i-1].second;
for(int j=1; j<=k; j++) {
if( j >= wei ) {
dp[i][j] = max(dp[i-1][j-wei] + val, dp[i-1][j]);
} else {
dp[i][j] = dp[i-1][j];
}
}
}특정 무게, 특정가치의 물건들을 넣어서 정해진 무게의 배낭에 가장 비싼가치를 담는 문제이다.
위의 동전문제와는 조금 다르다. 우선 동전은 정해진 가격을 맞춰야 하지만, 베낭은 꼭 최대무게를 맞추지 않아도 된다. 그리고 동전문제는 경우의수를 구하는 문제이고, 배낭문제는 최대값을 구하는 문제이다.

동그라미 친 부분을 설명하자면, 3kg/6원짜리를 사용하지않고 7kg를 만드는 방법과 3kg/6원짜리를 사용하고 7kg를 만드는 방법 중 큰 값을 택하는 그림이다.
그럼 동전은 dp[i][j-coin[i]] 이렇게 같은 행에서 가져오고, 이 문제는 dp[i-1][j-wei] 이렇게 이 전 행에서 가져오는가? 당연히 동전은 여러개를 사용할 수 있고 이 물건들은 하나만 사용 가능 하기 떄문이다.
int dfs(int x, int y) {
if(x == n-1 && y == m-1) {
return 1;
}
if(dp[x][y] != -1) return dp[x][y];
dp[x][y] = 0;
for(int i=0; i<4; i++) {
int nx = x + dx[i];
int ny = y + dy[i];
if(nx < n && nx >= 0 && ny < m && ny >= 0) {
dp[x][y] += dfs(nx, ny);
}
}
return dp[x][y];
}(0,0)에서 (n,m)까지가는 경로의 개수를 찾는 문제이다. 문제별로 갈 수 없는 길과 갈 수 있는 길로 나
뉜다. (x,y)에서 dfs를 4개의 길마다 해서 도착점에 오면 1을 return하고 dp[x][y]에 저장한다.
만약 dp값이 있는곳을 방문했다면, 탐색하지 않고 dp값을 return한다.
나부터 목적지까지 가는 경로의 개수는 n개이니 탐색하지마세요라는 것이다. 따라서 방문여부인
visited배열도 필요가 없다.
이 문제는 backtracking으로 풀 수 있지만, dp로 푸는게 훨씬 시간이 적게든다.
for(int i=1; i<n; i++) {
for(int j=0; j<i; j++) {
if(arr[j] < arr[i]) {
dp[i] = max(dp[i], dp[j] + 1);
}
}
}1, 2, 8, 9, 4, 5 이런 수열에서 가장 긴 증가하는 부분수열의 최대 길이를 찾는 문제이다.
1, 2, 8, 9, 4, 5 이렇게 1, 2, 4, 5가 가장 길기 때문에 정답은 4가된다.
반복문을 돌며 자신 앞까지 자신보다 작은 값 중, 가장 dp값이 큰 dp값에 + 1을 해주면 된다.
이 문제는 이진탐색으로 풀면 O(nlogn)시간 안에 해결할 수 있기 때문에, 이진탐색을 쓰는 것을 더 추
천한다.
for(int i=1; i <= s1.length(); i++) {
for(int j=1; j <= s2.length(); j++) {
if(s1[i-1] == s2[j-1]) {
dp[i][j] = dp[i-1][j-1] + 1;
} else {
dp[i][j] = max(dp[i-1][j], dp[i][j-1]);
}
}
}두 문자열이 있을때 공통으로 포함된 가장 긴 문자열의 길이를 구하는 문제이다.
두 문자열이 같다면 왼쪽위에서 가져오고, 같지 않다면 위나 왼쪽 중 큰 값을 가져 오면 된다.
사실 잘 이해가 되지 않는다. 관련 문제를 더 풀어보고 마저 작성해야겠다.
string ans = "";
int i = s1.length();
int j = s2.length();
while(dp[i][j] != 0) {
if(dp[i][j] == dp[i-1][j]) {
i--;
} else if(dp[i][j] == dp[i][j-1]) {
j--;
} else if(dp[i][j] == dp[i-1][j-1] + 1) {
ans += s1[i-1];
i--;
j--;
}
}위의 dp로 구한 값을 역 추적하면서 증가되었던 해당 부분의 문자를 더해주고 역으로 출력해 주면
공통부분의 문자열을 구할 수 있다.
정렬을 어떻게 정렬할 것인가가 가장 중요하다.
처음 값을 기준으로 정렬할 것인가?
마지막 값을 기준으로 정렬할 것인가?
두 수의 차를 기준으로 정렬할 것인가?
위 세가지를 순서대로 해보고 예외가 발생하지 않는 정렬을 선택하자.
for(int i=0; i<lec.size(); i++) {
int start_time = lec[i].second;
int end_time = lec[i].first;
while(start <= end) {
if(check[start] == false) {
check[start] = true;
break;
}
start++;
}
}다양한 범위의 숫자들을 각자 하나의 방에 최대한 많이 넣는 경우에 사용한다
1,2,3,4방이 있고 2-3, 1-7, 1-7, 1-7 숫자들이 있다면 처음 값을 기준으로 정렬한다면 2-3은 들어갈 수
없기 때문이다.
void binary_search(int start, int end, int target) {
if(start > end) return;
int mid = (start+end) / 2;
if(mid >= target) {
binary_search(mid + 1, end, m);
} else {
binary_search(start, mid - 1, m);
}
}범위를 반씩 줄여가며 탐색하는 방법이다.
**탐색범위가 수상하리 만큼 넓을 때, 이진탐색을 먼저 떠올려야한다. (**1억이상되는 범위 탐색 문제들)
이진 탐색은 처음부터 끝까지 탐색하는 O(N)타임보다 적은 O(logN)타임이 소요된다.
이진 탐색 문제를 풀때 주의할 점
-
정렬된 리스트에만 이진 탐색이 가능하다!
-
범위가 매우 넓어 int형을 넘어서 overflow가 발생할 수 있으므로 잘 확인하여 자료형을 사용하자.
( c++의 경우 int의 범위는 -21억~21억)
-
탐색 범위를 잘 제한하자. 0이 될 수도, 1이 될 수도, 배열의 첫 번째 원소가 될 수 있다.
계속하여 최소값이나 최대값을 조회하는 문제이거나, 새롭게 원소가 추가 될때마다 정렬을 계속해주는 문제라면 우선순위 큐를 먼저 떠올려야한다.
왜 우선순위 큐를 떠올려야하는가? 조회할때마다 max나 min의 변수를 이용하여 최소/최댓값을 계속 변경해 나가면 되는데 왜 우선순위 큐를 사용할까? 보통 우선순위 큐를 사용하는 문제는 queue에 저장되어있는 최댓값 다음의 값을 다음 반복문에서 또 사용하기 때문이다.
sort(bag, bag + k); // 가방 오름차순 정렬
sort(jew, jew + n); // 보석 무게 오름차순으로 정렬 ( 무게 같으면 가격 오름차순 )
long long sum = 0;
int idx = 0;
for(int i=0; i<k; i++) {
// 가방 무게보다 가벼운 보석들의 가격을 pq에 담음
while(idx < n && jew[idx].first <= bag[i]) {
pq.push(jew[idx].second);
idx++;
}
// 가장 가격이 높은 보석의 가격을 sum에 합치면서 pq에서 pop
// 다음 가방에도 pq에서 가장 가격이 높은게 들어감
// 무게가 가방보다 낮은것들만 위에서 걸러서 넣었기 때문에 가능
if(!pq.empty()) {
sum += pq.top();
pq.pop();
}
}
가방들에 넣을 수 있는 최대무게는 정해져 있고, 특정 무게들의 보석들이 있을때, 얼마나 많은 보석을 넣을 수 있는지를 알아내는 문제이다. 가방과 보석을 정렬한 다음, 가방 무게보다 낮은 보석들을 pq에 담아나가면서 계속 넣어주면 된다.
int dp[20001];
vector<pair<int,int>> graph[20001];
priority_queue<pair<int ,int>, vector<pair<int, int>>, greater<pair<int, int>>> pq;
pq.push(make_pair( 0, start ));
dp[start] = 0;
while(!pq.empty()) {
int dist = pq.top().first;
int now = pq.top().second;
pq.pop();
if(dp[now] < dist) continue;
for(int i=0; i<graph[now].size(); i++) {
int next = graph[now][i].first;
int cost = dist + graph[now][i].second;
if(cost < dp[next]) {
dp[next] = cost;
pq.push(make_pair( cost, next ));
}
}
}노드간의 거리가 주어질때, 특정 한 노드로부터 다른 모든 노드까지의 최단거리를 구하는 알고리즘이다.
만약 우선순위 큐를 사용하지 않는다면, 일반적인 완전탐색과 같은 알고리즘이 된다. 다익스트라 알고리즘의 빠름은 현재 노드에서 가장 비용이 적게드는 간선을 선택하여 그 노드를 먼저 방문하는 방식에 있다. 그렇지 않고 비용에 상관없이 방문하는 방식을 택한다면 나중에 가장 비용이 적게드는 간선을 통과하여 노드를 방문했을때, 다시 최단거리로 업데이트 해주어야 하니 시간이 곱절로 들게된다.
음의 간선은 처리 불가능
for(int i=0; i<1001; i++) {
for(int j=0; j<1001; j++) {
if(i == j) dp[i][j] = 0;
else dp[i][j] = 1000000000;
}
}
for(int k=1; k<=n; k++) {
for(int i=1; i<=n; i++) {
for(int j=1; j<=n; j++) {
dp[i][j] = min(dp[i][j], dp[i][k] + dp[k][j]);
}
}
}노드간의 거리가 주어질때, 모든 노드로부터 다른 모든 노드까지의 최단거리를 구하는 알고리즘이다.
i → j → k 순으로 반복문을 이어나가면 다른 노드의 최단거리가 미쳐 업데이트 되지 않은 상태에서
다른 노드의 최단거리를 구하려는 꼴이 되니, k를 먼저 사용해서 특정 한 점에대해서 매번 맵을 순회
하도록 한다.
플루이드 워셜 알고리즘은 시간복잡도가 O(N^3)이므로 간선이 매우 많고, 노드가 적은 문제에서 유
리하다.
이 유형은 다익스트라 알고리즘으로도 해결할 수 있으므로, 노드가 1000개가 넘어간다면 다익스트
라 알고리즘으로 해결하도록 하자.
음의 간선 처리 가능
플루이드 워셜 알고리즘으로 두가지의 일의순서나 크기비교로 세가지 정보를 얻을 수 있다.
int tree[100001];
vector<tuple<int, int, int>> graph;
int get_parent(int child) {
if(tree[child] == child) {
return child;
}
return tree[child] = get_parent(tree[child]);
}
void merge(int child1, int child2) {
int parent1 = get_parent(child1);
int parent2 = get_parent(child2);
if(parent1 == parent2) return;
tree[parent2] = parent1;
}
sort(graph.begin(), graph.end());
for(int i=0; i<graph.size(); i++) {
int cost = get<0>(graph[i]);
int node1 = get<1>(graph[i]);
int node2 = get<2>(graph[i]);
if(get_parent(node1) != get_parent(node2)) {
merge(node1, node2);
ans += cost;
}
}크루스칼 알고리즘은 최소 신장 트리를 만들기 위한 알고리즘이다.
신장트리는 간선의 비용이 존재하는 그래프에서 모든 노드가 연결되기 위한 최소한의 간선만 제외
하고 모두 제외한 트리이고, 최소 신장 트리는 그 간선의 가중치의 합이 최소가 되는 트리이다.
간선의 비용을 오름차순으로 정렬하고 비용이 낮은 간선부터 분리집합처리를 하면된다.

위의 그림에서 1의 부모와 3의 부모의 부모를 비교하여 부모가 같다면 cycle이 발생하므로 둘을 연결하지 않고,
부모가 다를때만 둘을 연결해주면 된다.
dp[1] = 0;
bool cycle = false;
for(int i=1; i <= n; i++) {
for(int j=1; j <= n; j++) {
int now = j;
for(int k=0; k<graph[j].size(); k++) {
int next = graph[j][k].first;
int dis = graph[j][k].second;
if(dp[now] != INF && dp[next] > dp[now] + dis) {
dp[next] = dp[now] + dis;
if(i == n) cycle = true;
}
}
}
}간선 중 음의 간선이 있을때, 벨만포드 알고리즘을 사용하면 cycle로 인한 최단거리 갱신을 막을 수 있다.
이 알고리즘은 아직 잘 모르겠다. 나중에 나오면 한번더 공부해 보겠다.
for(int i=1; i<=n; i++) {
if(degree[i] == 0) {
q.push(i);
}
}
while(!q.empty()) {
int child = q.top();
cout << child << " ";
pq.pop();
for(int i=0; i<graph[child].size(); i++) {
int parent = graph[child][i];
degree[parent]--;
if(degree[parent] == 0) {
q.push(parent);
}
}
}
Directed Acyclic Graph (DAG)는 사이클이 없는 방향 그래프이다.
DAG는 이벤트 간의 우선순위를 나타내기 위해 주로 사용된다.
위상 정렬(Topological sort)은 비순환 방향 그래프(DAG)에서 정점을 선형으로 정렬하는 것입니다.
그래프가 DAG가 아닌 경우 그래프에 대한 위상 정렬은 불가능합니다.
쉬운예로 스타크래프트의 건물 짓는 과정을 생각하면 된다.
어떤 일들을 무언가를 특정 기준에 의해 순서대로 나열하고 싶을때 사용한다.
각 노드간의 차수를 기록해두고 차수가 0인 노드부터 끊어내면 된다.
백준 3665 - 최종 순위 (이해 잘 안됨)


int find_parent(int child) {
if(tree[child] == -1) return child;
return tree[child] = find_parent(tree[child]);
}
void merge(int child1, int child2) {
int a_parent = find_parent(child1);
int b_parent = find_parent(child2);
if(a_parent == b_parent) return;
if(parent1 > parent2) {
tree[parent1] = parent2;
} else {
tree[parent2] = parent1;
}
}분리집합은 두개의 원소가 같은 집합에 있는가? ( 두개의 원소가 같은 부모를 가리키는가?) 에 대한
알고리즘이다.
원소의 value를 부모의 index를 가리키게 해서 하나의 집합을 이루게 하는 방식이다.
첫번째 그림의 왼쪽 처럼 줄지어 이어가면 시간복잡도가 늘어나므로, 공통부모를 통일해준다.
두개의 집합을 합쳐줄때는 한쪽 집합의 부모가 다른쪽 집합의 부모를 가리키게 한 다음, 또다시 공통
부모를 통일해준다.
for(let j=1; j<=n; j++) {
tree[j] = get_parent(j)
}만약 [1, 2] [2, 3] [3, 4] 이렇게 간선이 순서대로 주어진다면 tree는 [1, 1, 1, 1]이 되겠지만
[1, 2] [3, 4] [2, 3]로 주어진다면 4의 부모는 1로 update되지 않고 3으로 남아있게 된다. 따라서 이렇게 연결 순서대로 주어지지 않는 경우에는 이렇게 해당 node를 다시 순회하며 부모를 update시켜 주어야 한다.

long long segment_tree(int start, int end, int node) {
if(start == end) return tree[node] = arr[start];
int mid = (start + end) / 2;
return tree[node] = segment_tree(start, mid, node * 2) + segment_tree(mid + 1, end, node * 2 + 1);
}
long long sum(int node, int start, int end, int left, int right) {
if(start > right || end < left) return 0;
else if(left <= start && end <= right) return tree[node];
else {
int mid = (start + end) / 2;
return sum(node * 2, start, mid, left, right) + sum(node * 2 + 1, mid+1, end, left, right);
}
}
void update(int change_index, long long diff, int node, int start, int end) {
if(change_index < start || change_index > end) return;
tree[node] += diff;
if(start != end) {
int mid = (start+end) / 2;
update(change_index, diff, node*2, start, mid);
update(change_index, diff, node*2+1, mid+1, end);
}
}세그멘트 트리를 이용하면 여러개의 연속적인 데이터가 존재할 때, 특정한 범위의 데이터의 합을 구
하기 용이하다.
특정 배열에서 길이가 n인 구간의 합을 구하려면 시간 복잡도는 O(N)이 소요된다. 하지만 구간의 합
을 계속해 나가다 보면 많은 시간이 소요되는 법이다. 세그멘트 트리는 미리 구간의 합을 기록해두고
찾아서 활용하는 방식이다. 세그멘트 트리를 활용하면 O(logN)시간안에 구간의 합을 구할 수 있다.
배열에서 특정값이 수정되어 그에 따른 구간 합을 수정하는 것도 O(logN) 시간이 소요된다.