We collect observation (birdseye view image) and action (velocity and steering) measurements from an agent that navigates the track using the Potential Field algorithm. This provides labeled data for our CNN.
In order to have a sufficiently rich training dataset, we collect driving data in 3 main configurations:
- driving closer to left track boundary
- driving closer to right track boundary
- driving in the middle
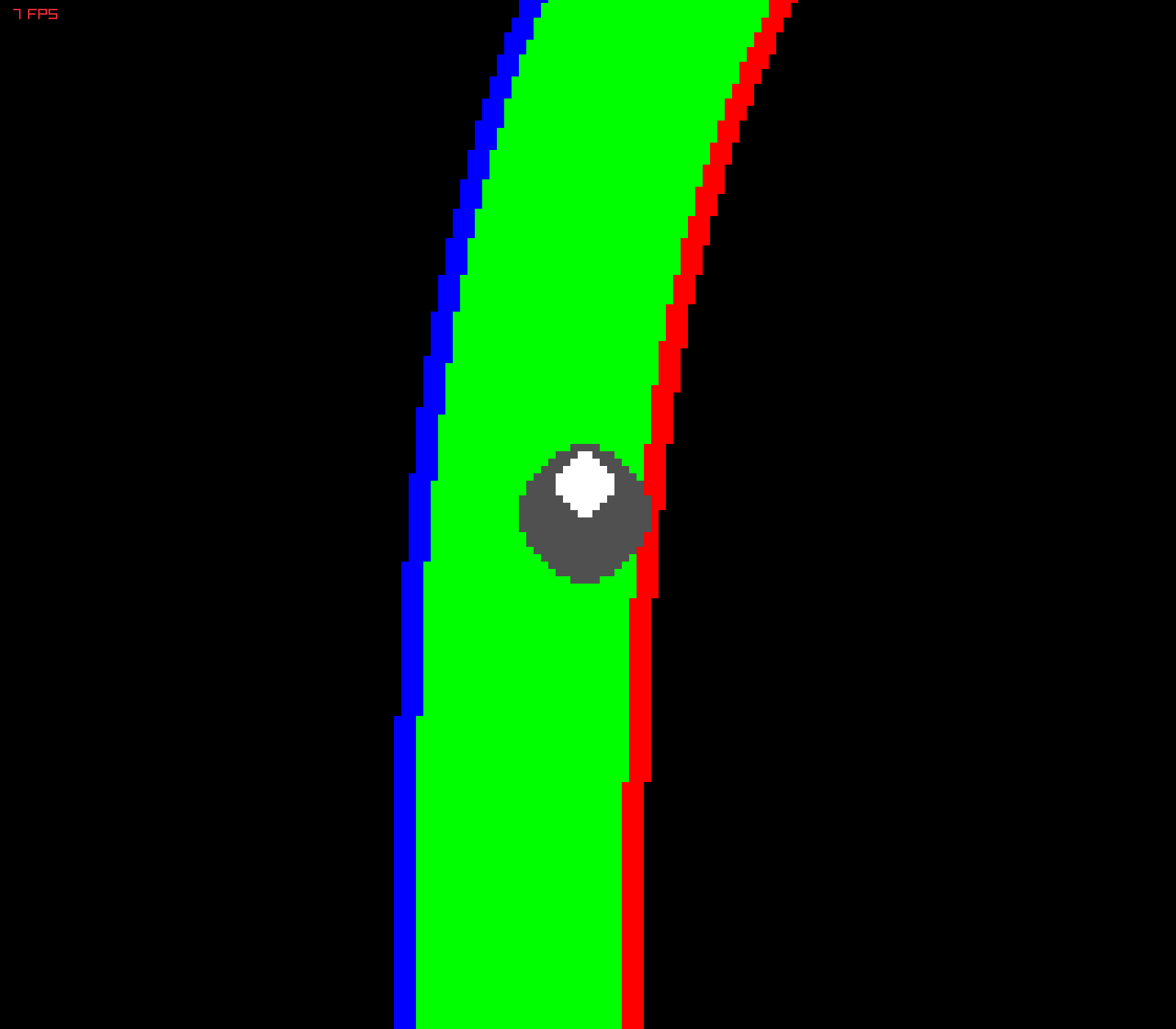
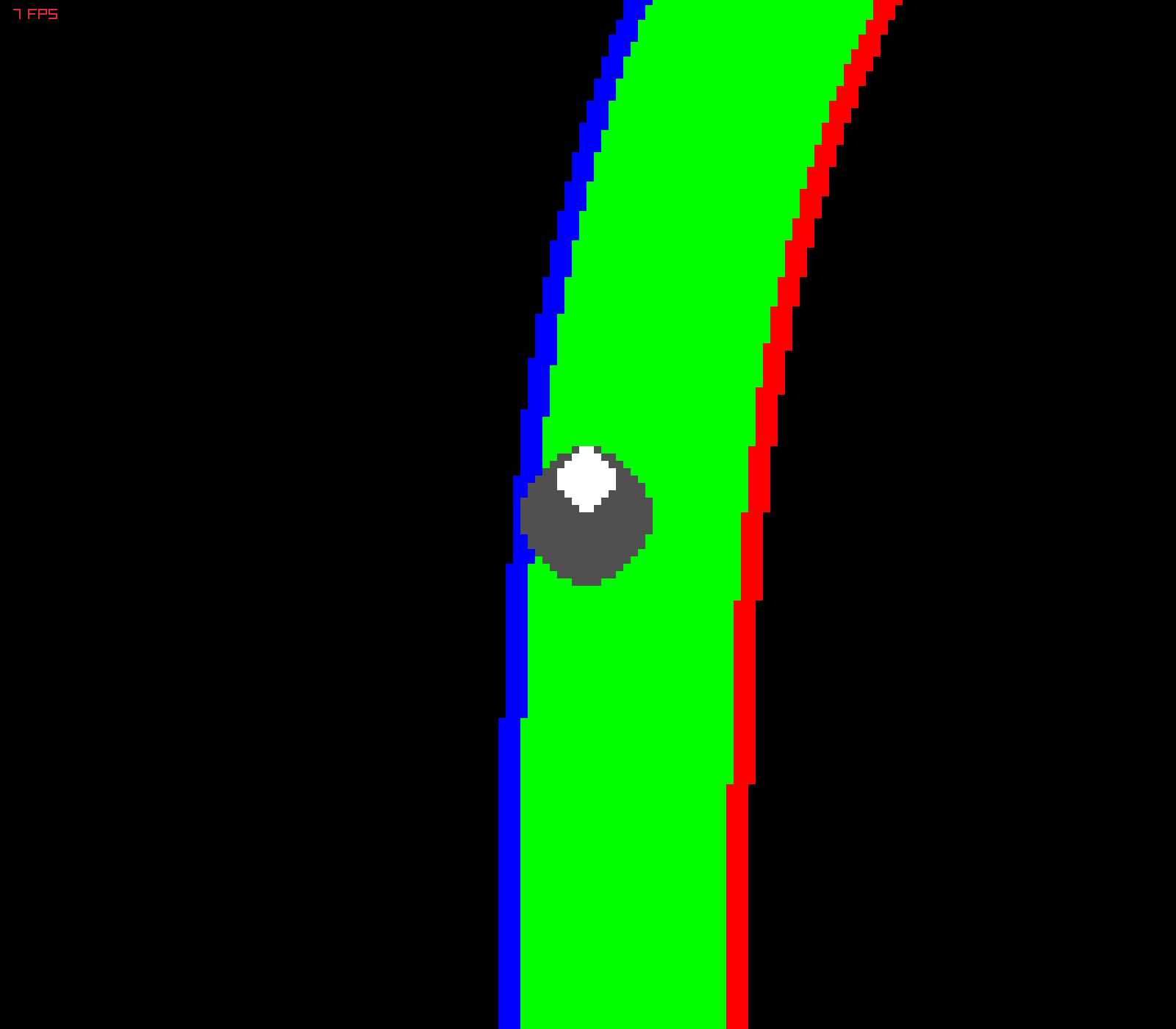
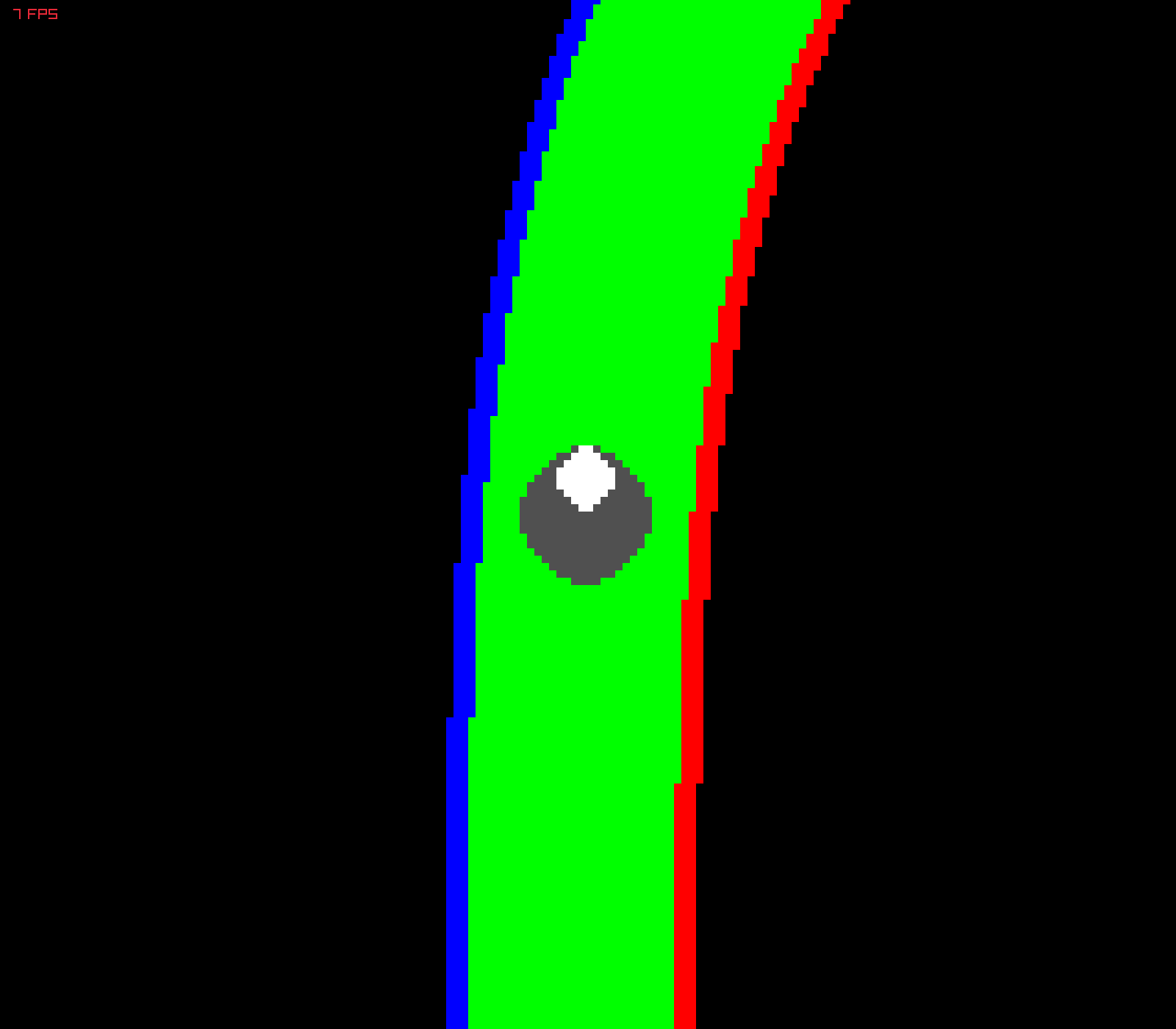
Although the BEV images collected are in RGB, CNN we train uses grayscale images. Architecture of the CNN is simple:
- 5 2d-convolutions, each of which is followed by a Relu
- A flattening layer that takes multi-dim output from the 5th convolutional layer and reduces to single dimension
- 4 fully connected layers, each of which is followed by a Relu.
- These reduce in size progressively, last layer having the same size as our actions.
- Final tanh layer to normalize the action output.
Activations from the first 3 layers can be seen below:
- 1st layer

- 2nd layer

- 3rd layer
