Word2vec can be used to generate word vector(word embeding),the distance between these vectors inflect the word’s relationship .A very interesting phenomenal is these vectors can be added and minused in the formulation.For example: vector('Paris') - vector('France') + vector('Italy') equals vector('Rome'), vector('king') - vector('man') + vector('woman') equals vector('queen').
In this project I use gensim and pretrained google word2vec model to cluster common used english words.These common English words mainly comes from Google Top 10000 (google-10000-english.txt). Before we do cluster,we first need to extract the word vector .In gemsim we can load the pre-trained word2vec model,then the vector can be extracte from the model.
word_vectors = {}
#load top 10000 word to word_vectors
with open(GOOGLE_ENGLISH_WORD_PATH) as f:
lines = f.readlines()
for line in lines:
line = line.strip('\n')
if line:
word = line
print(line)
word_vectors[word]=None
model = gensim.models.KeyedVectors.load_word2vec_format(GOOGLE_WORD2VEC_MODEL, binary=True)
for word in word_vectors:
try:
v= model.wv[word]
word_vectors[word] = v
except:
pass
save_model(word_vectors,GOOGLE_WORD_FEATURE)
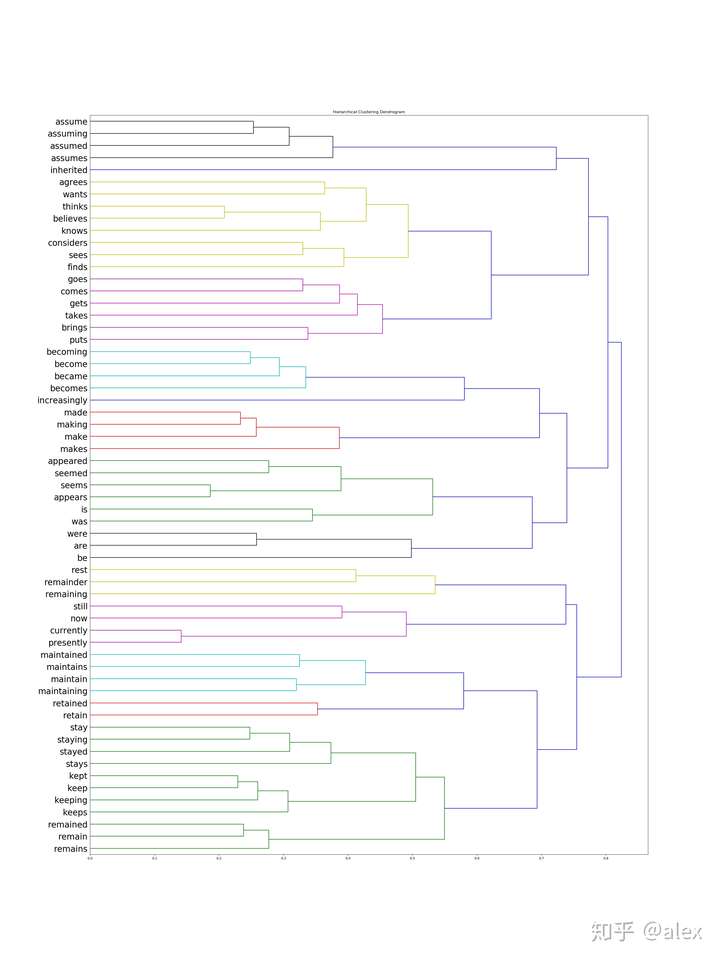
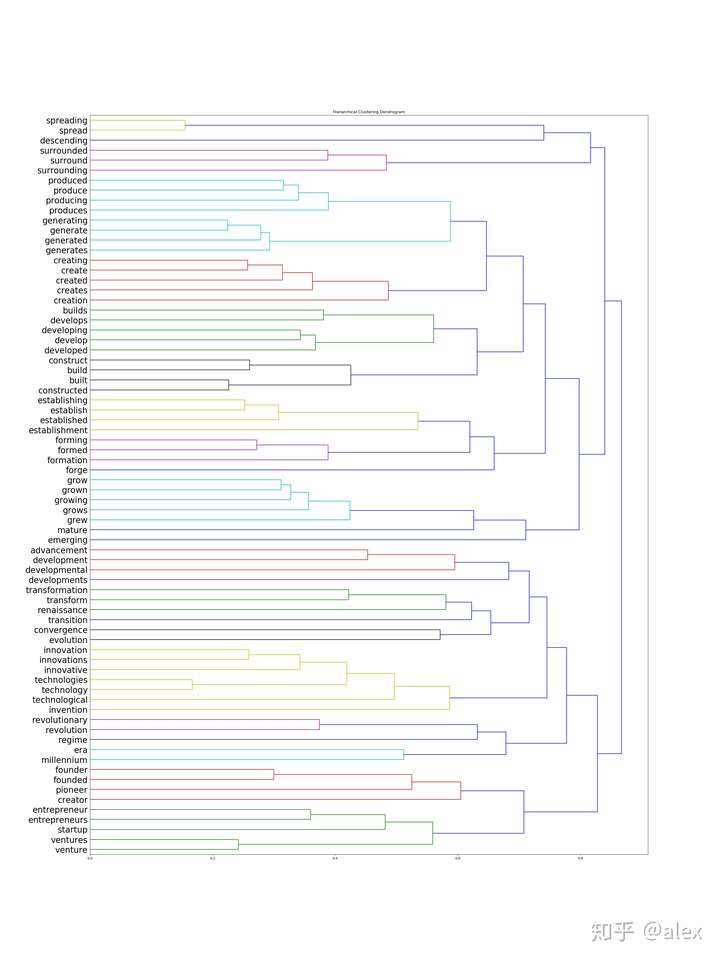
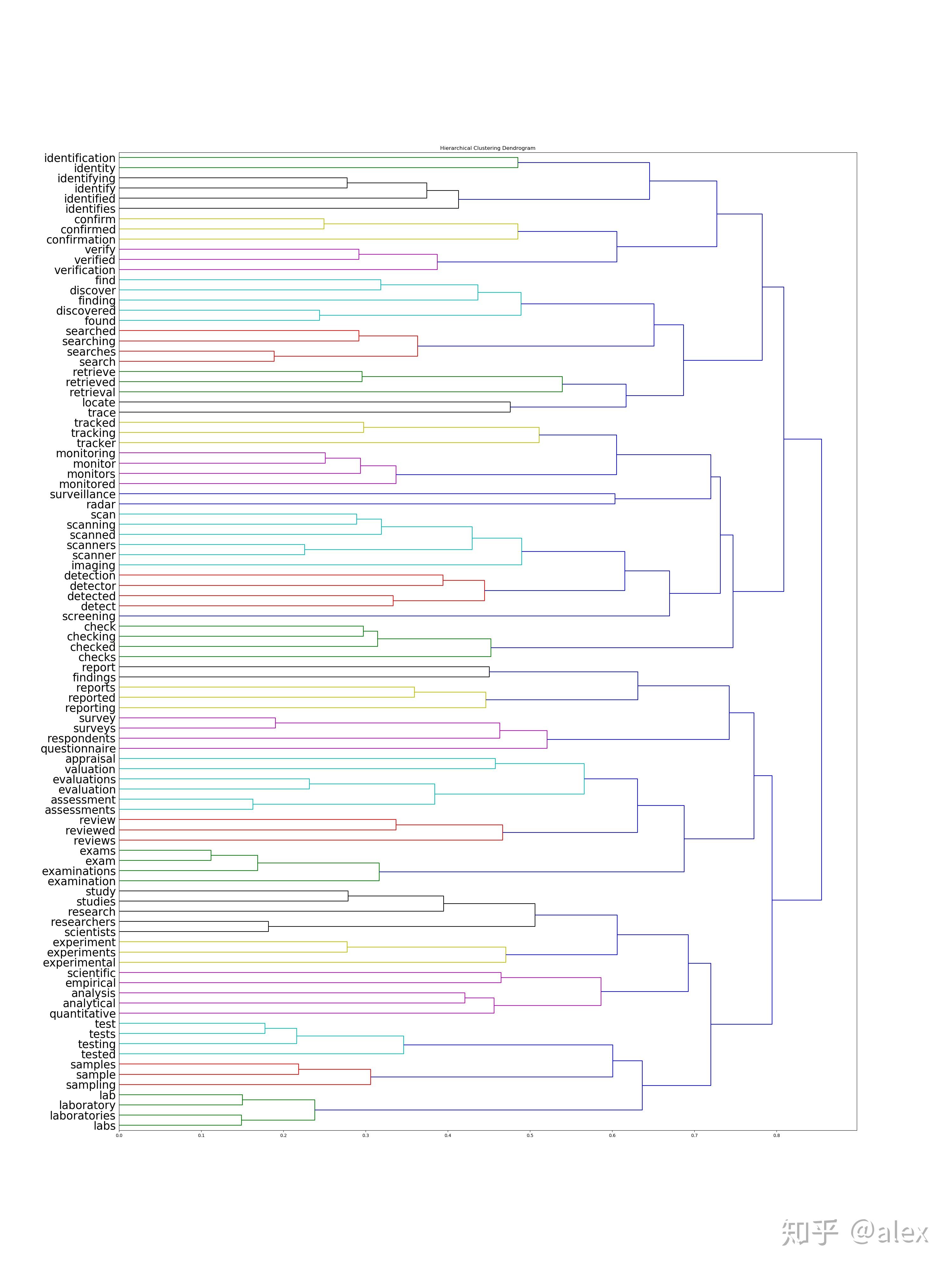
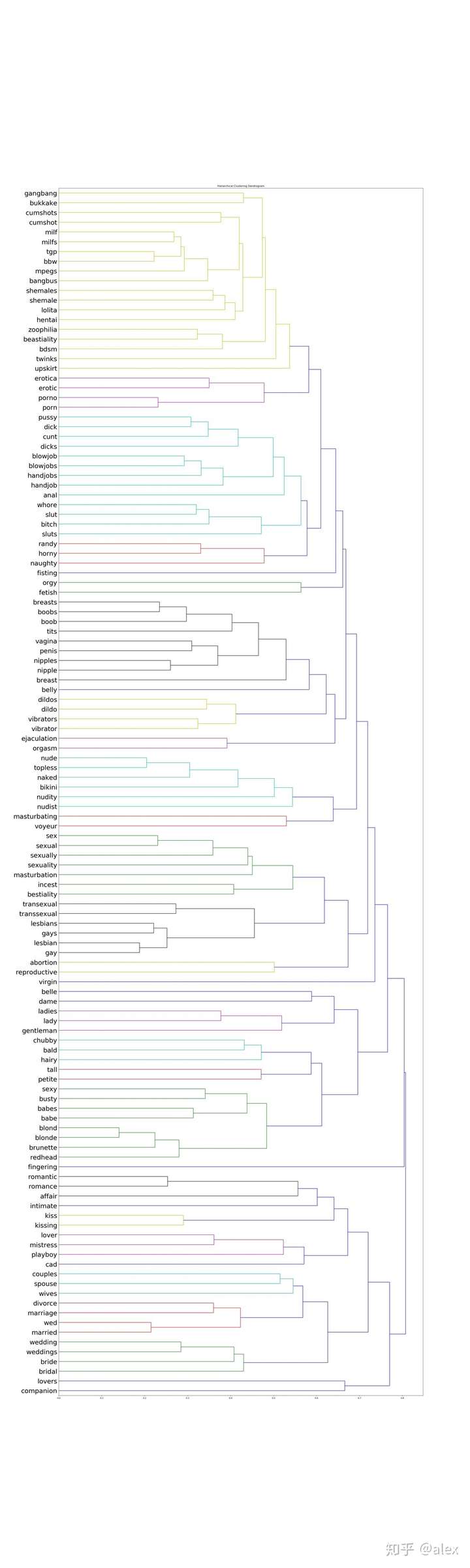
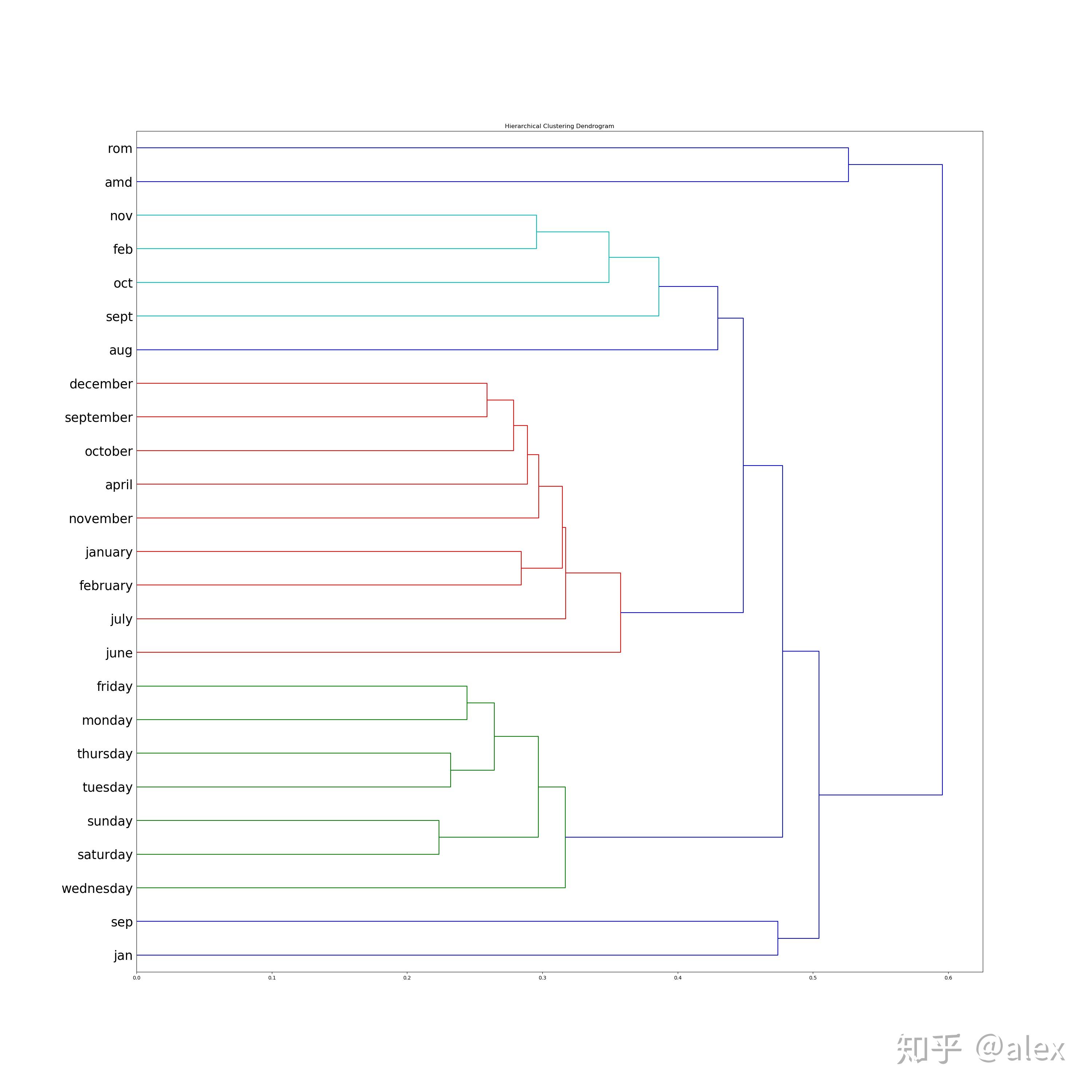
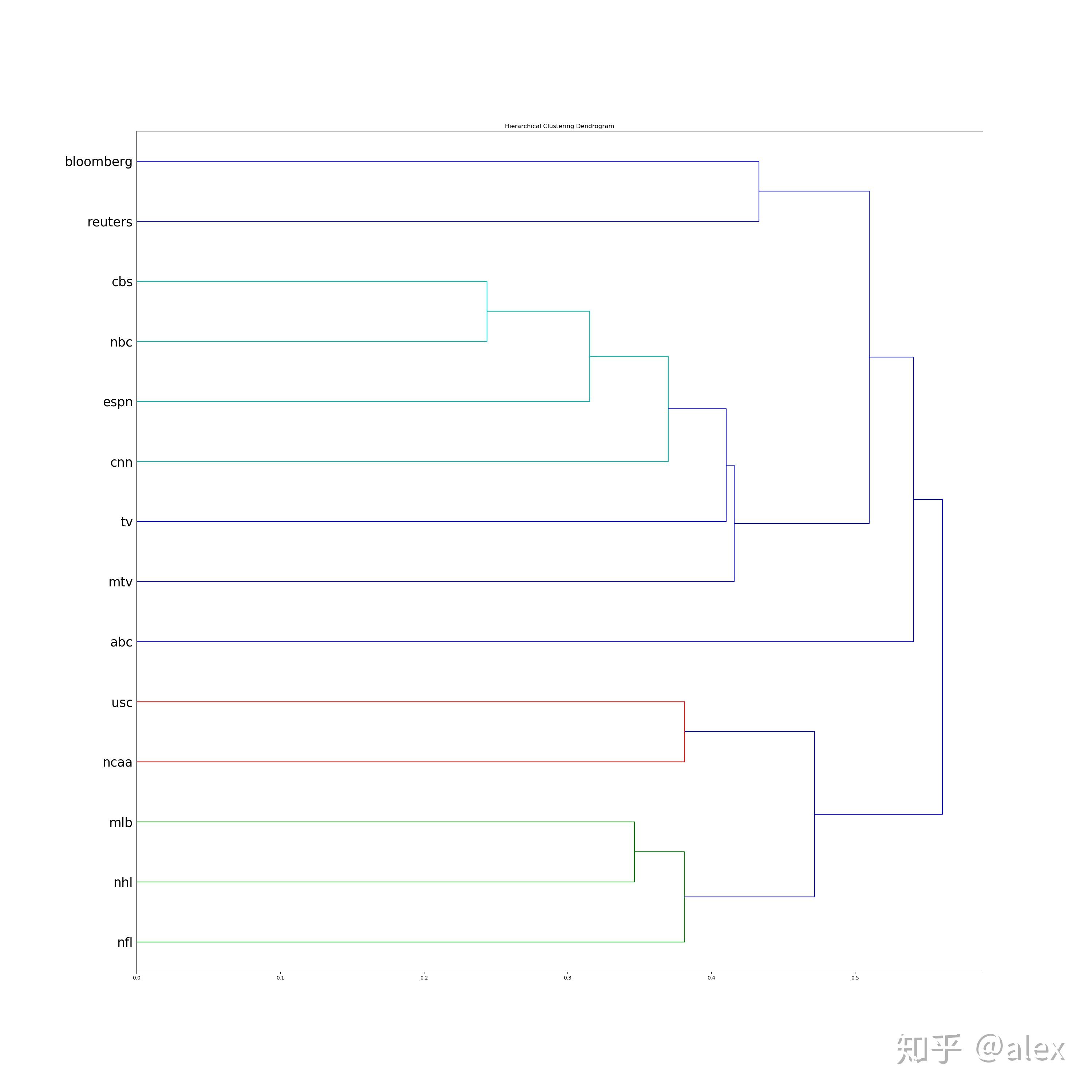
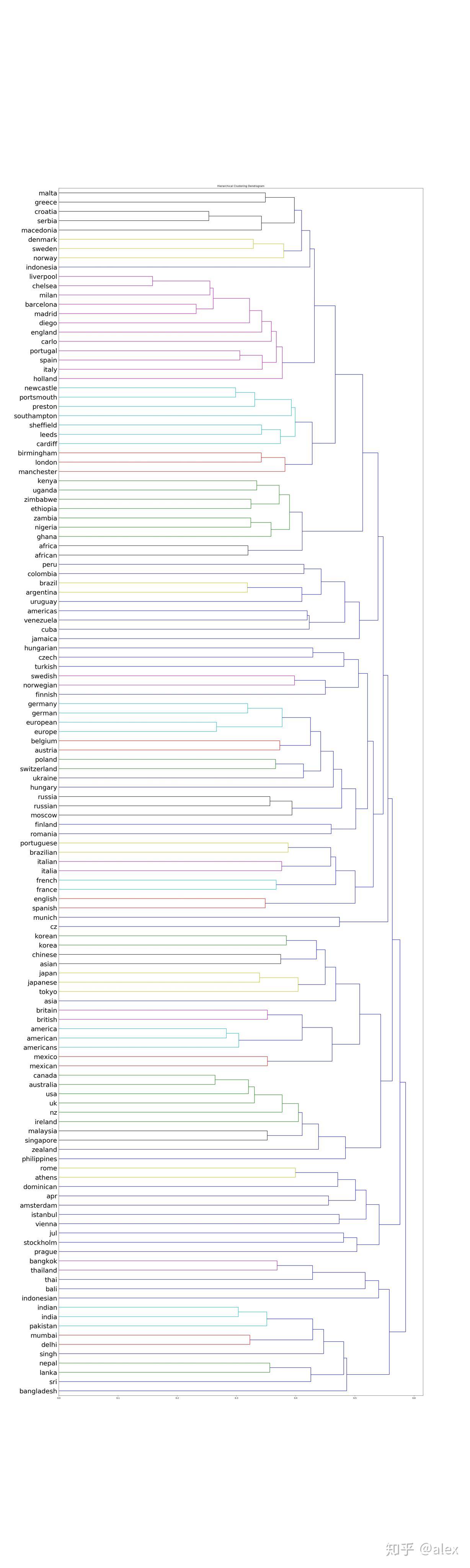
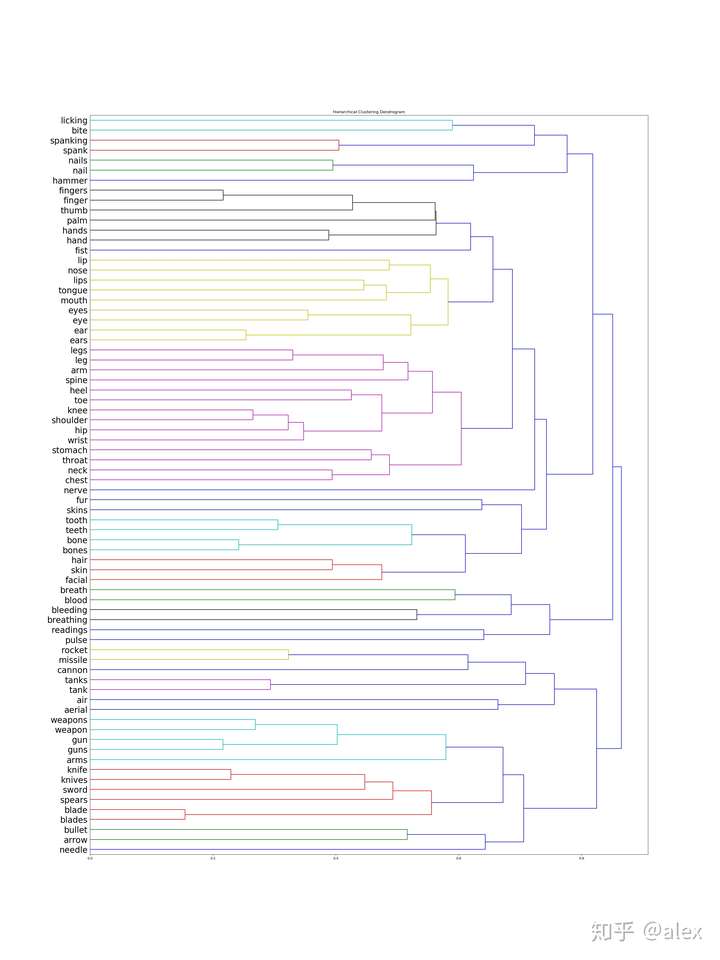
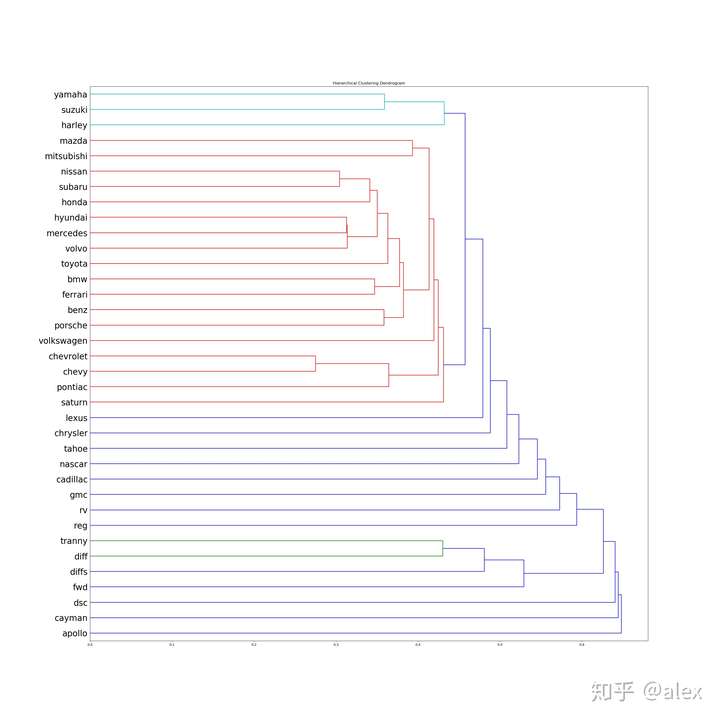
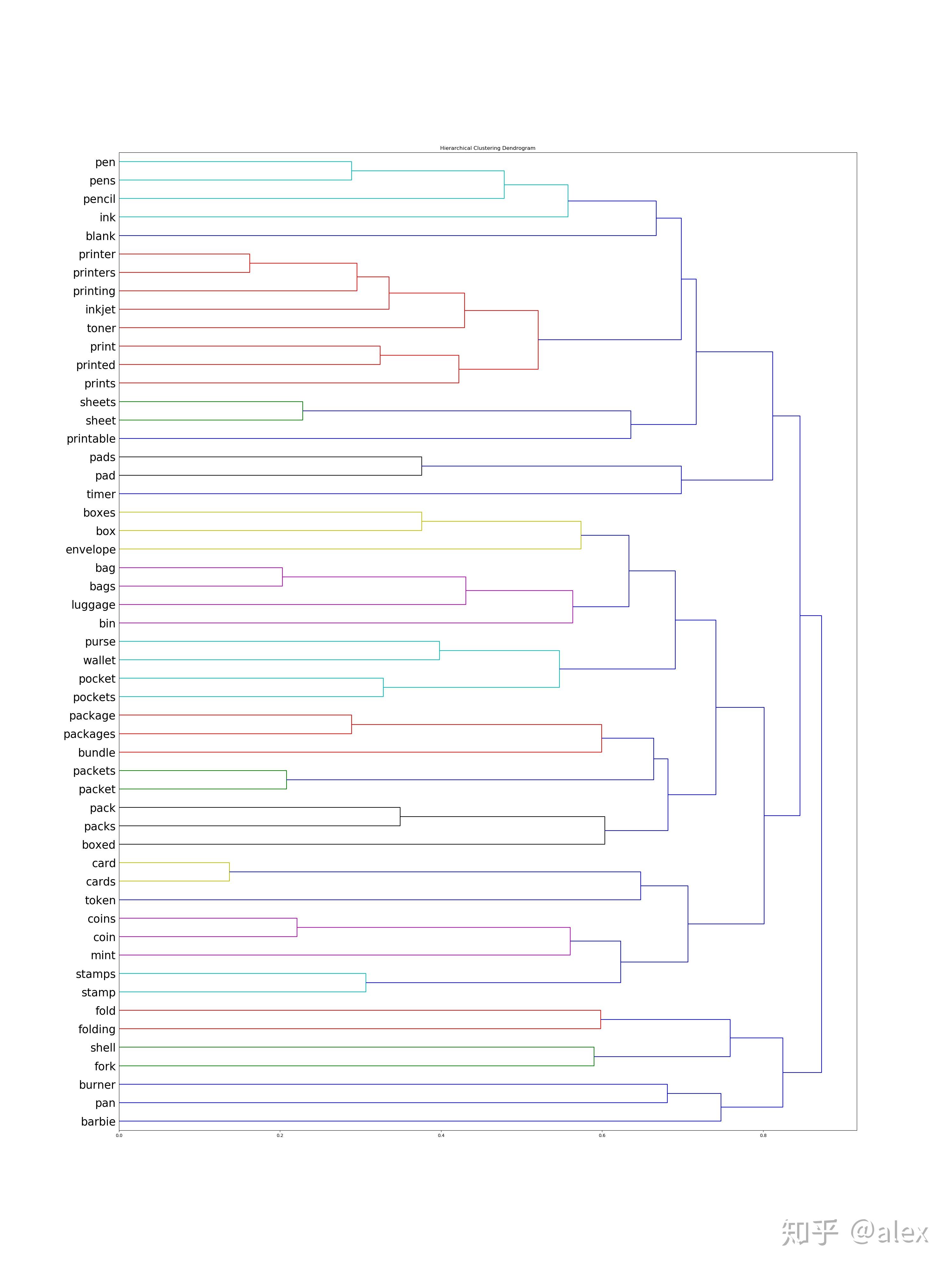
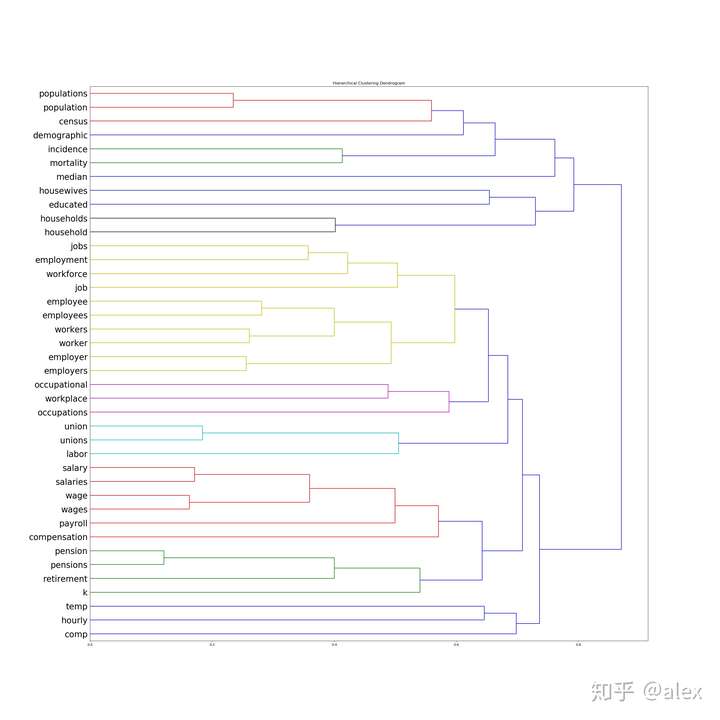
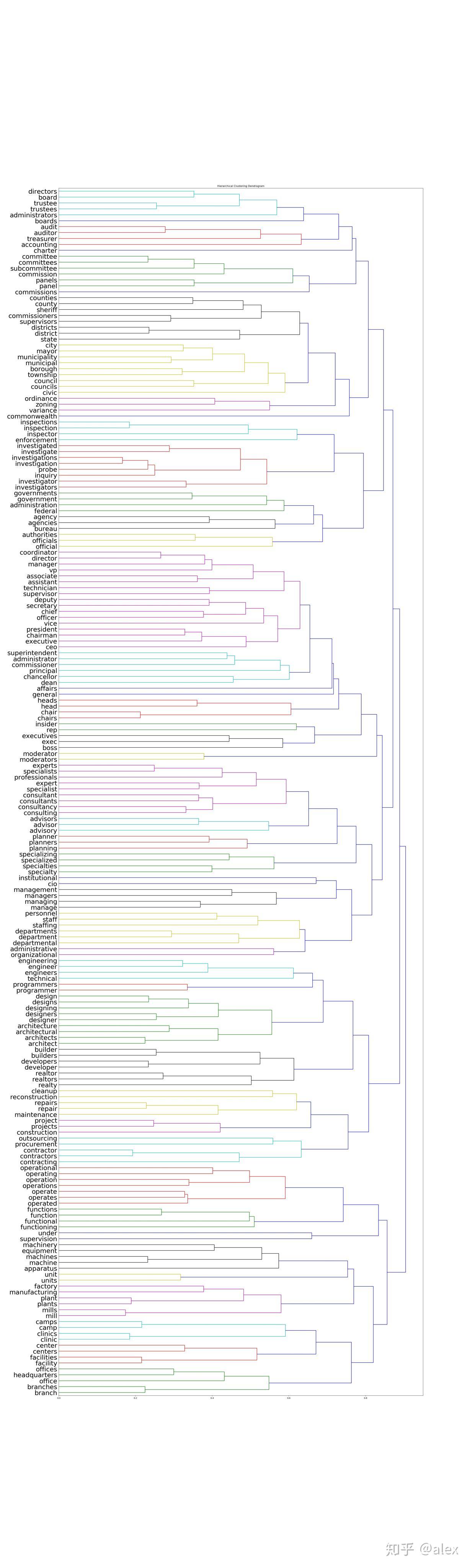
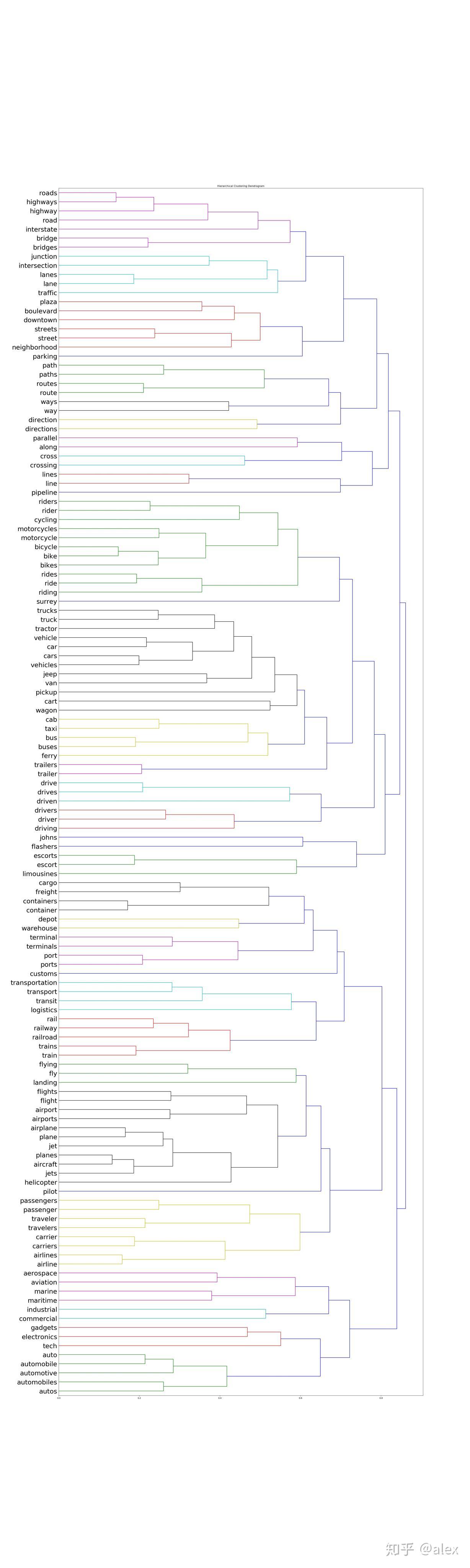
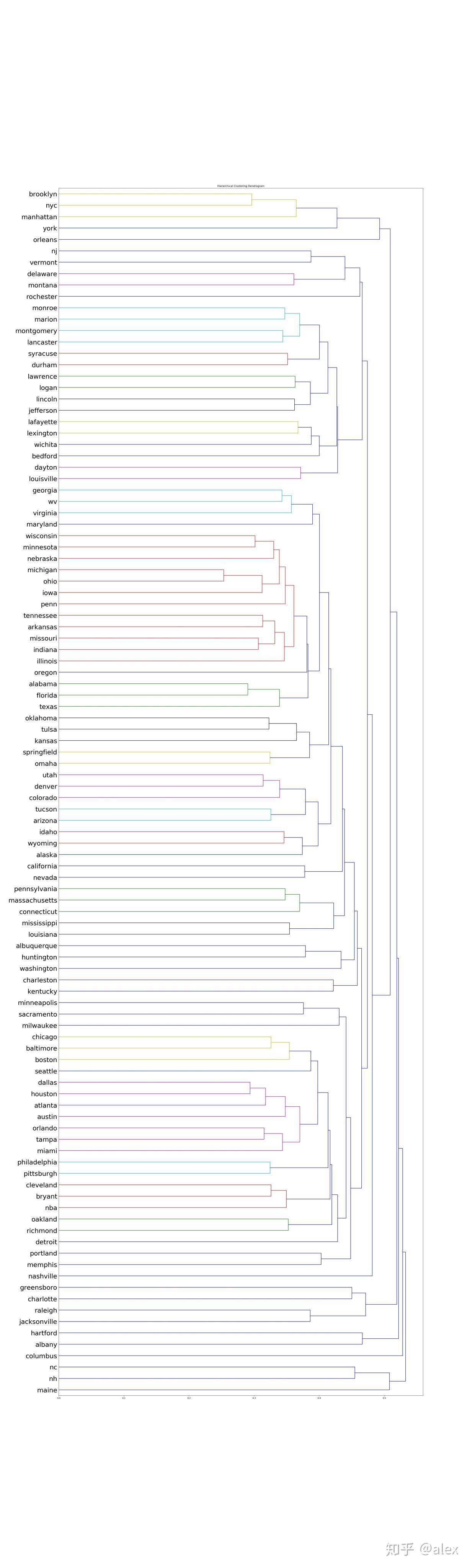
After we got the word vectore,we can use certain method to do clustering.Most people choose K-means.But in this project,I choose hierarchical cluster method.In hierarchical cluster we can see the whole word tree from bottom to top.In scipy ,linkage can be used to do this work. Dendrogram can be then used to draw the tree and output it in image format.There are about 10000 word,it not easy and not suitable to display the tree in one image.In the code source folder,I worte a hierarchical_cluster parser function to parese the linkage retured result.The result is saved into file in json format.It can be used for further analysis.
The whole word cluster tree is very large.In order to display it properly,I split it to manly sub-trees.And each sub-treee should not large then 400.There are about 50-60 sub-trees after spliting.I manuly checke them and foud some intersting thing here.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
#parse linkage results
from scipy.cluster.hierarchy import dendrogram, linkage
def hierarchical_cluster(centers,wods):
to_merge = linkage(centers,method='average', metric='cosine')
clusters = {}
maxcluster =0
for i, merge in enumerate(to_merge):
if merge[0] <= len(to_merge):
a = centers[int(merge[0]) - 1]
a=words[int(merge[0]) ]
else:
a = clusters[int(merge[0])]
if merge[1] <= len(to_merge):
b = words[int(merge[1])]
else:
b = clusters[int(merge[1])]
distance=merge[2]
count = merge[3]
clusters[1 + i + len(to_merge)] = {
'children' : [a, b],'distance':distance,'count':count
}
maxcluster=1 + i + len(to_merge)
return clusters,maxcluster
cluster的格式大致如下
{
"distance": 0.45818002237821087,
"children": [
leftcluster,
righcluster
],
"count": 2.0
}