new_audit(font-size-audit): legible font sizes audit #3533
Conversation
…ing selectors even if test passed. Clean up.
…yles of a parent node. Fixing linting errors, improvic jsdoc.
ccc68cc
to
6d1b518
Compare
There was a problem hiding this comment.
WOW nicely done! very impressive how much is accounted for here, left no stone unturned!
I'm mildly concerned about the implications of gathering all the information might have on when we can include the audit by default, but some of that might be a trade-off @rviscomi has already thought about?
Getting the granular level of attribution we have here might make it excluded from default config/HTTP archive/etc :/
| @@ -49,6 +52,10 @@ module.exports = [ | |||
| score: false, | |||
| displayValue: '403', | |||
| }, | |||
| 'font-size': { | |||
| rawValue: false, | |||
There was a problem hiding this comment.
perhaps we can assert how many elements fail too? details: { items: { length: x }}
There was a problem hiding this comment.
Here we fail because viewport is not configured (see debugString below), so we don't even go into evaluating text size and details will be empty. Viewport is empty on this page because of the viewport audit that we also want to fail here.
There was a problem hiding this comment.
yeah I figured that out last time, but who knows what I was thinking 18 days ago :)
| * @return {{type:string, snippet:string}} | ||
| */ | ||
| function nodeToTableNode(node) { | ||
| const attributesString = node.attributes.map((value, idx) => |
There was a problem hiding this comment.
how does this look in practice, are the attributes way too long? is there a subset we might be interested in?
There was a problem hiding this comment.
good point, list of attributes may be long in some cases (e.g. schema.org metadata). However, limiting number of attributes shown to e.g. class and id, may be IMO confusing to the user as our representation of the node won't match the original one. This is especially problematic as ATM users have to find these nodes manually in their code/DOM (we don't link to the Element's panel from the report). If we want to limit number of attributes shown, we should at least expose node's xpath (just like a11y tests do) to make sure it is findable:

There was a problem hiding this comment.
hm yeah I agree, I'm on board with the path to element on hover either way
| * @param {Node} node | ||
| * @returns {{source:!string, selector:string}} | ||
| */ | ||
| function getOrigin(stylesheets, baseURL, styleDeclaration, node) { |
There was a problem hiding this comment.
origin is a pretty overloaded term on the web, how about "findStyleRuleSource" or something?
| }; | ||
| } | ||
|
|
||
| const totalTextLenght = getTotalTextLength(artifacts.FontSize); |
lighthouse-core/config/seo.js
Outdated
| passName: 'extraPass', | ||
| gatherers: [ | ||
| 'seo/font-size', | ||
| 'styles', |
There was a problem hiding this comment.
unfortunate that this relies on the styles gatherer :/ do you foresee a way the audit could optionally rely on the styles gatherer output? i.e. still report the violations but maybe with less helpful identifiers? I'm not sure we're going to get to a place in DevTools where we want to add the extra pass by default and it'd be a shame to miss out on the whole audit
There was a problem hiding this comment.
Only thing I need the styles gatherer for is stylesheetId -> stylesheet URL info. We can just say 'external stylesheet' if we don't have that mapping info, but I wonder - what's wrong with the 'styles' gatherer? Why does it need a separate run? Maybe I can collect stylesheetId -> stylesheet URL information in my gatherer separately and avoid requiring a separate run?
There was a problem hiding this comment.
styles gatherer parses all the stylesheets on the page with gonzales which can be extremely slow in some cases (old runs of theverge spent ~20s in styles gatherer)
this seems like a useful split though for cases where you don't need the actual parsed content of stylesheets 👍
There was a problem hiding this comment.
I've tried creating a styles-metadata gatherer that duplicates styles gatherer minus the parsing. However, I couldn't get styleSheetIds to match. font-size gatherer returned different IDs than styles-metadata gatherer for the exact same stylesheets. As far as I can see, this happens when you have two separate CSS.enable->CSS.disable runs. When I've put CSS.styleSheetAdded into the font-size gatherer (same CSS.enable->CSS.disable run) everything started to work.
Why this happens? No idea, possibly a Chrome bug. Why it worked when I used styles gatherer? This gatherer starts collecting stylesheet info in beforePass and finishes in afterPass, I can't do it in the default run because LH will complain that: "CSS domain enabled when starting trace".
I'm not a fan of keeping CSS.styleSheetAdded in the font-size gatherer, but don't see any other option at this point. Please let me know if you have any other ideas.
| .then(() => getAllNodesFromBody(options.driver)) | ||
| .then(nodes => nodes.filter(isNonEmptyTextNode)) | ||
| .then(textNodes => Promise.all( | ||
| textNodes.map(node => getFontSizeInformation(options.driver, node)) |
There was a problem hiding this comment.
this seems like it could have 1000s of inflight commands, 2 for each node in the body right?
any thoughts on limiting the protocol round-trips to try and compute as much as possible on browser side or do we absolutely need the node IDs for attribution :/
There was a problem hiding this comment.
2 for each node in the body
For each non empty text node in the body, yes.
Yeah, I was also worried about that part, but interestingly it performs very well. I understand your concern though. If we would like to keep the number of sent commands down I do have some ideas:
- get all computed styles in one shot with
DOMSnapshot.getSnapshot(we should be able to connect info from that method with info fromDOM.getDocumentvia backendNodeId ) - inject a script that will collect font-size information in the browser context (but it will be tricky to connect that info with Node objects from
DOM.getDocument) - only call
getMatchedStylesForNodefor nodes that have font-size below the threshold (but this would mean making the gatherer less generic) - filter nodes a bit more to only consider visible ones (figuring out what's visible might be tricky though)
Let me know what you think!
There was a problem hiding this comment.
but interestingly it performs very well.
alright then works for me as is :) maybe throw a comment in there saying it works out fine because X so future people don't bother trying to fix?
There was a problem hiding this comment.
I have renewed concern about the impact of this on pages with lots of DOM nodes :) I ran it on a few pages with a lot of elements I pulled from HTTPArchive and the gatherer took ~3-7s.
axe and event listeners audits are generally just as bad on the same sites, and it's probably a small fraction of sites where it's this bad, but we should try to be shrinking the list of super slow gatherers in the default set if possible.
What kind of impact do the 2nd and 3rd strategies you've proposed have on the runtime? If they're easy to explore, even in a hacky way it'd be nice to make an informed decision here :) A good example case for testing: https://www.flynashville.com/Pages/default.aspx
There was a problem hiding this comment.
I did some testing (using url that you provided):
current solution
getting nodes: 631.190ms
getting font size info: 6445.445ms
whole gatherer: 7212.822ms
w/o CSS.getComputedStyleForNode
getting nodes: 717.872ms
getting font size info: 6005.998ms
whole gatherer: 6726.438ms
w/o CSS.getMatchedStylesForNode
getting nodes: 621.086ms
getting font size info: 215.401ms
whole gatherer: 839.306ms
CSS.getMatchedStylesForNode only for nodes with font-size < 16px
getting nodes: 576.719ms
getting font size info: 4676.480ms
whole gatherer: 5280.742ms
It looks like CSS.getMatchedStylesForNode is responsible for bad performance.
Ideas that we had were around getting nodes and computed styles for them. However, this doesn't seem to be a bottleneck. We will need some ideas for dealing with CSS.getMatchedStylesForNode. Calling it only for nodes below the threshold doesn't do the trick.
Wish there was something like https://chromedevtools.github.io/devtools-protocol/tot/CSS/#method-setEffectivePropertyValueForNode but for getting effective rules for given property. Or ability to make more specific CSS.getMatchedStylesForNode calls (e.g. tell that we only care about one property and only about effective rule).
There was a problem hiding this comment.
As discussed with @patrickhulce right now - we will only call getMatchedStylesForNode for top X nodes with longest text. If website has more than X failing nodes user will get information at the end of the table that this is a partial result. I'll try to figure out what X value is to keep this audit under a second.
| * @param {!Object} driver | ||
| * @returns {!Array<!Node>} | ||
| */ | ||
| function getAllNodesFromBody(driver) { |
There was a problem hiding this comment.
do you think you could modify
lighthouse/lighthouse-core/gather/driver.js
Lines 783 to 795 in 63beebe
for your use case or is it much easier to work directly with the protocol as you're doing here?
it'd be nice to avoid collecting too many ad-hoc methods of retrieving DOM elements
There was a problem hiding this comment.
bump for thoughts on this :)
There was a problem hiding this comment.
getElementsInDocument filters text nodes out and puts everything into Elements (throwing away a lot of metadata returned by the DOM. getFlattenedDocument) so it was really hard for me to reuse it. Instead, I have extracted the this.sendCommand('DOM.getFlattenedDocument', {depth: -1, pierce}) part as a new driver method (getNodesInDocument) that getElementsInDocument depends on.
There was a problem hiding this comment.
Ah ok, that's cool :)
…for dynamically injected styles
e298c13
to
a588863
Compare
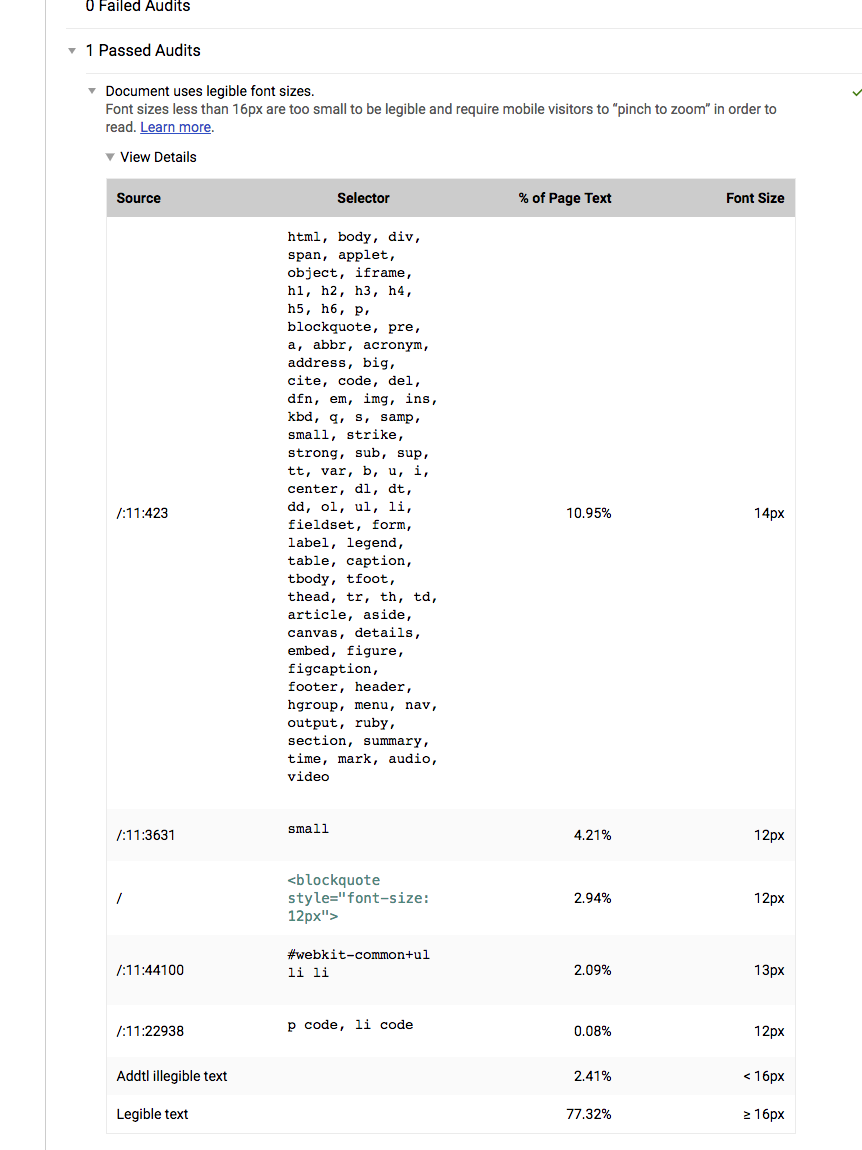
| description: 'Document uses legible font sizes.', | ||
| failureDescription: 'Document doesn\'t use legible font sizes.', | ||
| helpText: 'Font sizes less than 16px are too small to be legible and require mobile ' + | ||
| 'visitors to “pinch to zoom” in order to read. ' + |
There was a problem hiding this comment.
it's a little funny to see this audit end up in passing even when there are failures (example). I know this is the same as other audits, but i'm thinking we could start explaining our passing cutoff in the helpText here.
Strive to have >75% of page text >=16px;
@vinamratasingal @kaycebasques hows that sound?

| (failingTextLength - analyzedFailingTextLength) / visitedTextLength * 100; | ||
|
|
||
| tableData.push({ | ||
| source: 'Addtl illegible text', |
There was a problem hiding this comment.
abbreviation bikeshed!!
https://writingexplained.org/english-abbreviations/additional kinda recommends Add'l. That was the one I was expecting. let's do that.
|
@paulirish both nits addressed. AppVeyor failure is not connected with this PR. |
|
woohoo!! great job @kdzwinel! 🎉 💯 |
|
Cool, remind me to call out Konrad's contribution in the relevant "What's New In DevTools", when this (eventually) makes its way into the Audits panel |
|
Why is this placed in SEO audit section? |
|
@jitendravyas having legible text is a big part of responsive web design, which plays a significant role in SEO.
https://developers.google.com/search/mobile-sites/mobile-seo/ |
|
I know that tiny font sizes are not good but didn't know that Search engine crawler can detect the font size given in CSS file and it can affect ranking too. I used to think that Crawler check Content (HTML) only like Lynx browser see it. Font size is actually an accessibility issue, I think it can be placed in Accessibility section. But anyway, it's a good edition, though it will hard to keep 16px as a minimum size for any text, mainly in web apps. |
|
Yeah, there are already some SEO audits that are borrowed from the accessibility section; there's a lot of overlap between the two. It's ok (and encouraged) to use the audits in whichever section is applicable because they should affect the aggregate score of the relevant audit categories. I agree that 16px may be too ambitious. Analyzing the data in HTTP Archive, we're only seeing a ~20% pass rate for this audit. So we're looking into making necessary adjustments. |
|
Today I checked on lighthouse website and found that minimum font size has been changed from |
|
Your previous comment summed it up nicely:
16px was too high a bar and 80% of pages tested were failing the audit. The dashboard on HTTP Archive shows that the audit is performing much better now with a more realistic bar:
|

{kind=link}
|
ok. I would like to know why 12px was decided why not 14?
Was it decided based on WCAG 2.0 or any other research or recommendation or just because 80% of pages tested were failing the audit? |
|
12px/60% was chosen because we knew the audit would fail at a much more tolerable rate of ~25%. Of course, bigger text is better for legibility, but it's a subjective measurement. I'd be very interested to see more research into this space and we can adjust the audit calibration accordingly. |
Corresponding issue - #3174
Failing audit (grouped by source, sorted by coverage):

*edge case - when font-size is inherited from parent and parent uses attributes style (e.g.

<font size=1>) we get no info about where the styles came from. Seems like a DT bug:Successful audit:
