Learn more:
goodgame or shorter gg is a huge trade-off to express neural networks and work with them in a new way. gg comes from e-sports and was the name of my team years ago, but more important, after a game the teams say gg for a good time, to make the long story short, gg treats neural networks like a good game.
The rules are simple, every training sample and every custom sample is trainable. The goal is to reach the highest accuracy for the untrainable test data.
Let me give a first example of a test:
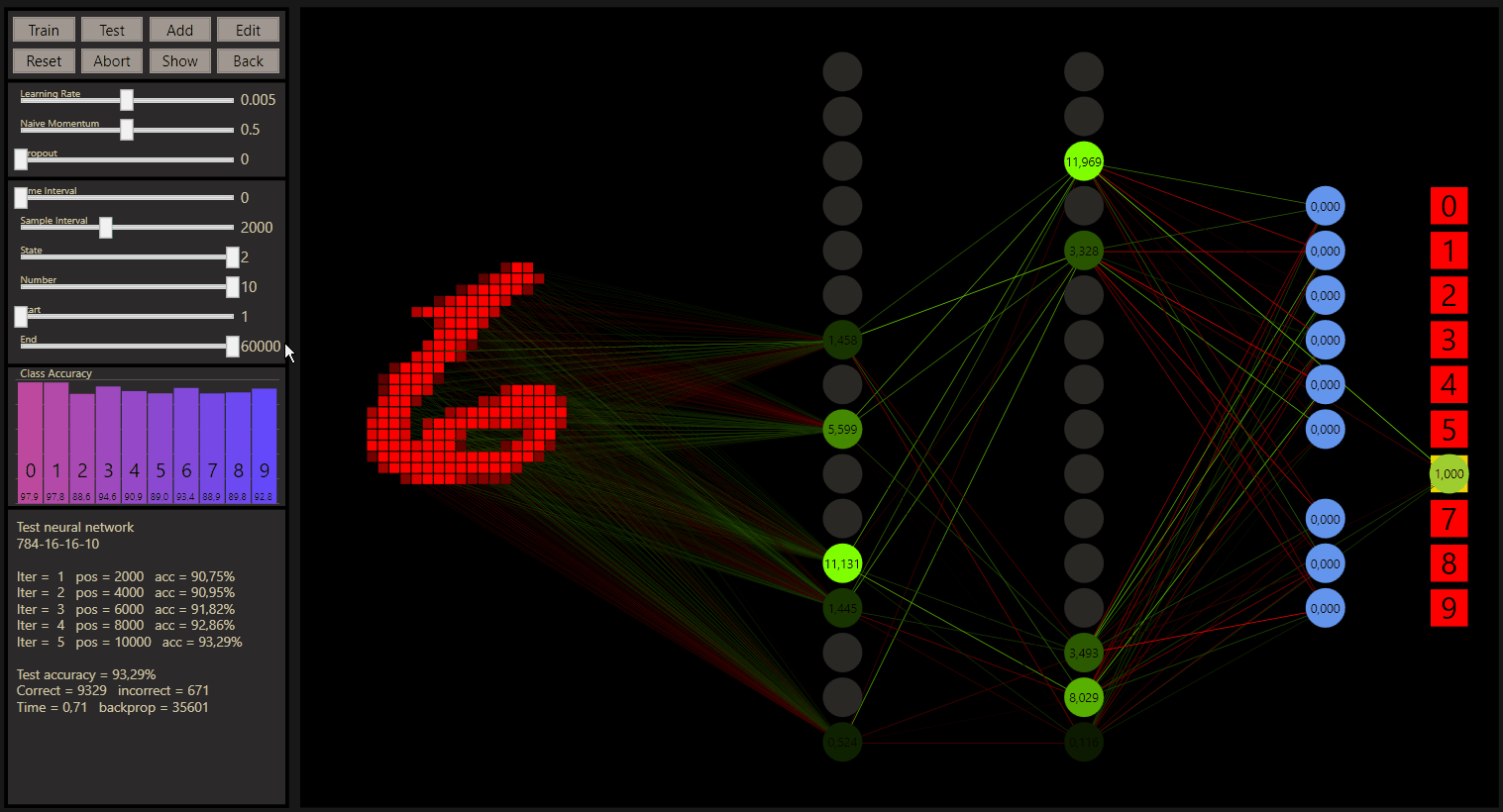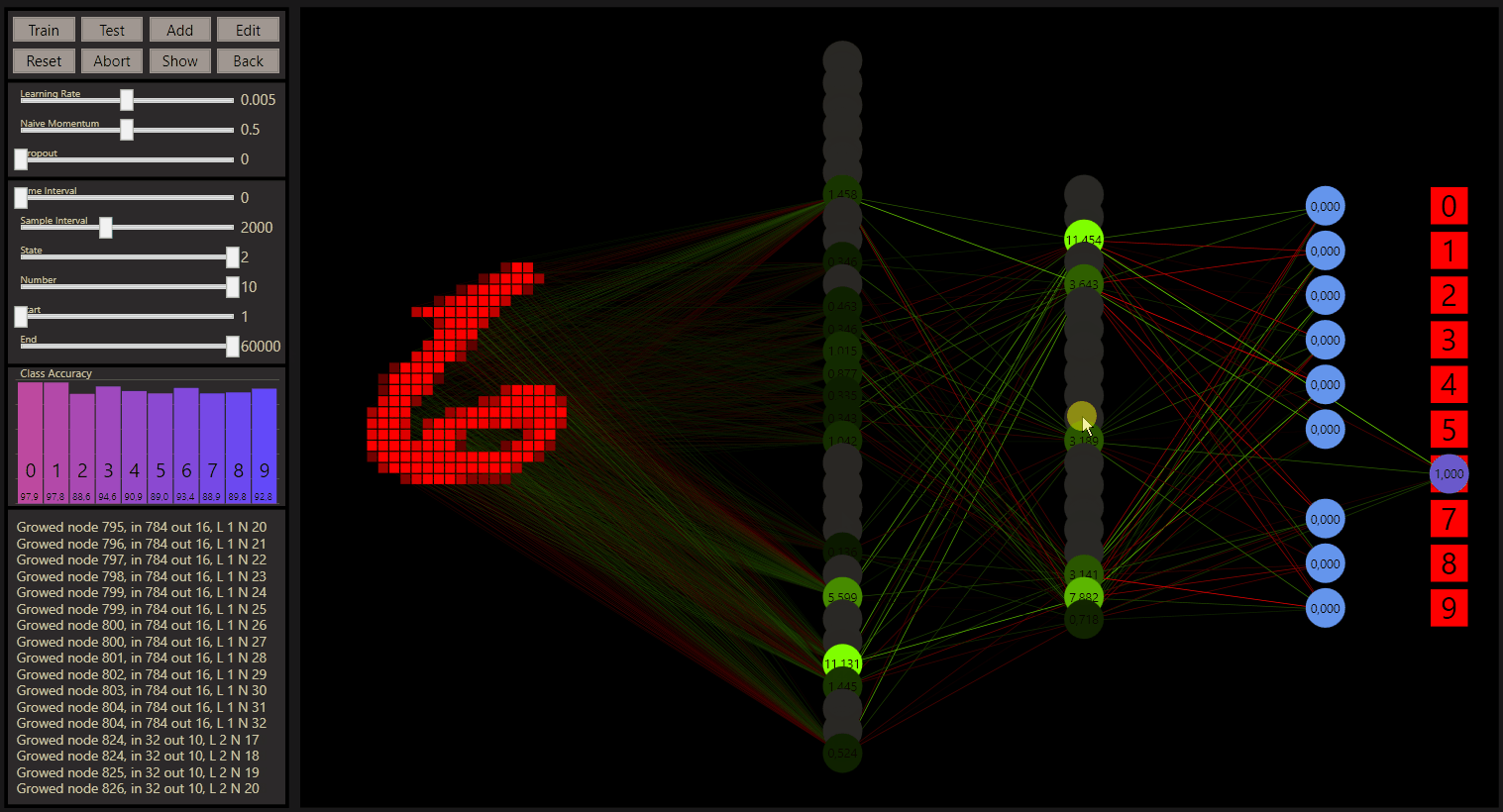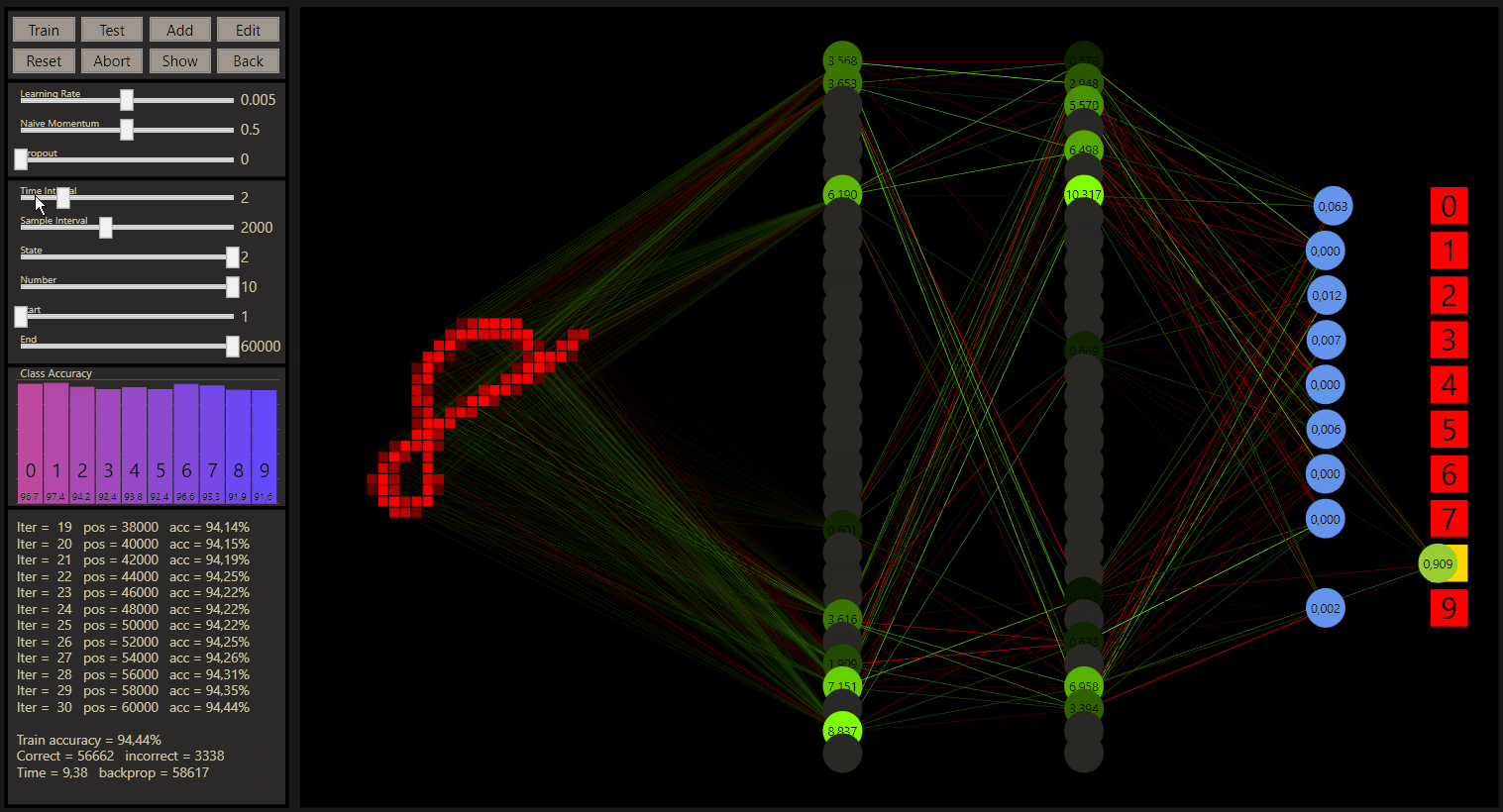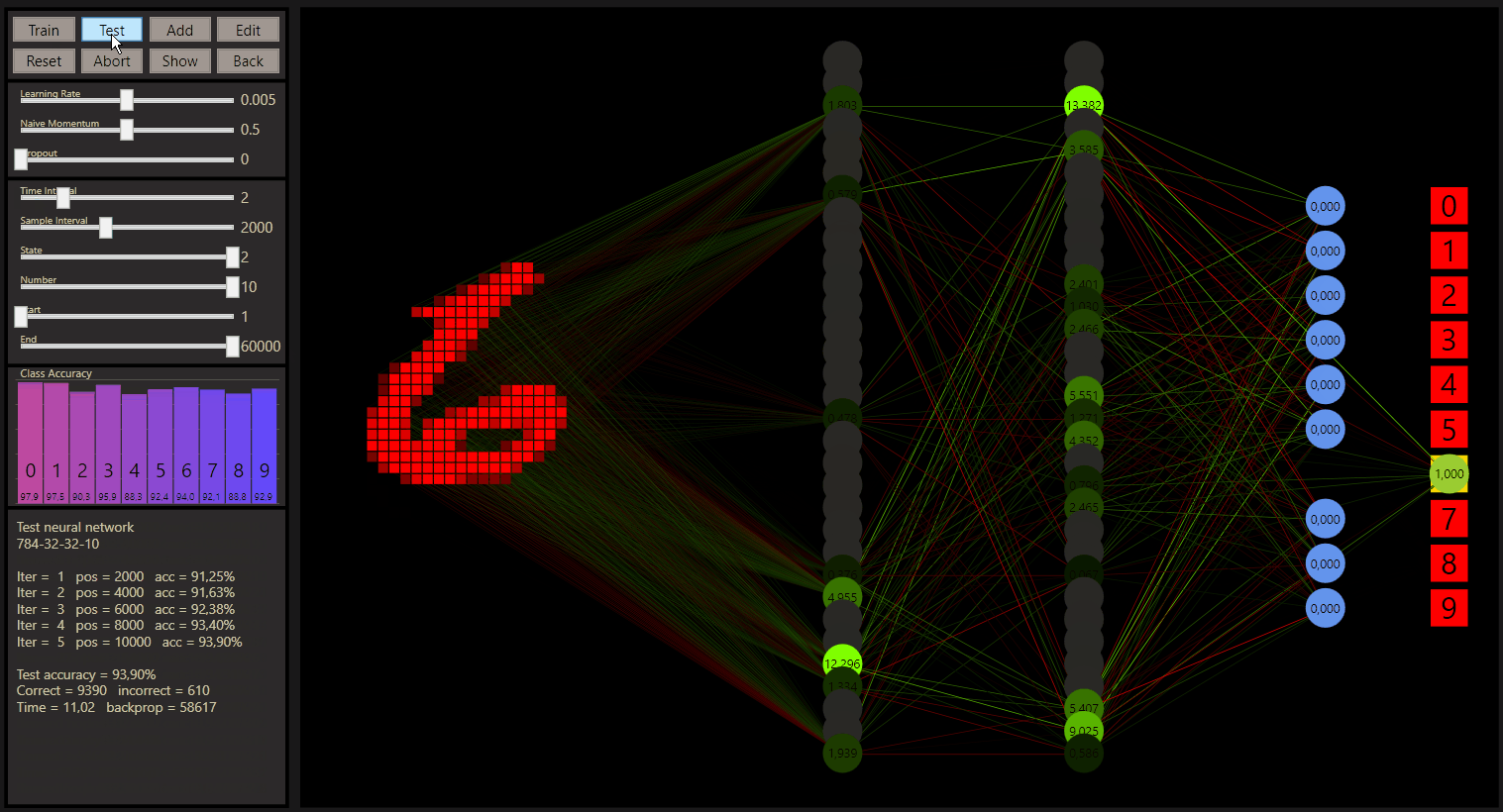
After a training of the 60.0000 samples of the MNIST trainind data set, the test accuracy with the standard neural network is 93.29%. A neural network is initiated with continuous random weight values to create a breaking symmetry, gg used the Glorot initialization to reach this. The neural network describes a unique seed. The weights use the seed to generate continuous random values, which is what a neural network needs. However, if you want to change the starting value, simply add or remove a neuron, then do a reset and restore the desired network.
Note: 784-16-16-10 + one training = 93.29% for the test.
If you watched the neural network series from 3Blue1Brown, you know the 784-16-16-10 neural network already. That's important because the starting point with goodgame is this network with the default hyperparameters.
Let's create a sample and train it:
 The interaction is more than the control panel, here I create my own input and train it on the right.
The interaction is more than the control panel, here I create my own input and train it on the right.
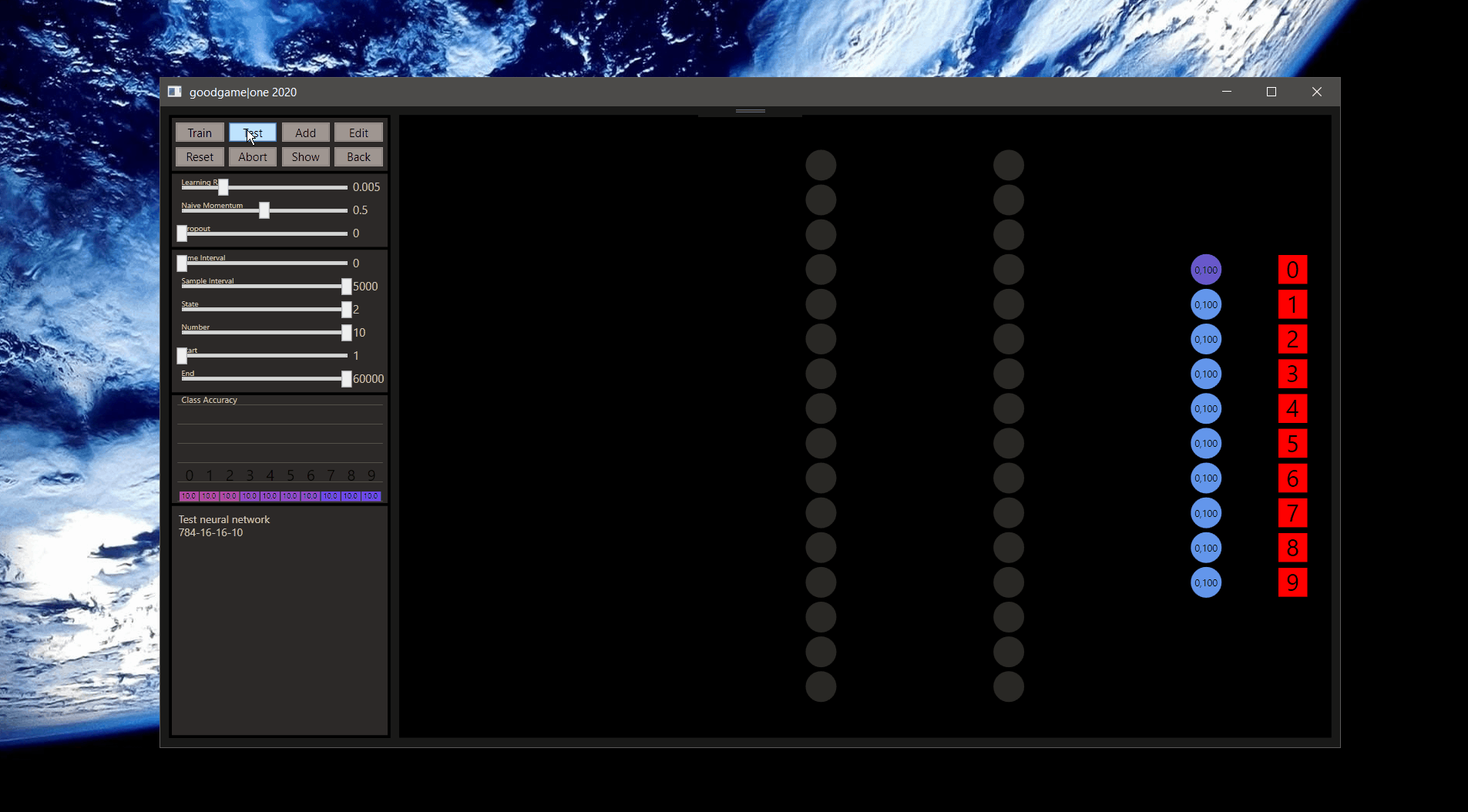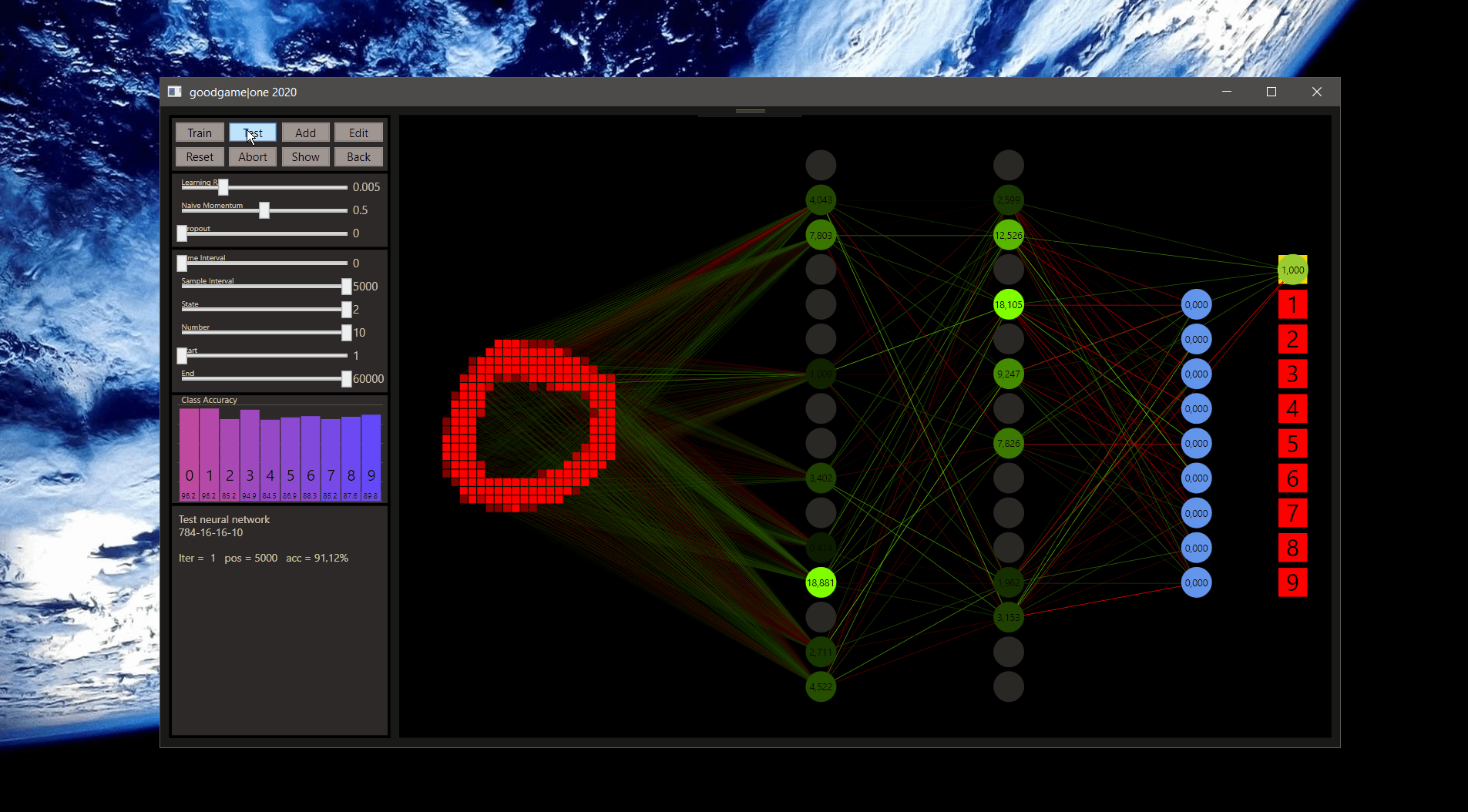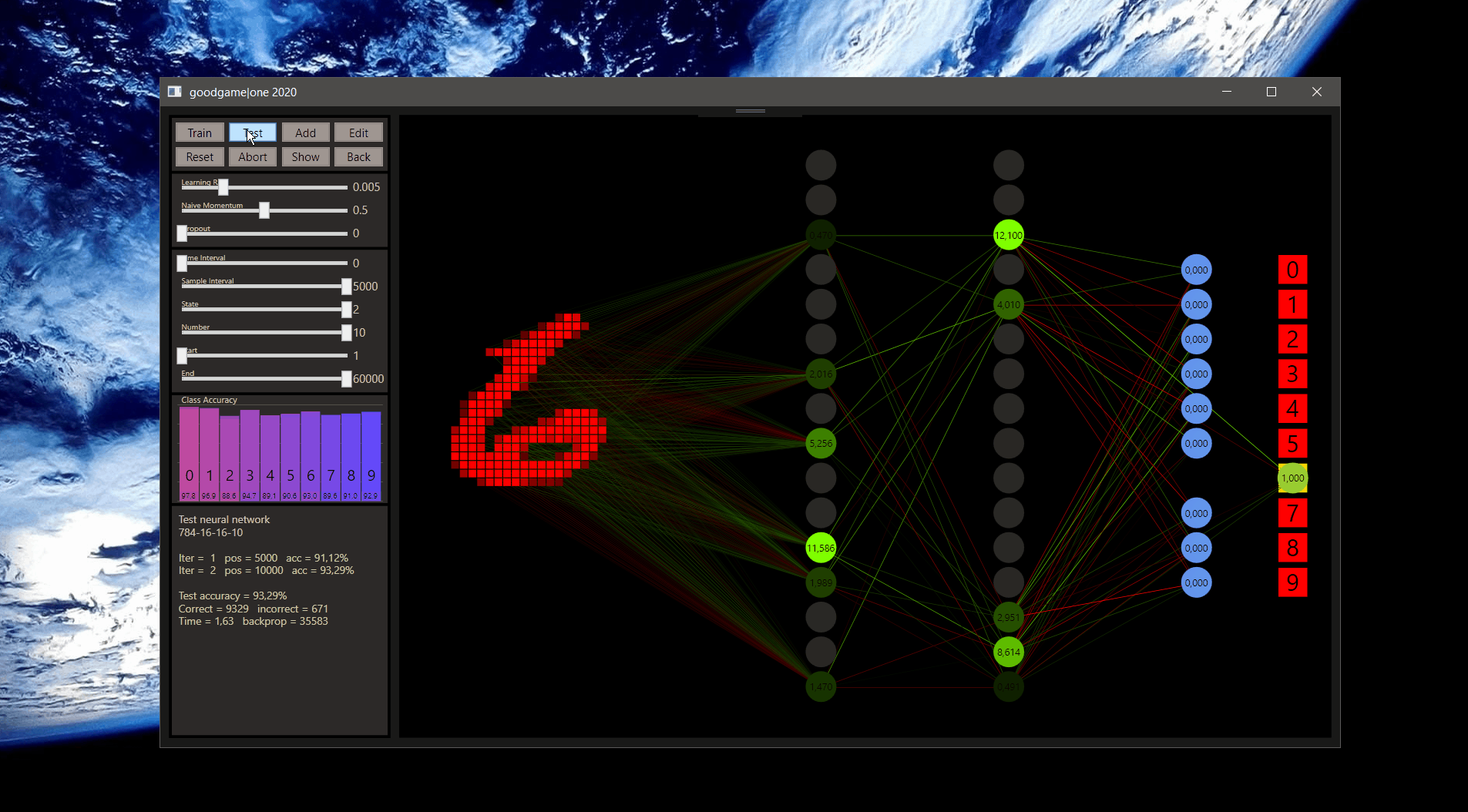
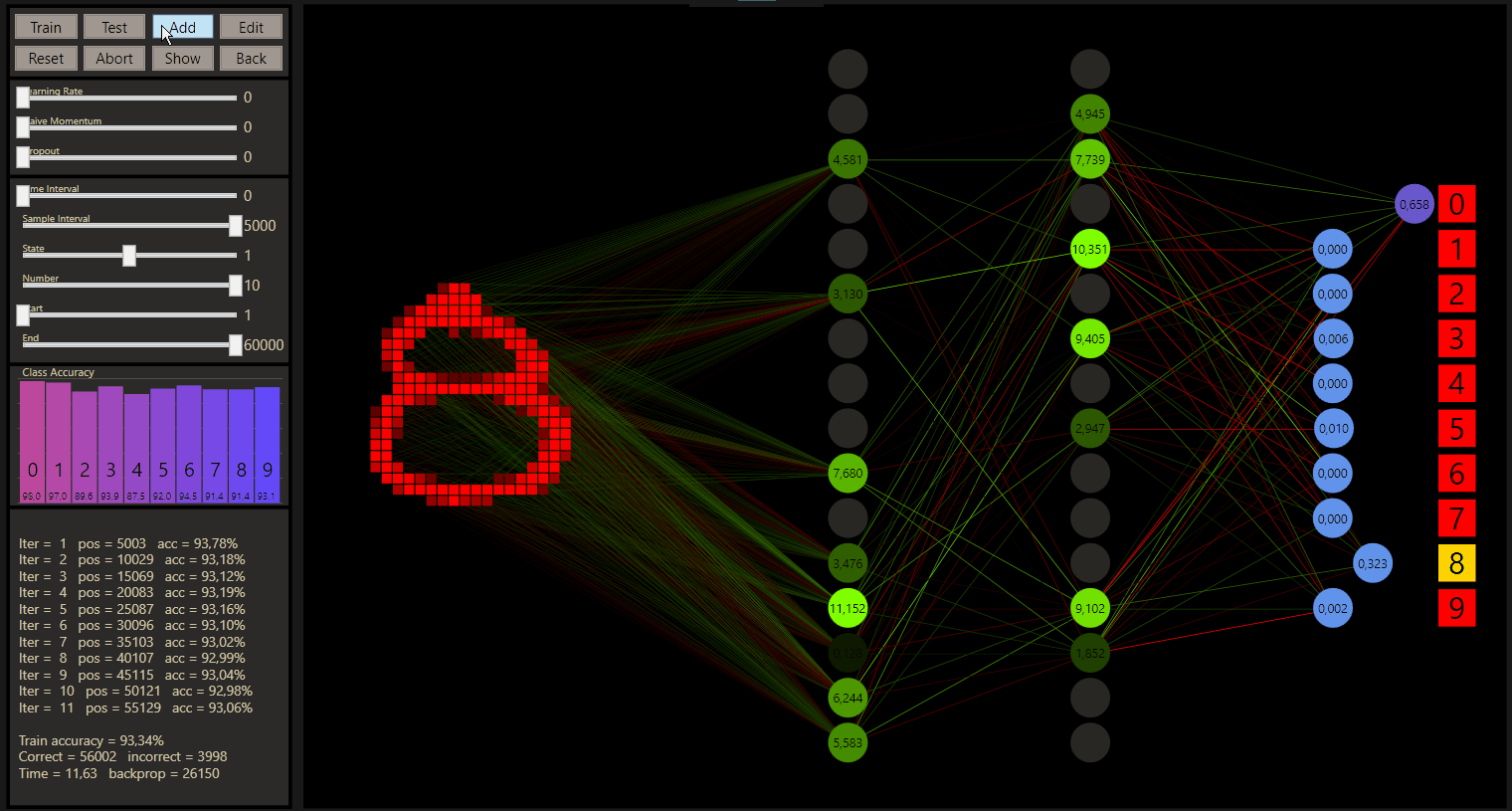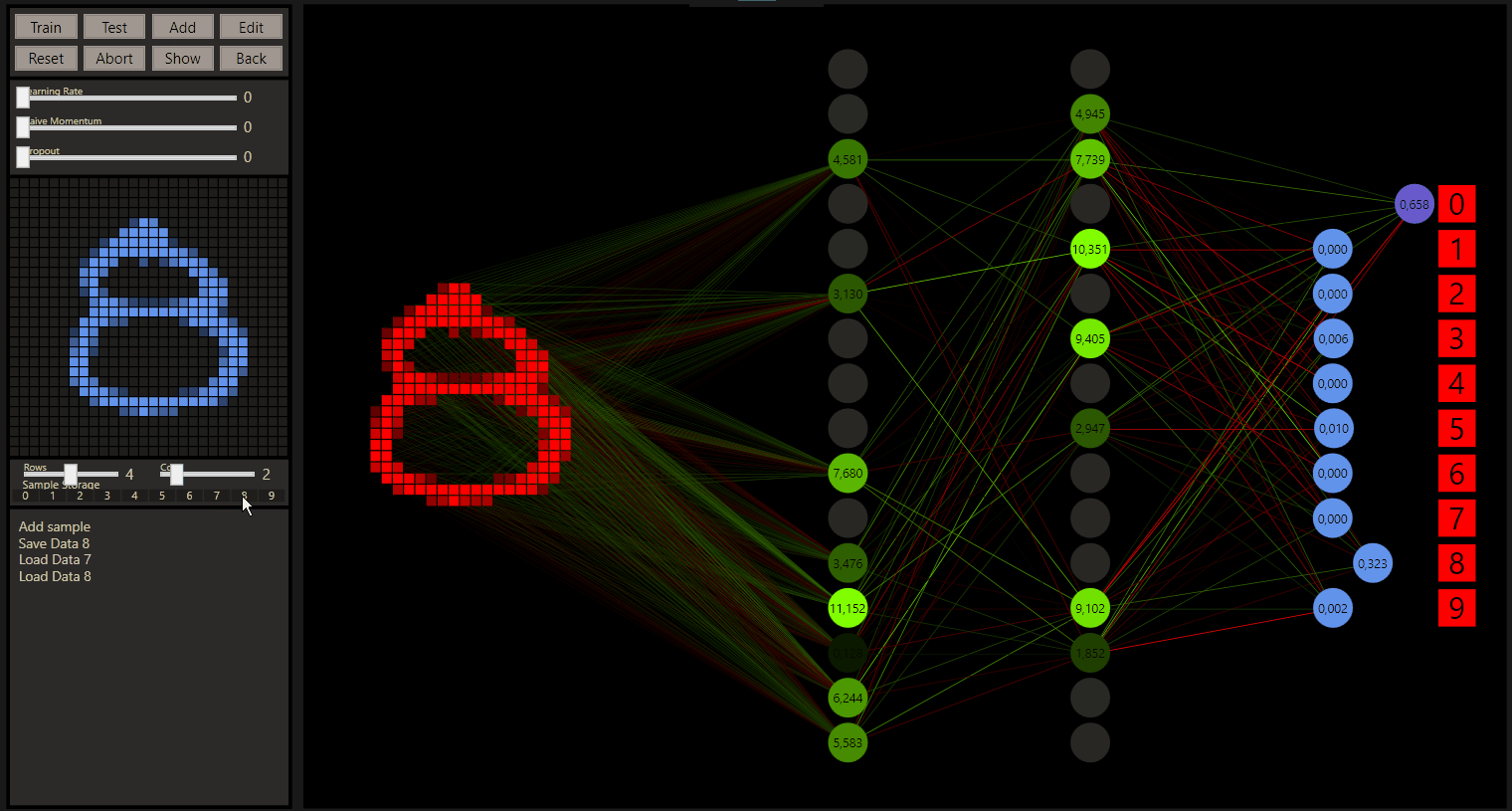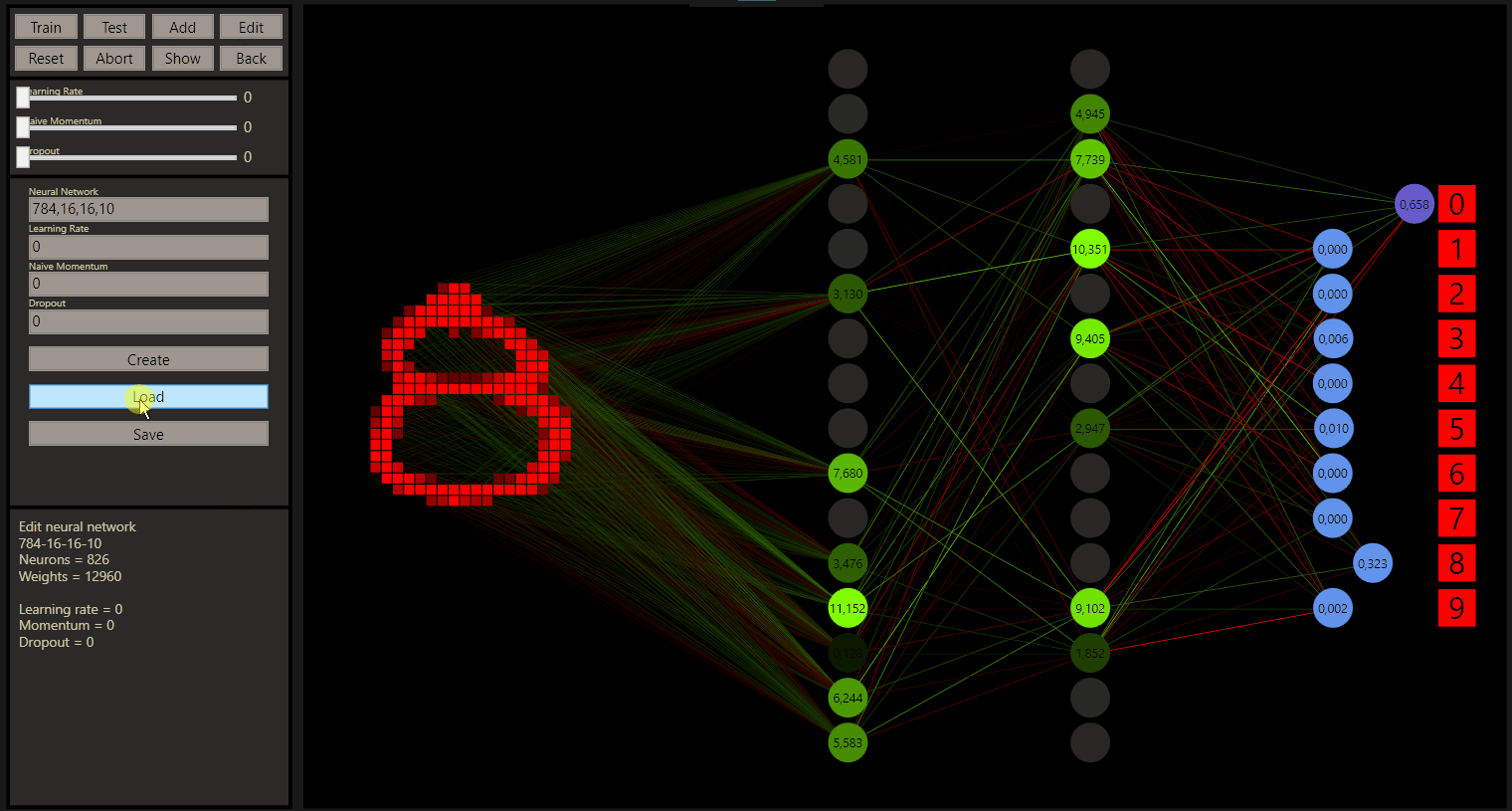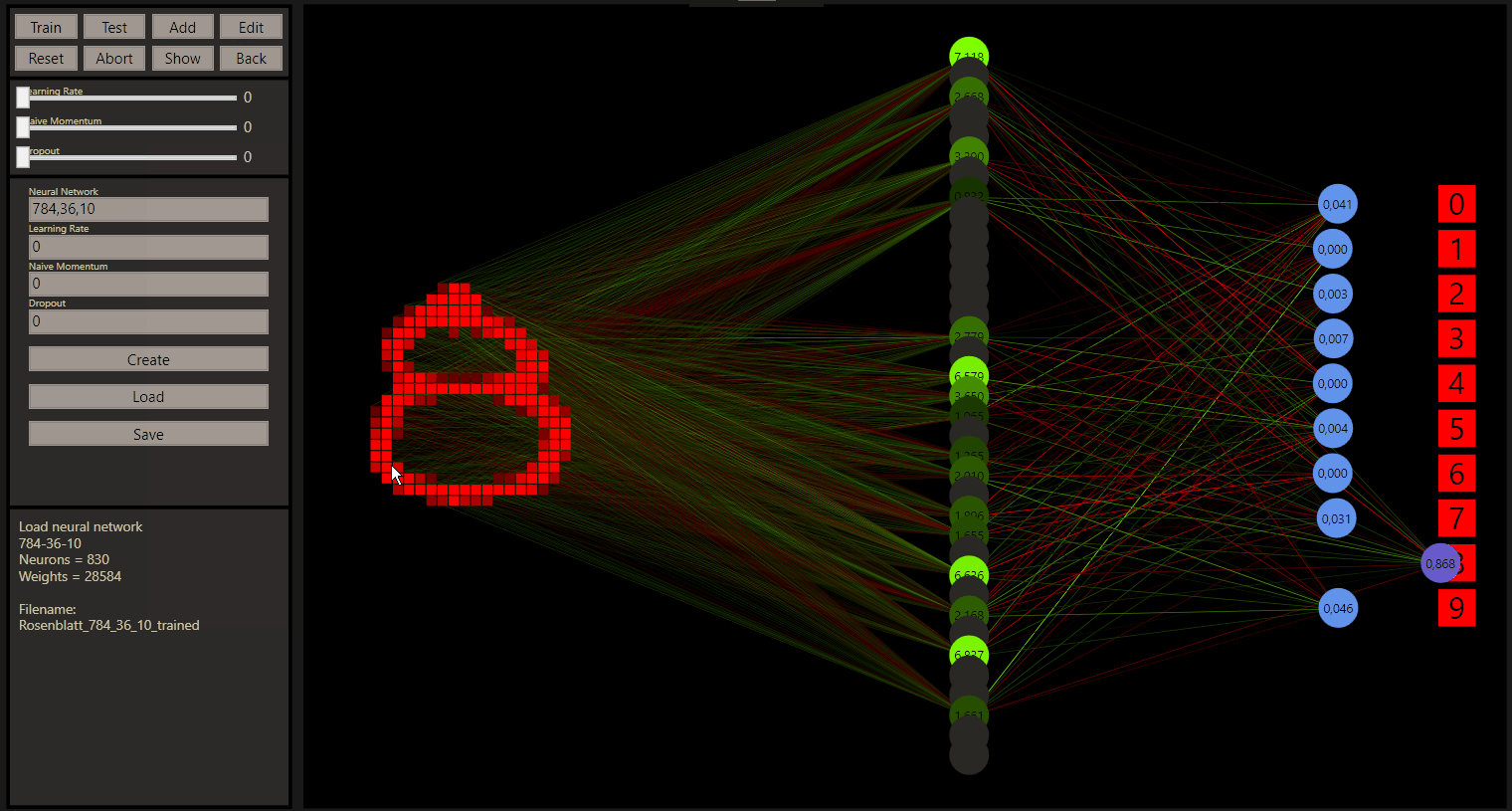
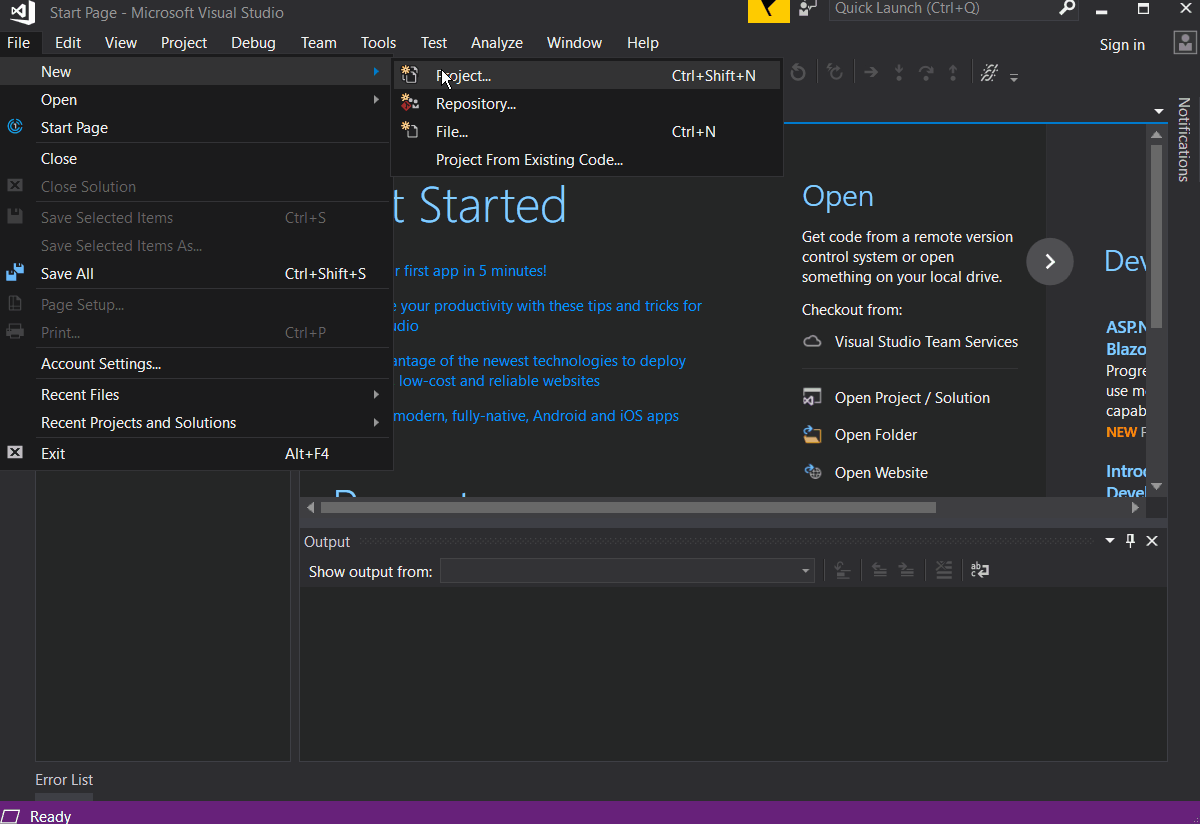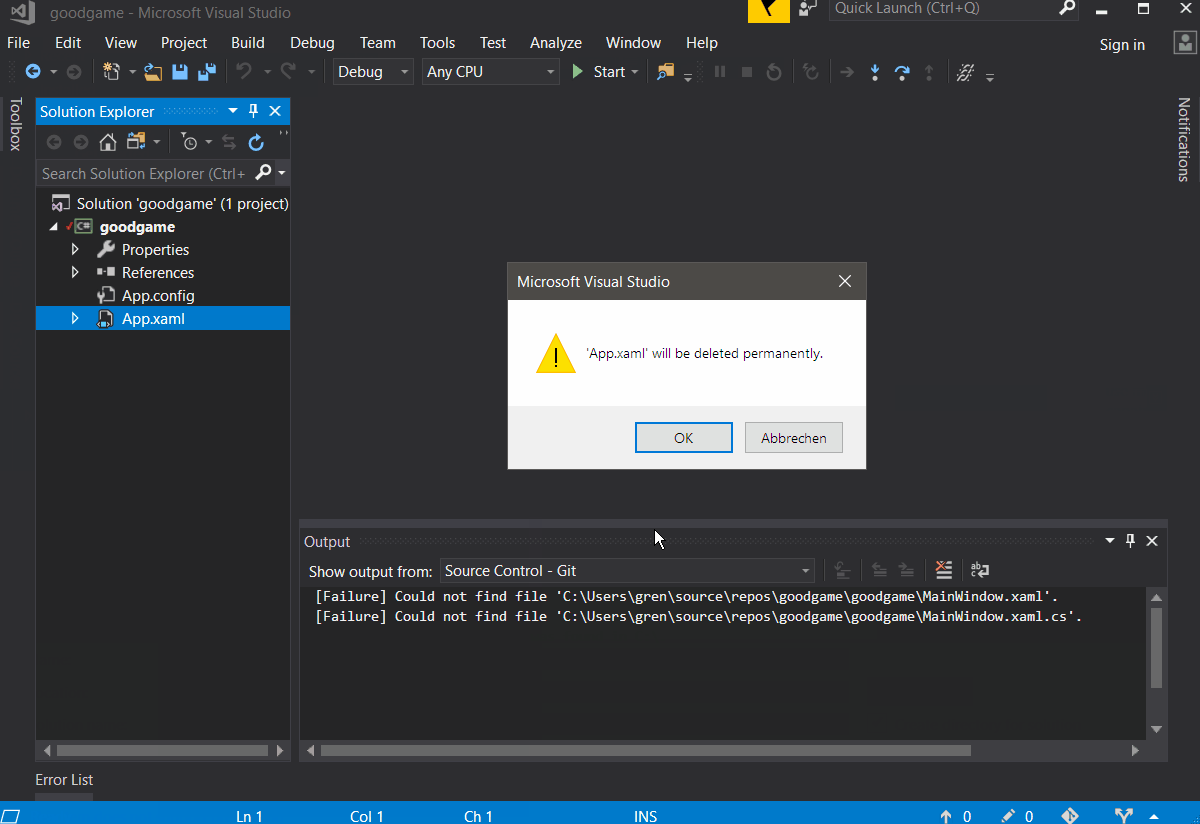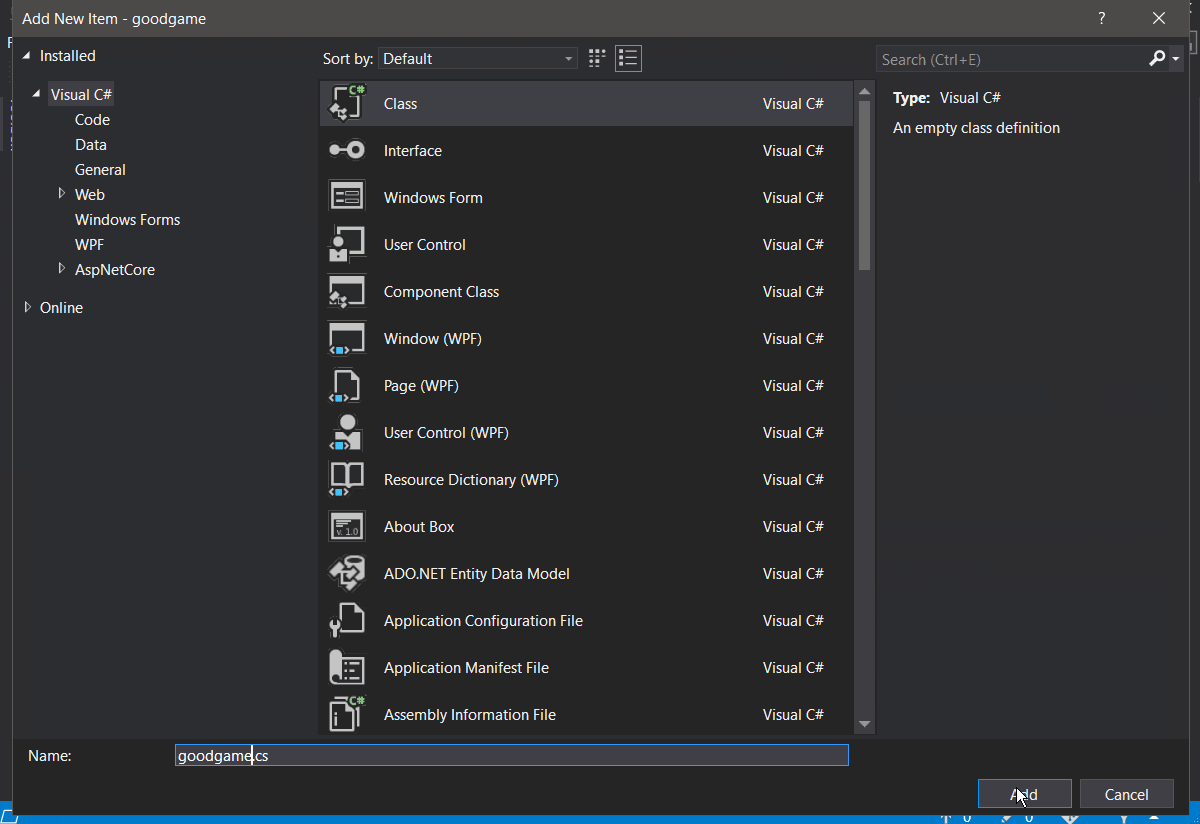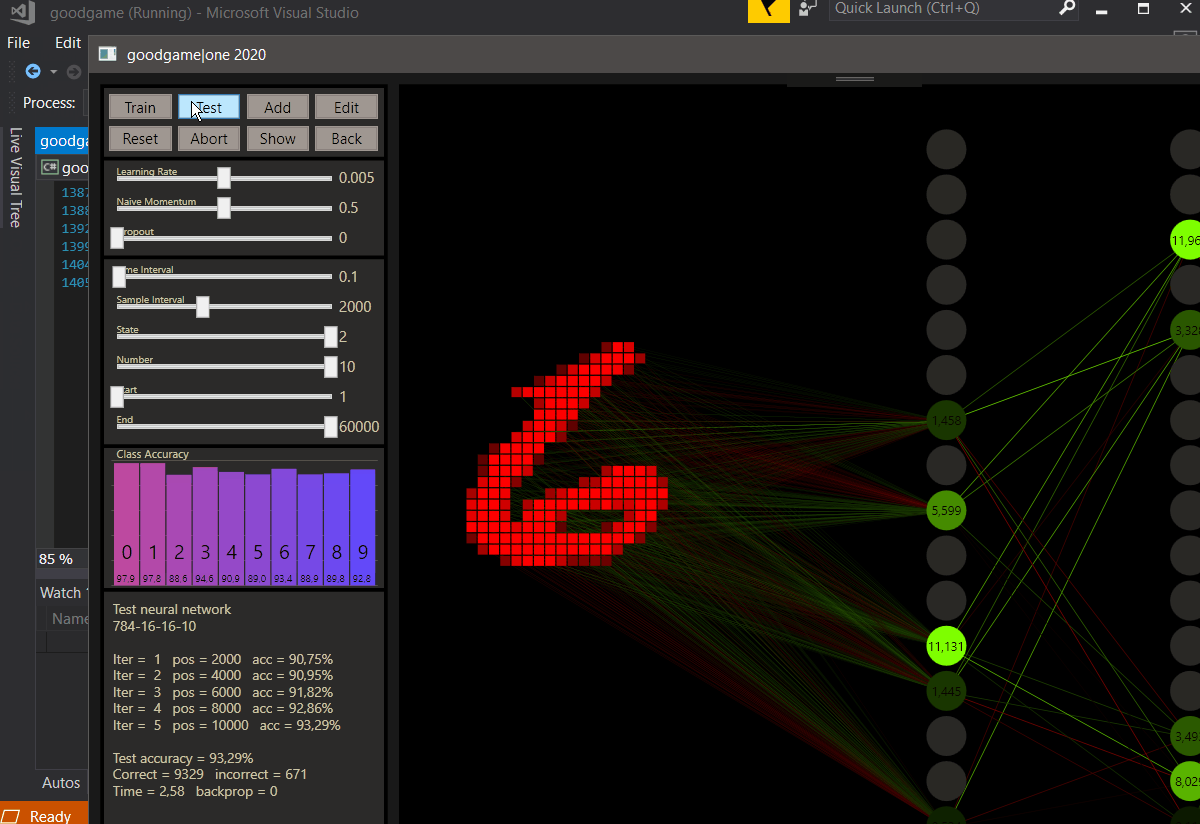
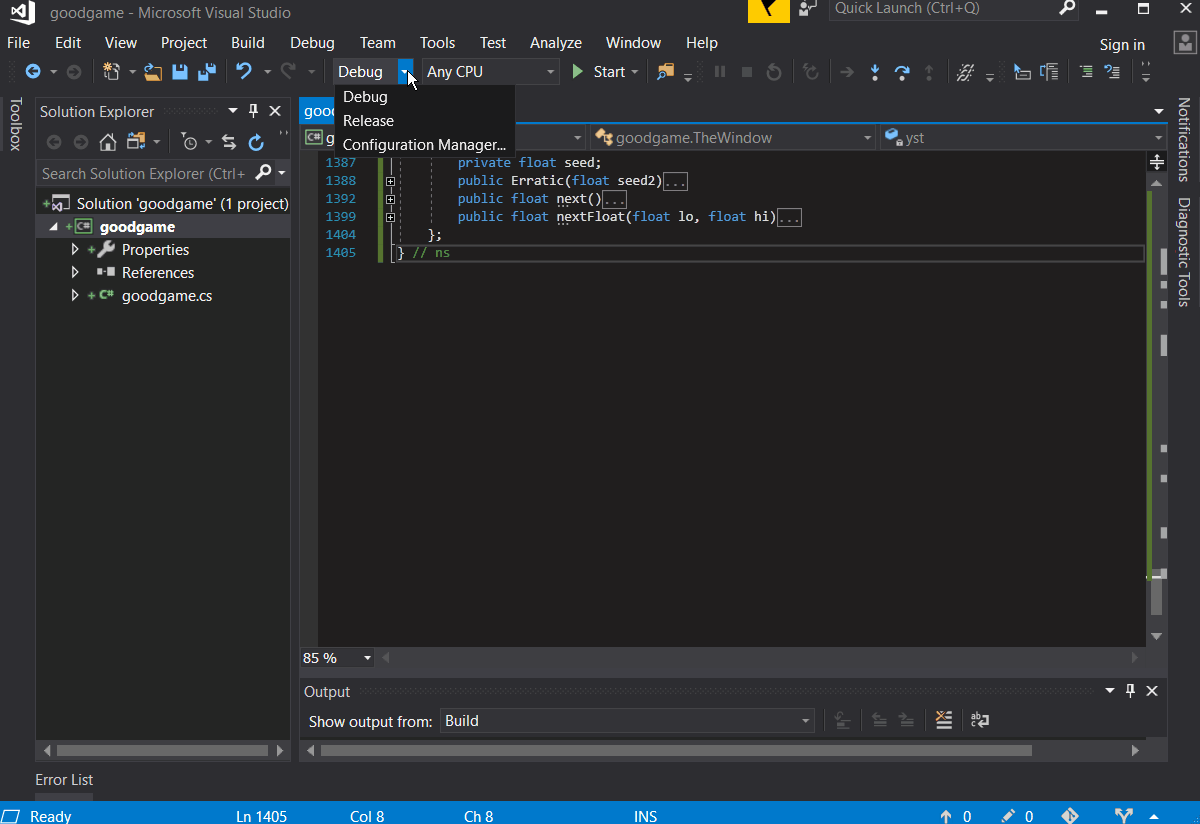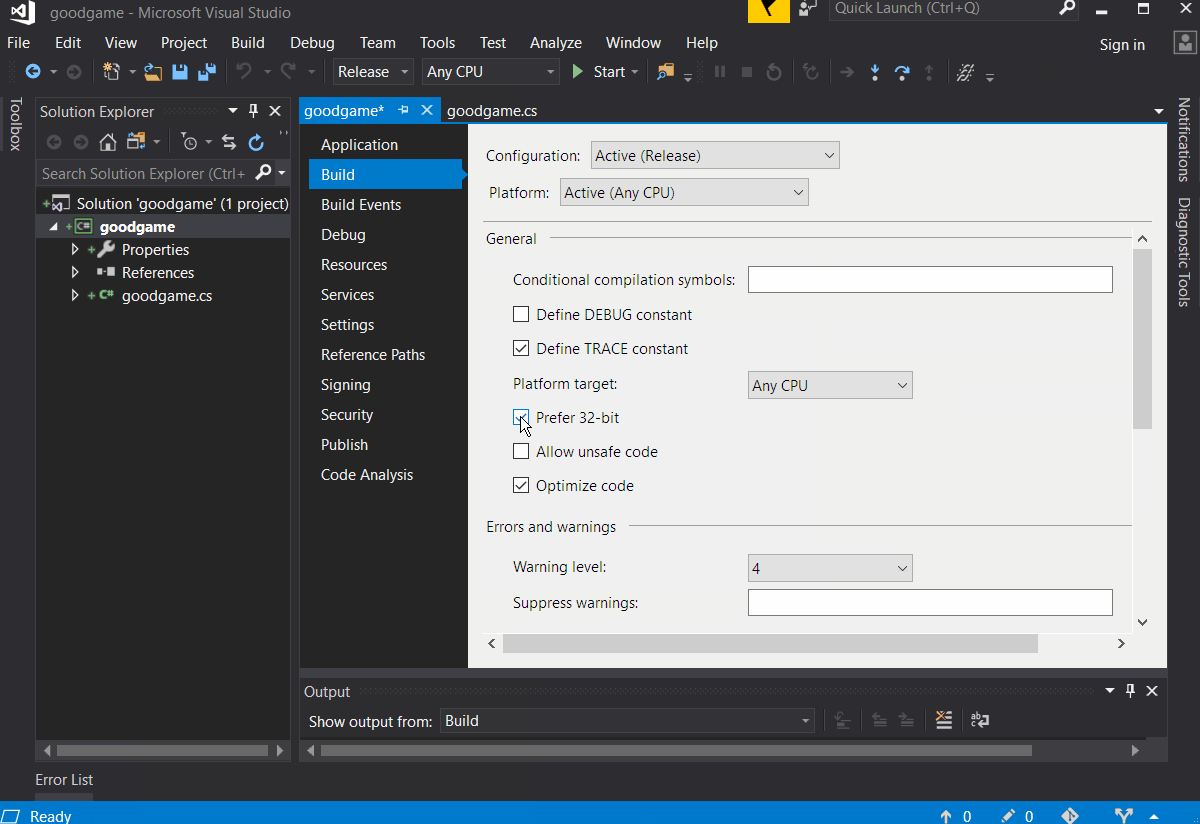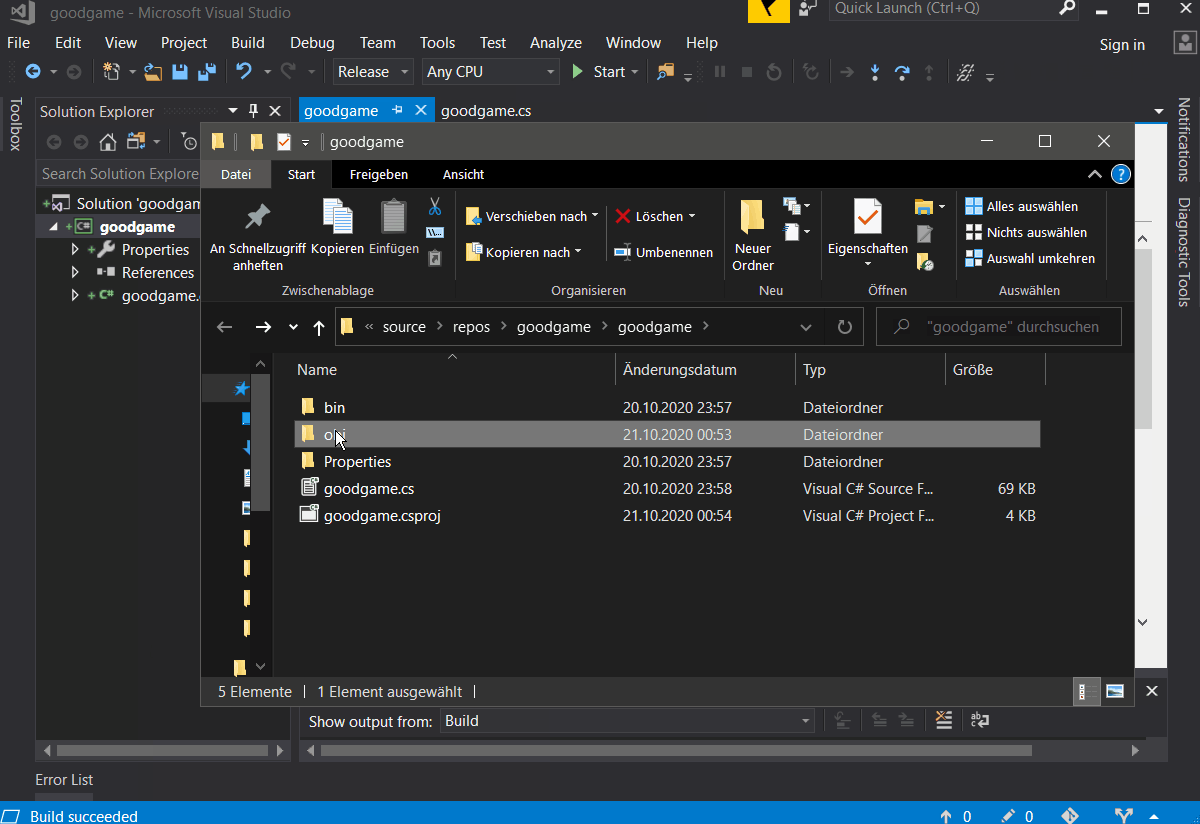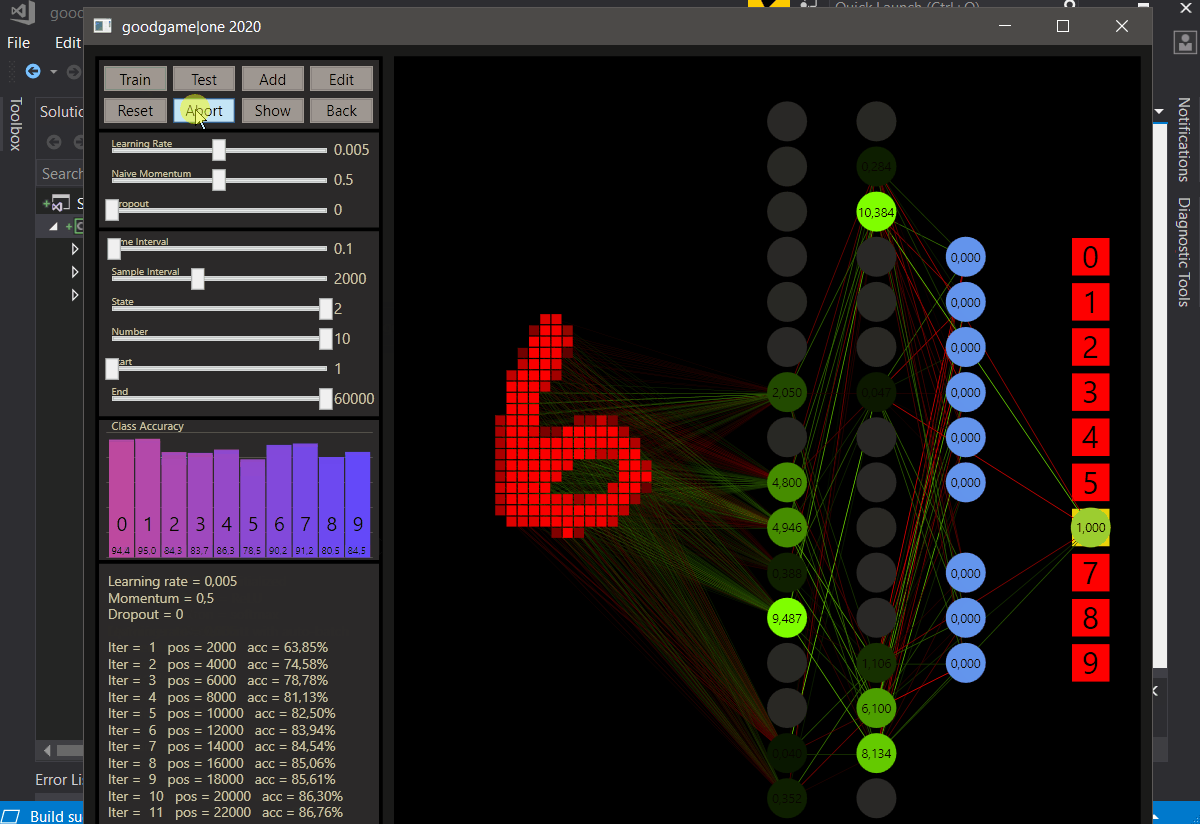
Before we go further let's checkout what goodgame can show, the input neurons are red rectangles on the left and express the samples. Every input neuron is fully connected with a weight to every output neuron on the next layer. The weights in green chartreuse show positive values and the reds show negative values. The highest or lowest color depends on the highest or lowest weight here and all other weights show colors between. Note, the values are the colors in a good, but not an exact way. If the highest weight value will be 1.01 on this layer, the range can be really big and values with 0.07 and 0.04 can show the same color.
The neurons show their connections only when they are ReLU activated, if the value was below 0 the neuron is set to 0. Here we can get a good feeling how the weights works, the highest neuron color represents also the highest neuron value that is figured on the neuron.
The output neurons with softmax activation shown on the right side use 100 pixels from left to right 0-100% to express the prediction accuracy. If the prediction was the target the neuron becomes green and the class gold.
 We can also spot what's going wrong. The state slider, correct = 0, incorrect = 1, all = 2. In combination with the other sliders every data is easily accessible. The sliders can be controlled by the left and right arrow keys on the keyboard too. For example, to determine the start of training between 60.000 samples. 59916 seems a 7, or?
We can also spot what's going wrong. The state slider, correct = 0, incorrect = 1, all = 2. In combination with the other sliders every data is easily accessible. The sliders can be controlled by the left and right arrow keys on the keyboard too. For example, to determine the start of training between 60.000 samples. 59916 seems a 7, or?
Despite goodgame is kept really low with basic ideas and not a special neural network, the functionality can come really complex. I was looking for a way to make it intuitiv to play. So with a left click you can put something in, with a right click you can take something out.
We can test the networks with our own samples:
 The Sample Storage can load a sample with a left click, or saves a sample with a right click. If the storage was empty, you would reset the sample with a left click on this storage.
The Sample Storage can load a sample with a left click, or saves a sample with a right click. If the storage was empty, you would reset the sample with a left click on this storage.
So we can also create, load and save our neural networks. Additional goodgame saves after a close and loads after a start your neural network automatically. So you can do really strange things and compare the networks with specific examples.
Another example of the functionality:
The quantum leaps of neural networks:
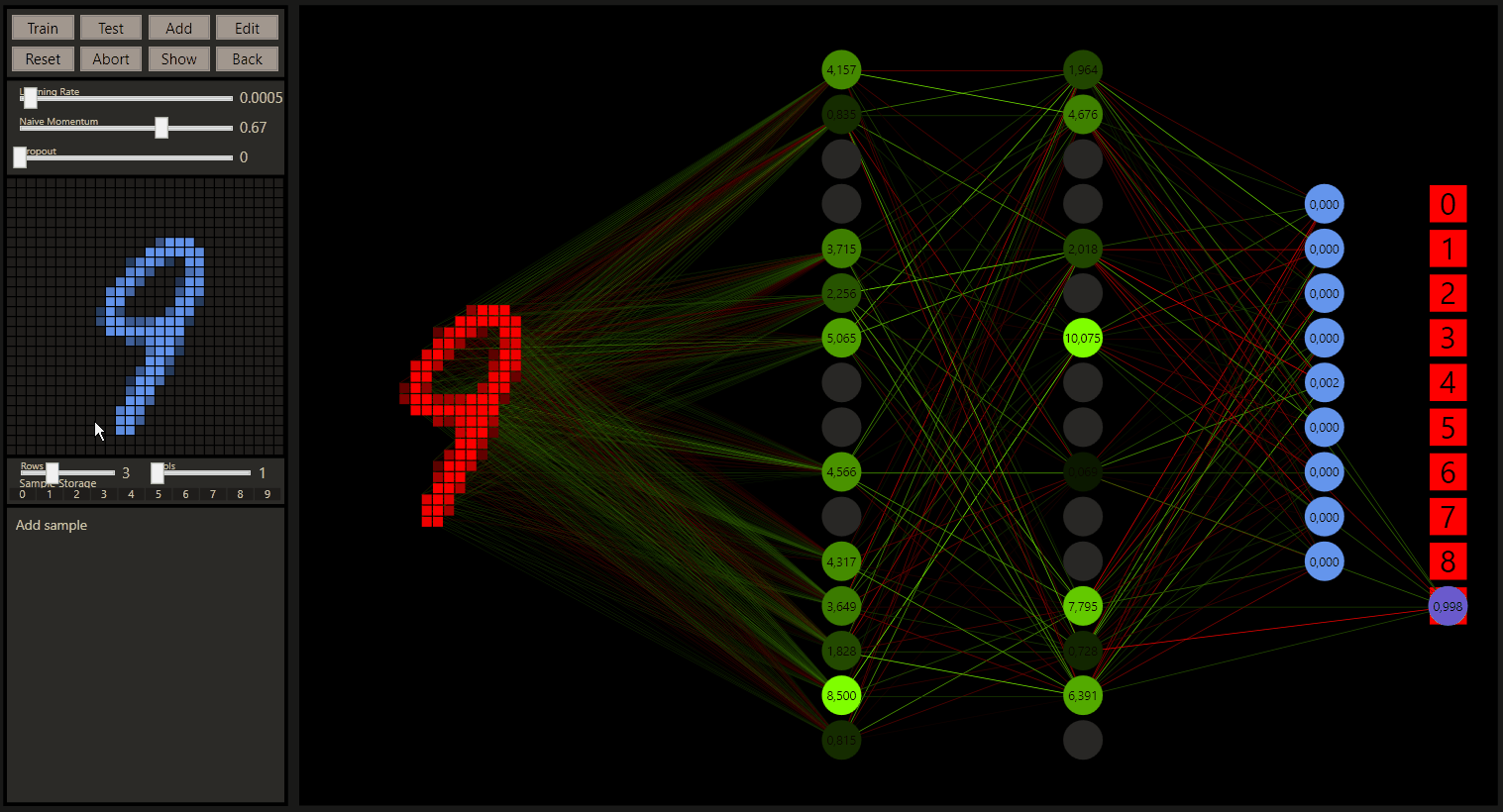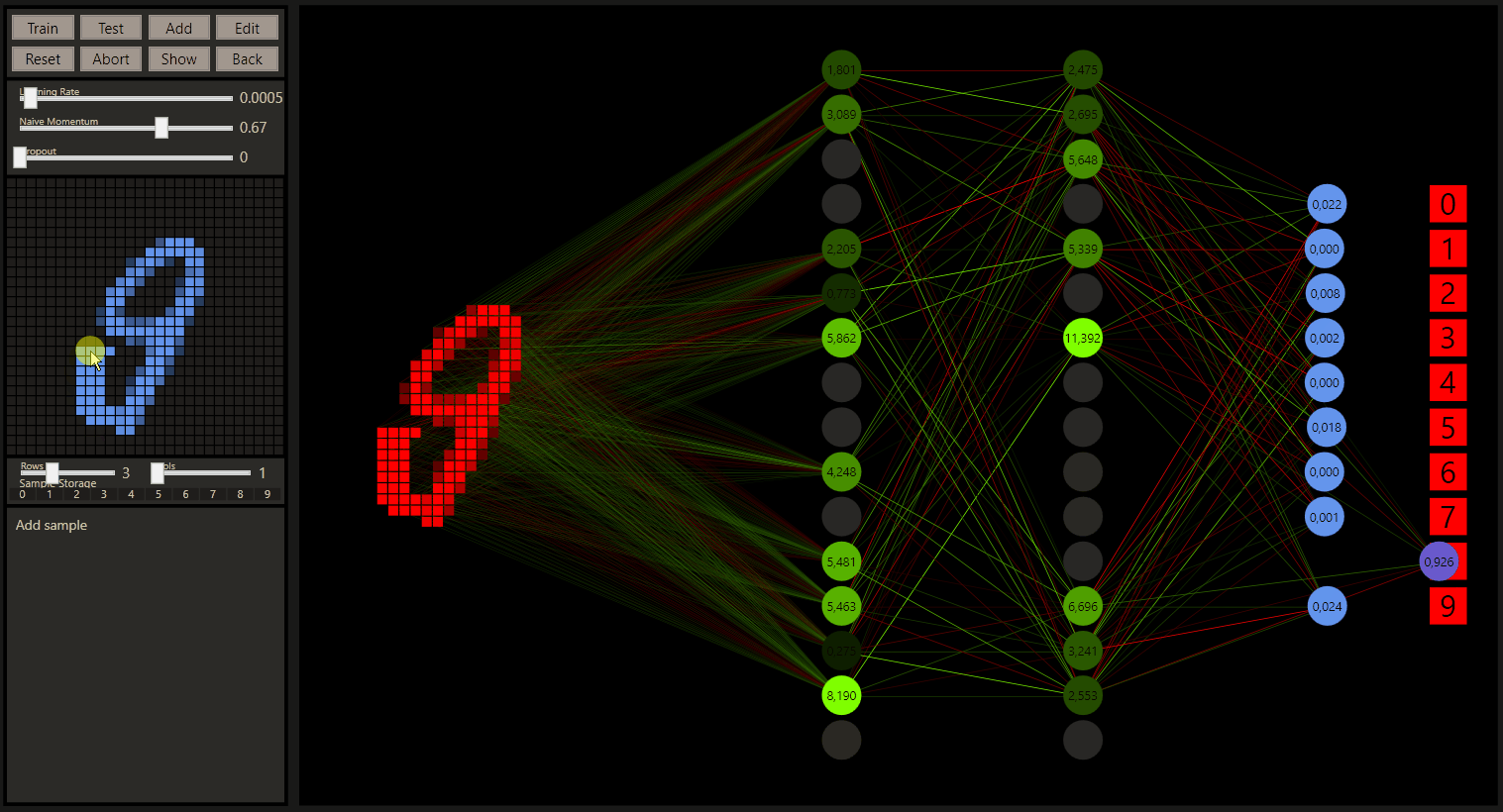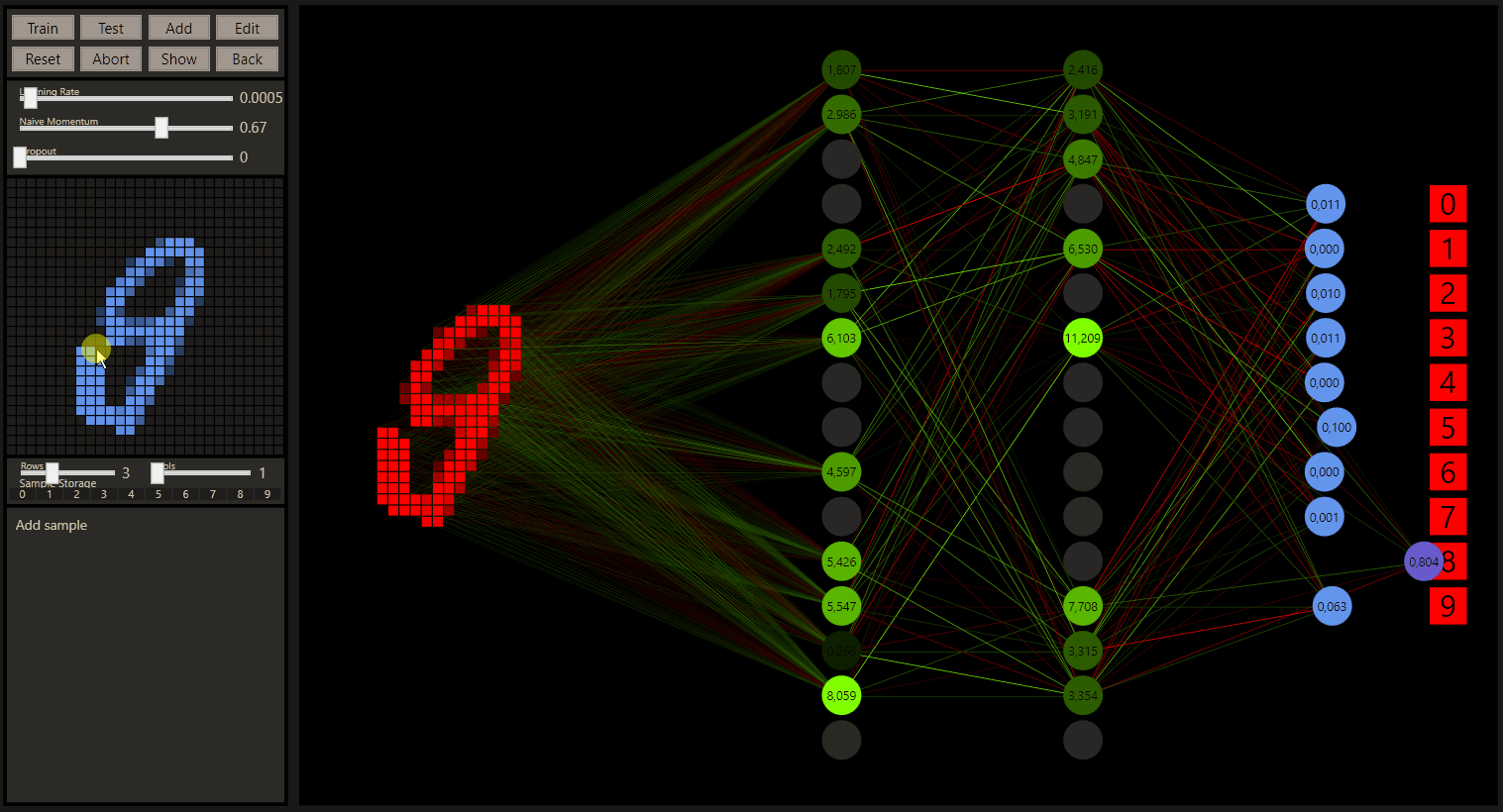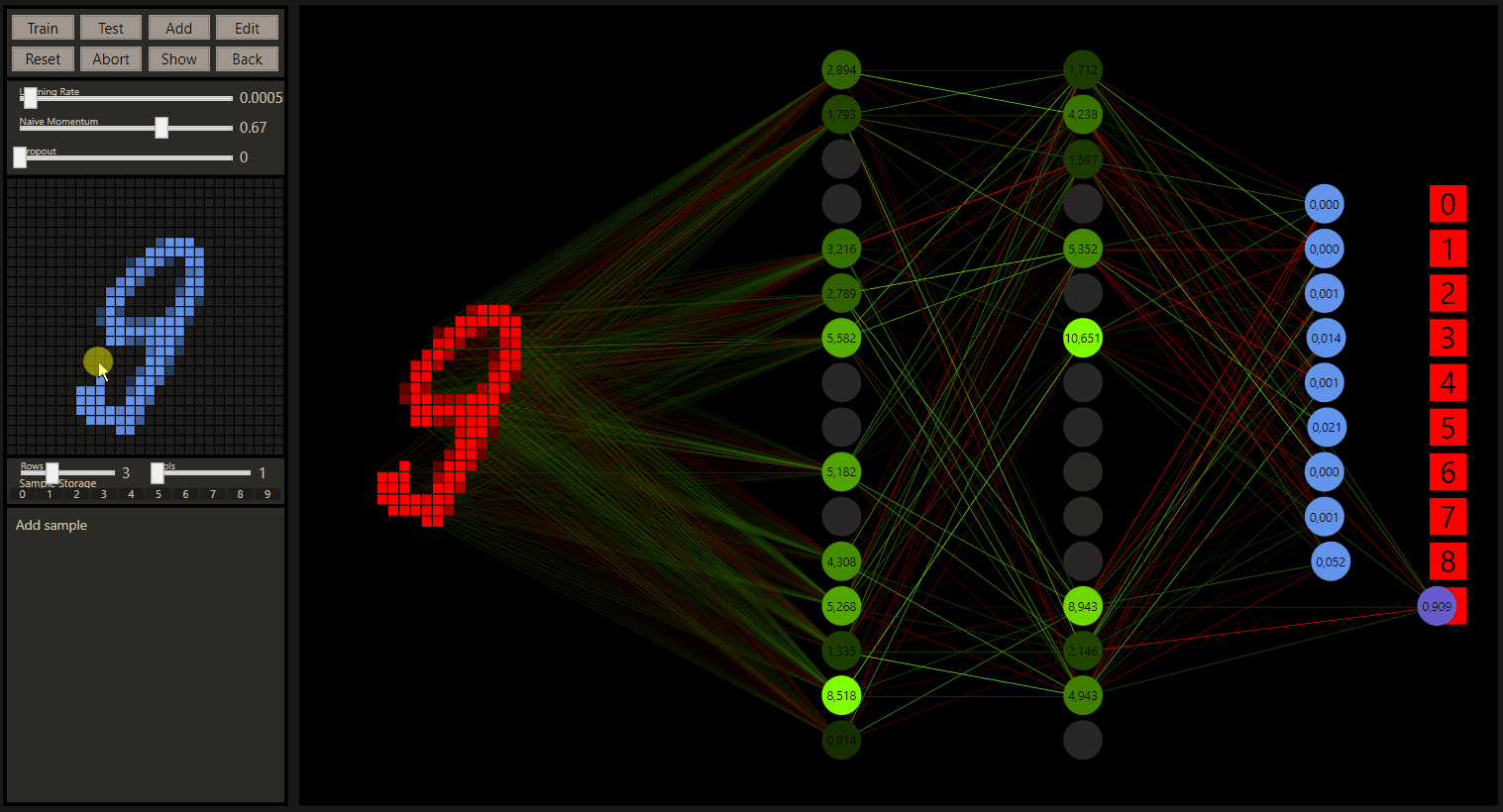
How the prediction moves from one class to the next has been one of the most interesting things to me. Further transformations, from '8' to '6' and from '6' to '5' can provide even more insights about the classes and their relationship.
The quantum leaps of neural networks or just the change in classification of the nearby input increases the understand of neural networks a lot. Especially the intuition how the prediction was made and how we would evaluate this as a human.
What can one hidden neuron predict:
 The Class Accuracy on the left shows the prediction of each class. The question was, how many hidden neurons are needed to handle the data? The demo shows a test till a 784-7-10 network. The experiments can go further, but the 784-3-10 network suprised me most, but 784-4-10 network can handle all data in my opinion
The Class Accuracy on the left shows the prediction of each class. The question was, how many hidden neurons are needed to handle the data? The demo shows a test till a 784-7-10 network. The experiments can go further, but the 784-3-10 network suprised me most, but 784-4-10 network can handle all data in my opinion
Logistic regression is like a neural network with one layer, the parameters to compute are here 784 * 10 = 7840 + 10 for the bias = 7850. A neural network with one layer like the 784-7-10 computes 784 * 7 + 7 * 10 = 5558 parameters without a bias in the case of gg and can outperform logistic regression. Efficency is a core of gg, with one more layer, 784-7-100-10 network would compute 6188 parameters, but how would we rate a 784-6-50-10 network with 5504 parameters? A very important aspect if we think about how we should build our networks for more efficiency, but also for the prediction quality.
Train inside the training:
 *It is time for popcorn, take your seat and manipulate the predictions, train with your intuition within the training.
*It is time for popcorn, take your seat and manipulate the predictions, train with your intuition within the training.
Maximize the layer size:
 How many layers can we train? This is a deep neural network with 20 layers. It was really hard to train, but the pattern of the neurons looks pretty cool.
How many layers can we train? This is a deep neural network with 20 layers. It was really hard to train, but the pattern of the neurons looks pretty cool.
The effect of the learning rate:
 The learning rate affects the training. In case of the ReLU activation, the learning rate affects also the activation level of the neurons, lower lr's keep the activation level high, and high lr's keep the activations low, till a whole layer is disconnected. The example shows a briefly look into the test low = 0.001 vs high = 0.01 after 200.000 backpropagations, even with this moderate settings is this effect easy to see.
The learning rate affects the training. In case of the ReLU activation, the learning rate affects also the activation level of the neurons, lower lr's keep the activation level high, and high lr's keep the activations low, till a whole layer is disconnected. The example shows a briefly look into the test low = 0.001 vs high = 0.01 after 200.000 backpropagations, even with this moderate settings is this effect easy to see.
Push the weakest class in your training:
 How to increase the weakest class prediction. If the step was wrong, take the last training step and try again. It looks not so good for the others classes after this move, but with a lot of sensitive it's possible to support your network with specific training.
How to increase the weakest class prediction. If the step was wrong, take the last training step and try again. It looks not so good for the others classes after this move, but with a lot of sensitive it's possible to support your network with specific training.
Change the conditions:
 How would the the neural network perform with only three classes to predict? Experiments like this are not very useful, on the other they could bring new perspectives. I didn't expect this test accuracy after only one training, neat.
How would the the neural network perform with only three classes to predict? Experiments like this are not very useful, on the other they could bring new perspectives. I didn't expect this test accuracy after only one training, neat.
Add a bunch of neurons:
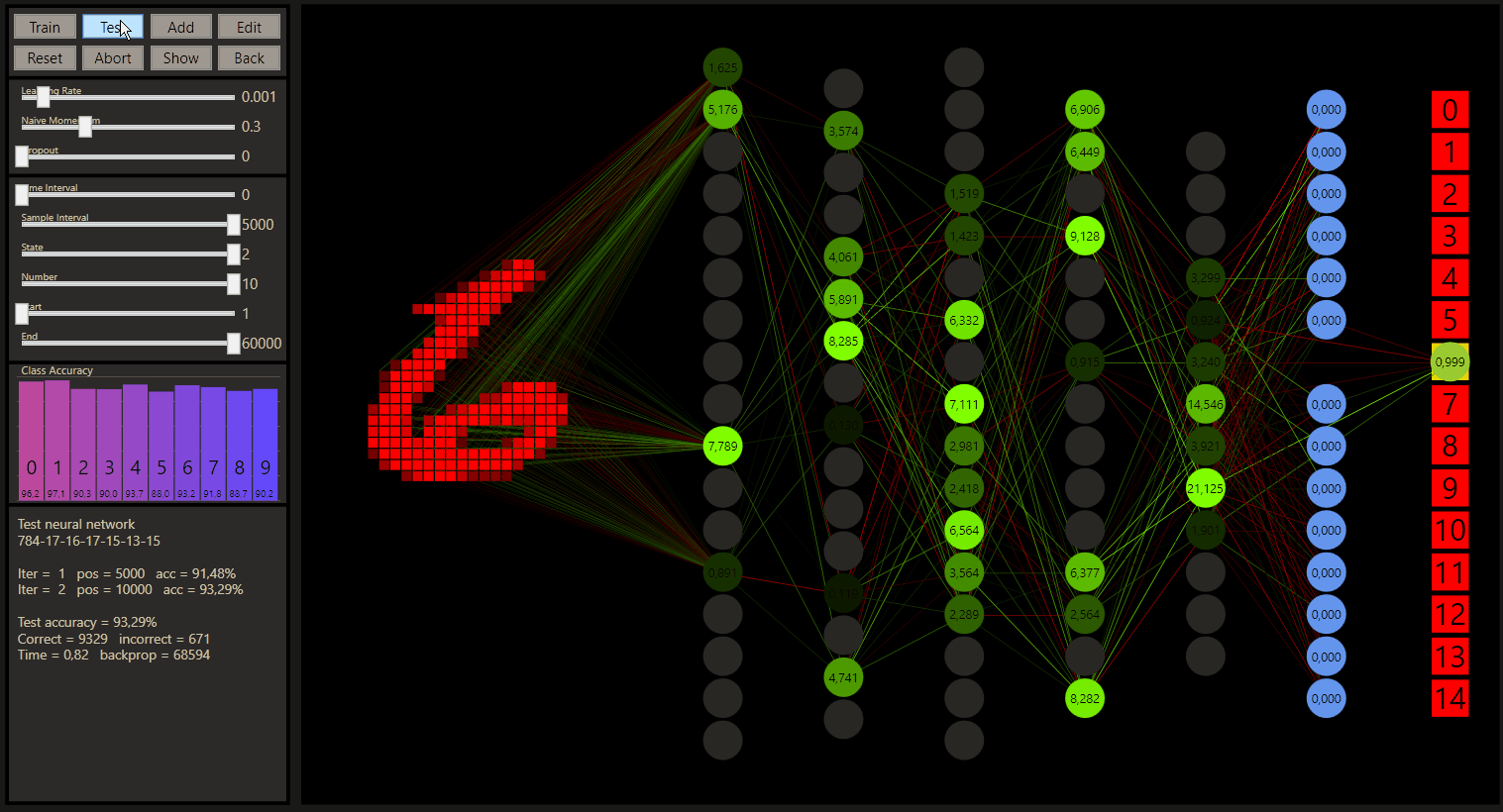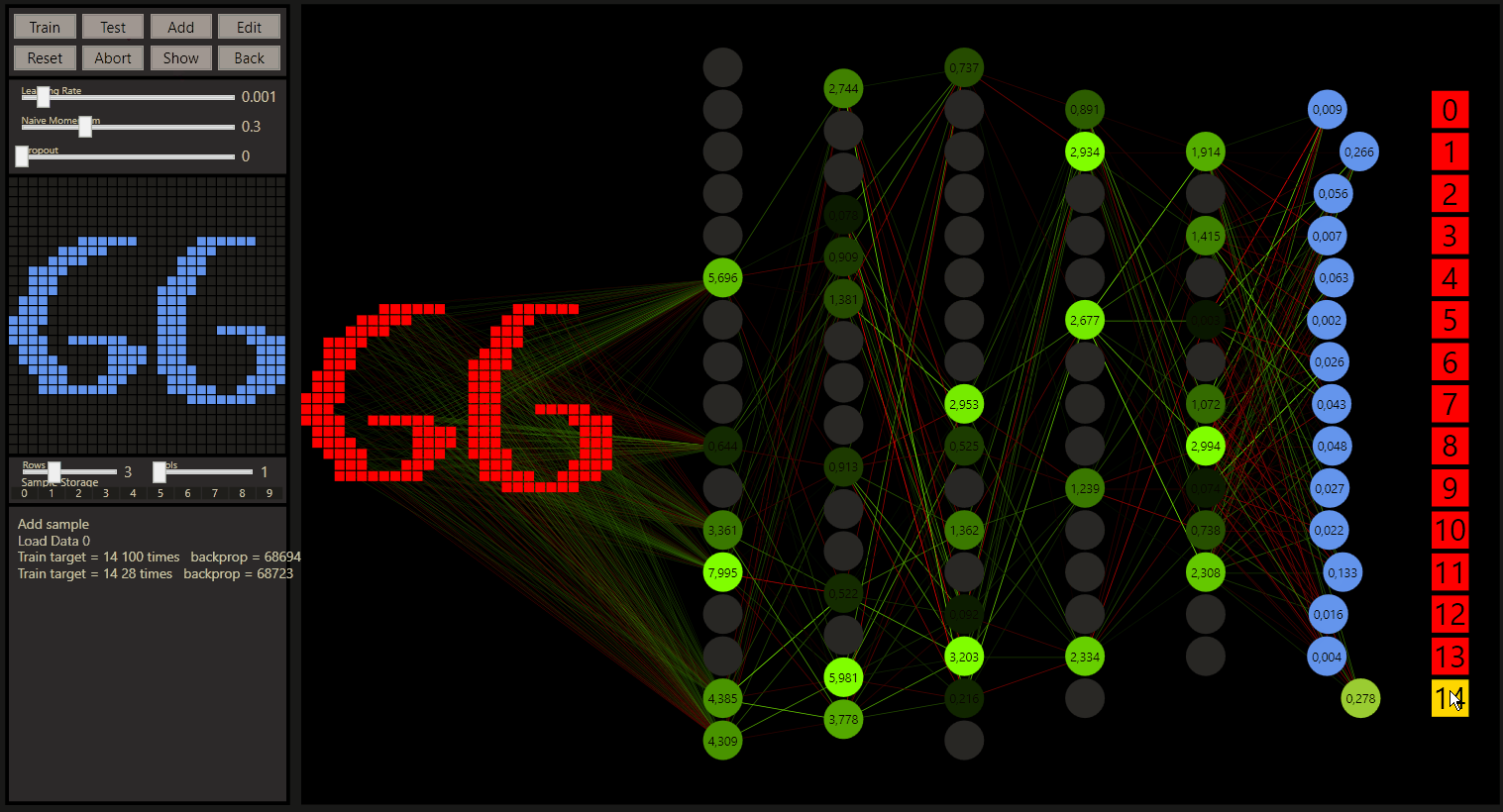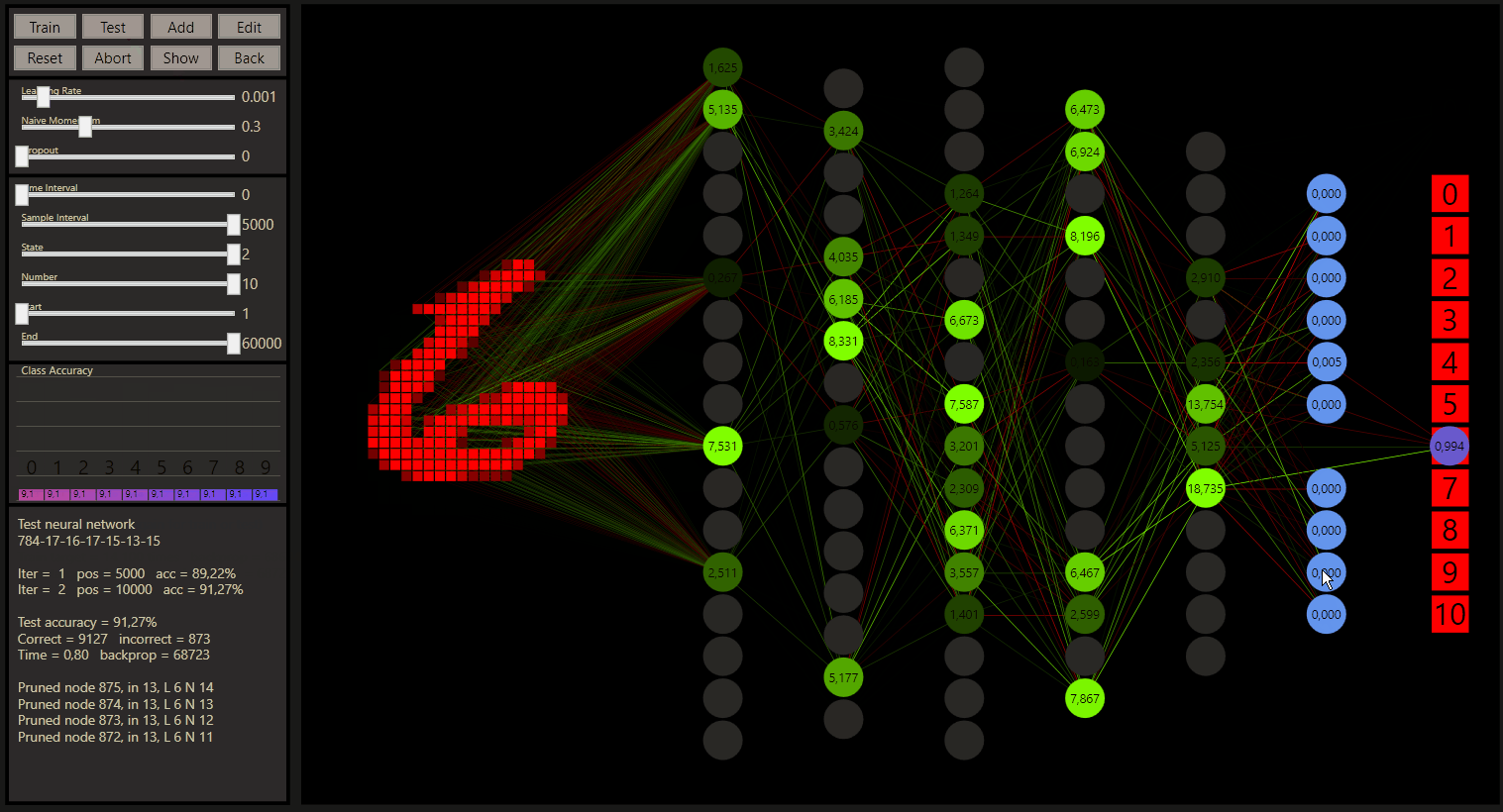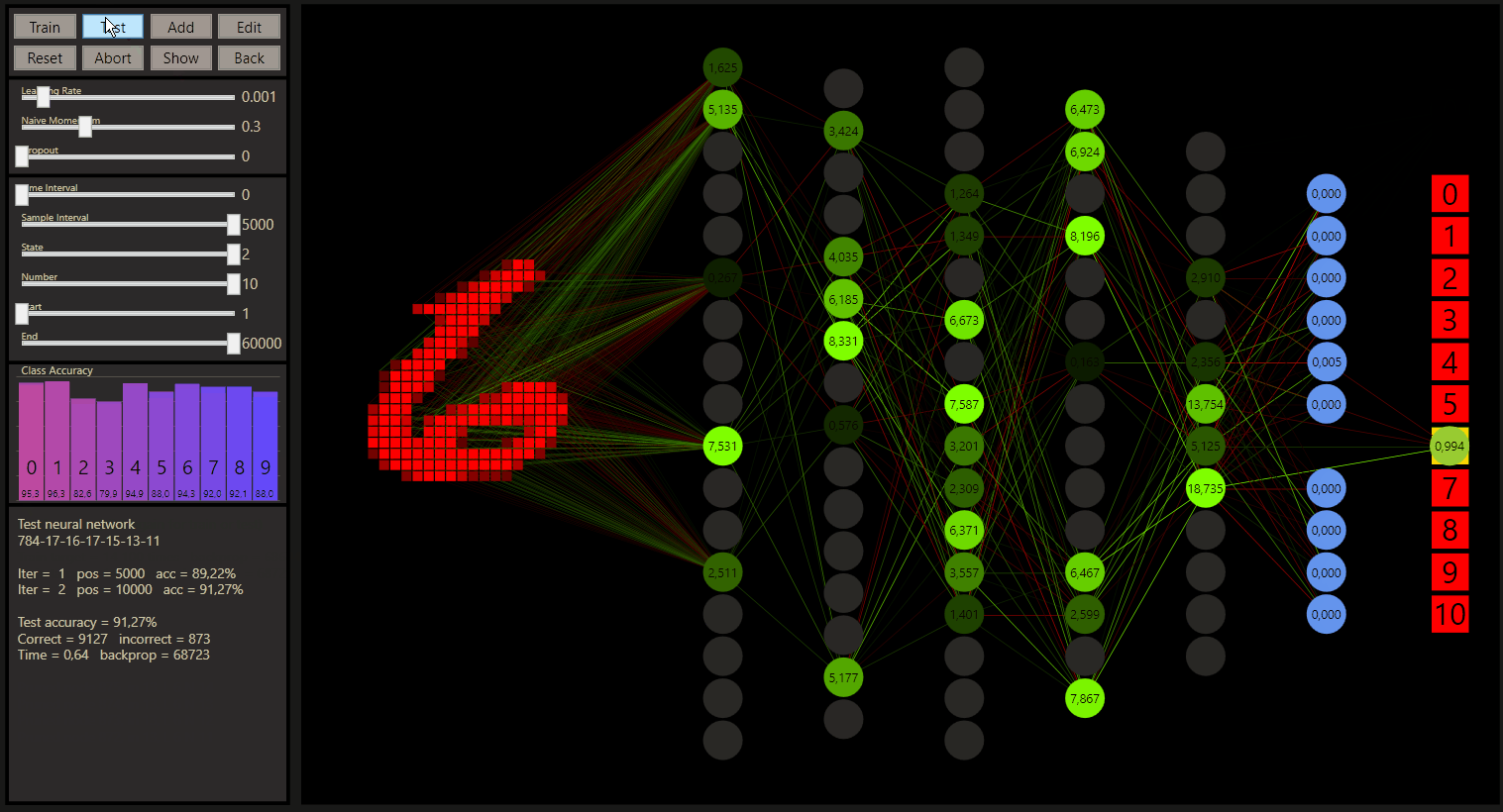
 With more neurons you reach more accuracy, that's right, almost. Neurons can be added or removed all the time with gg. Here the starting point was used to create a new network inside the existing one. After enough rounds the merged networks should be act as one, sometimes not so clever. It seems more useful to use the final size from start, but not always.
With more neurons you reach more accuracy, that's right, almost. Neurons can be added or removed all the time with gg. Here the starting point was used to create a new network inside the existing one. After enough rounds the merged networks should be act as one, sometimes not so clever. It seems more useful to use the final size from start, but not always.
Change the game:
 Finally, it is possible to add new data for new classes that differ from the common data. gg
Finally, it is possible to add new data for new classes that differ from the common data. gg
How to install:
Download and extract the directory to the c: folder.
Or:
1. Download the folder MNIST_Data for the unzipped data set and the Neural_Network_Backup with the empty file.
2. Then create the directory c:/goodgame/one/ and put both folders inside.
3. Now goodgame is ready to run on Visual Studio with the goodgame.cs code.
4. To collapse all the 1400 lines press CTRL + M + O.
Core functions:
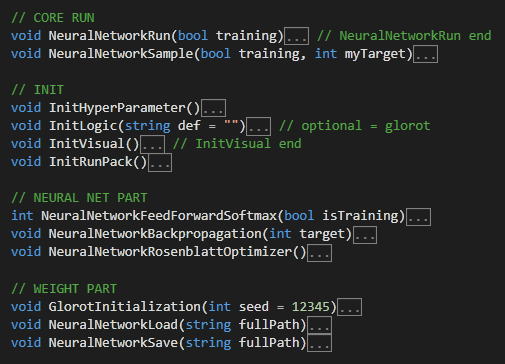
The code is really complicated in many parts and 1400 lines are a lot of lines, a good way to get the connection is start with the NeuralNetworkRun() function. The function handles training and test runs. NeuralNetworkSample() treats the custom training.
Build a release version of your goodgame app.
More about the low level:
For the code understanding, it is essentially to understand this concept. It seems the best way to built neural networks and the easiest way to work with them, but it's a heavy painful step to understand all the details to build a network by yourself. Give me a chance to make this easy.
For me A (input) + B (network model) = C (prediction) describes in a way my basic understanding of neural networks. it is abstract, but it helps me to keep things simple. If a perceptron is unknown to you, take a look here.
James D. McCaffrey writes:
"A perceptron is code that models a single biological neuron. Perceptrons were the predecessor to neural networks — a neural network is a collection of interconnected perceptrons."
Let's start to learn the feed forward way of the perceptron concept process in a very intuitiv way. Under the assumption of a solid skill over a C-family programming language we can start.
We start with one input neuron, connected with one weight, this is the dot-product or what I prefer, the netinput.
float net = 0;
net += neuron[0] * weight[0];
In the case of the MNIST data set, we have 784 input neurons, so we need more neurons, weights and a loop.
for (int n = 0; n < 784; n++)
net += neuron[n] * weight[n];
The result is one perceptron. But at least ten classes are needed to make a prediction, we need a new loop and output neurons. This leads to two dimensions, but instead expand the dimensions, we stack the output on top of the input neurons and weights. The weights will increase by 784 * 10 = 7840 weights.
for (int k = 0; k < 10; k++)
{
float net = 0;
for (int n = 0, m = k; n < 784; n++, m += 10)
net += neuron[n] * weight[m];
neuron[784 + k] = net;
}
This is the usual way to compute one layer and with the softmax for the output this would lead to ordinary logistic regression for the feed forward way. Elementary, the goal is to describe our network in one array u = { 784, 10} and with so many hidden layers we want to use. We need a new loop.
int[] u = { 784, 10 };
for (int i = 0, j = u[0]; i < 1; i++)
for (int k = 0; k < u[i + 1]; k++, j++)
{
float net = 0;
for (int n = 0, m = k; n < u[i]; n++, m += u[i + 1])
net += neuron[n] * weight[m];
neuron[j] = net;
}
Looks more complicated, but hopefully this makes sense to you despite we have to take one more step to construct our neural network building. Take care of the j variable, it is the index for every neuron after the inputs.
int[] u = { 784, 10 };
for (int i = 0, j = u[0], t = 0, w = 0; i < 1; i++)
{
for (int k = 0; k < u[i + 1]; k++, j++)
{
float net = 0;
for (int n = t, m = w + k; n < t + u[i]; n++, m += u[i + 1])
net += neuron[n] * weight[m];
neuron[j] = net;
}
t += u[i]; // stacks the neurons
w += u[i] * u[i + 1]; // stacks the weights
}
And that's it, if you understand this step, you have what you need to compute the activations, and you can create deep neural networks in one array. Let's take a more realistic example what can be used in practice, similar to the NeuralNetworkFeedForwardSoftmax() function in the code.
int[] u = { 784, 200, 180, 100, 10 }; // <-- that's a more deep neural network
int layer = u.Length - 1;
for (int i = 0, j = u[0], t = 0, w = 0; i < layer; i++, t += u[i - 1], w += u[i] * u[i - 1])
for (int k = 0; k < u[i + 1]; k++, j++)
{
float net = 0;
for (int n = t, m = w + k; n < t + u[i]; n++, m += u[i + 1])
net += neuron[n] * weight[m];
neuron[j] = (i != layer - 1 && net < 0) ? 0 : net; // ReLU activation
}
A nice challenge for you could be to take the code of goodgame on line 665 with NeuralNetworkFeedForwardSoftmax() and add the softmax activation to the code above. Because the code uses this idea in several forms, this is the most important code part to understand and deal with goodgame on the low level.
To take a connection to all that, it was necessary for me to use my own figure of this abstract concept.
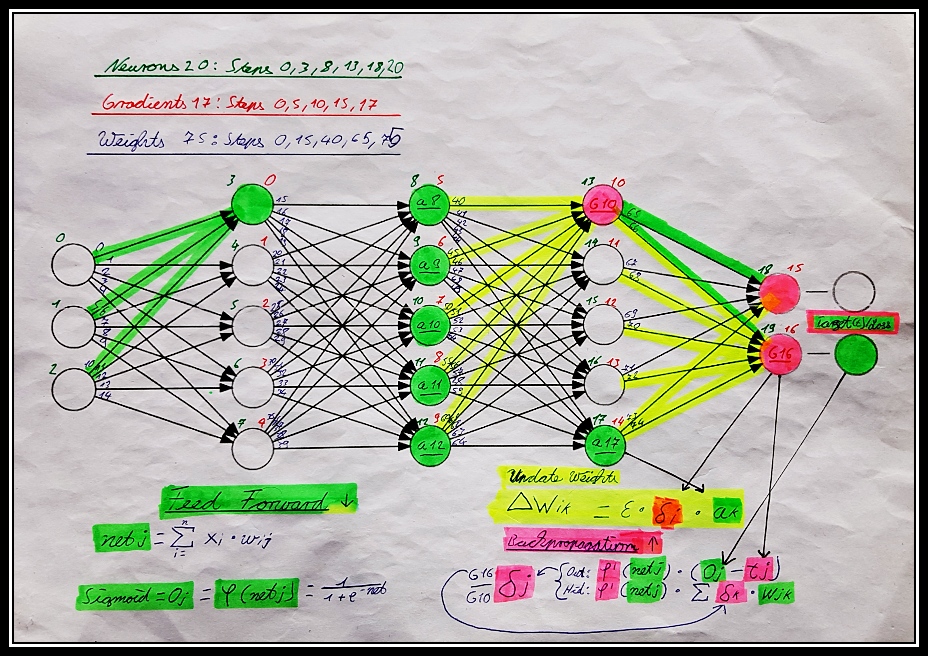
There are a lot more steps to understand goodgame in every detail, to explain all this would cost a lot of time, for the development it was better to work just in time. Before I was started this project, there was a huge question which language should I use, but it was not C++ at the end, because all the learning steps for me seems much harder and uncertain in comparsion to C#. But there is no real requierement to take C# or C++, it is more the understanding and using of all the tools we have.