Sample lines from Dataset Used: ( label1- Real label2- Fake )
| DOC_ID | LABEL | RATING | VERIFIED_PURCHASE | PRODUCT_CATEGORY | PRODUCT_ID | PRODUCT_TITLE | REVIEW_TITLE | REVIEW_TEXT |
|---|---|---|---|---|---|---|---|---|
| 1 | label1 | 4 | N | PC | B00008NG7N | Targus PAUK10U Ultra Mini USB Keypad, Black | useful | When least you think so, this product will save the day. Just keep it around just in case you need it for something. |
This DVD is awesome. I love the way that it shows all different kinds of life in the Ocean. Especially that of the Dolphins and the Whales. Finding out about the rays, sharks and many other things that live in the ocean is just as impressive. Just amazing. Simply Wonderful.
Roughly the size of a notebook paper, this little chalkboard is incredibly handy. It mounts easily to any surface with the included double sided tape. We use it in the kitchen for reminders and little notes. It is very light weight. The faux wood edges look nice as well. We're happy with this product.
Dataset has not been fact checked for correctness. I couldn't find a reliable datasource as filtering fake reviews is a hard task for humans,let alone for machines.
Given the nature of task and the fact that it was tougher to find a reliable dataset which is made available for students, I couldn't work on a better intuitive model. I found this repo to be nicer model to begin with. But my use case required usage of neural networks to solve this problem. So I went with following three implementations
ROC Curves:
1. Simple Word2Vec

2. Word2Vec concat with meta data

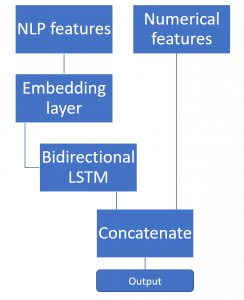
3. Simple Doc2Vec


4. Simple BERT


Inferences:
-
Basic BOW and TFIDF won't be suitable for this usecase simply, because reviews generally do contain repeating words and these methods will give less weightage for words which occur frequently.
-
Word2Vec captures the relationship between words through embeddings and using W2V embeddings with LSTM produced a reasonably better model which gave accuracy slightly greater than blind guessing But model seem to overfit the training set as validation accuracy was fluctuating back and forth
-
Doc2Vec was improvement over Word2Vec which works on TaggedSentences to produce slightly complex embeddings. But here also, model seem to overfit the training set as validation accuracy was fluctuating back and forth.
-
BERT gave an accuracy of 64% but despite being a complex architecture, it didn't overfit itself, but gave poor predictions on test dataset.