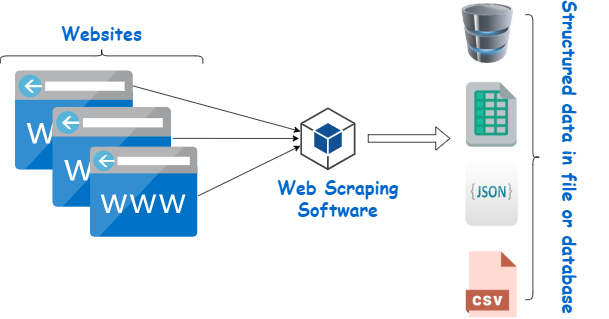
Web scraping is about downloading structured data from the web, selecting some of that data, and passing along what you selected to another process.
If you’ve ever copy and pasted information from a website, you’ve performed the same function as any web scraper, only on a microscopic, manual scale.
- First, our team of seasoned scraping veterans develops a scraper unique to your project, designed specifically to target and extract the data you want from the websites you want it from.
- The data is retrieved in HTML format, after which it is carefully parsed to extricate the raw data you want from the noise surrounding it. Depending on the project, the data can be as simple as a name and address in some cases, and as complex as high dimensional weather and seed germination data the next.
- Ultimately, the data is stored in the format and to the exact specifications of the project. Some companies use third party applications or databases to view and manipulate the data to their choosing, while others prefer it in a simple, raw format - generally as CSV, TSV or JSON.
Web scraping is used in a variety of digital businesses that rely on data harvesting. Legitimate use cases include:
- Search engine bots crawling a site, analyzing its content and then ranking it.
- Price comparison sites deploying bots to auto-fetch prices and product descriptions for allied seller websites.
- Market research companies using scrapers to pull data from forums and social media (e.g., for sentiment analysis).
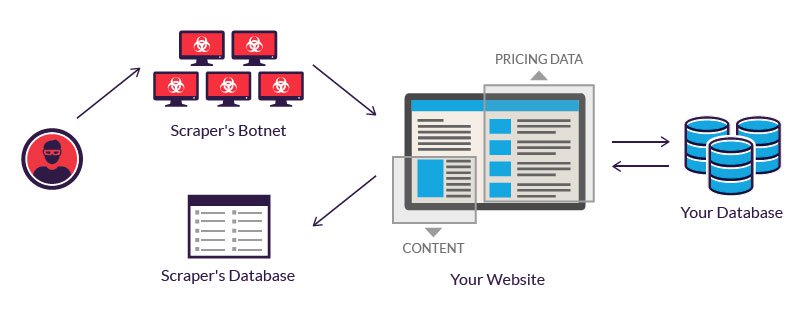
Web scraping is also used for illegal purposes, including the undercutting of prices and the theft of copyrighted content.
Open a terminal
Setup the pip package manager
Install the virtualenv package ---
pip install virtualenv
Create the virtual environment --(taking virtualenvname=mypython)
virtualenv mypython
Activate the virtual environment --
mypthon\Scripts\activate
To decativate the virtual environment and use your original
Python environment, simply type ‘deactivate’
Deactivate the virtual environment --
deactivate
Installing selenium
pip install selenium
CHECK
pip check selenium
if there "No broken requirements found."
then the selenium package is successfully installed
download the chromedriver from the link compatible to the version of your google chrome version installed
You can check version of Chrome in -settings/About Chrome