[BUG] Upgrade: post-drain job fails when upgrading to the same version #3175
Comments
Pre Ready-For-Testing Checklist
|
|
Automation e2e test issue: harvester/tests#618 |
|
Upgrade the same version from
Will try following the workaround to proceed the upgrade. |
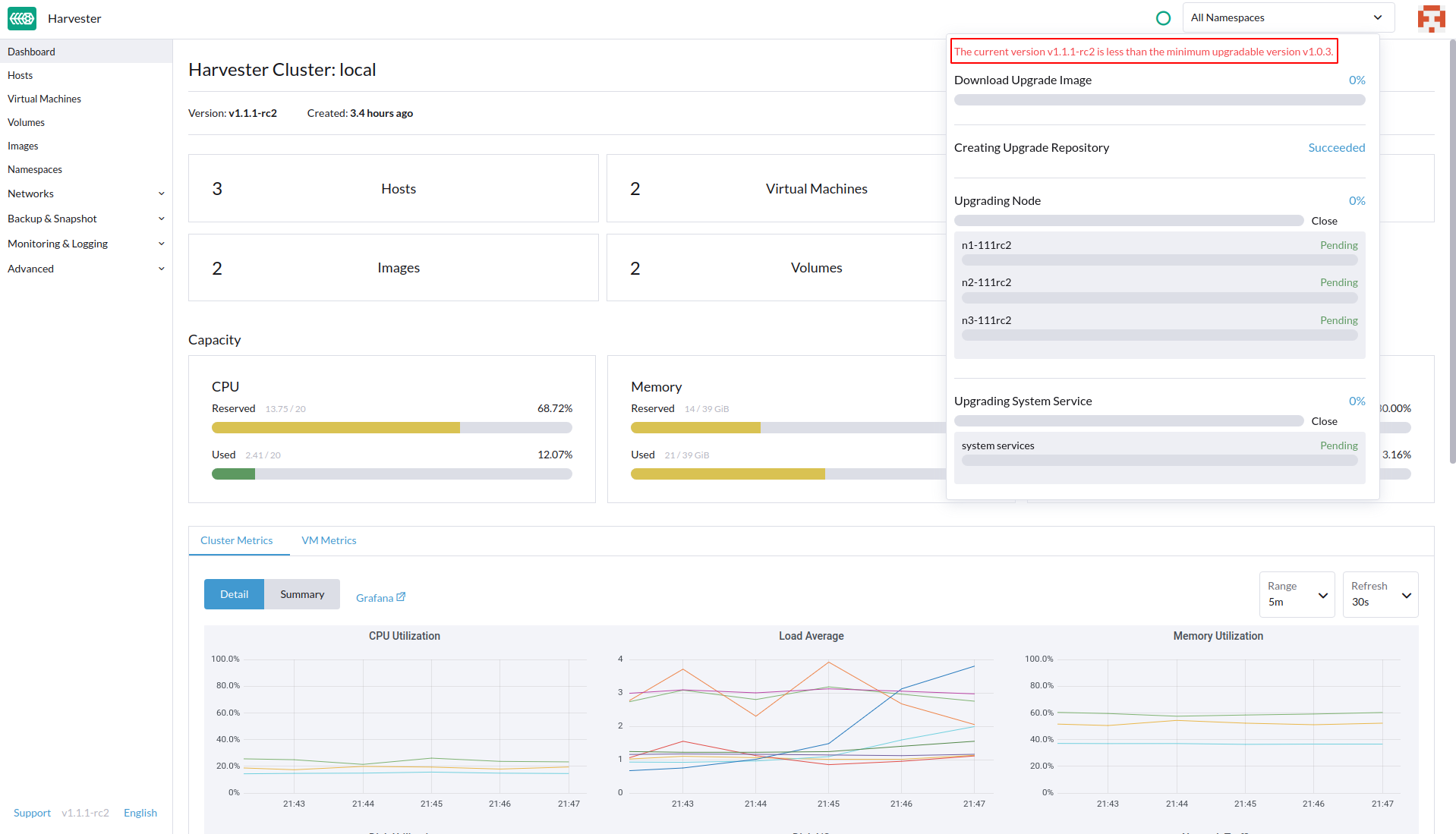
|
Build another 3 nodes Harvester cluster to perform the same version After applying the workaround to pause managed chart and pretend v1.0.3 release
We would continue to check more details of it. |
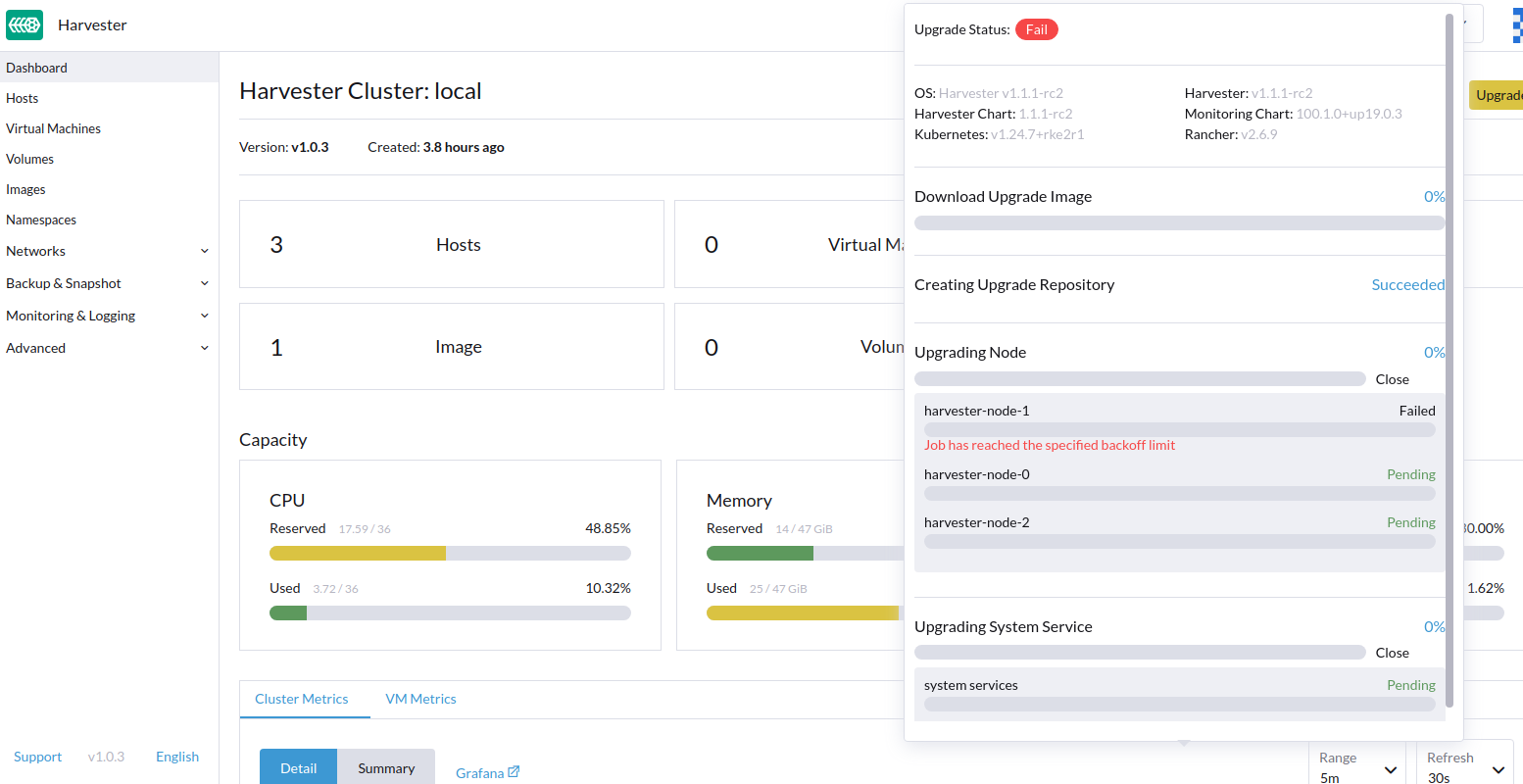
|
When testing against the fix, we need to apply the workaround prior to the upgrade. This is basically to make Harvester think of itself as an older and formal release version like v1.0.3 or v1.1.0, but the controller codebase is actually v1.1.1-rc2. However, this leads to an upgrade failure in the image preloading stage:
To better testing on this, we may have to fake the Then kick start the upgrade. |


|
Verified fixed on ResultWe build up a v1.1.1-rc2 Harvester cluster and upgrade the same version on existing cluster again. After we apply the workaround to pause managed chart and pretend v1.1.0 release and also retag
Test Information
Verify Steps
|

Describe the bug
The post-drain job fails if upgrading the same ISO twice.
To Reproduce
Steps to reproduce the behavior:
Looks like the trap threw the wrong exit code.
Expected behavior
The job should succeed.
Support bundle
Environment
Additional context
Add any other context about the problem here.
The text was updated successfully, but these errors were encountered: