This repo contains lab tests using Flent to compare SCE and L4S.
- Introduction
- Test Setup
- Test Output
- Scenarios and Results
- List of SCE Issues
- List of L4S Issues
- Changes
- Installation
- Future Work
- Acknowledgements
This repo contains lab tests using Flent to compare SCE and L4S. The current tests cover some basics, including link utilitization, inter-flow and intra-flow latency, fairness, a simple gaming scenario and experiments with the CoDel AQM.
In deference to RFC 5033, as it pertains to the evalution of congestion control proposals:
The high-order criteria for any new proposal is that a serious scientific study of the pros and cons of the proposal needs to have been done such that the IETF has a well-rounded set of information to consider.
We admit that we have quite a ways to go to thoroughly test all of the considerations mentioned in the literature. We also acknowledge that real world tests in realistic scenarios should be the final arbiter of the utility of high-fidelity congestion control and how it may be deployed. To the extent that we can, we will try to incorporate any reported problems seen in real world testing into something we can repeatably test in the lab.
The plan is to iterate on these tests up until IETF 106 in Singapore, so that the IETF has some more concrete comparative material to work with in evaluating the SCE and L4S proposals. We will consider input from feedback on the tsvwg mailing list and surrounding communities, as well as the helpful draft-fairhurst-tsvwg-cc and its references, including but not limited to RFC 5033, RFC 3819 and RFC 5166.
Please feel free to file an Issue for any of the following reasons:
- Suggestions for new tests or variations (see also Future Work)
- Suspicious results
- Updated code for re-testing
- Requests for additions or corrections to plots or other test output
- Inaccuracies or omissions
- Biased or inappropriate wording in this document
The test setup consists of two endpoints (one C and one S) and four middleboxes (M1-M4). Each node is configured with one interface for management (not shown) plus one (for C and S nodes) or two (for M nodes) for testing, connected as follows:
C1 -| |- S1
|- M1 - M2 - M3 - M4 -|
C2 -| |- S2
The test is run separately for SCE and L4S, and all configuration changes needed for the different test scenarios are made automatically. SCE tests are run from C1 to S1, and L4S tests from C2 to S2.
The kernels, software and sysctl settings on each node are as follows:
- C1 (SCE):
- C2 (L4S):
- M1:
- role: middlebox
- kernel: L4S
- sysctl:
net.ipv4.ip_forward = 1
- M2:
- role: middlebox
- kernel: SCE
- sysctl:
net.ipv4.ip_forward = 1
- M3:
- role: middlebox
- kernel: L4S
- sysctl:
net.ipv4.ip_forward = 1
- M4:
- role: middlebox
- kernel: SCE
- sysctl:
net.ipv4.ip_forward = 1
- S1 (SCE):
- role: server / receiver
- kernel: SCE
- software: netserver, tcpdump
- sysctl:
net.ipv4.tcp_sce = 1
- S2 (L4S):
- role: server / receiver
- kernel: L4S
- software: netserver, tcpdump
- sysctl:
net.ipv4.tcp_ecn = 3
Unless otherwise noted, default parameters are used for all qdiscs. One exception is for Cake, for which we use the
besteffort parameter in all cases, which treats all traffic as besteffort,
regardless of any DSCP marking. Since we are not testing DSCP markings in these
tests, this has no effect other than to make it a little clearer when viewing
the tc statistics.
The setup and teardown logs (examples here and here), accessible from the Full Results links, show the configuration and statistics of the qdiscs before and after each test is run.
ℹ️ All bottlenecks restrict to 50Mbit, unless otherwise noted. Bandwidth information is also available in line 3 of the plot titles. All shaping is done on egress, except for netem delays, which are added on ingress.
ca_ratio=40 and ss_ratio=100
are used for the SCE client in these tests, the theoretical justification for
which is as follows (from Jonathan Morton):
0: Transient queuing is much more noticeable to high-fidelity congestion signalling schemes than to traditional AQM. A single brief excursion into the marking region kicks the flow out of SS, even if it hasn't actually reached the correct range of cwnd to match path BDP.
1: The default pacing parameters exhaust the cwnd in less than one RTT, regardless of whether in SS or CA phase, leaving gaps in the stream of packets and thus making the traffic more bursty. Ack clocking is not sufficient to smooth those bursts out sufficiently to prevent significant amounts of transient queuing, especially during SS. Hence we choose 100% as the maximum acceptable scale factor.
2: SS makes the cwnd double in each RTT, and it takes a full RTT for the first congestion signal to take effect via the sender, so the transition out of SS has to compensate for that by at least halving the send rate. The initial response to transitioning out of SS phase is an MD for a traditional CC (to 70% with CUBIC), plus the change from SS to CA pacing rate (to 60% of SS rate with defaults). In total this is a reduction to 42% of the final SS send rate at the start of CA phase, which is compatible with this requirement.
3: High fidelity CC responds much less to the initial congestion signal, which may indicate less than a millisecond of instantaneous excess queuing and thus the need for only a very small adjustment to cwnd. The one-time reduction of send rate required due to the SS-CA transition must therefore be provided entirely by the pacing scale factor. Our choice of 40% gives similar behaviour to CUBIC with the default scale factors, including the opportunity to drain the queue of excess traffic generated during the final RTT of the SS phase.
4: A sub-unity pacing gain may also show benefits in permitting smooth transmission in the face of bursty and contended links on the path, which cause variations in observed RTT. This has not yet been rigorously quantified.
Experimentally, these pacing settings have been shown to help avoid overshoot for SCE.
We do not use these settings for L4S, because that's not what the L4S team tested with, and we have not found these settings to materially improve the results for L4S in repeatable ways.
Please file an Issue if there are any concerns with this.
The results for each scenario include the following files:
*_fixed.png- throughput, ICMP RTT and TCP RTT plot with fixed RTT scale for visual comparison*_var.png- throughput, ICMP RTT and TCP RTT plot with variable RTT scale based on maximum value for showing outliers*.debug.log.bz2- debug log from Flent*.flent.gz- standard Flent output file, may be used to view original data or re-generate plots*.log- stdout and stderr from Flent*.process.log- output from post-processing commands like plotting and scetrace*.setup.log- commands and output for setting up each node, as well as kernel version information (nodes that do not appear have their configuration set to default)*.tcpdump_*.json- output from running scetrace on the pcap file*.tcpdump_*.log- stdout and stderr from tcpdump*.tcpdump_*.pcap.bz2- pcap file compressed withbzip2 -9*.teardown.log- commands and output upon teardown of each node, after the test is run, includingtcstats and output fromip tcp_metrics
The batch consists of numbered scenarios. The following definitions help interpret the topology for each:
- L4S middlebox: uses
sch_dualpi2 - SCE middlebox: uses
sch_cakewith thesceparameter - FQ-AQM middlebox: uses
fq_codel - single-AQM middlebox: uses
fq_codelwithflows 1 - ECT(1) mangler: uses an iptables rule to set ECT(1) on all packets for the one-flow test, or all packets on one of the flows in the two-flow test
- FIFO middlebox: uses
pfifo_fast
Each scenario is run first with one flow, then with two flows (the second flow beginning after 10 seconds), and with the following variations:
- netem induced RTT delays of 0ms, 10ms and 80ms
- different CC algorithms as appropriate
Full results obtained at the SCE Data Center in Portland are available here.
Following are descriptions of the scenarios, with observations and links to some relevant results from Portland. Issues are marked with the icon :exclamation:, which is linked to the corresponding issue under the sections List of SCE Issues and List of L4S Issues.
This is a sanity check to make sure the tools worked, and evaluate some basics.
L4S: Sender → L4S middlebox (bottleneck) → L4S Receiver
SCE: Sender → SCE middlebox 1q (bottleneck) → SCE Receiver
Full results: SCE one-flow | SCE two-flow | L4S one-flow | L4S two-flow
One-flow Observations:
-
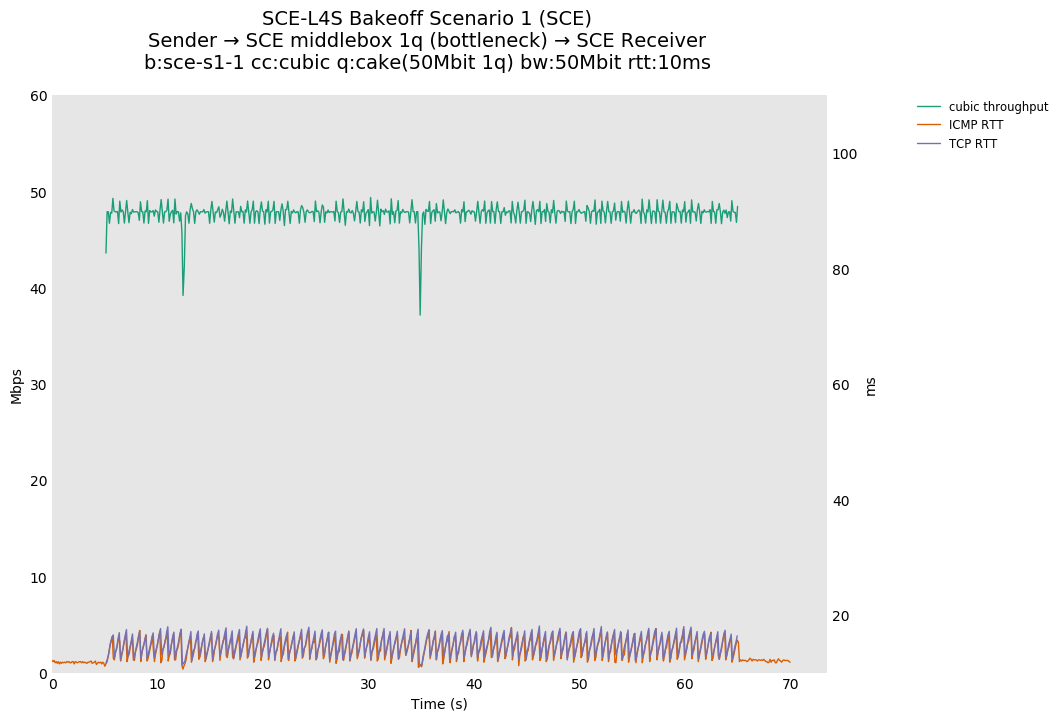
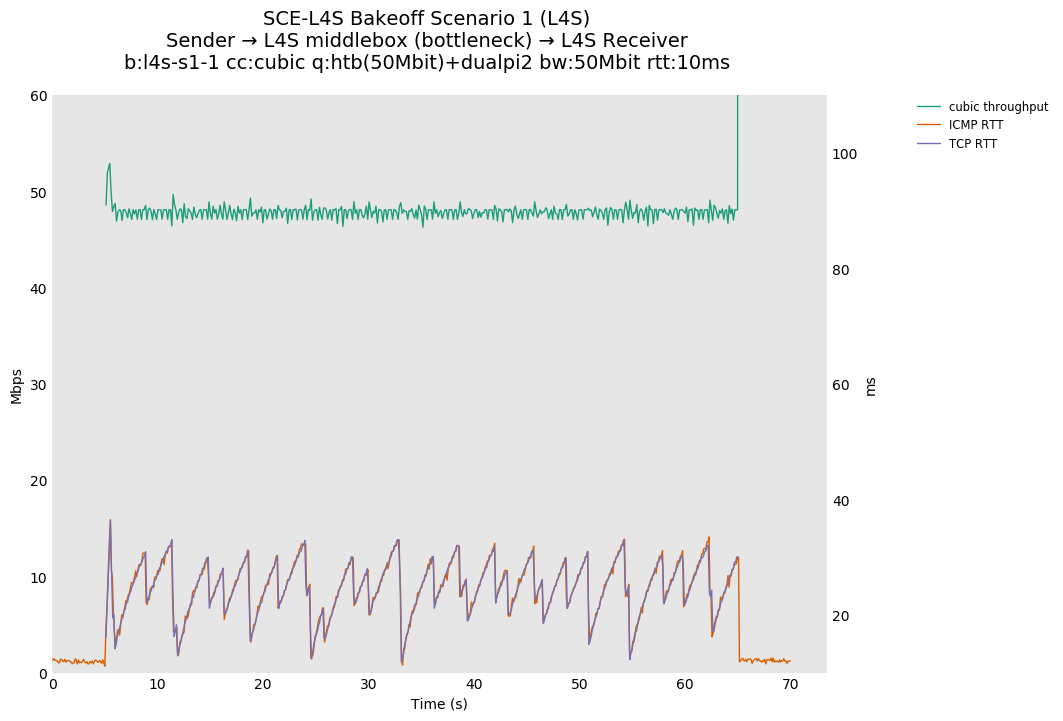
SCE vs L4S, single Cubic flows at 10ms
Cake maintains a lower ICMP and TCP RTT than dualpi2, likely due to the operation of Cake's COBALT (CoDel-like) AQM in comparison to PI. Note that Cake's default target is 5ms, and dualpi2's is 15ms.
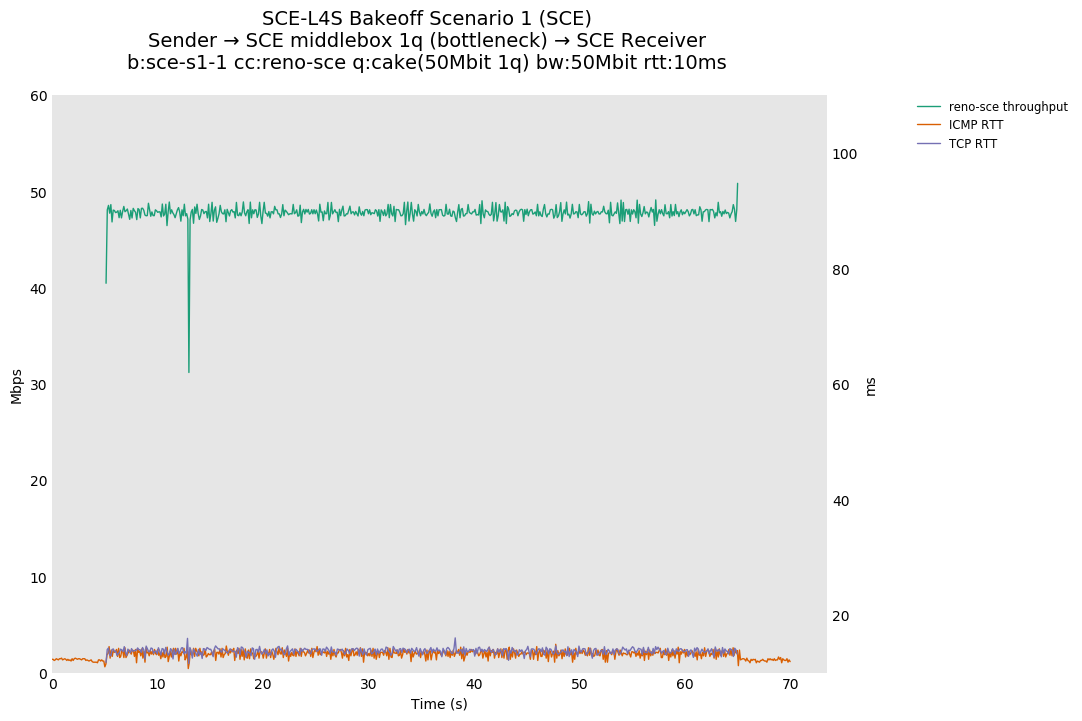
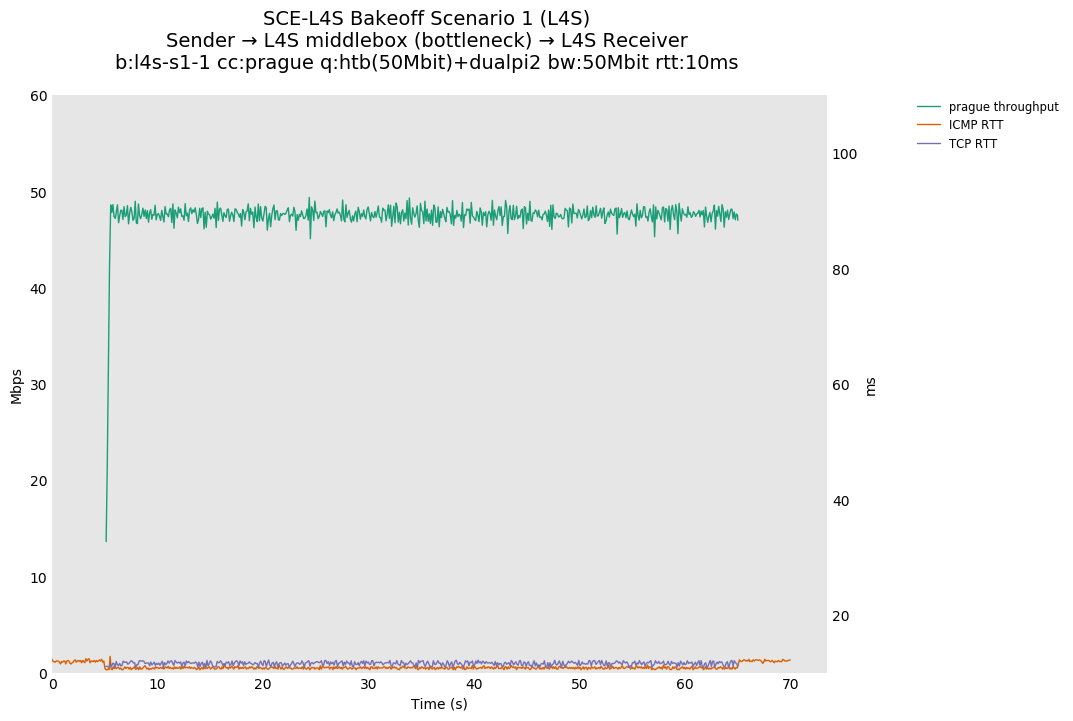
-
SCE vs L4S, single Reno-SCE and Prague flows at 10ms
TCP Prague, which uses dualpi2's L queue, maintains a lower ICMP and TCP RTT than Reno-SCE. This is probably due to dualpi2 marking congestion at a lower queue depth than Cake, which starts marking at a default depth of 2.5ms. We hypothesize that the earlier default marking for dualpi2 may lead to a higher drop in utilization with bursty flows, but this will be tested at a later time.
ℹ️ One common question here, and elsewhere, is why does ICMP RTT drop a bit when the TCP flow is active. The following explanation from Rodney Grimes helps explains this:
The most common cause that ICMP or for that matter any RTT goes down when an interfaces transistions from idle to underload is that often these devices are running in a mode that says only interrupt the CPU when you have work (and work is usually a BUNCH of packets) for it to do, otherwise wake the CPU in some time t (or the CPU may be set to poll the device at some interval t). So what you get when idle is your ping or single packet type RTT is driven by this poll/interval interrupt, but when you start sending traffic the device does have work for the CPU and so the CPU gets woken up at intervals much less than t.
This is a commonly misunderstood aspect of modern NIC hardware that uses large ring buffers, they are actually slow to respond when there are only a few packets per poll interval arriving, due to the wait for the end of the interval.
-
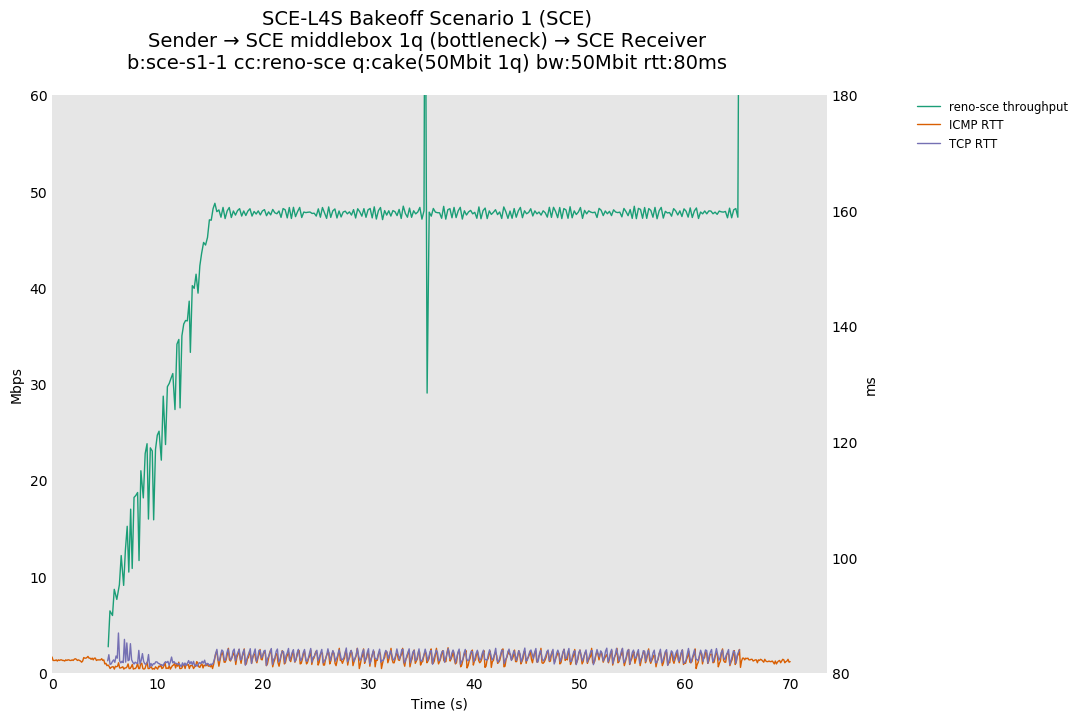
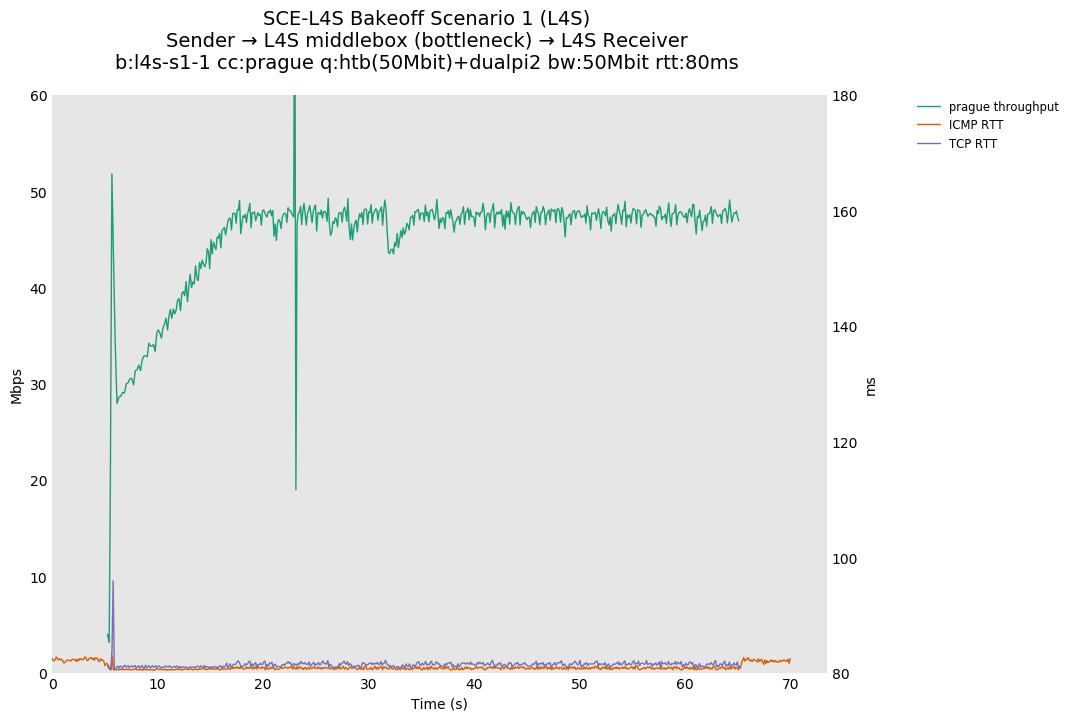
SCE vs L4S, single Reno-SCE and Prague flows at 80ms
For SCE, Reno-SCE shows a faster ramp during slow start, because while NewReno growth is 1/cwnd segments per ack, Reno-SCE grows by 1/cwnd segments per acked segment, so about twice as fast as stock NewReno, but still adhering to the definition of Reno-linear growth. Also, sometimes a single Reno-SCE flow can receive a CE mark, even when already in CA on an otherwise unloaded link. This may be due to a transient load in the test environment, causing a temporary buildup of queue. CE can still occur for SCE flows and this is not necessarily abnormal.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Two-flow Observations:
-
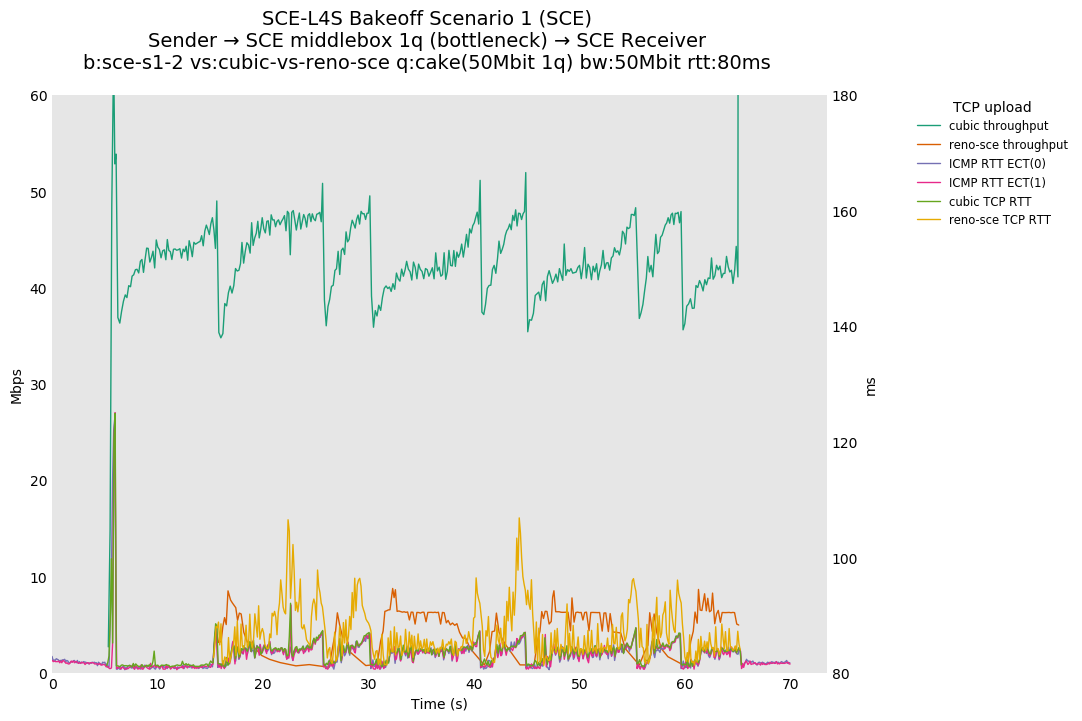
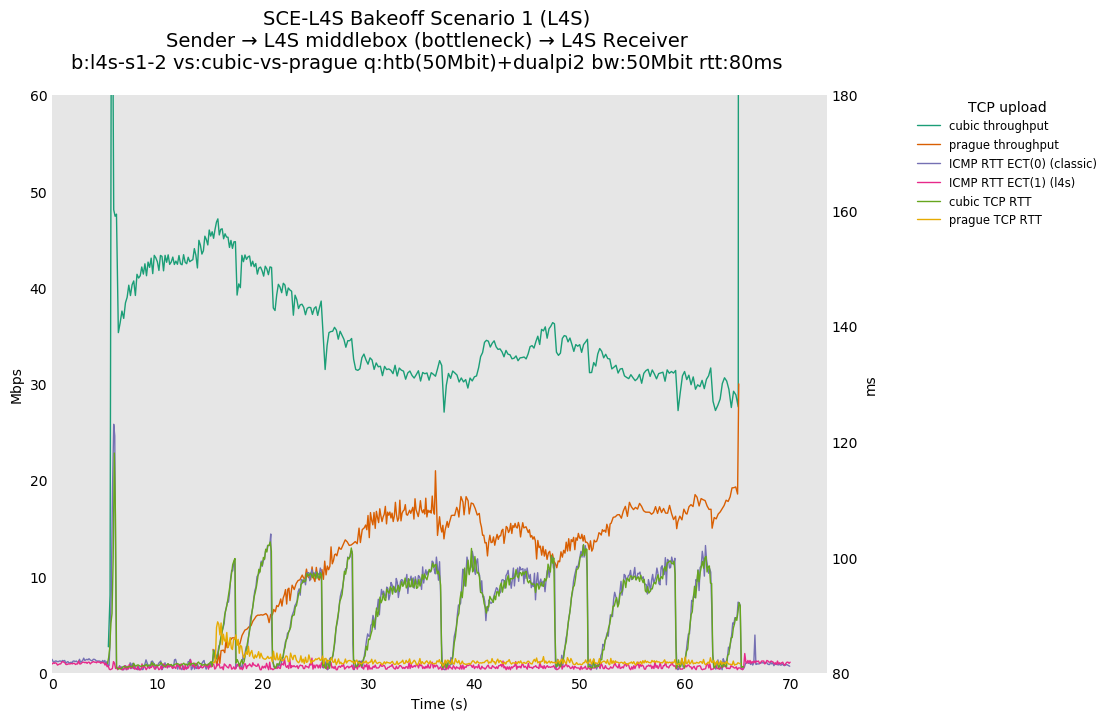
SCE vs L4S, Cubic vs Cubic at 80ms
Cubic ramps up faster for dualpi2 than Cake, but with a corresponding spike in TCP RTT. We hypothesize that Cubic is exiting HyStart early for Cake here, possibly due to minor variations in observed RTT.
We can also see that although TCP RTT is higher for dualpi2 than Cake, the L4S ping, marked ECT(1), shows lower RTT as the only L queue occupant.
-
SCE vs L4S, Cubic vs Reno-SCE and Cubic vs Prague at 80ms
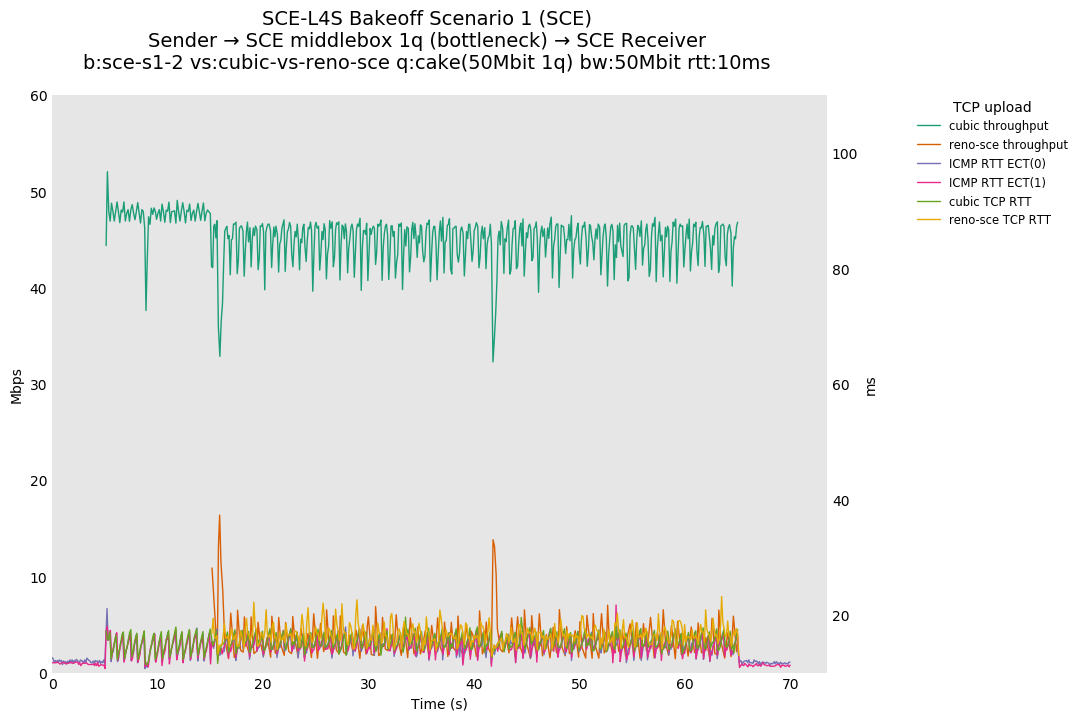
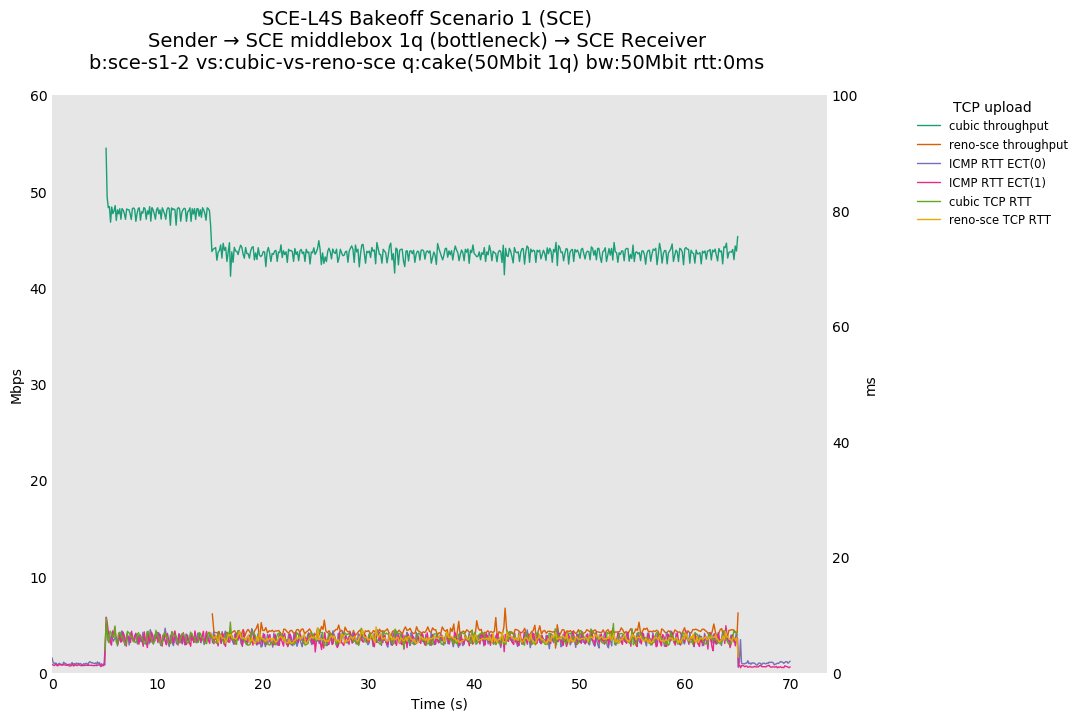
❗ Although SCE sometimes shows approximate fairness at 80ms, without changes to the default SCE marking ramp, Reno-SCE is dominated by a Cubic flow in a single queue at 10ms and 0ms.
❗ We see large differences in throughput fairness in this result vs 10ms and 0ms, suggesting that fairness is RTT dependent.
-
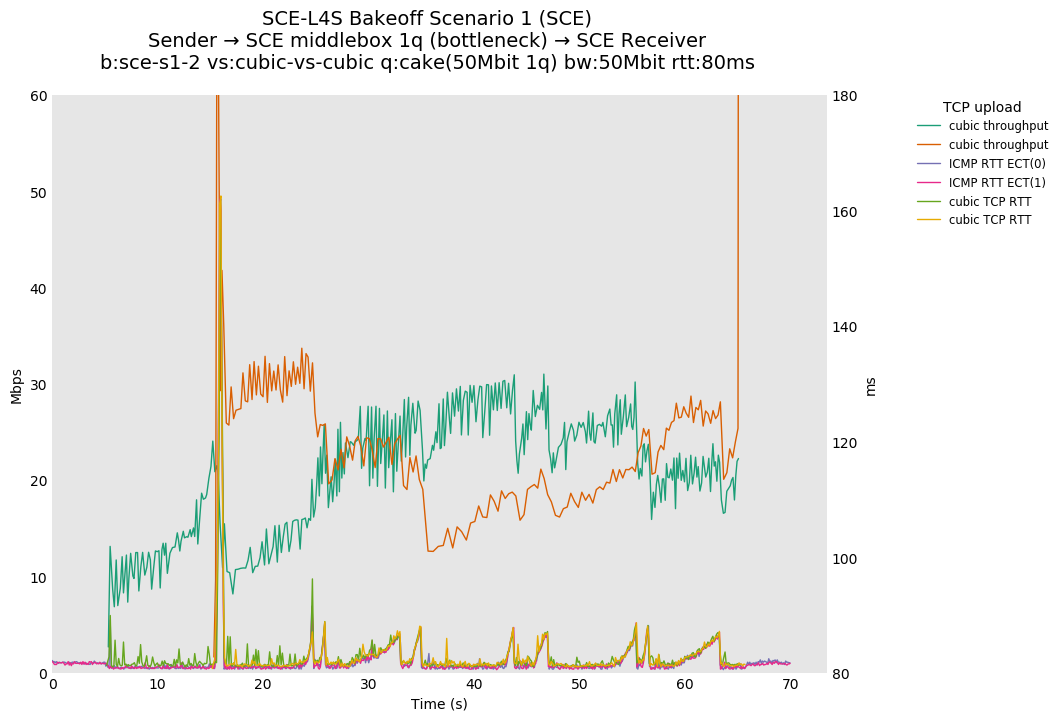
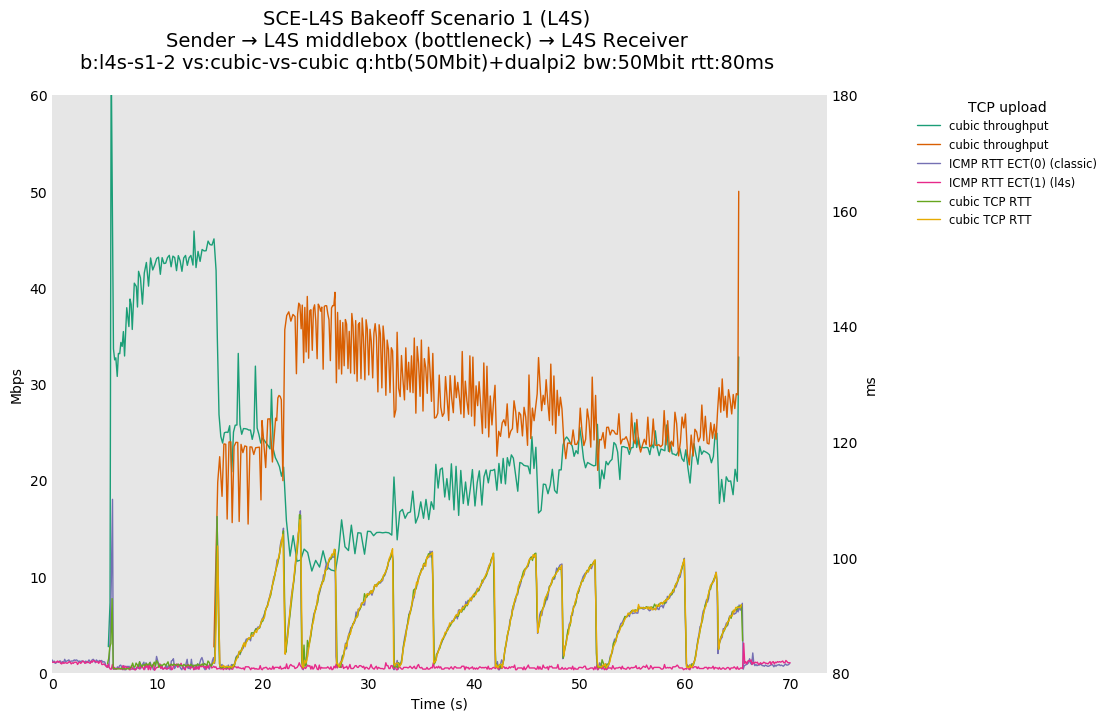
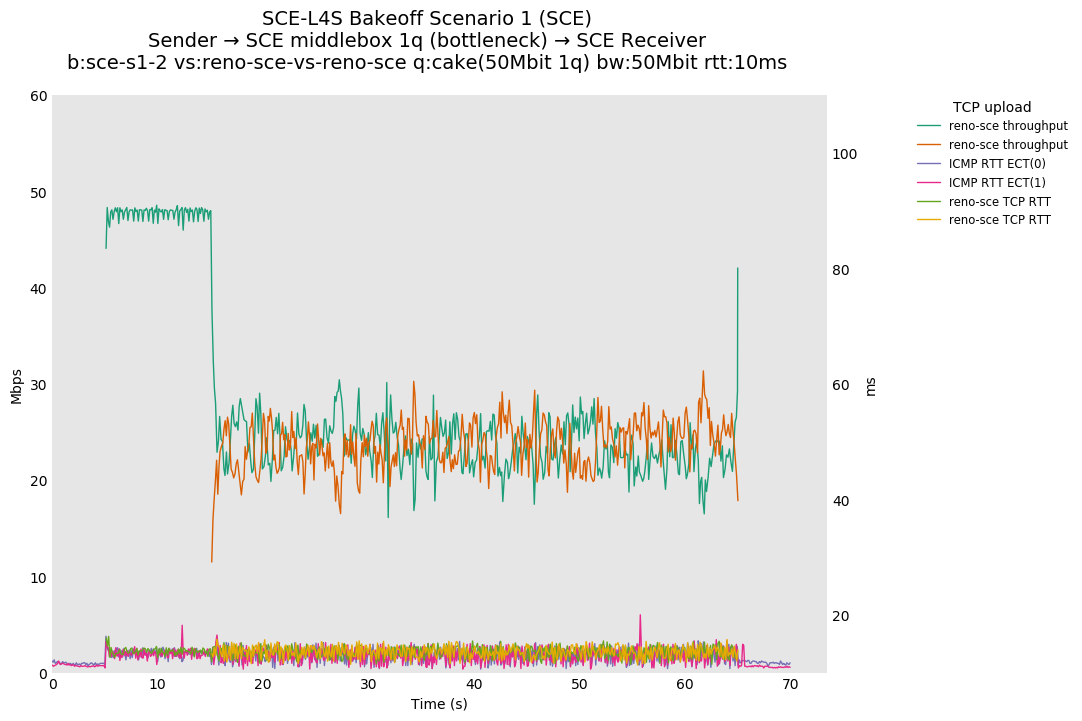
SCE vs L4S, Reno-SCE vs Reno-SCE and Prague vs Prague at 80ms
Noting that this is a single queue, Reno-SCE shows throughput fairness, with convergence on the order of 20 seconds (varies) at 80ms. Convergence time drops to a second or two at 10ms.
❗ We see higher convergence times of ~30-40 seconds for TCP Prague at 80ms.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
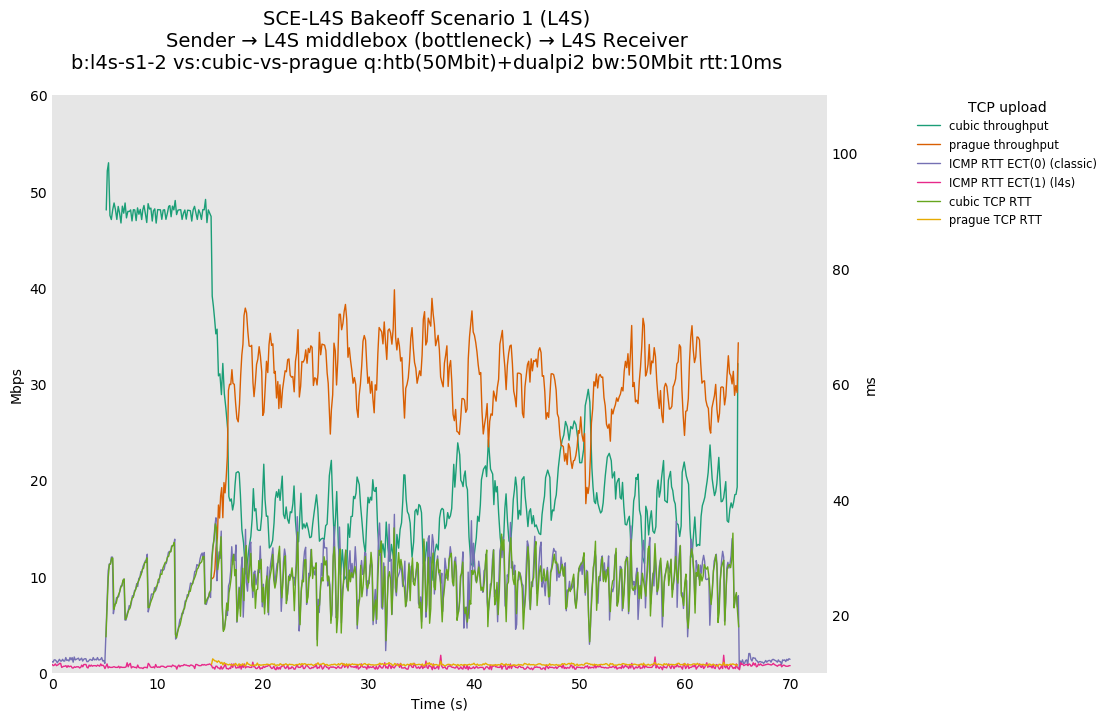{kind=link}
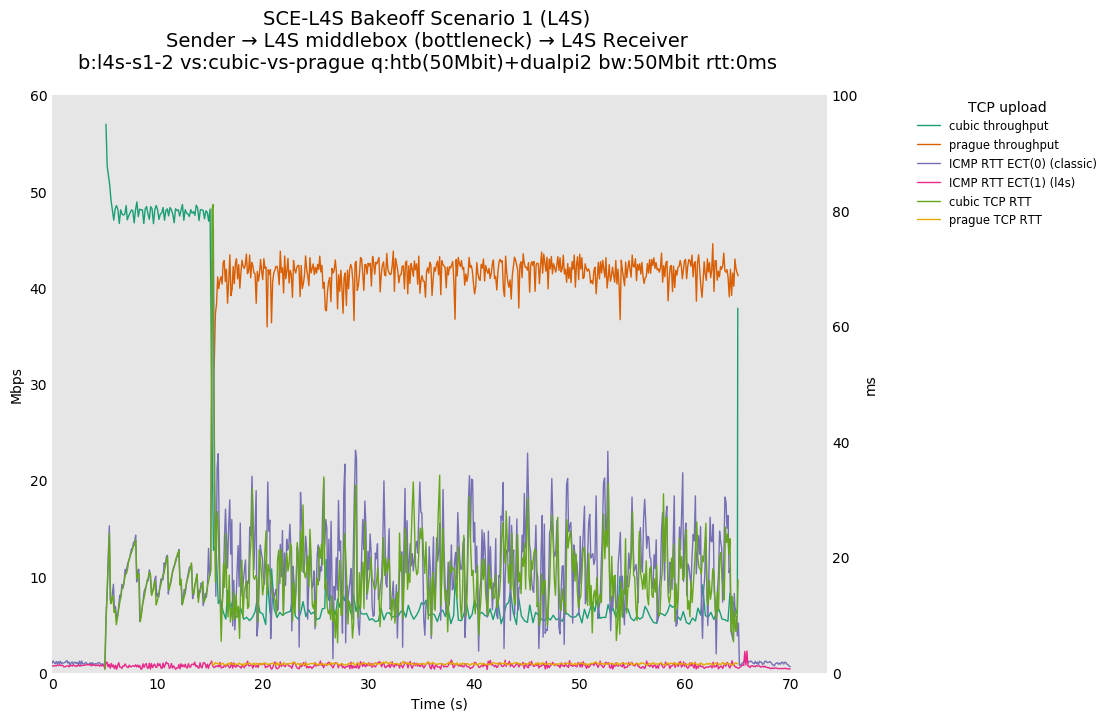{kind=link}
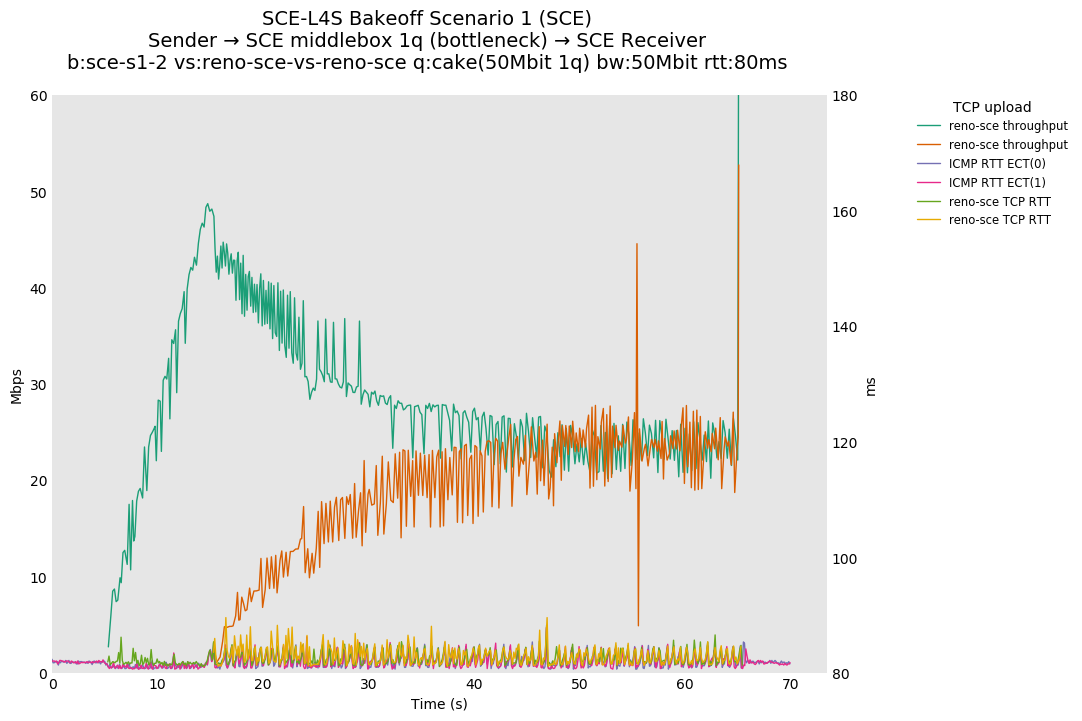{kind=link}
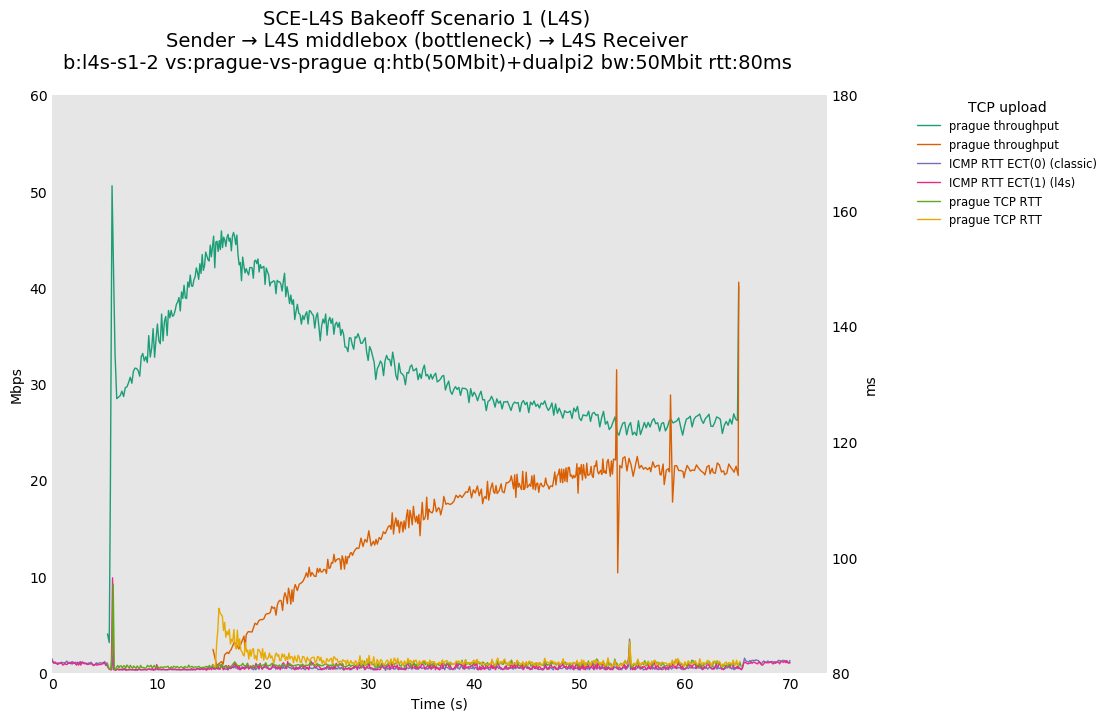{kind=link}
{kind=link}
This is the most favourable-to-L4S topology that incorporates a non-L4S component that we could easily come up with.
L4S: Sender → FQ-AQM middlebox (bottleneck) → L4S middlebox → L4S receiver
SCE: Sender → FQ-AQM middlebox (bottleneck) → SCE middlebox → SCE receiver
Full results: SCE one-flow | SCE two-flow | L4S one-flow | L4S two-flow
One-flow Observations:
-
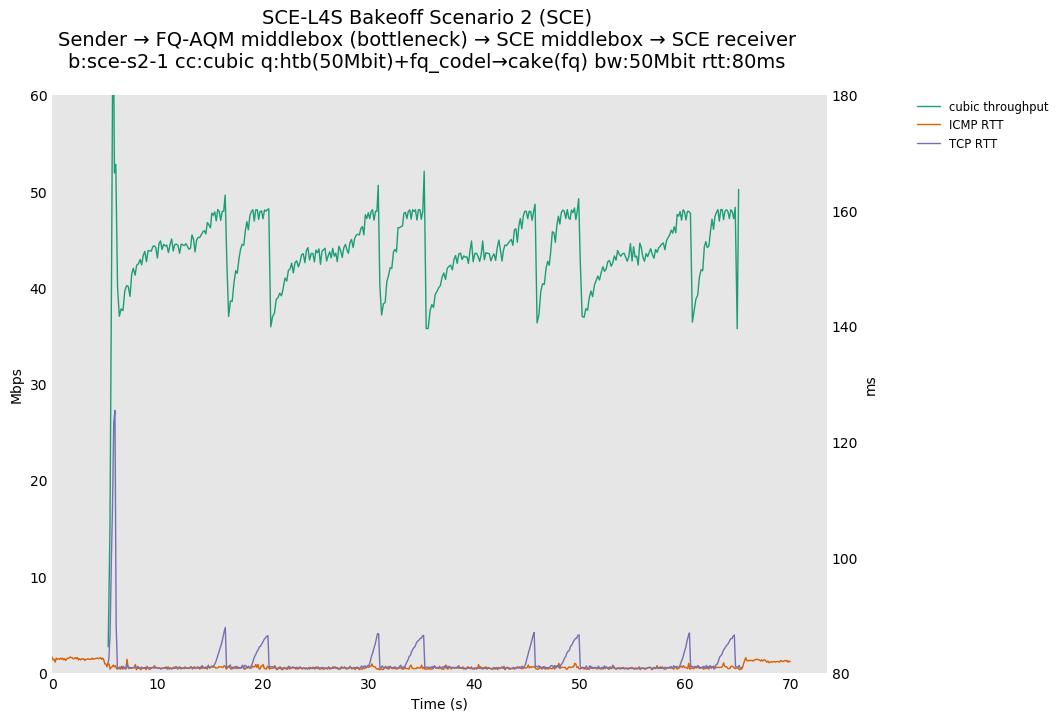
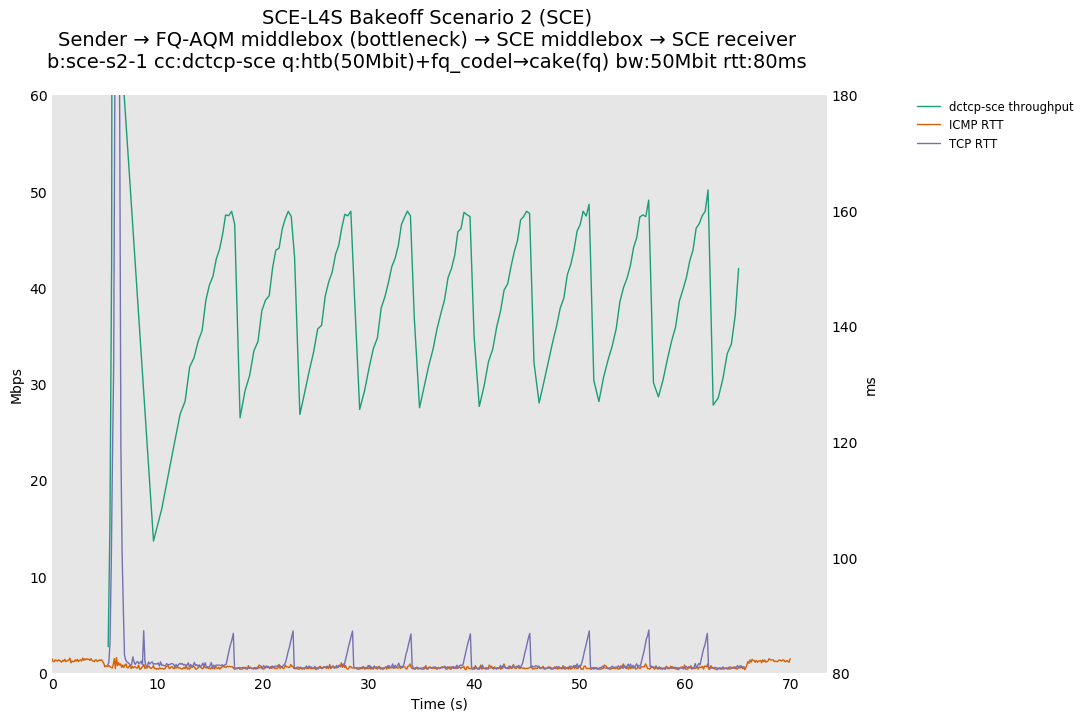
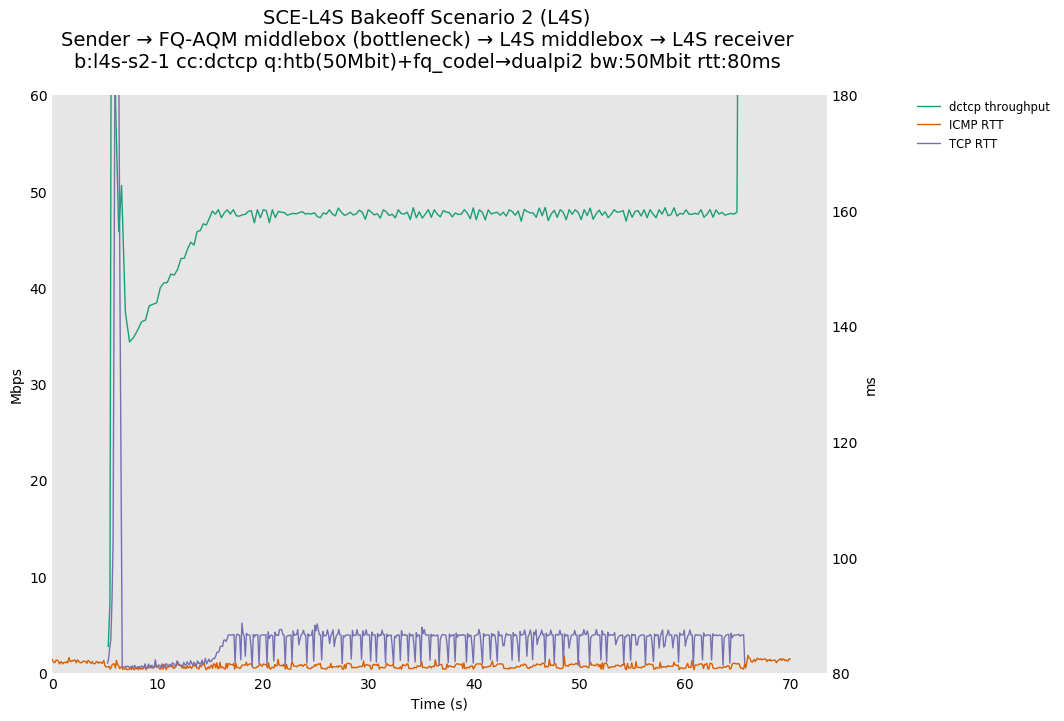
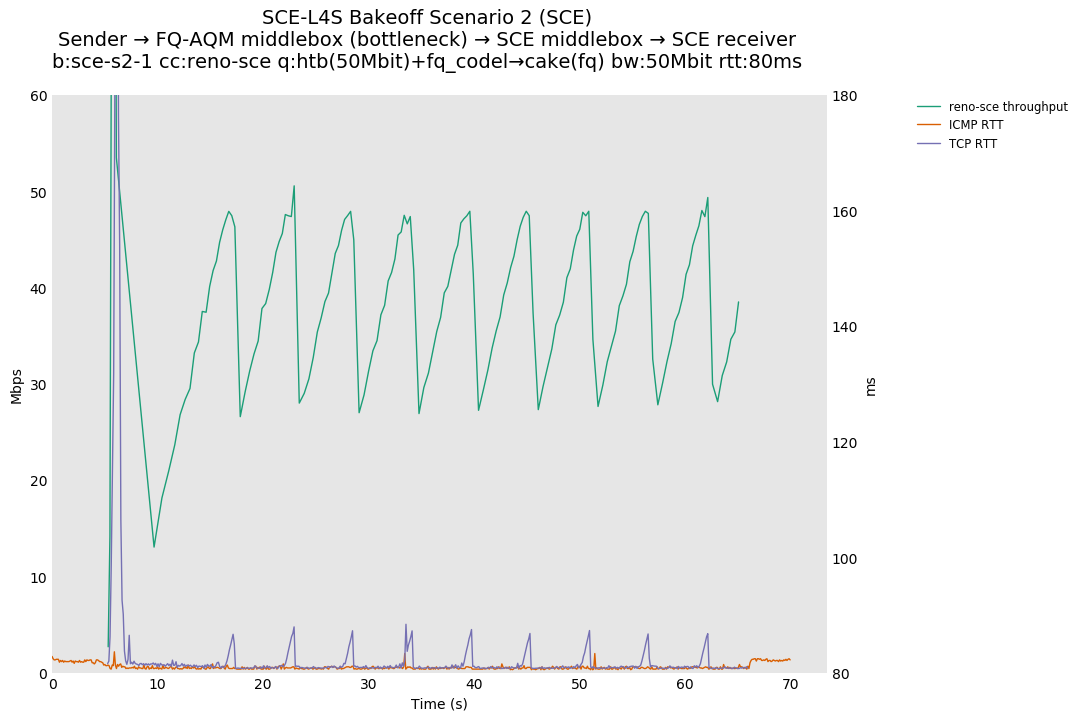
SCE vs L4S, single flow DCTCP-SCE or DCTCP at 80ms
DCTCP-SCE shows a throughput sawtooth because DCTCP-SCE treats the CE marks from fq_codel as per ABE, defined in RFC 8511, which is closer to the traditional RFC 3168 response.
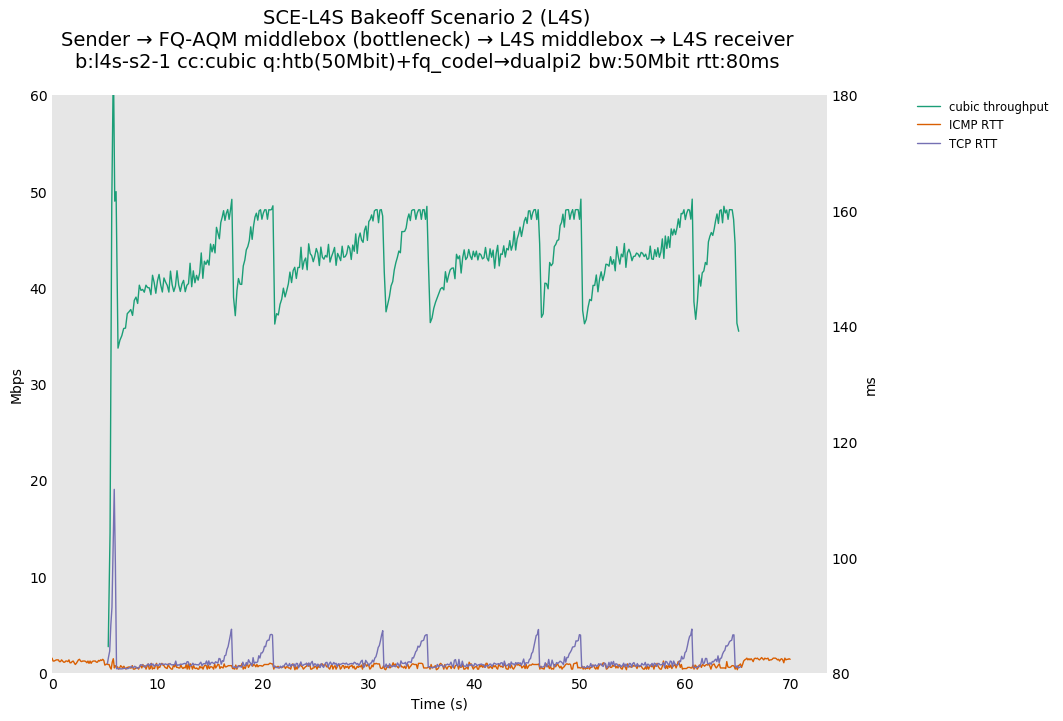
In the L4S architecture, DCTCP does not show a sawtooth, because CE has been redefined as a fine-grained congestion signal, as allowed for experimentation by RFC 8311. Correspondingly, the increase in TCP RTT stays right around fq_codel's target of 5ms, as compared to DCTCP-SCE, whose TCP RTT increase only approaches 5ms as queue depths near the CE marking point.
-
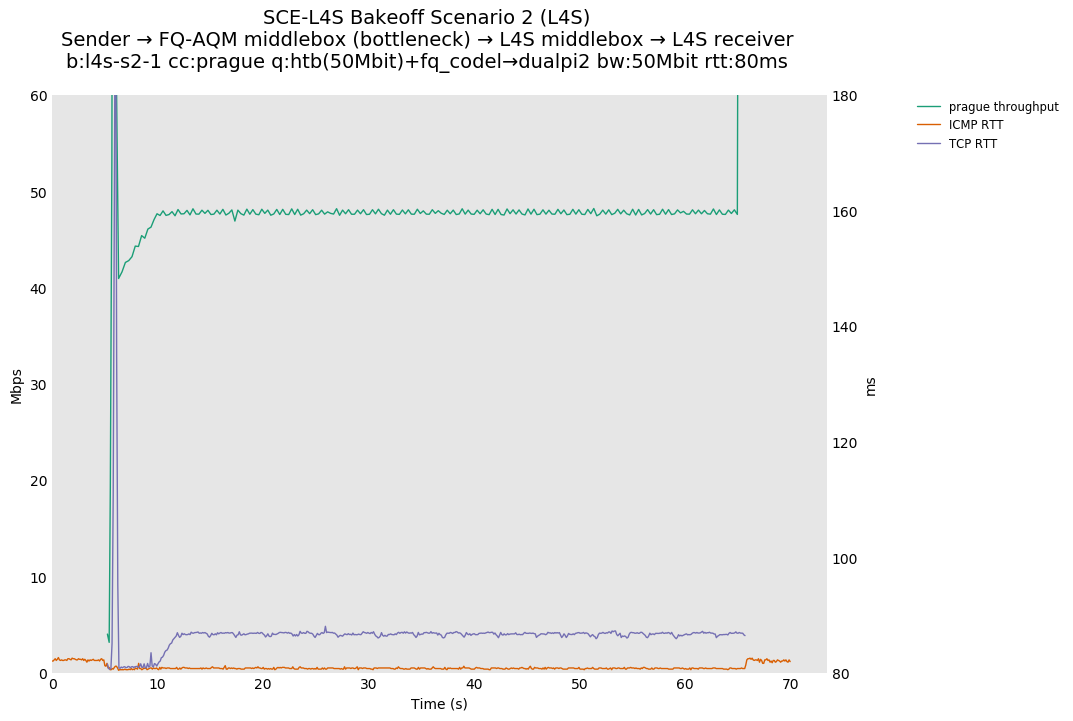
SCE vs L4S, single Reno-SCE and Prague flows at 80ms
As expected, Reno-SCE shows a Reno-like throughput sawtooth, because SCE marking is not occurring at the bottleneck.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Two-flow Observations:
-
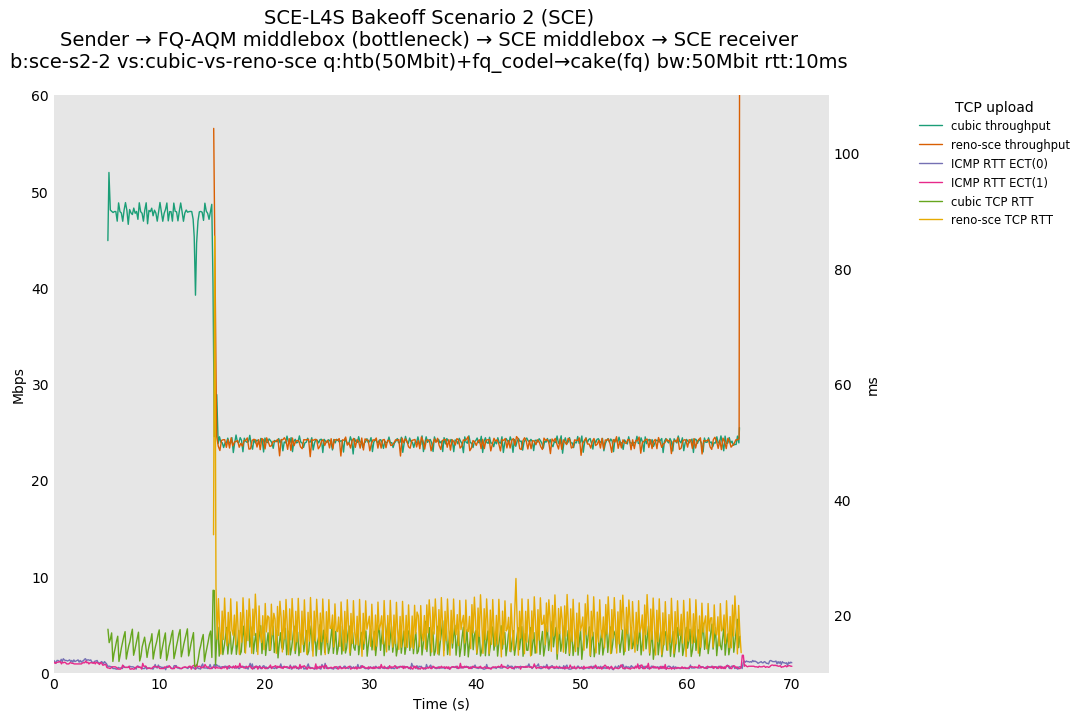
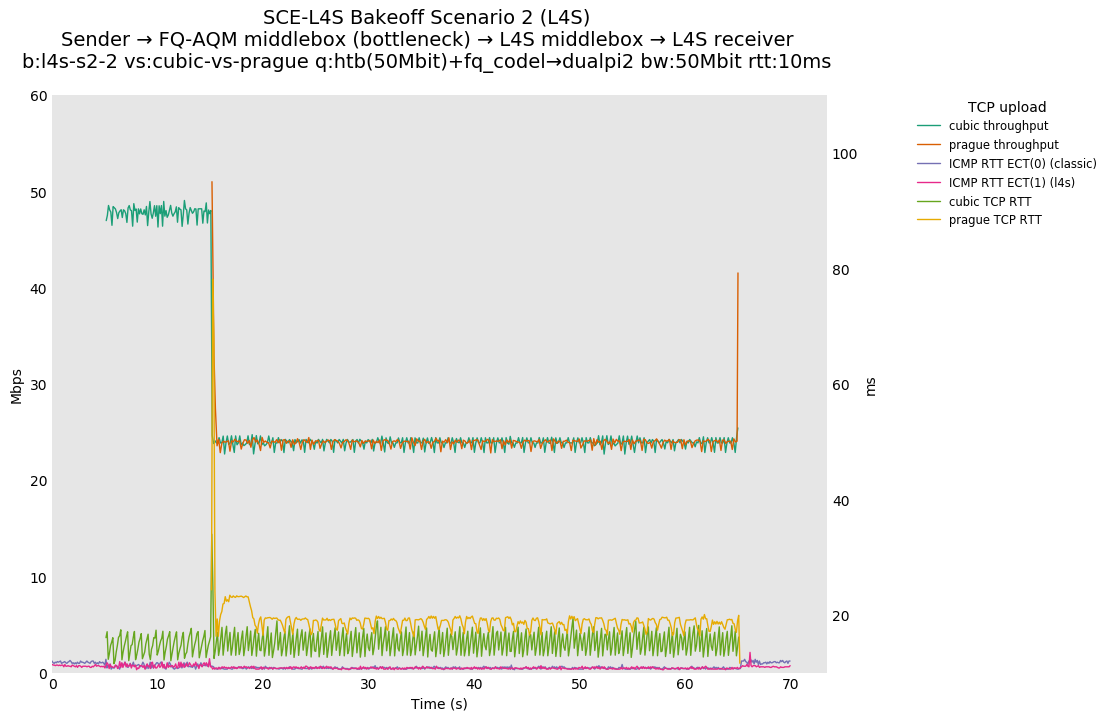
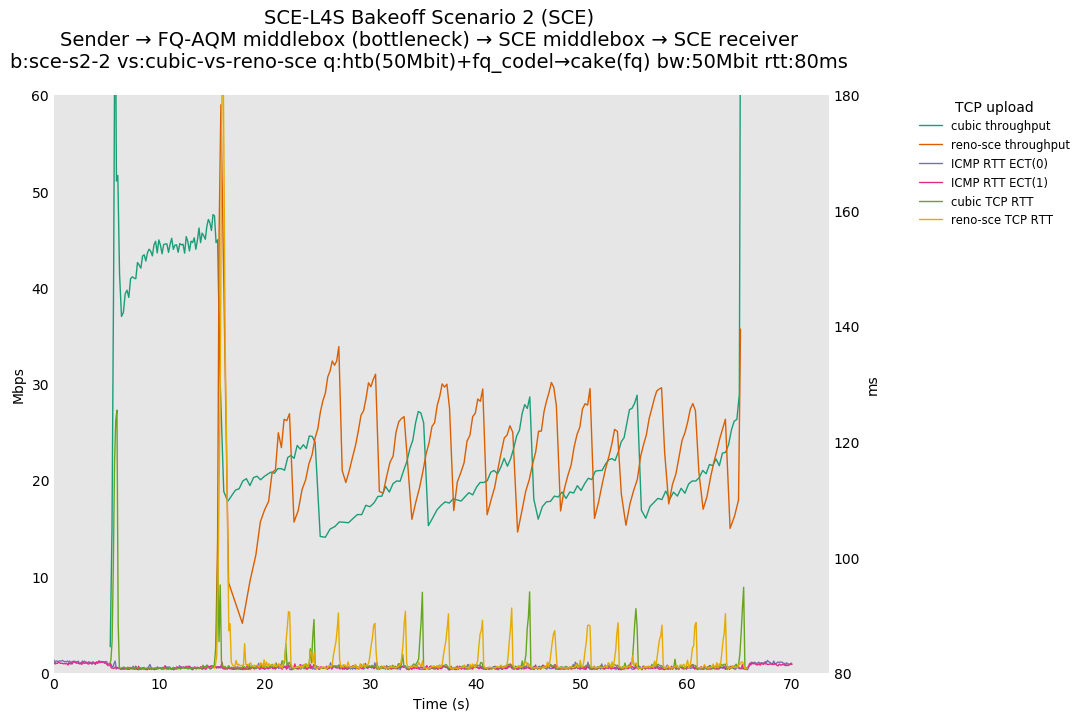
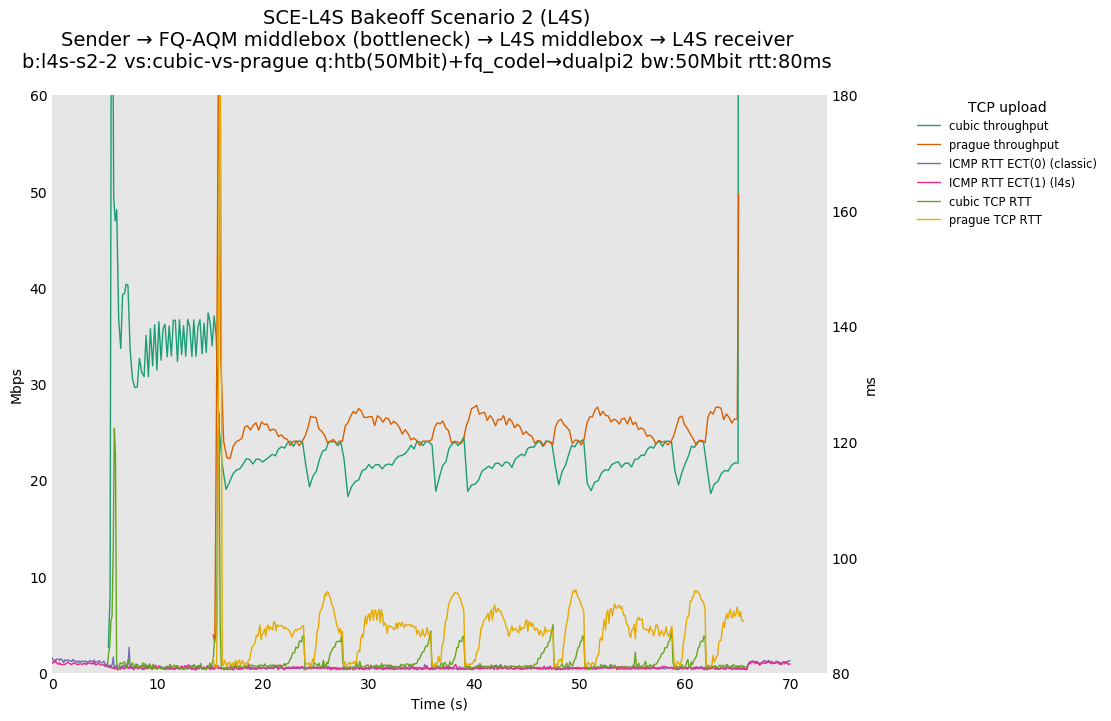
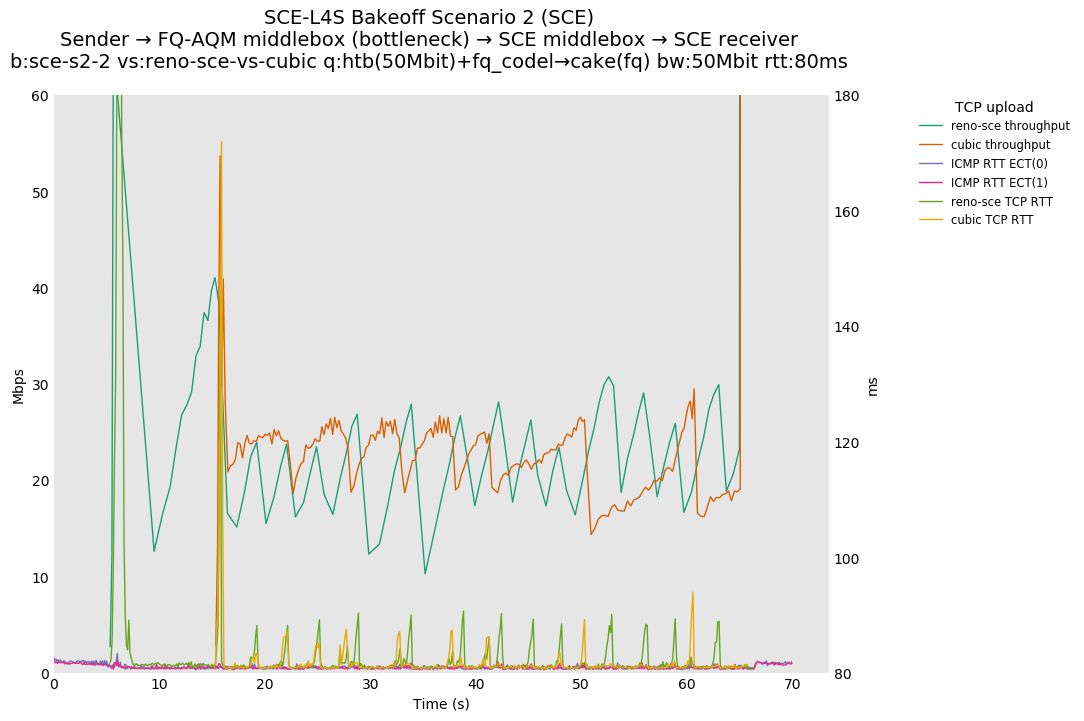
SCE vs L4S, Cubic vs Reno-SCE and Cubic vs Prague at 80ms
With this flow start order, latency spikes at flow start seem to be largely under control for both SCE and L4S.
-
SCE vs L4S, Reno-SCE vs Cubic and Prague vs Cubic at 80ms
❗ When the flow order is reversed, so that TCP Prague is after its slow-start exit, we see an ~50ms TCP RTT spike that lasts around 5 seconds.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
This scenario is obtained from topology 2 by adding the
flows 1parameter to fq_codel, making it a single queue AQM. Any queueing delays will affect all other flows in the queue.
L4S: Sender → single-AQM middlebox (bottleneck) → L4S middlebox → L4S receiver
SCE: Sender → single-AQM middlebox (bottleneck) → SCE middlebox → SCE receiver
Full results: SCE one-flow | SCE two-flow | L4S one-flow | L4S two-flow
One-flow Observations:
-
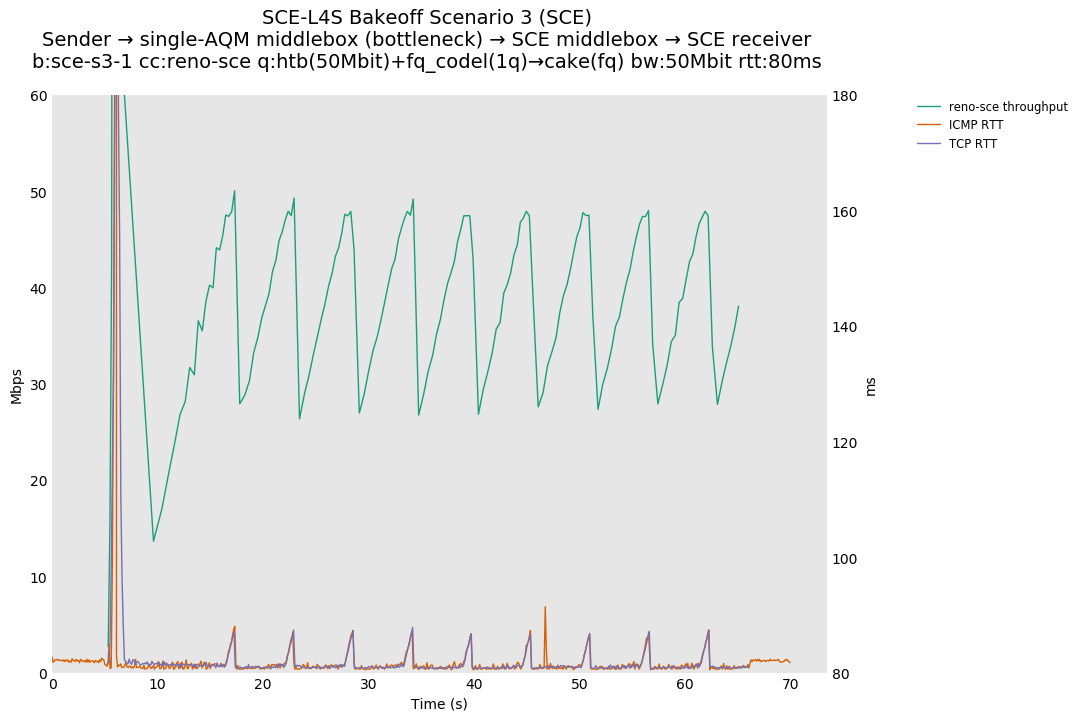
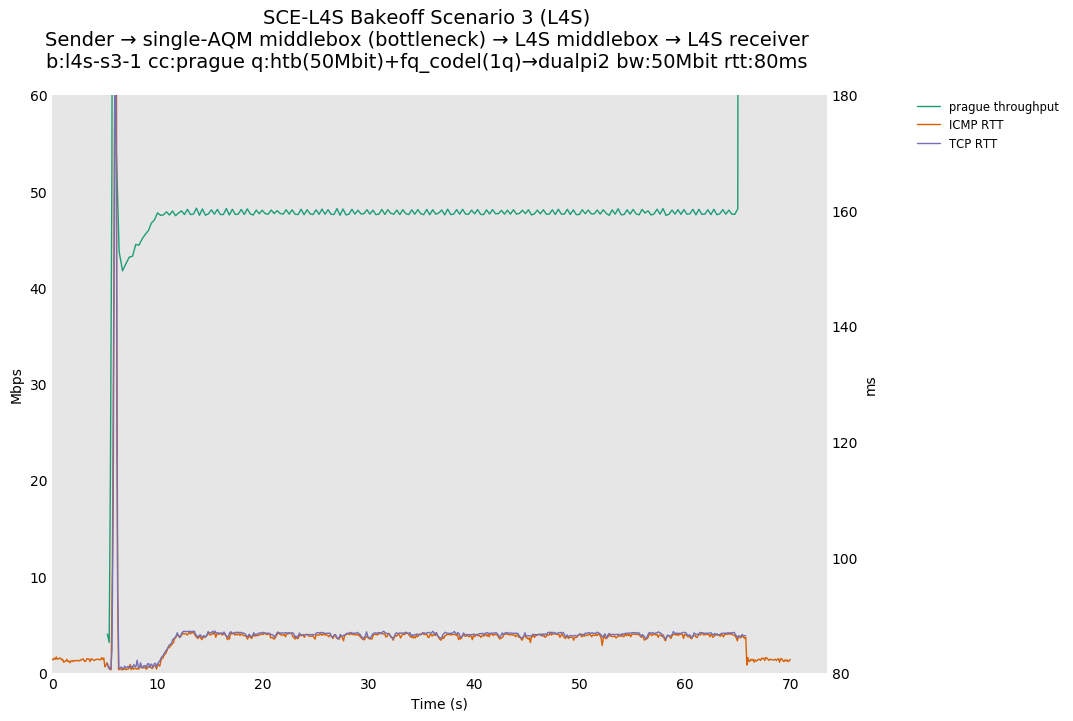
SCE FQ vs SCE 1Q and L4S FQ vs L4S 1Q, single Reno-SCE or Prague flow at 80ms
As expected, for SCE, moving to a single queue makes the short spike in RTT equivalent for ICMP and TCP, as there is no longer fair queueing or sparse flow optimization.
{kind=link}
{kind=link}
Two-flow Observations:
-
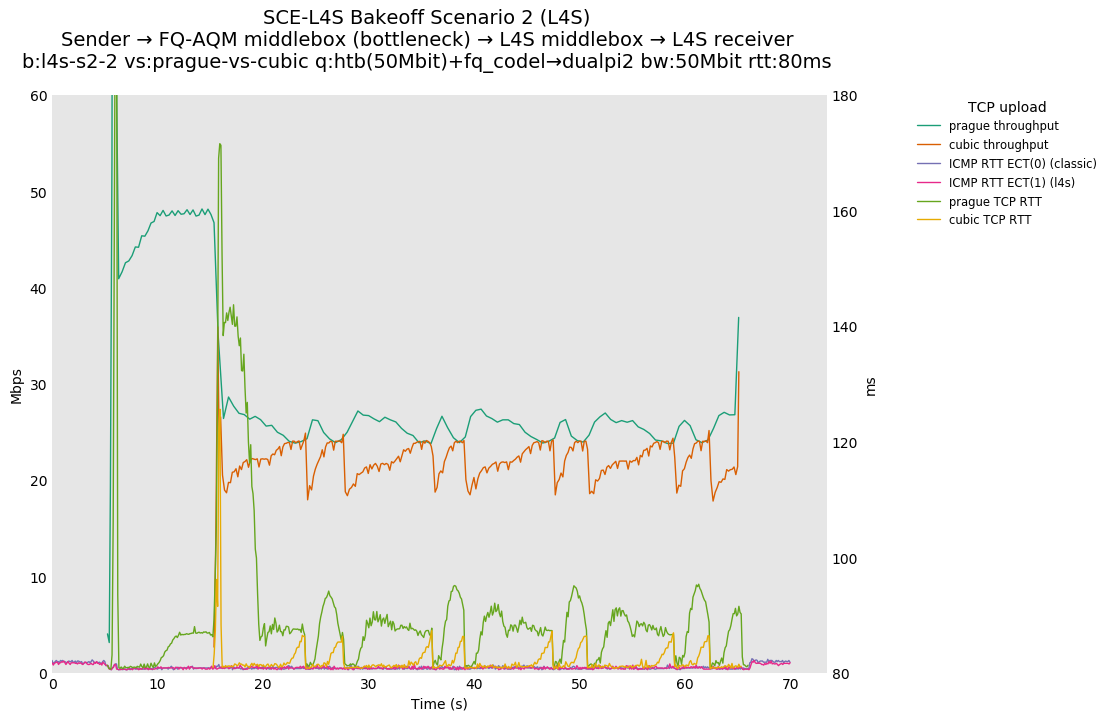
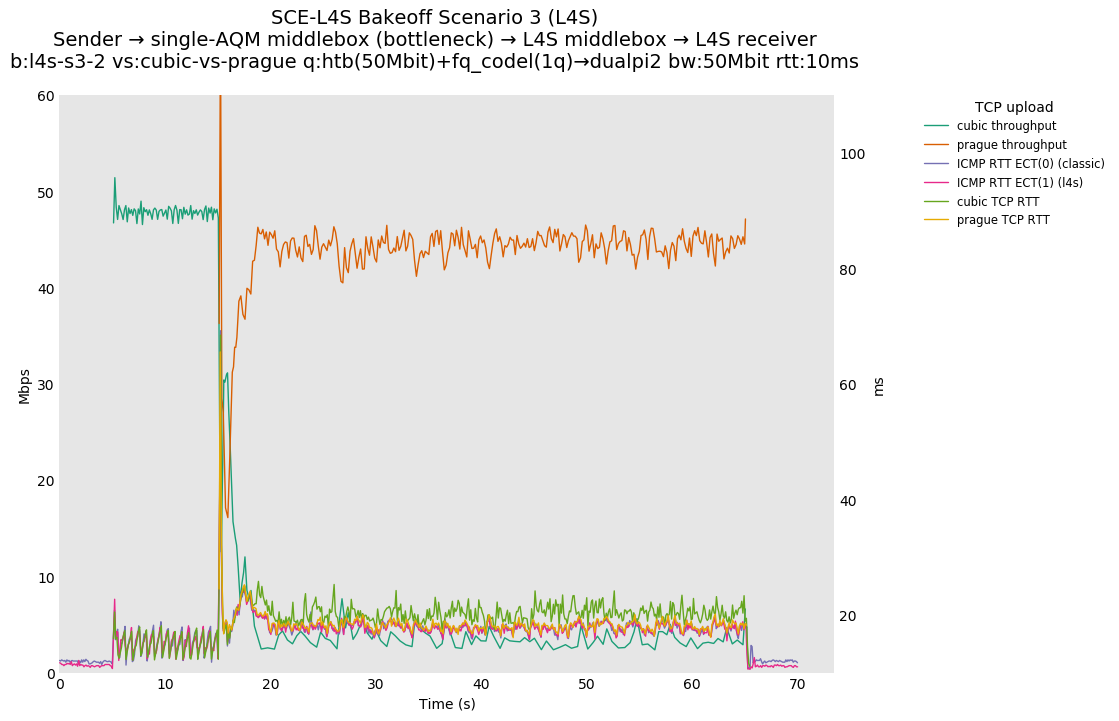
SCE vs L4S, Cubic vs Reno-SCE and Cubic vs Prague at 10ms
For SCE, Reno-SCE's mean throughput is about 1.5x that of Cubic, due to the use of the ABE response to CE described in RFC 8511. Whether or not this is acceptable is a discussion that should happen as part of the ABE standardization process.
❗ For L4S, TCP Prague's mean throughput is ~7.5x that of Cubic, due to the redefinition of CE and its assumption that the CE mark is coming from an L4S aware AQM. We hypothesize that this may also be a problem with other existing AQMs, such as PIE or RED, but this will be tested at a later time.
The potential for unfairness was hinted at in RFC 3168 Section 5, where it mentions the possible consequences of treating CE differently than drop:
If there were different congestion control responses to a CE codepoint than to a packet drop, this could result in unfair treatment for different flows.
-
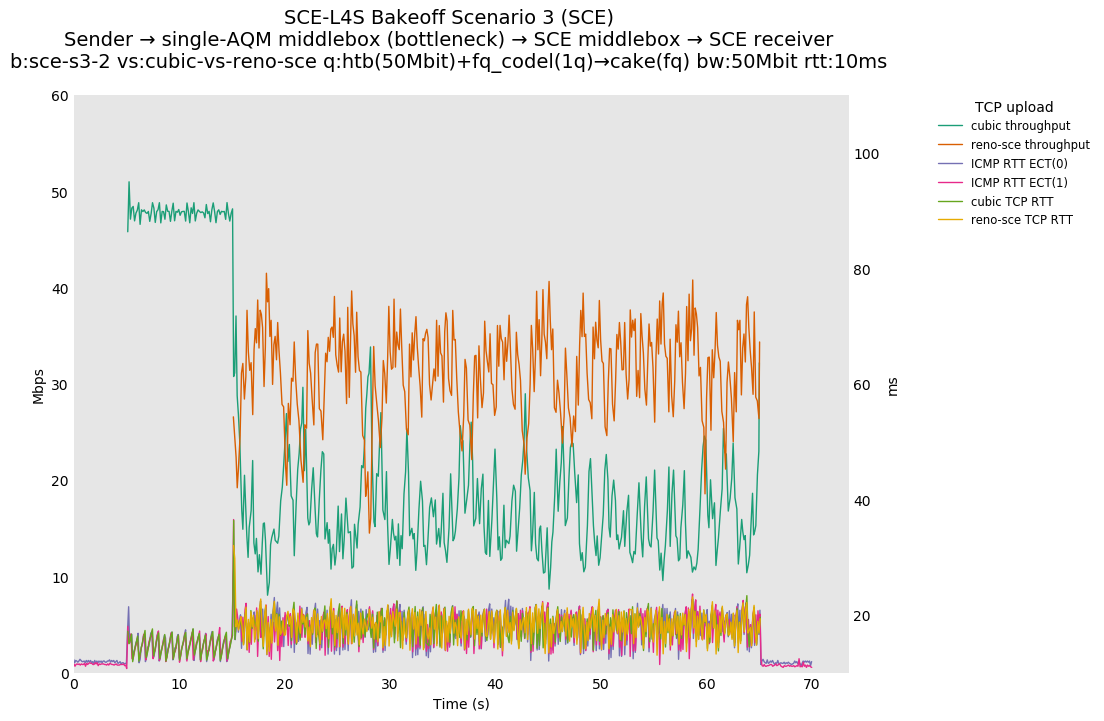
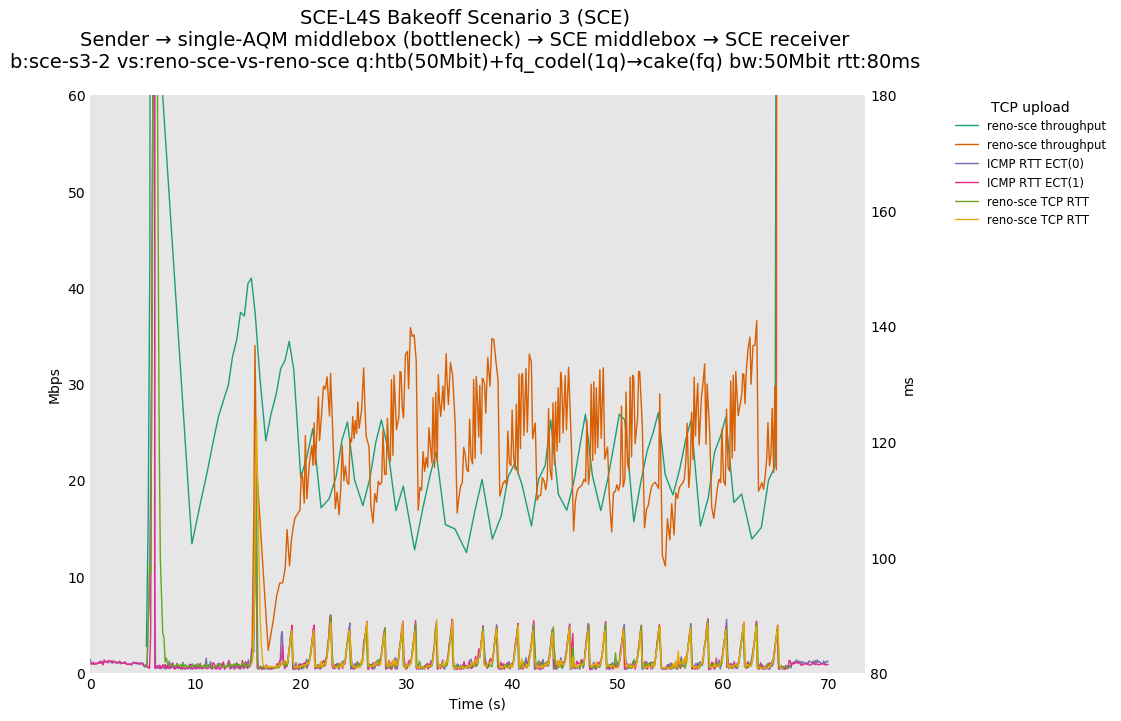
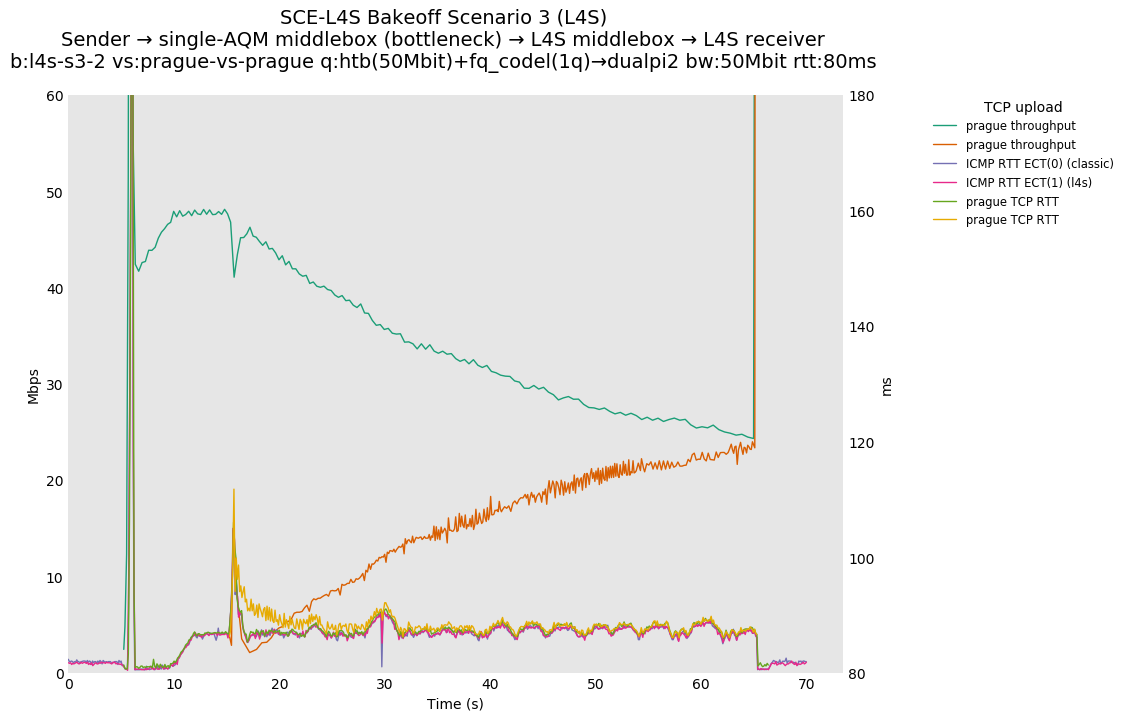
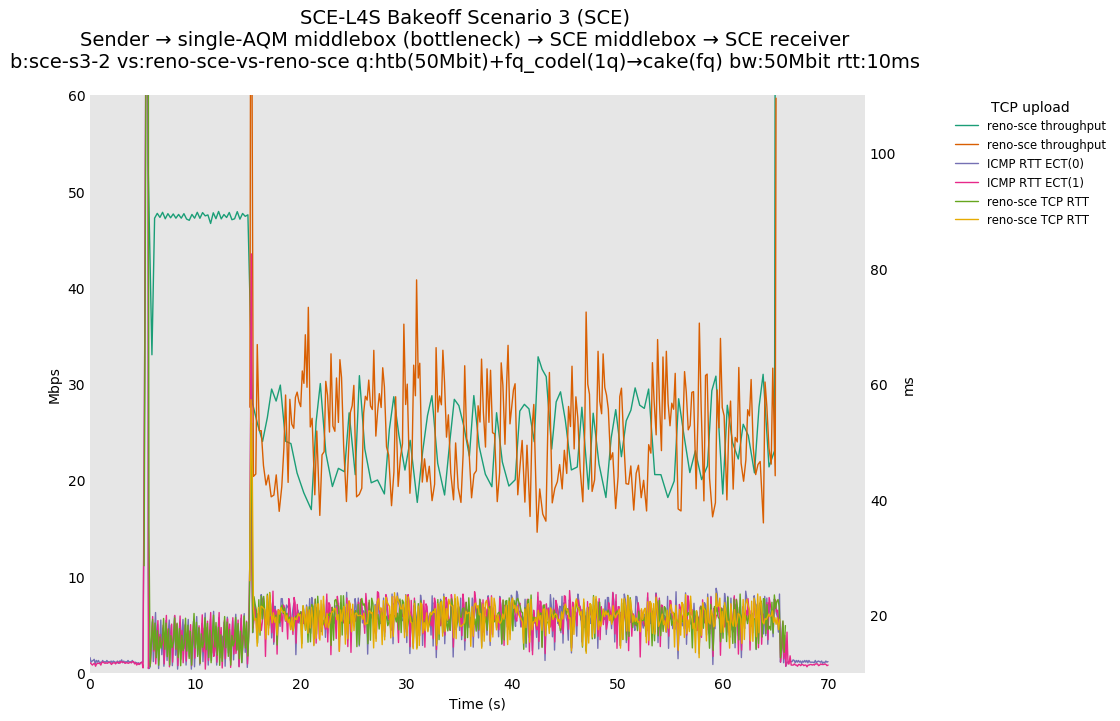
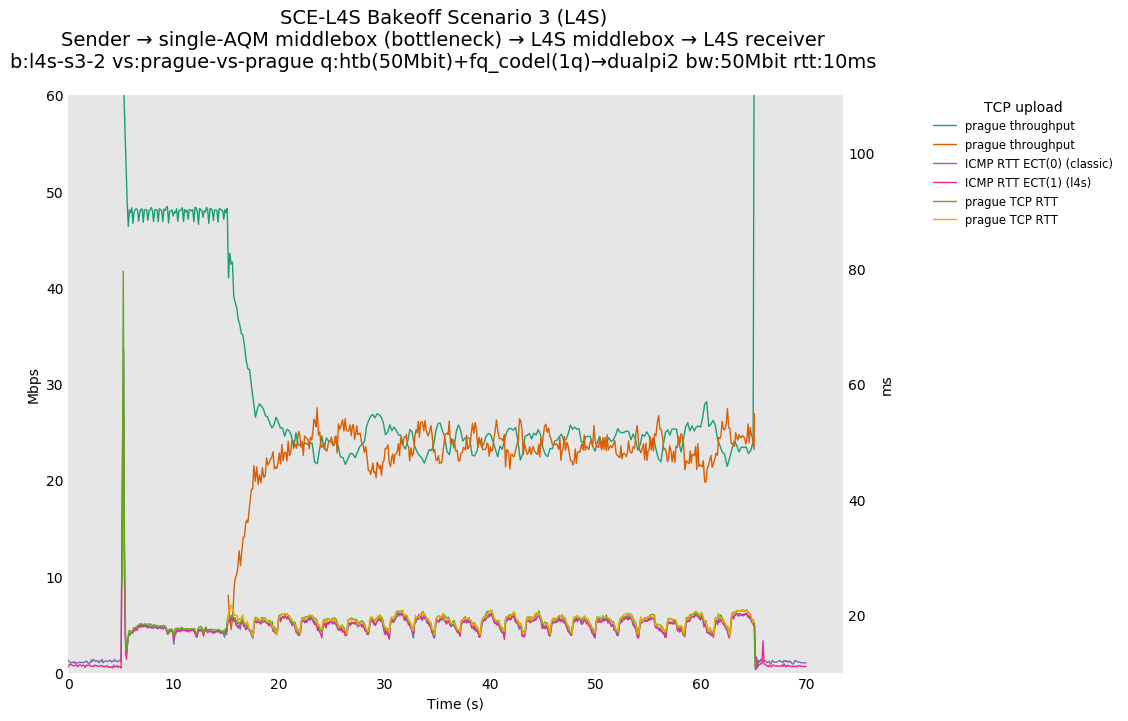
SCE vs L4S, Reno-SCE vs Reno-SCE and Prague vs Prague at 80ms
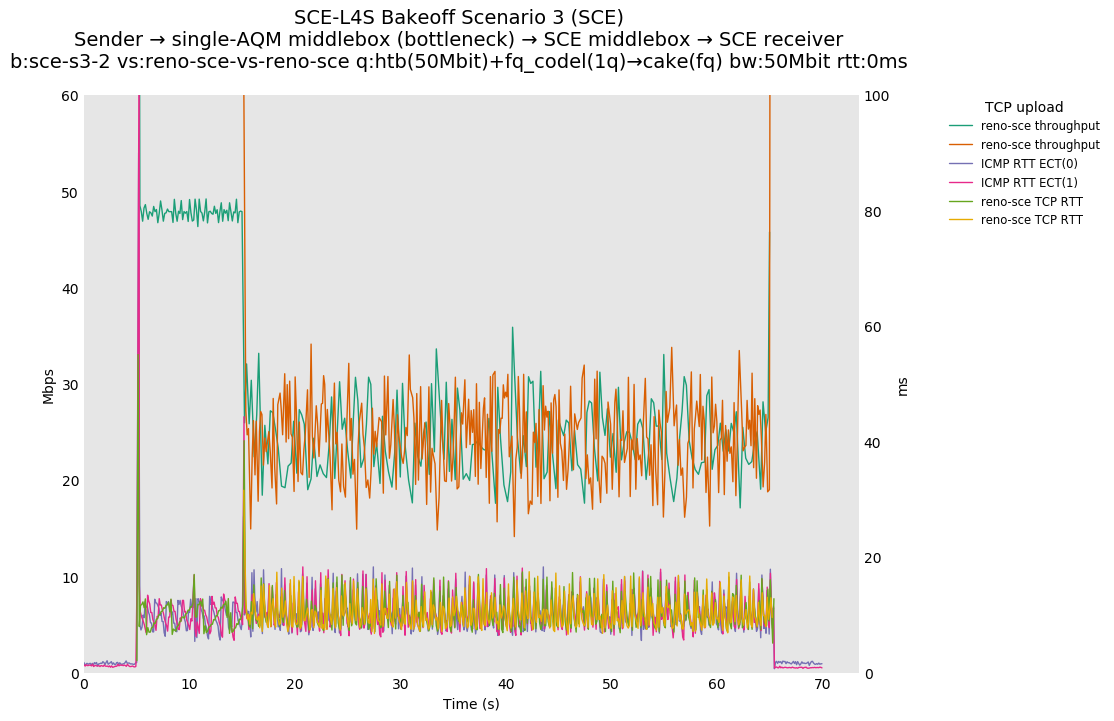
Reno-SCE vs Reno-SCE shows approximate throughput fairness in a single queue at an RTT delay of 80ms, as well as 0ms and 10ms, where convergence seems to occur in under 1 second in both cases.
❗ TCP Prague vs TCP Prague shows high convergence times in this case, appearing to extend beyond the 50 second interaction between the two flows. Convergence at 10ms appears to take around 5 seconds, as opposed to ~1 second for SCE.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
This explores what happens if an adversary tries to game the system by forcing ECT(1) on all packets.
L4S: Sender → ECT(1) mangler → L4S middlebox (bottleneck) → L4S receiver
SCE: Sender → ECT(1) mangler → SCE middlebox (bottleneck) → SCE receiver
Full results: SCE one-flow | SCE two-flow | L4S one-flow | L4S two-flow
One-flow Observations:
-
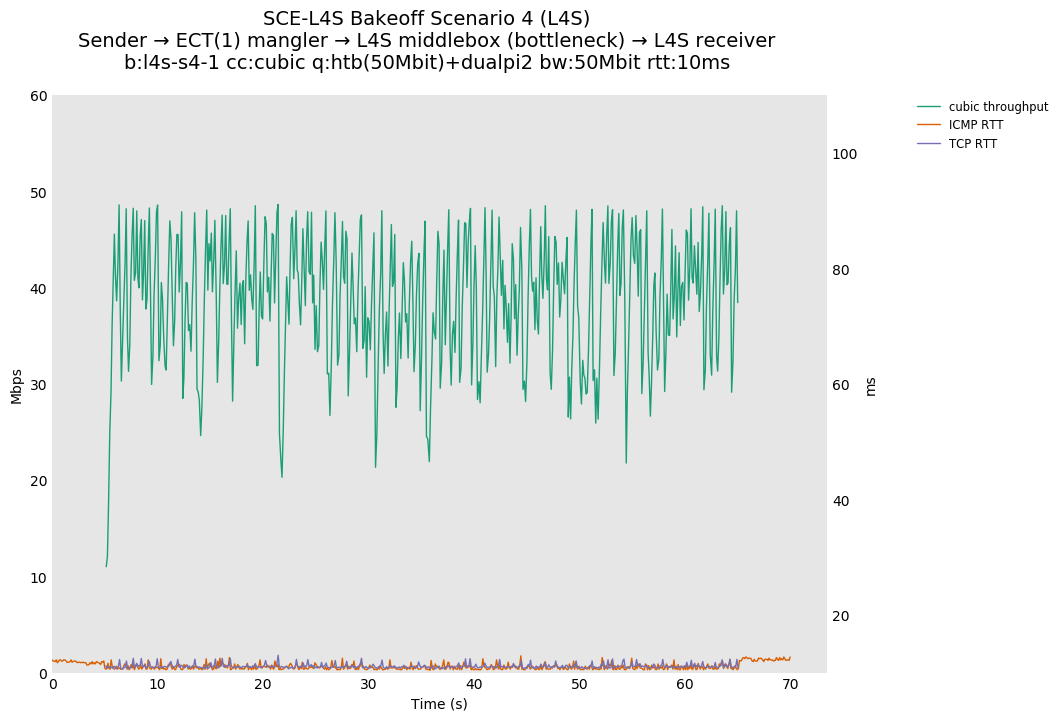
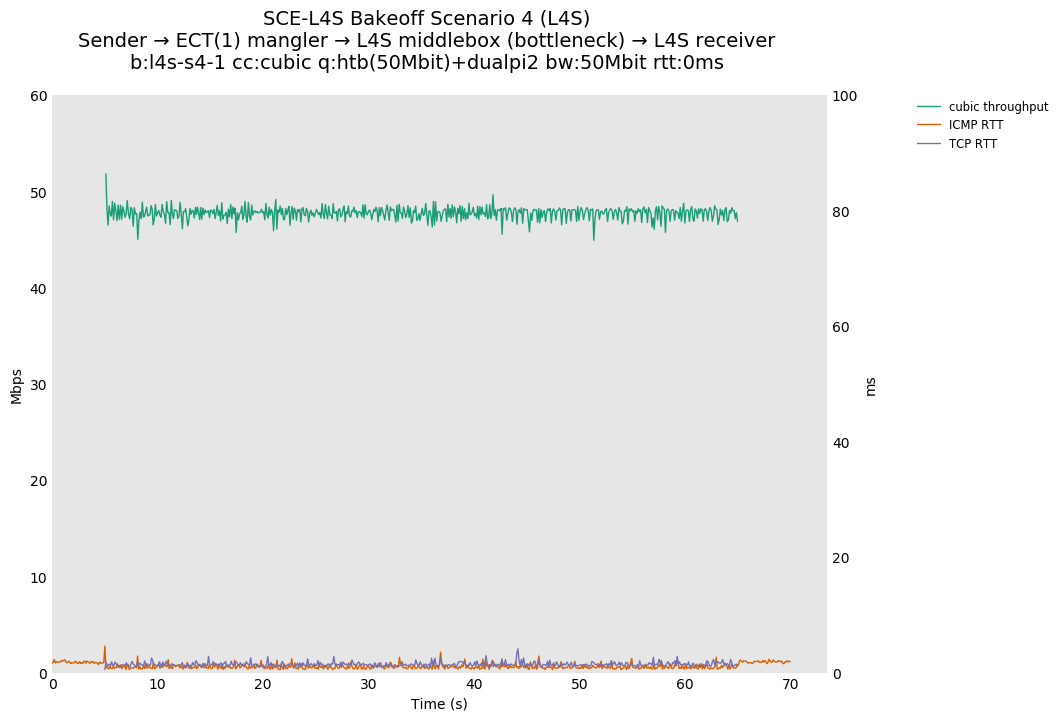
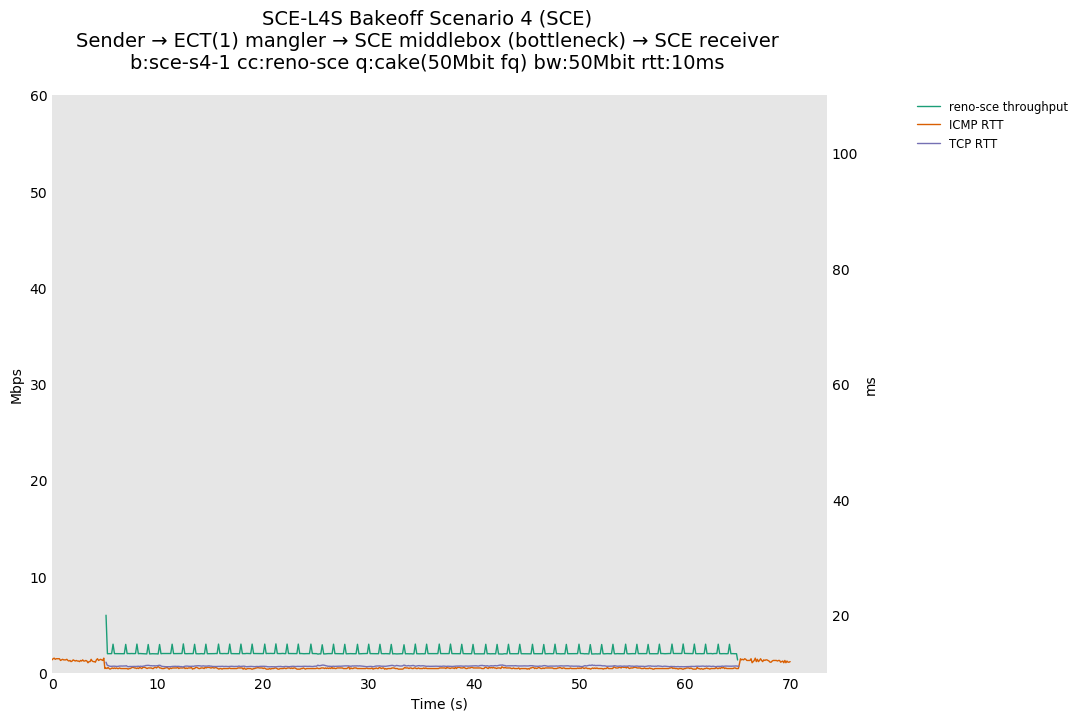
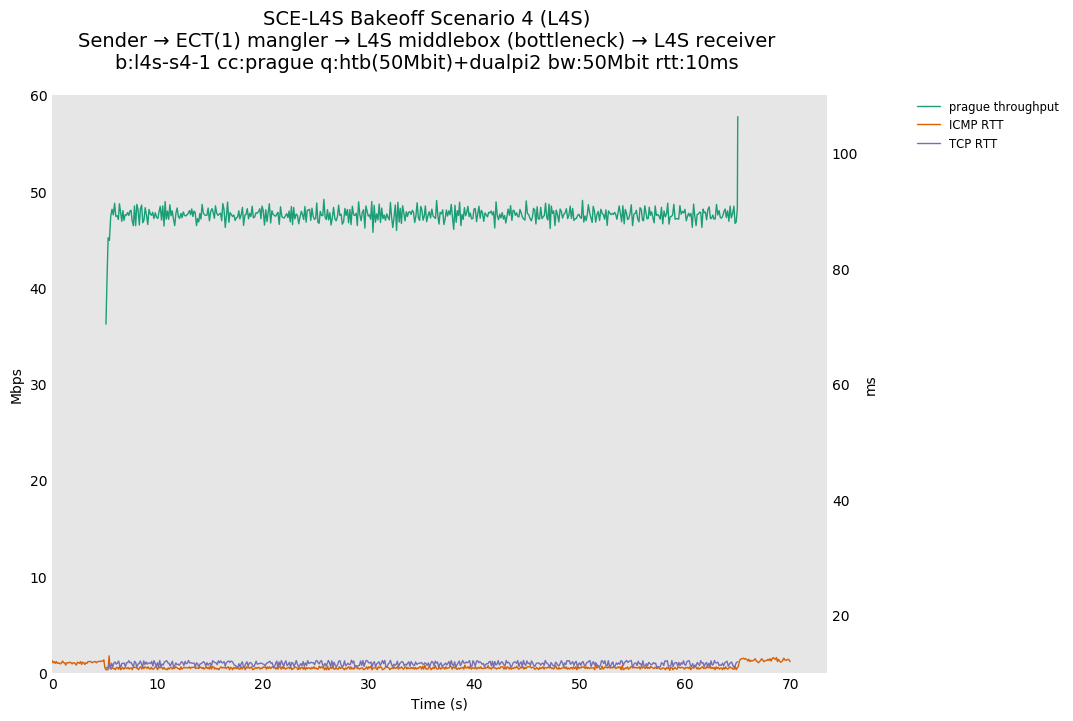
SCE vs L4S, single Cubic flow at 80ms
For SCE, Cubic is unaffected by setting ECT(1) on all packets.
For L4S, setting ECT(1) on all packets places them in the L queue, causing a drop in utilization that increases as the RTT delay goes up (compare with 10ms and 0ms).
-
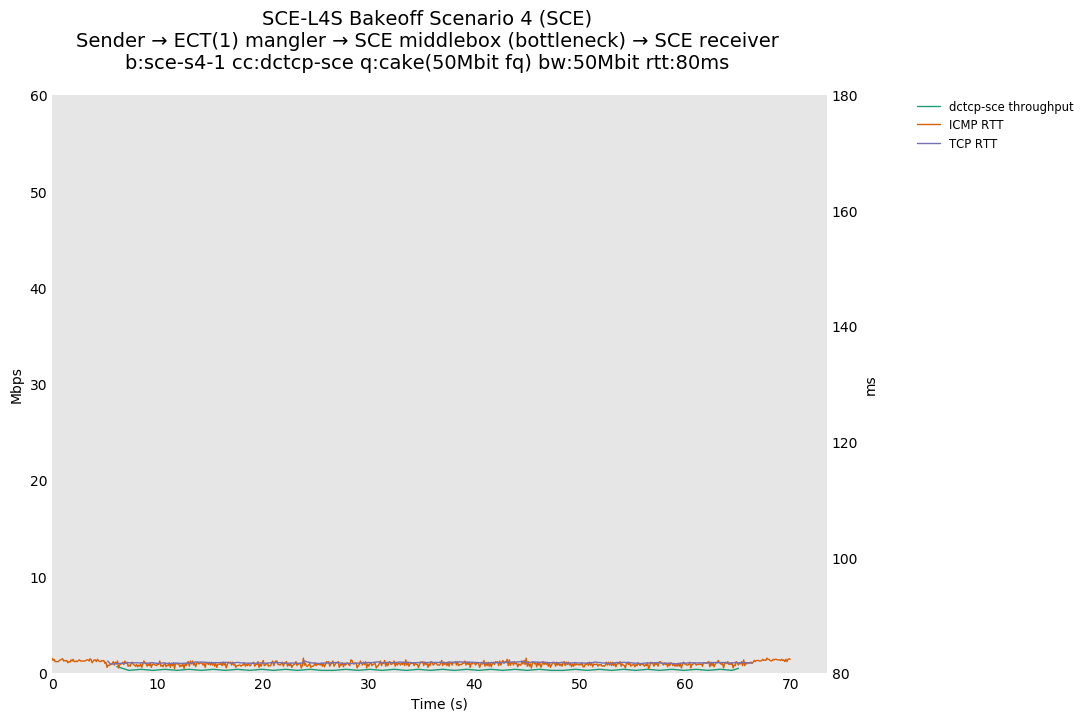
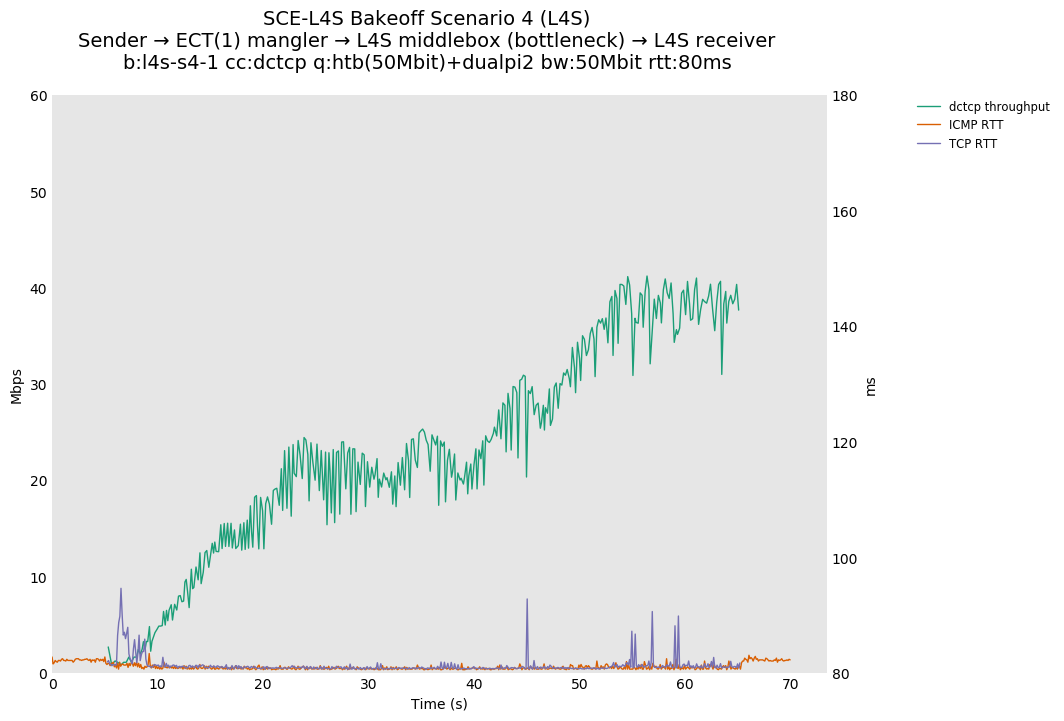
SCE vs L4S, single DCTCP-SCE or DCTCP flow at 80ms
As expected, setting ECT(1) on all packets causes a collapse in throughput for DCTCP-SCE, as there is a cwnd reduction for each ACK, limited to a minimum cwnd of two segments (however, with the 40% CA scale factor for pacing, this is effectively 0.8 from a throughput standpoint).
For L4S, setting ECT(1) on all packets causes a drop in utilization for DCTCP that's RTT dependent, similar to Cubic.
-
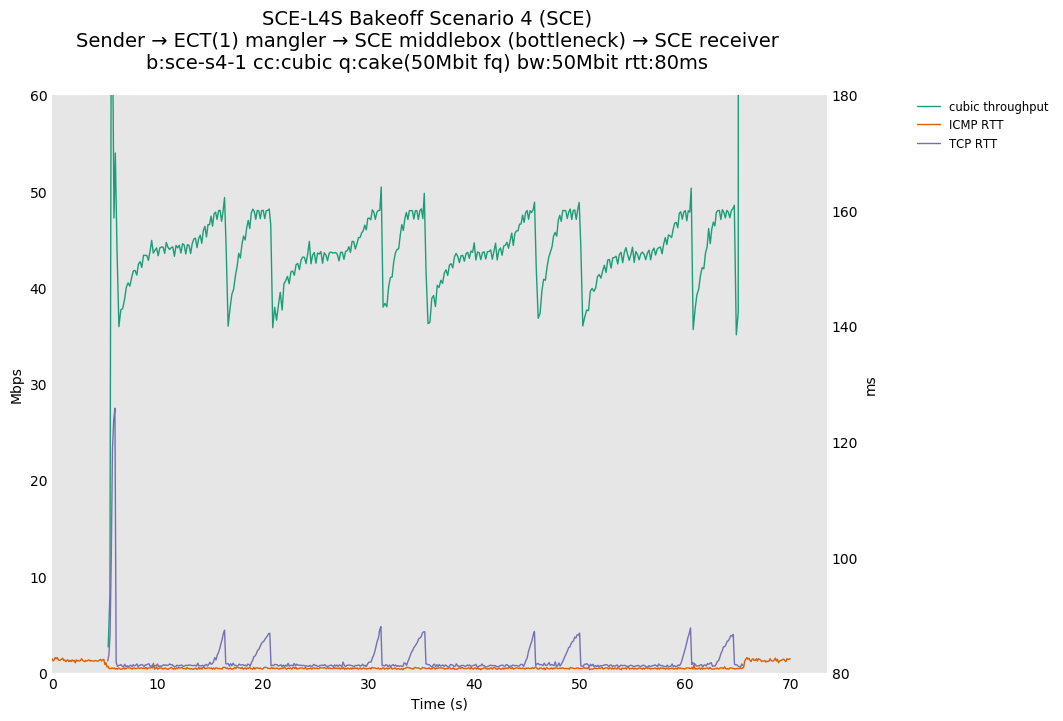
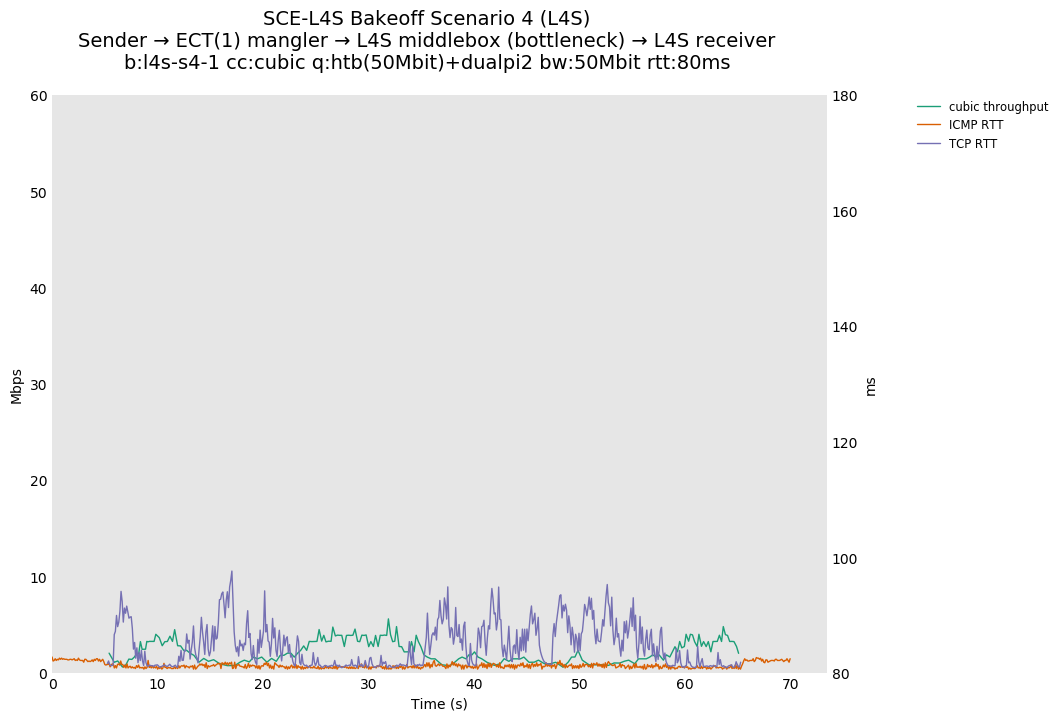
SCE vs L4S, single Reno-SCE or Prague flow at 80ms
We see the similar throughput collapse for SCE.
L4S is unaffected because TCP Prague marks ECT(1) anyway.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Two-flow Observations:
-
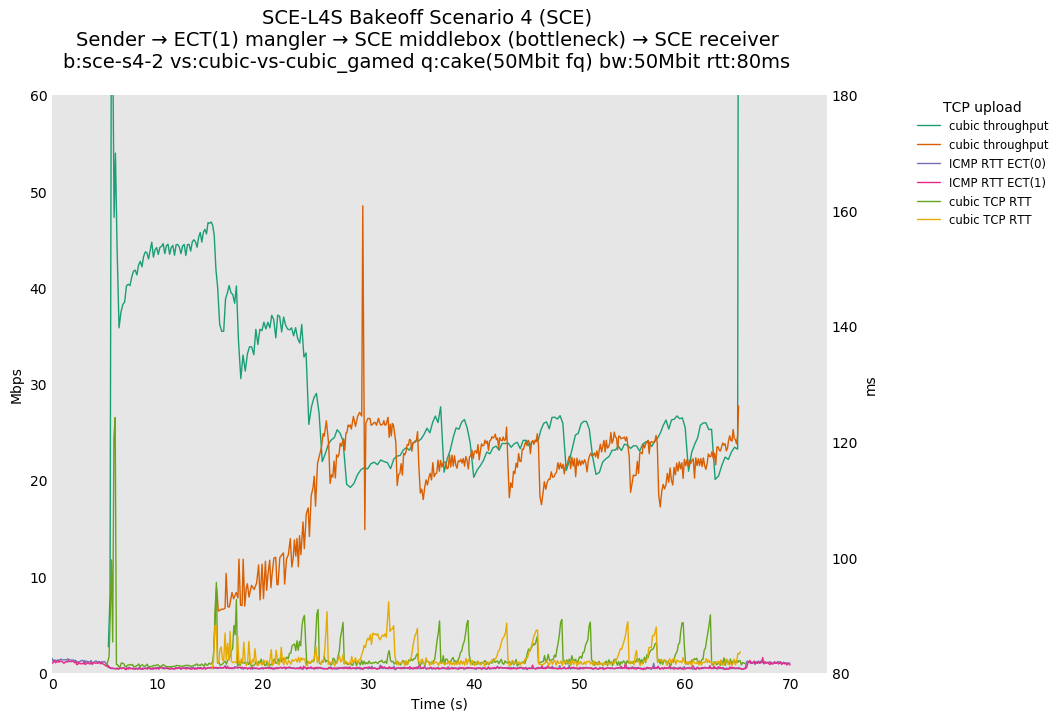
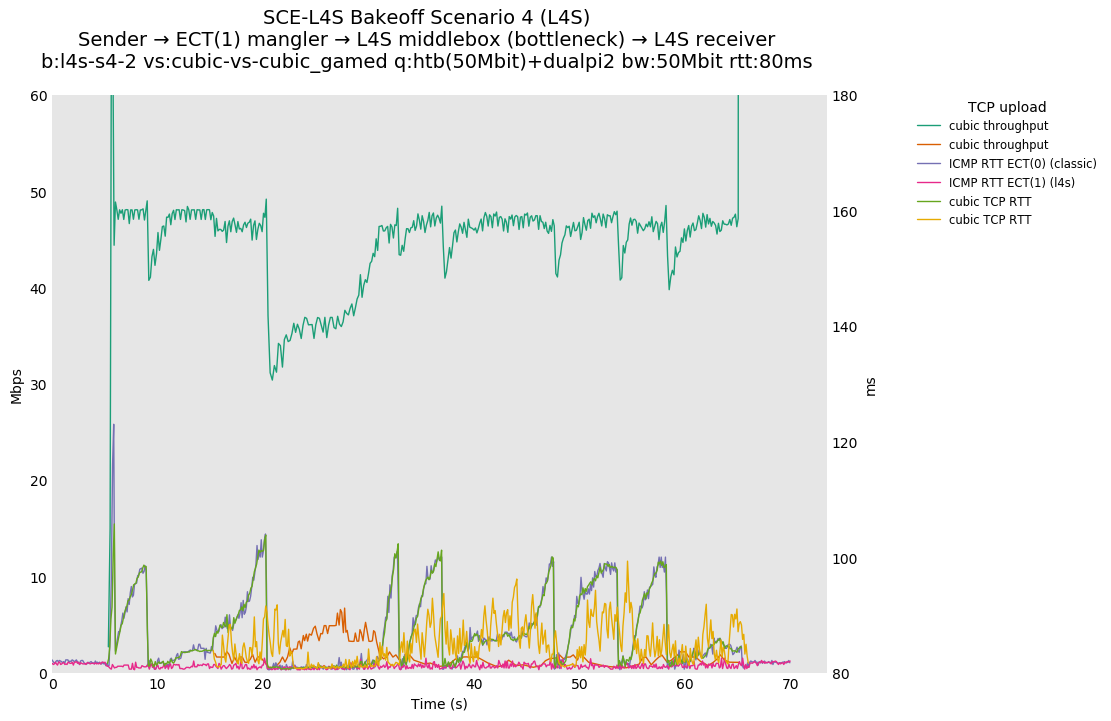
SCE vs L4S, Cubic vs Cubic "Gamed" at 80ms
For SCE, Cubic is unaffected by the setting of ECT(1), so the result is the same as if there were no gaming.
For L4S, the gamed flow sees a reduction in utilization that causes it to have lower throughput than the un-gamed flow, which should discourage gaming in this basic way.
{kind=link}
{kind=link}
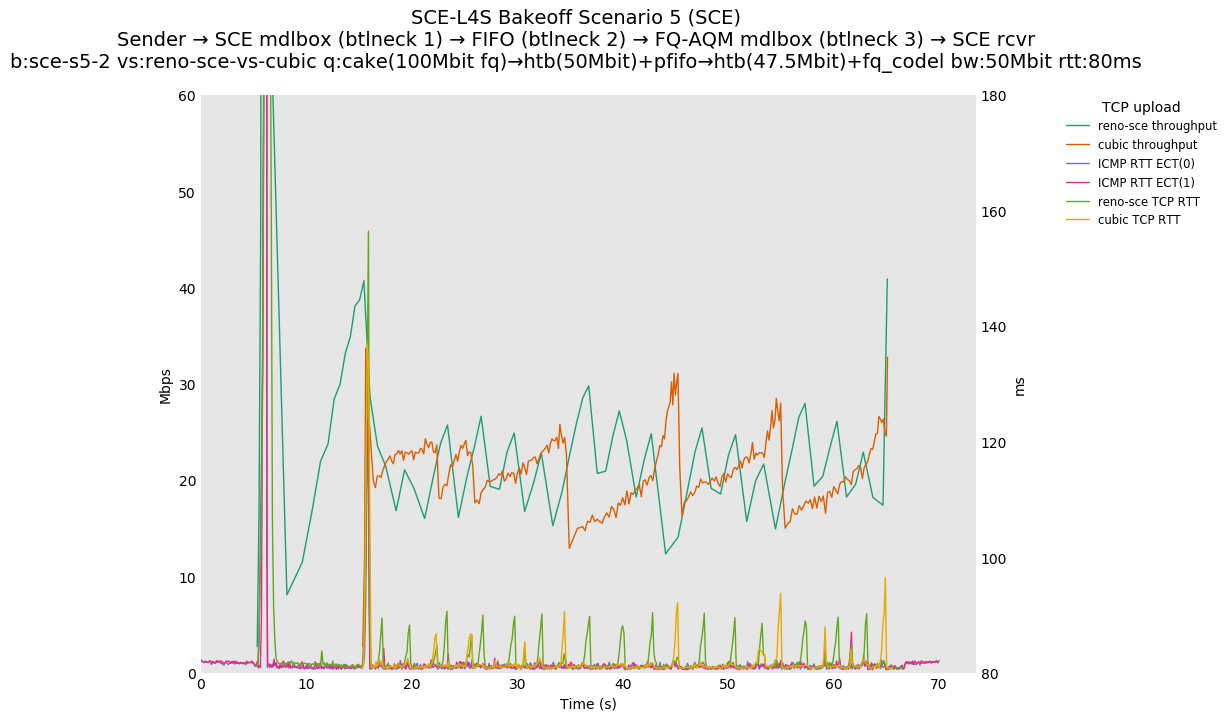
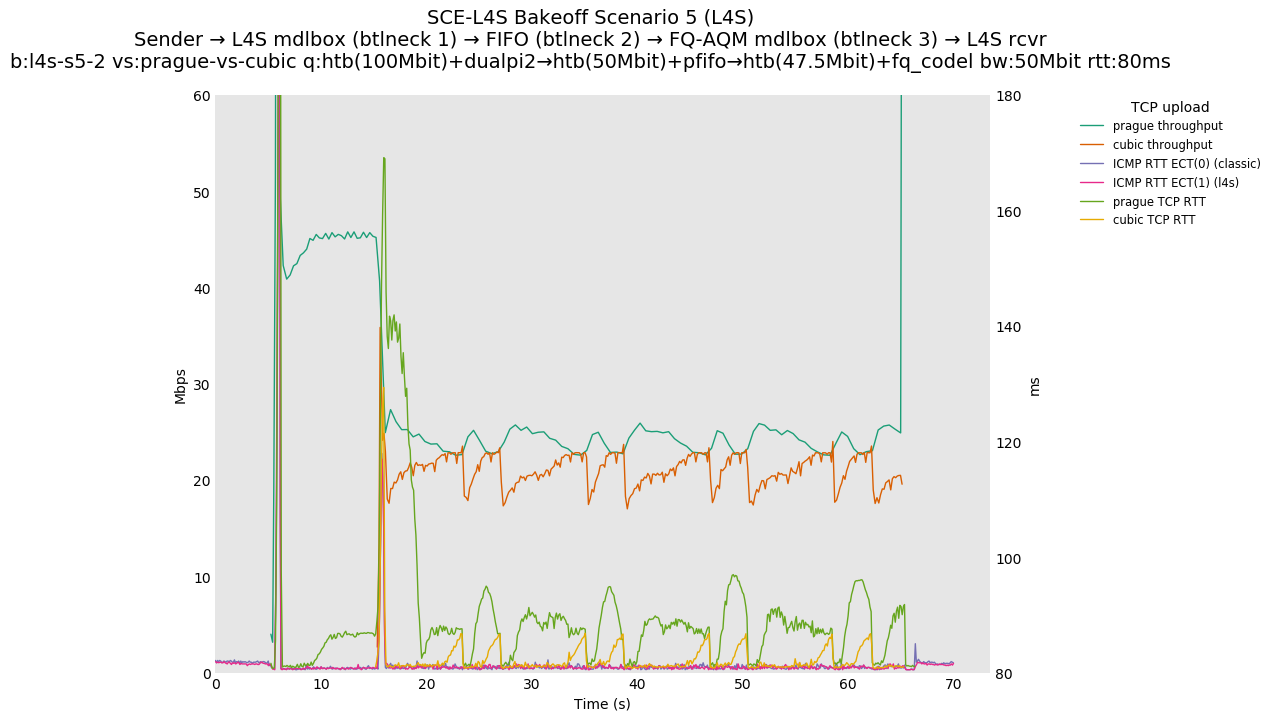
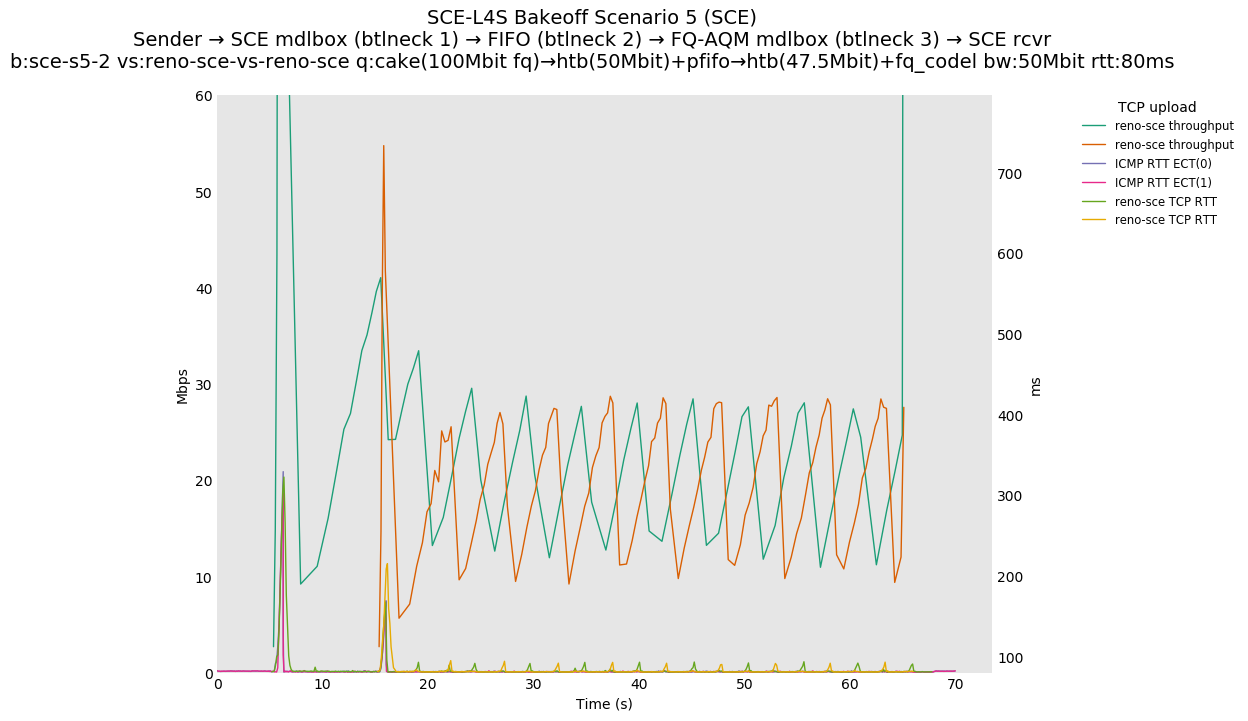
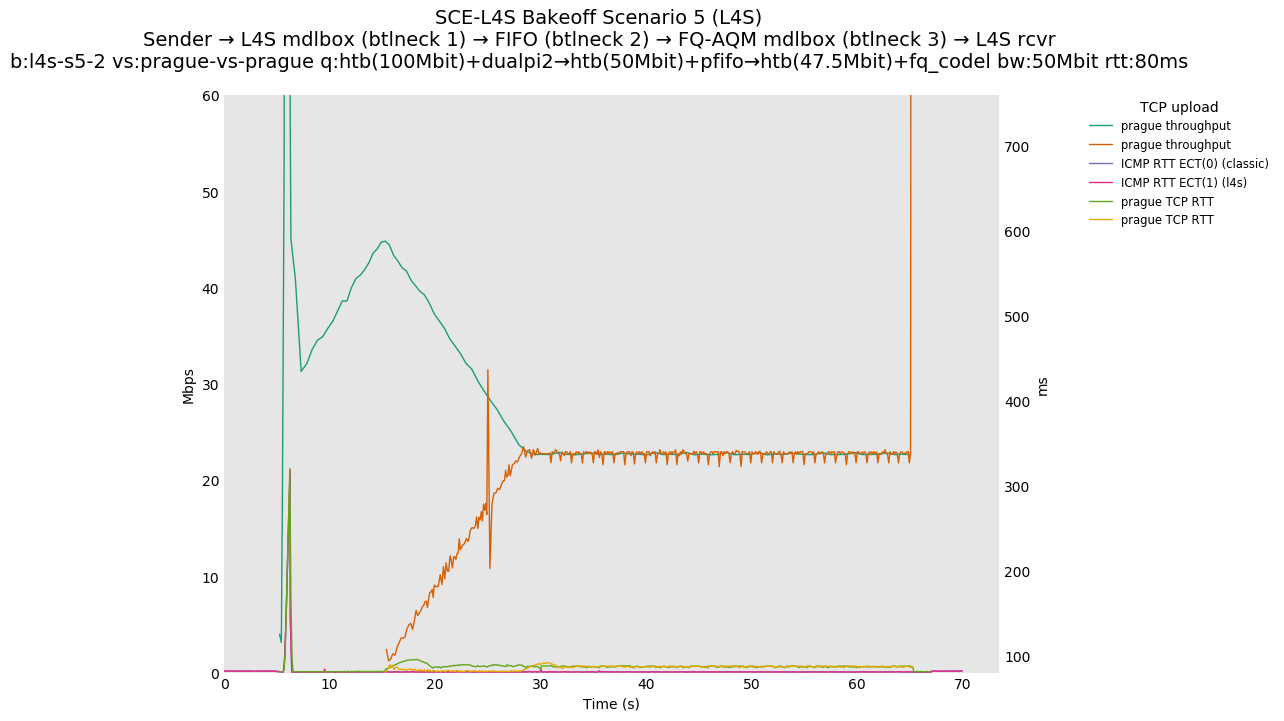
This is Sebastian Moeller's scenario. We had some discussion about the propensity of existing senders to produce line-rate bursts, and the way these bursts could collect in all of the queues at successively decreasing bottlenecks. This is a test which explores the effects of that scenario, and is relevant to best consumer practice on today's Internet.
L4S: Sender → L4S middlebox (bottleneck #1, 100Mbit) → FIFO middlebox (bottleneck #2, 50Mbit) → FQ-AQM middlebox (bottleneck #3, 47.5Mbit) → L4S receiver
SCE: Sender → SCE middlebox (bottleneck #1, 100Mbit) → FIFO middlebox (bottleneck #2, 50Mbit) → FQ-AQM middlebox (bottleneck #3, 47.5Mbit) → SCE receiver
Full results: SCE one-flow | SCE two-flow | L4S one-flow | L4S two-flow
One-flow Observations:
-
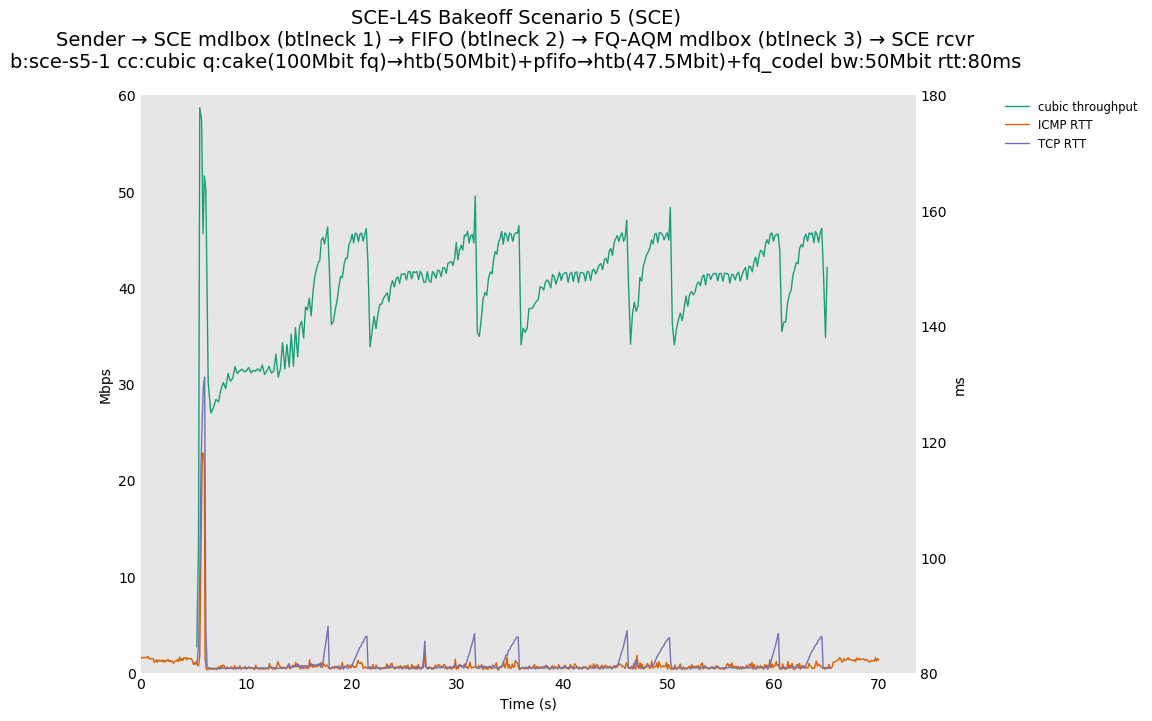
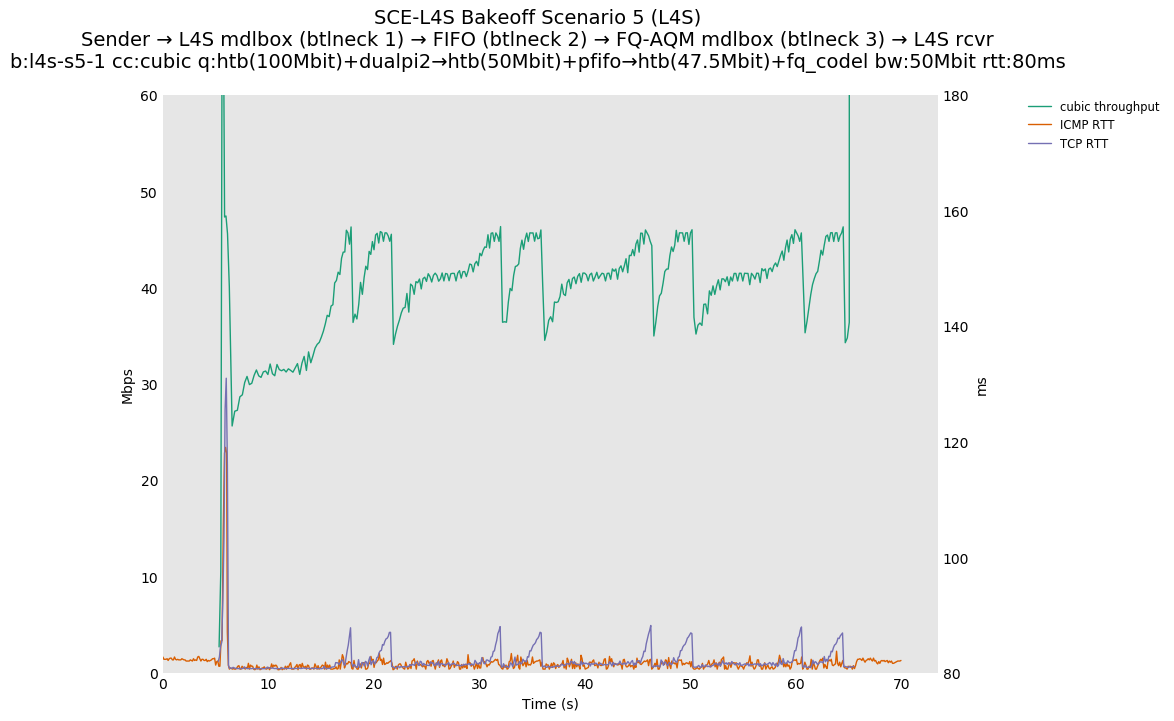
SCE vs L4S, single Cubic flow at 80ms
Both SCE and L4S see very similar latency spikes at flow startup, as the initial bottleneck (bottleneck 3) is the same.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
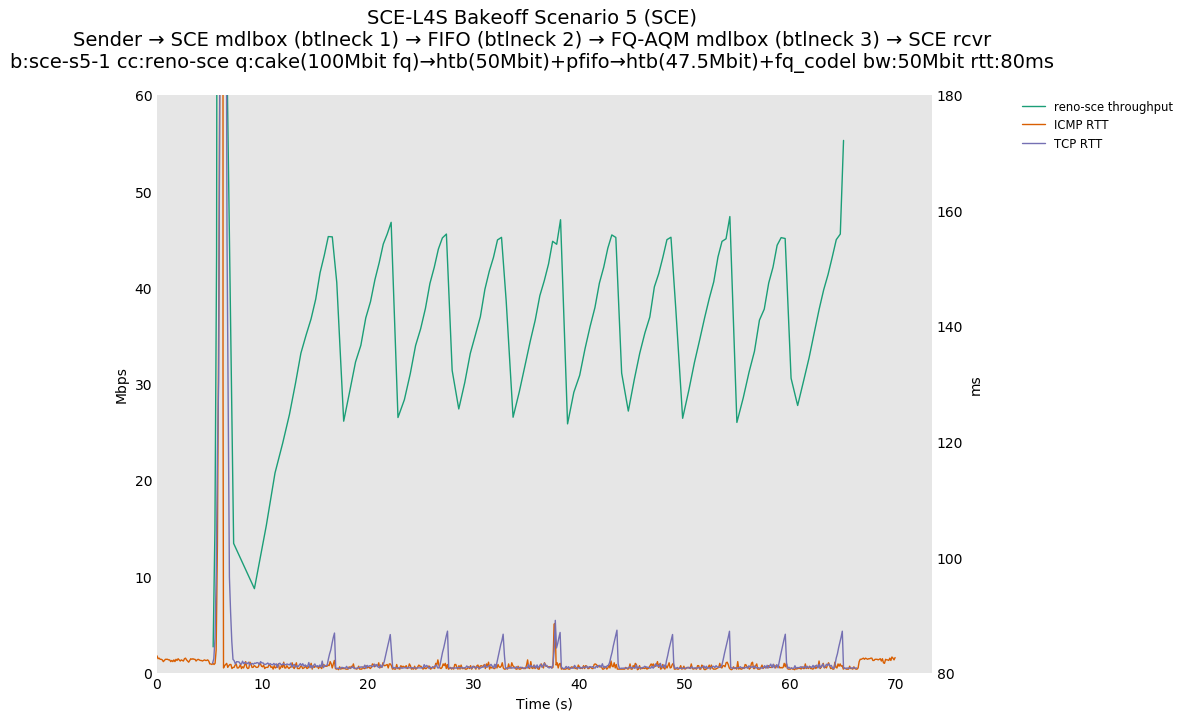{kind=link}
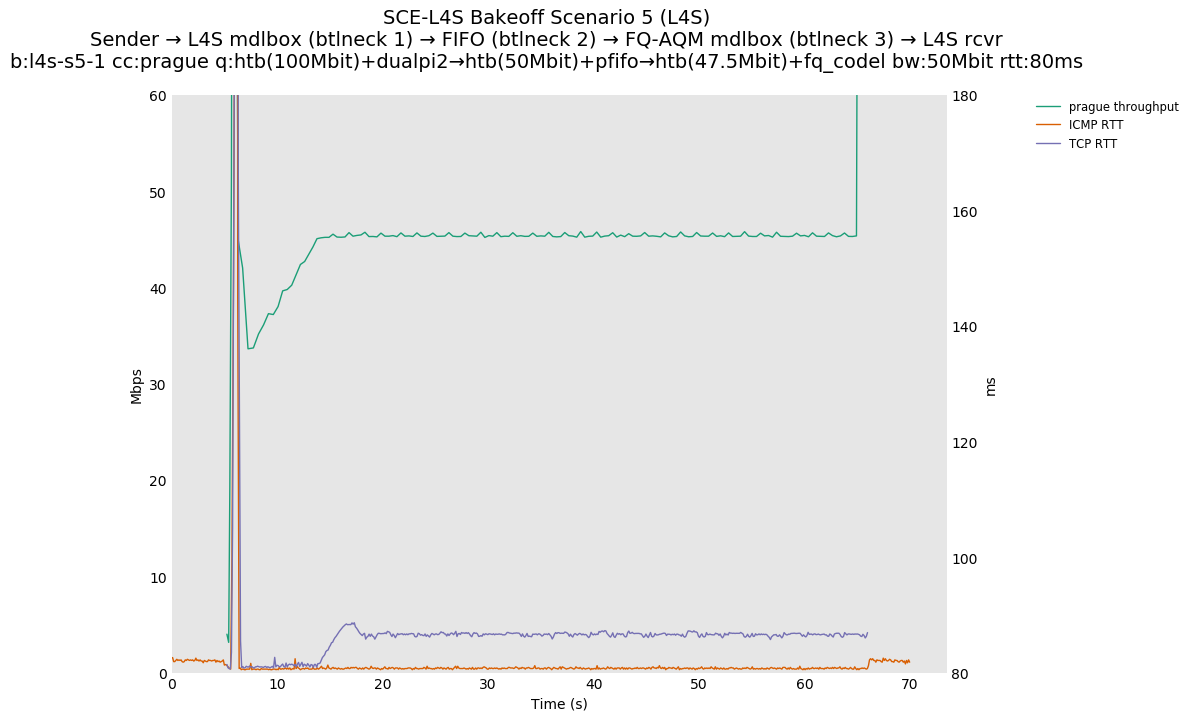{kind=link}
Two-flow Observations:
-
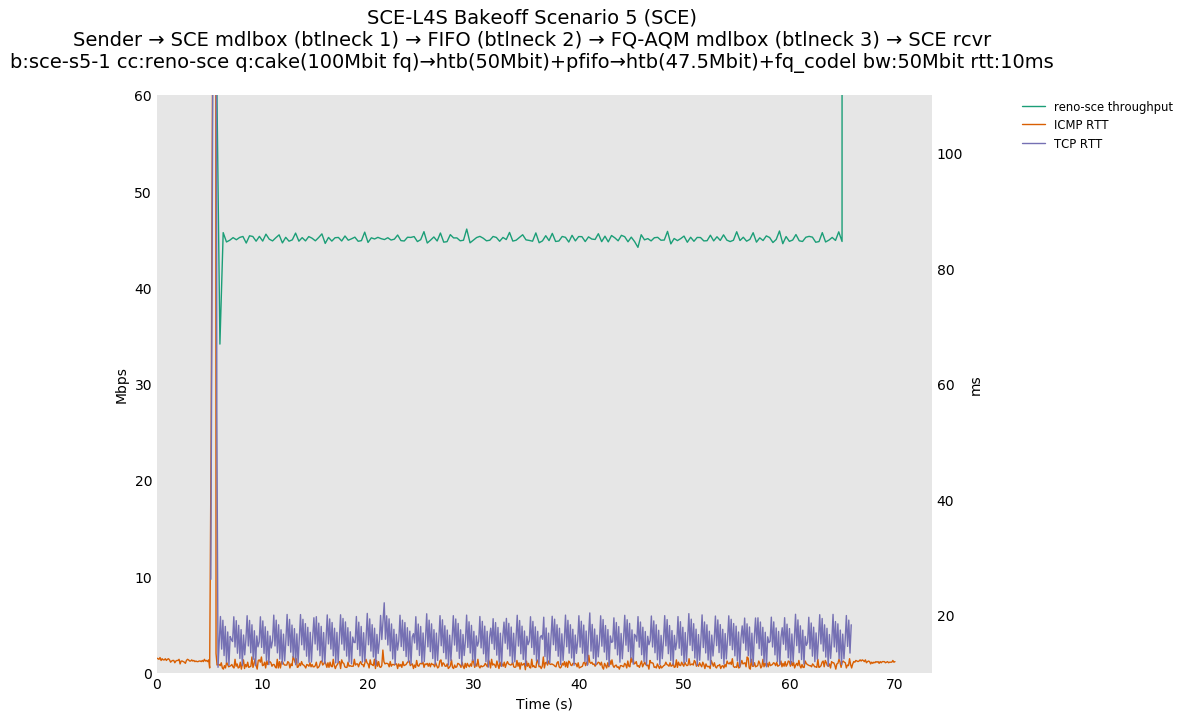
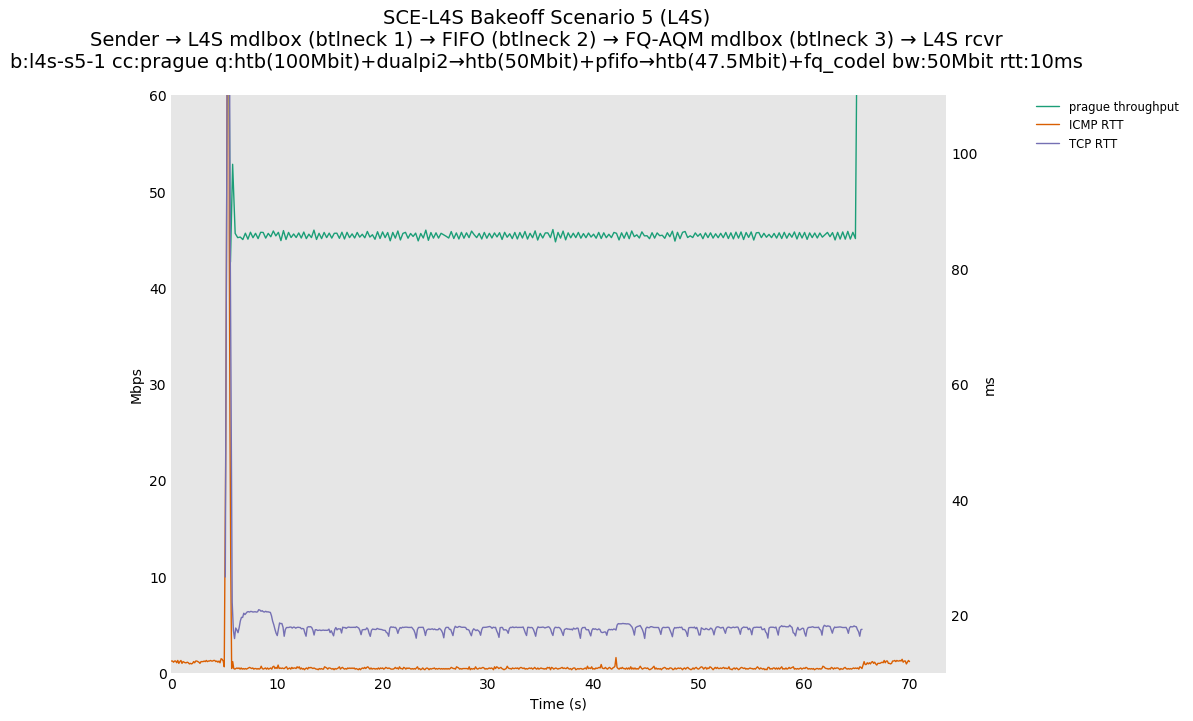
SCE vs L4S, Reno-SCE vs Cubic or Prague vs Cubic at 80ms
❗ When the flow order is reversed, so that TCP Prague is after its slow-start exit, we see an ~50ms TCP RTT spike that lasts around 4 seconds.
-
SCE vs L4S, Reno-SCE vs Reno-SCE or Prague vs Prague at 80ms, variable RTT scaling
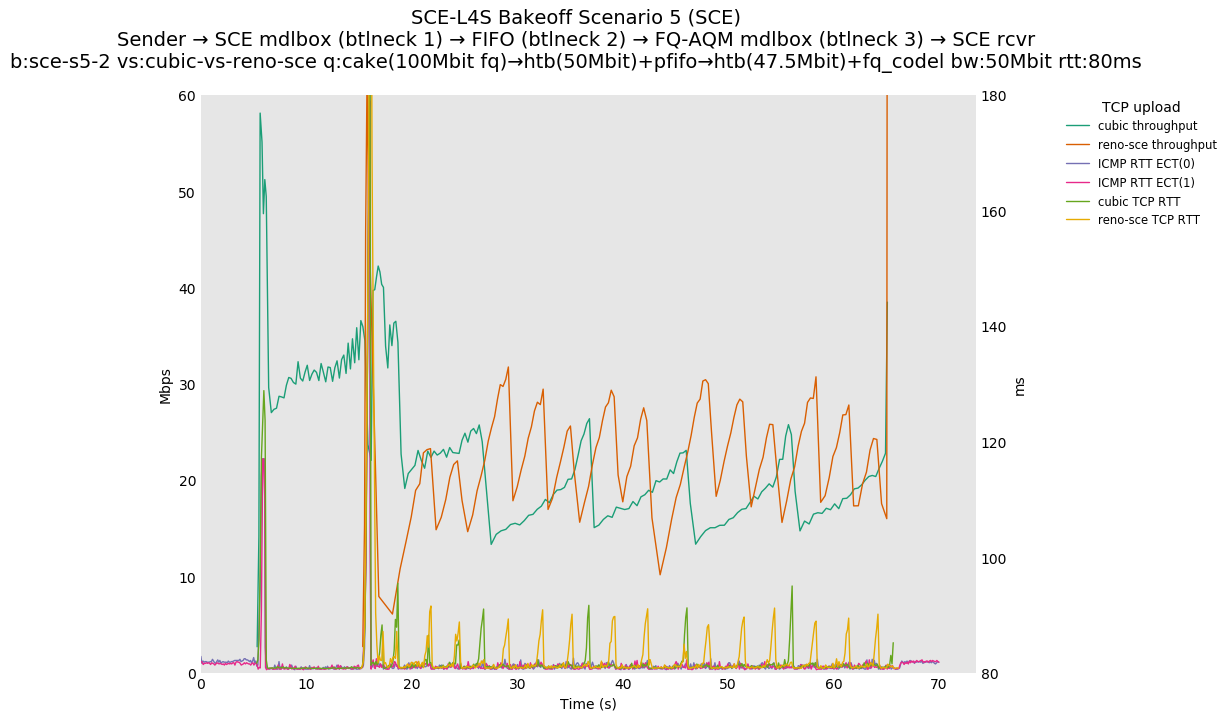{kind=link}
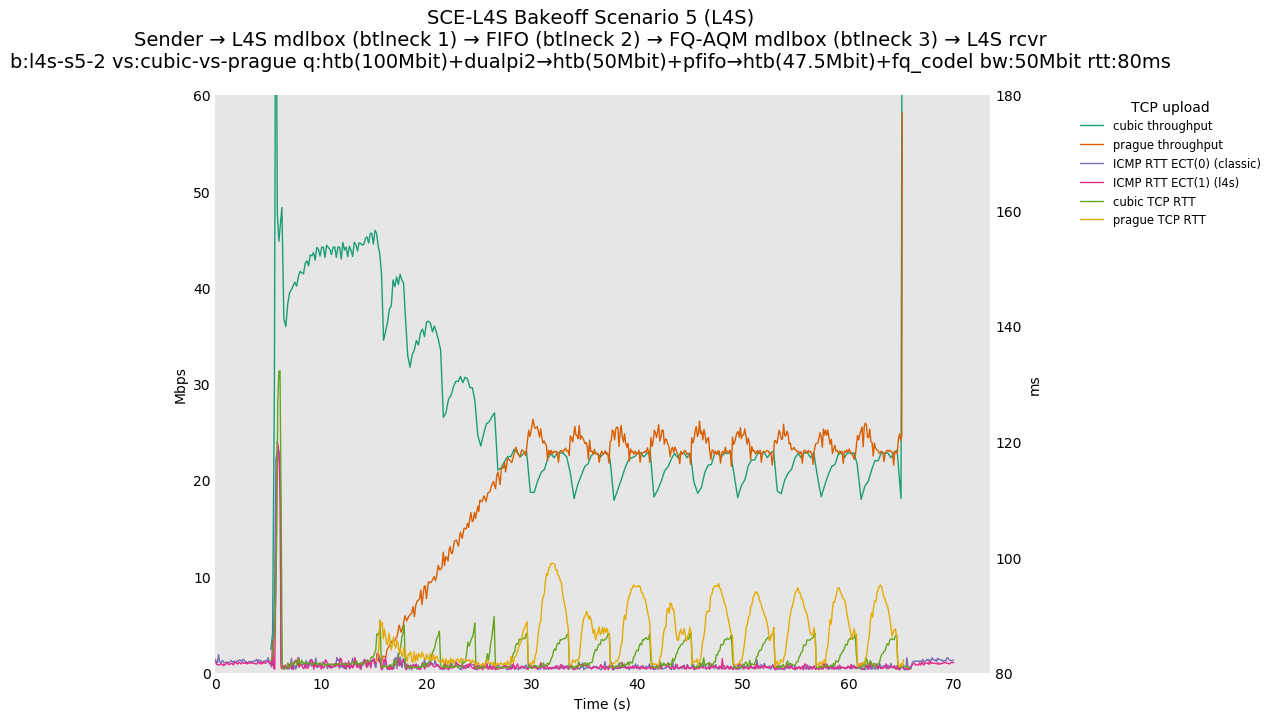{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
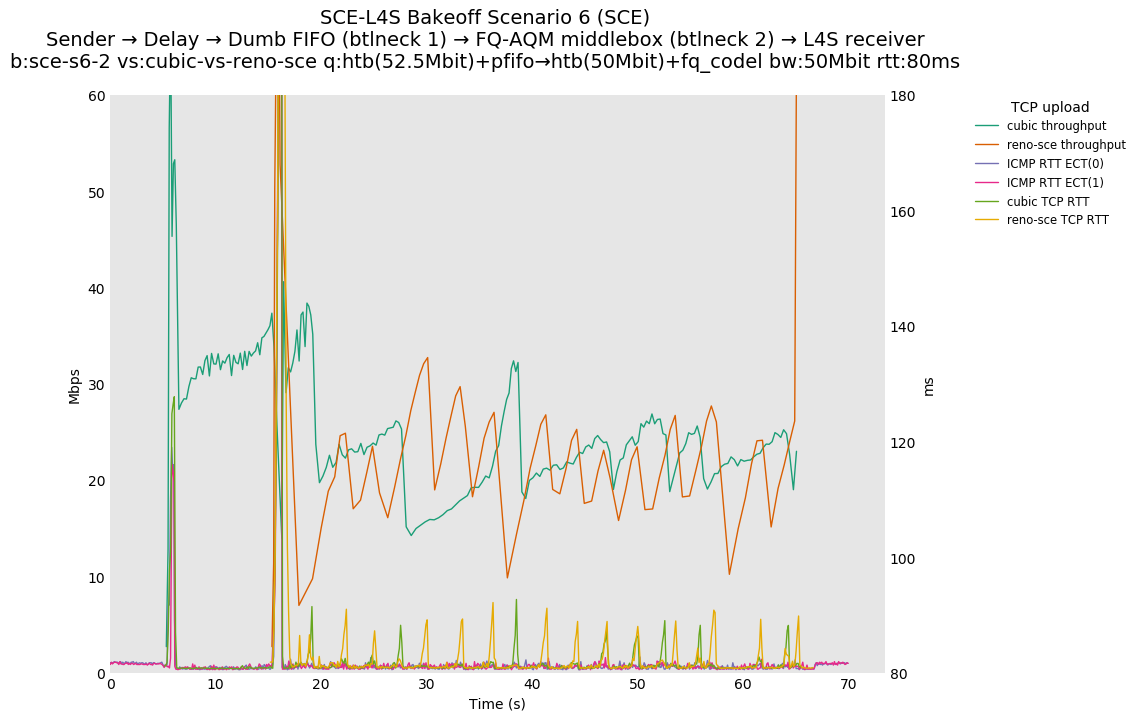
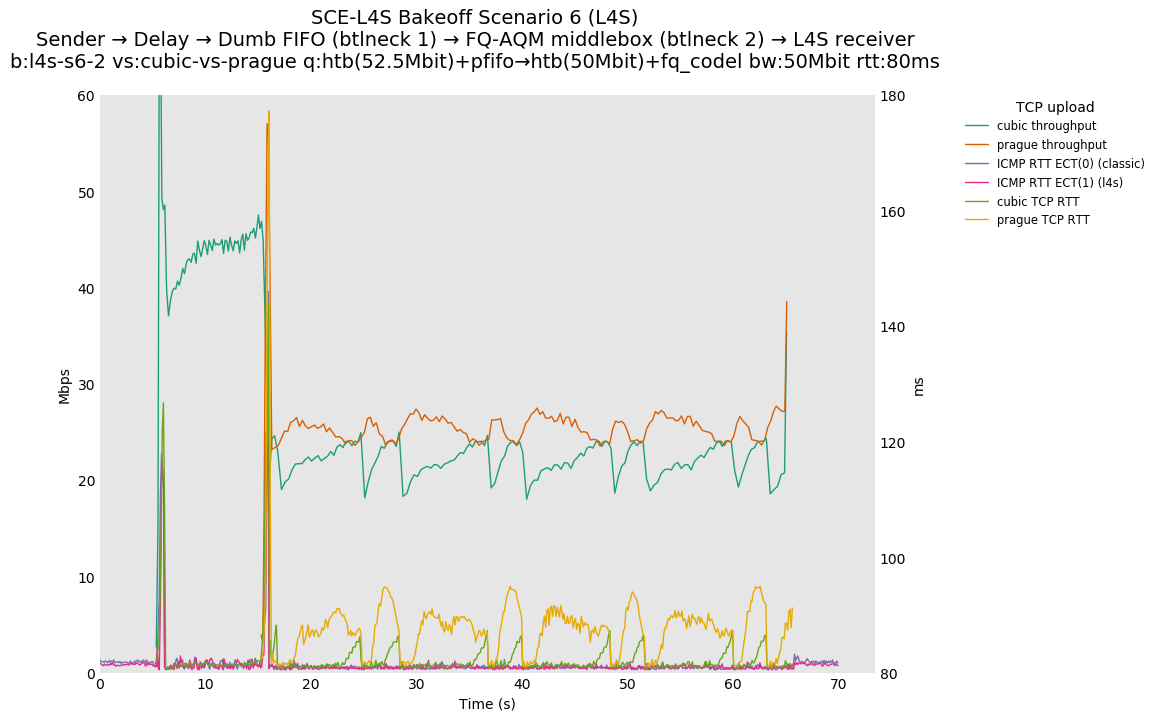
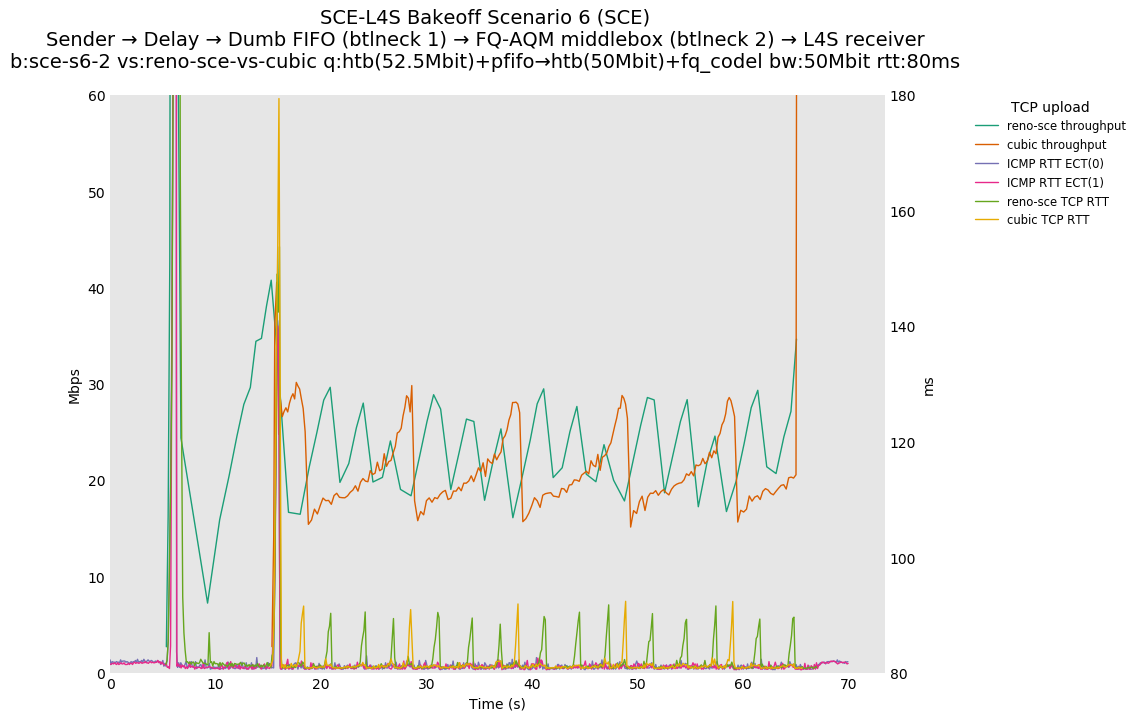
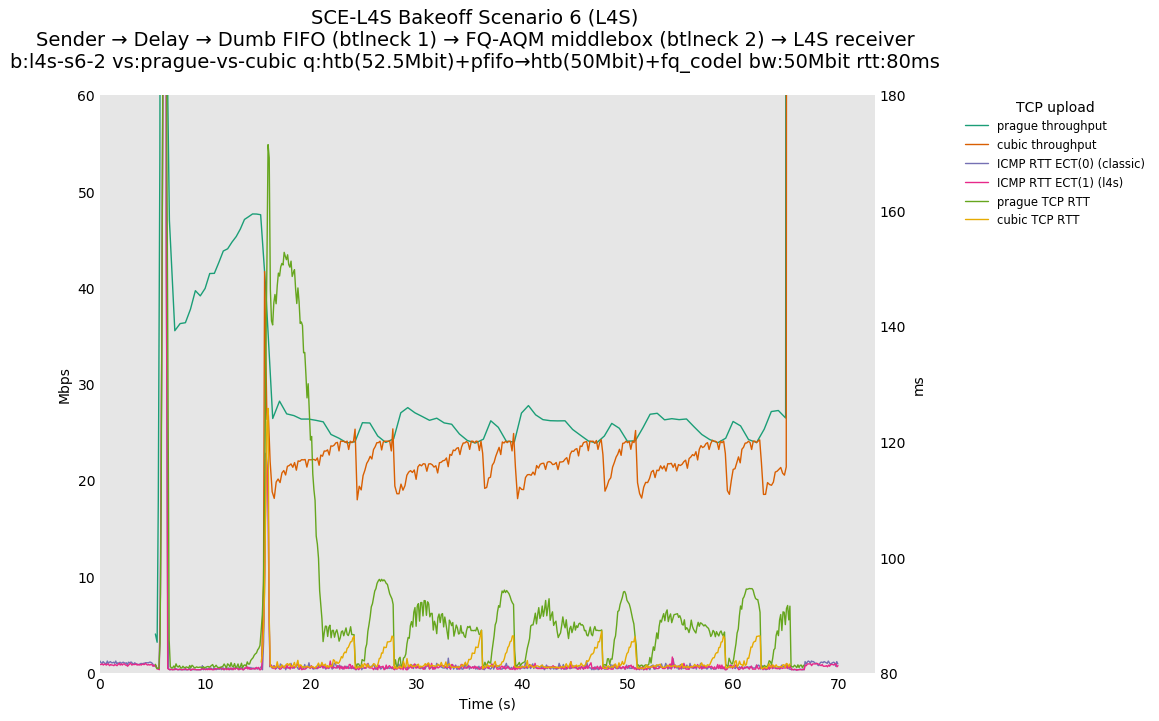
This is similar to Scenario 5, but narrowed down to just the FIFO and CoDel combination. Correct behaviour would show a brief latency peak caused by the interaction of slow-start with the FIFO in the subject topology, or no peak at all for the control topology; you should see this for whichever RFC 3168 flow is chosen as the control.
L4S: Sender → Delay → FIFO middlebox (bottleneck #1, 52.5Mbit) → FQ-AQM middlebox (bottleneck #2, 50Mbit) → L4S receiver
SCE: Sender → Delay → FIFO middlebox (bottleneck #1, 52.5Mbit) → FQ-AQM middlebox (bottleneck #2, 50Mbit) → SCE receiver
Full results: SCE one-flow | SCE two-flow | L4S one-flow | L4S two-flow
One-flow Observations:
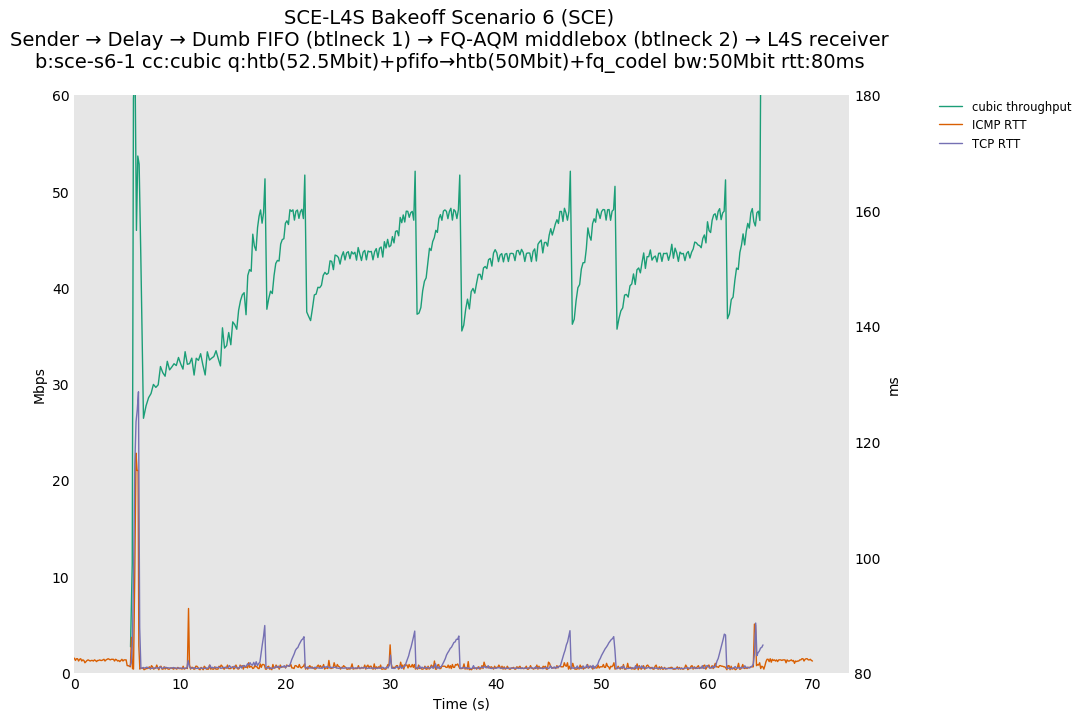{kind=link}
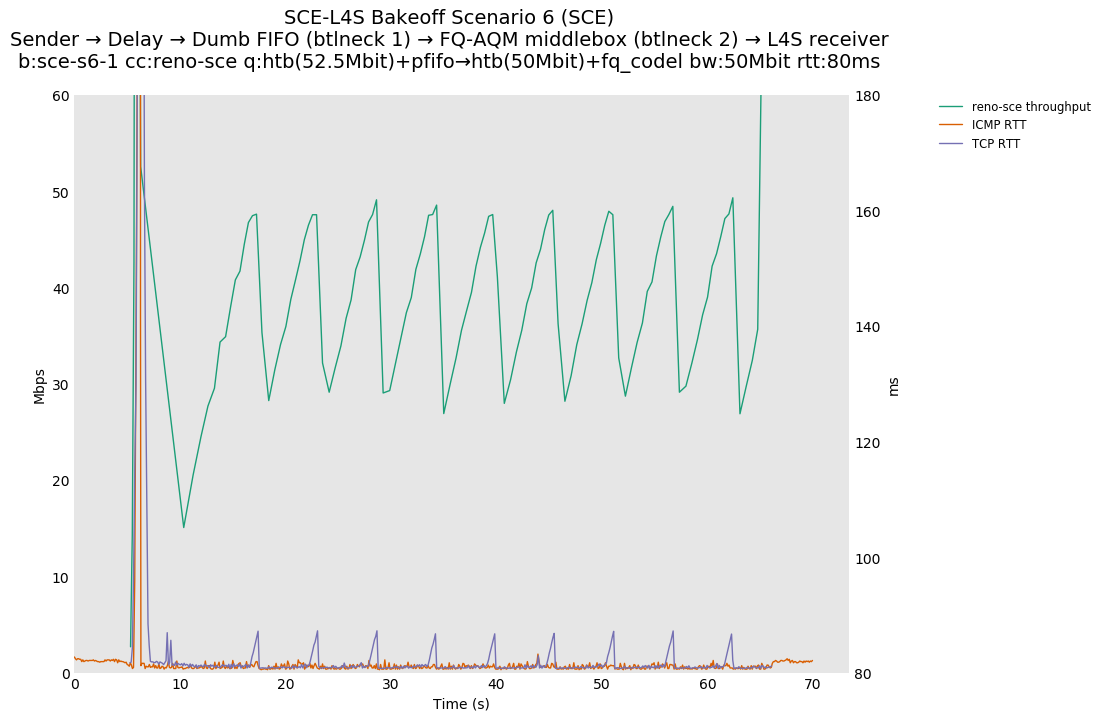{kind=link}
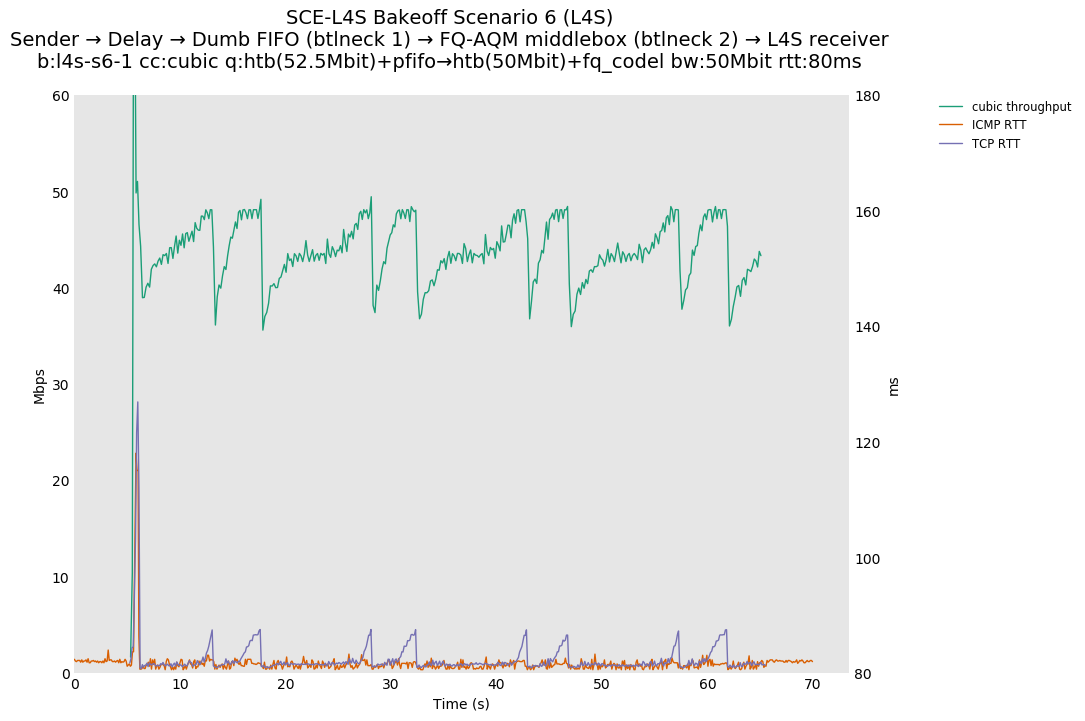{kind=link}
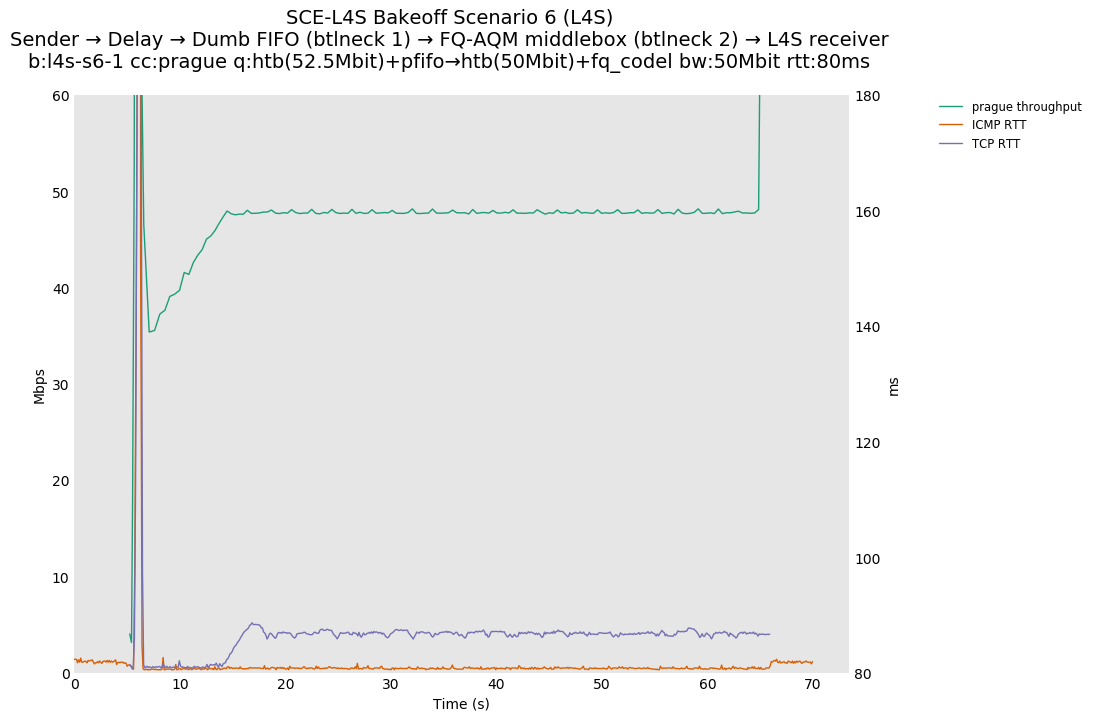{kind=link}
Two-flow Observations:
-
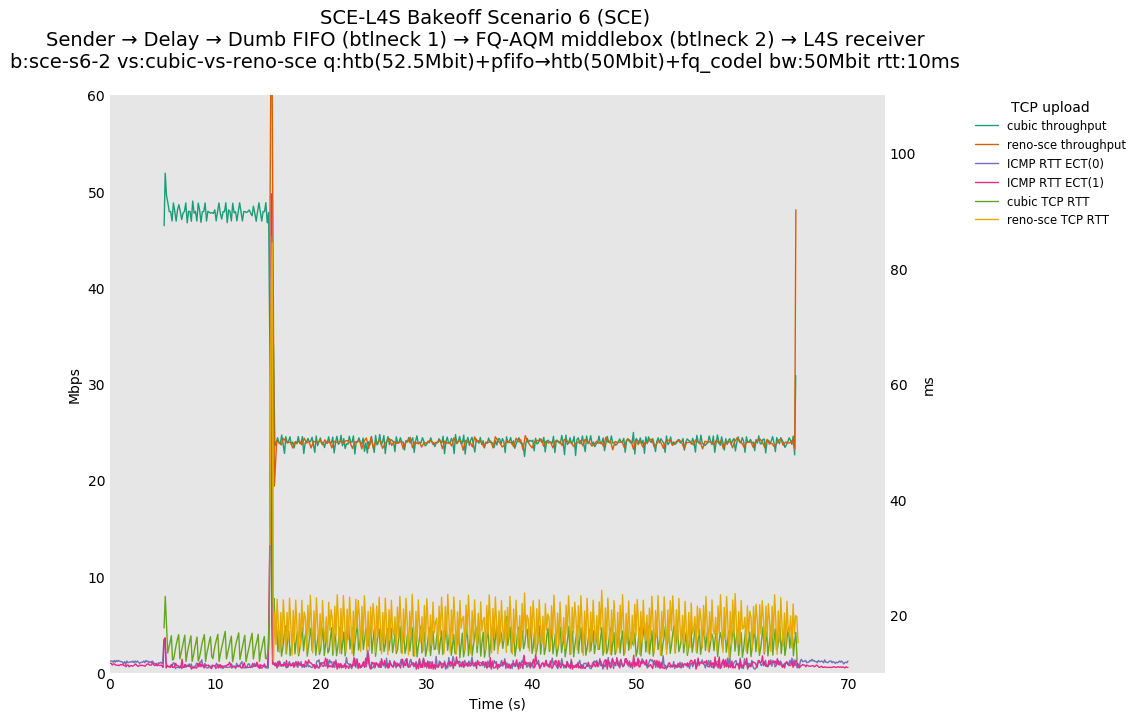
SCE vs L4S, Cubic vs Reno-SCE or Cubic vs Prague at 10ms
For SCE, we see a TCP RTT sawtooth during competition. Because there are no SCE-aware middleboxes, Reno-SCE reverts to standard RFC 3168 behavior.
-
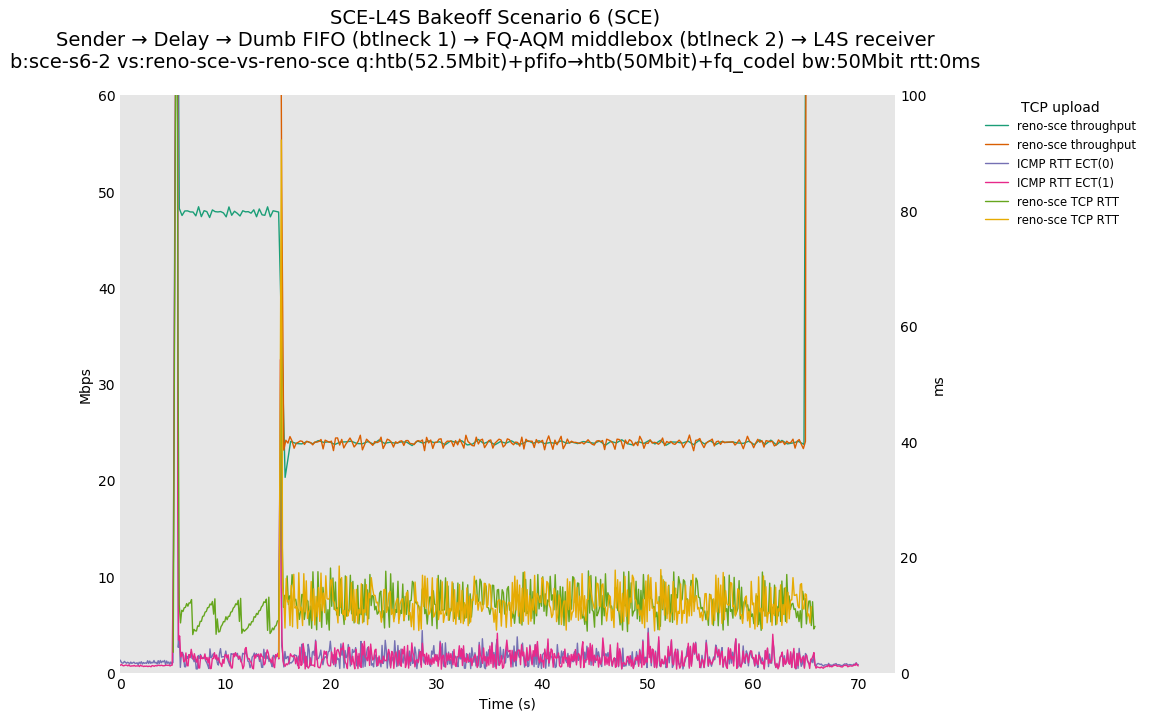
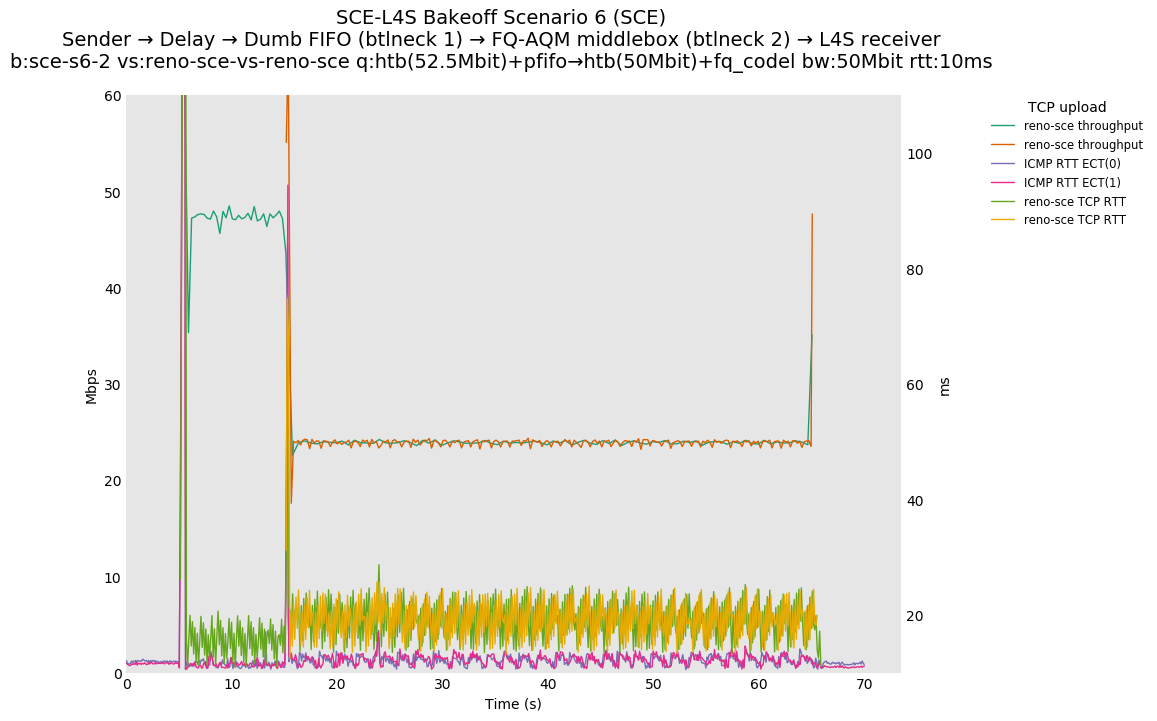
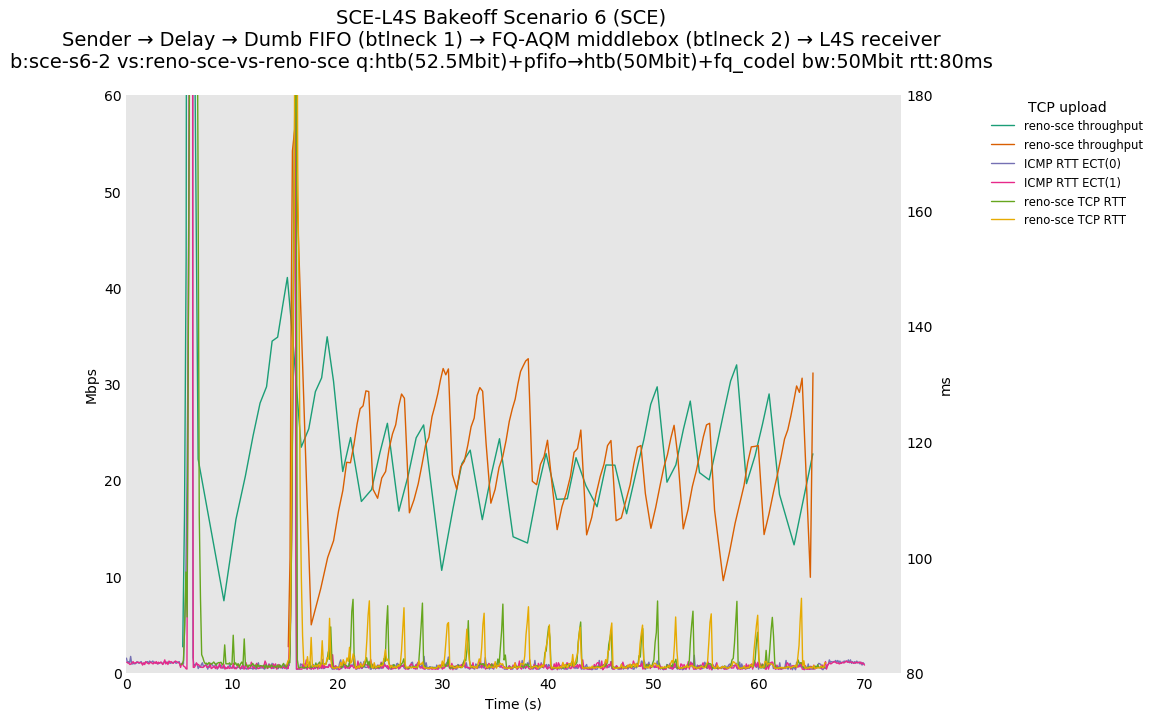
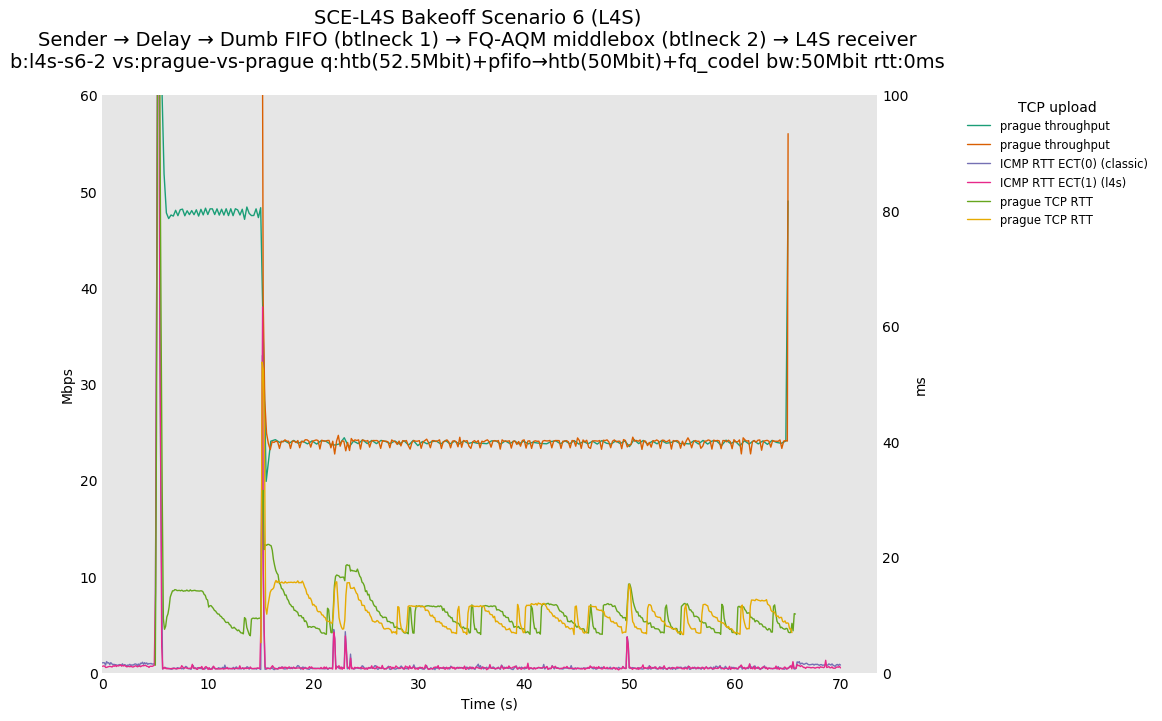
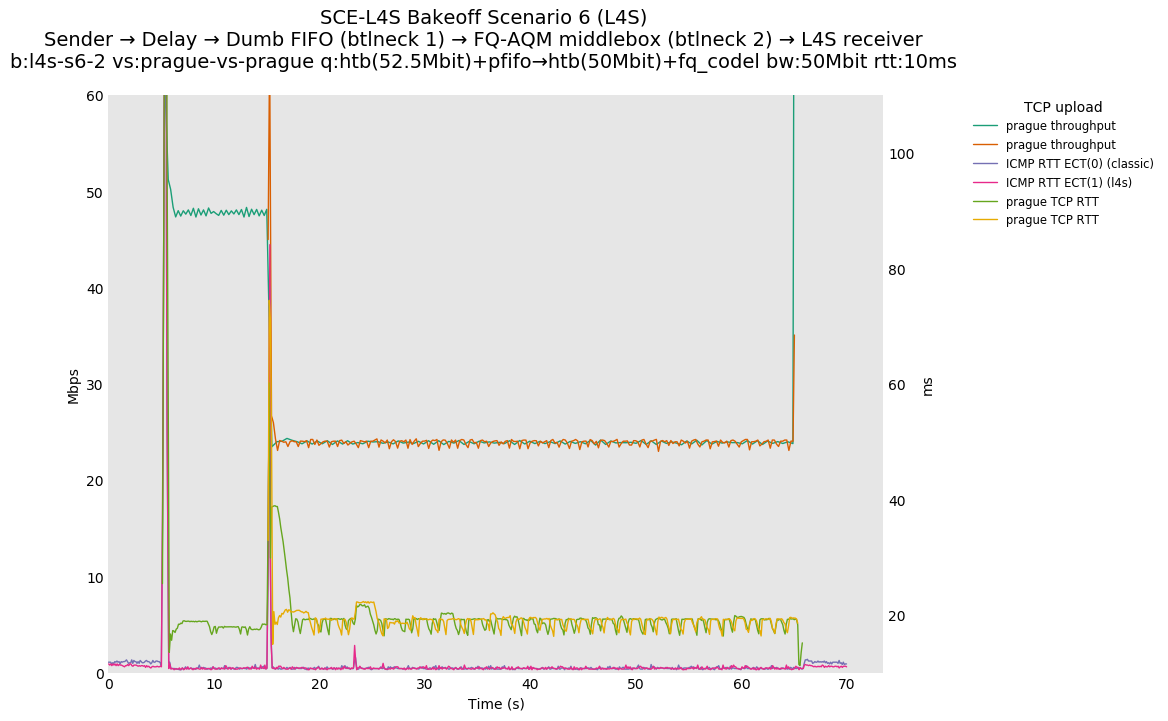
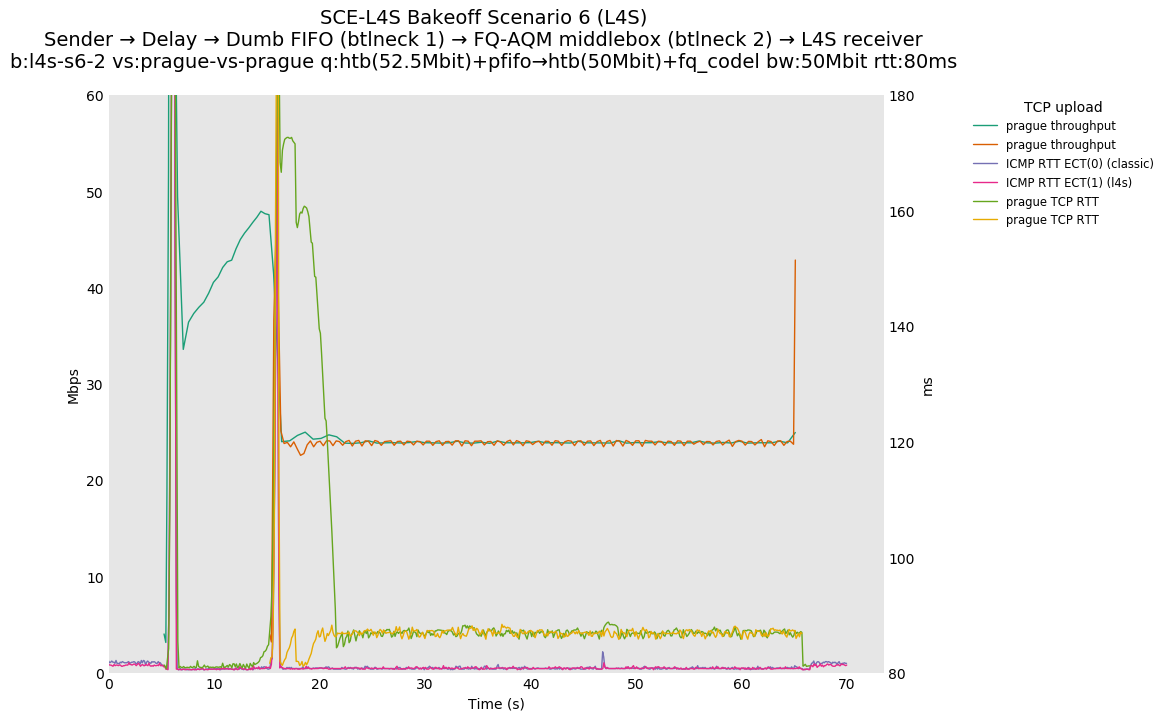
SCE for Reno-SCE vs Reno-SCE at 0ms, 10ms and 80ms, and L4S for Prague vs Prague at 0ms, 10ms and 80ms
-
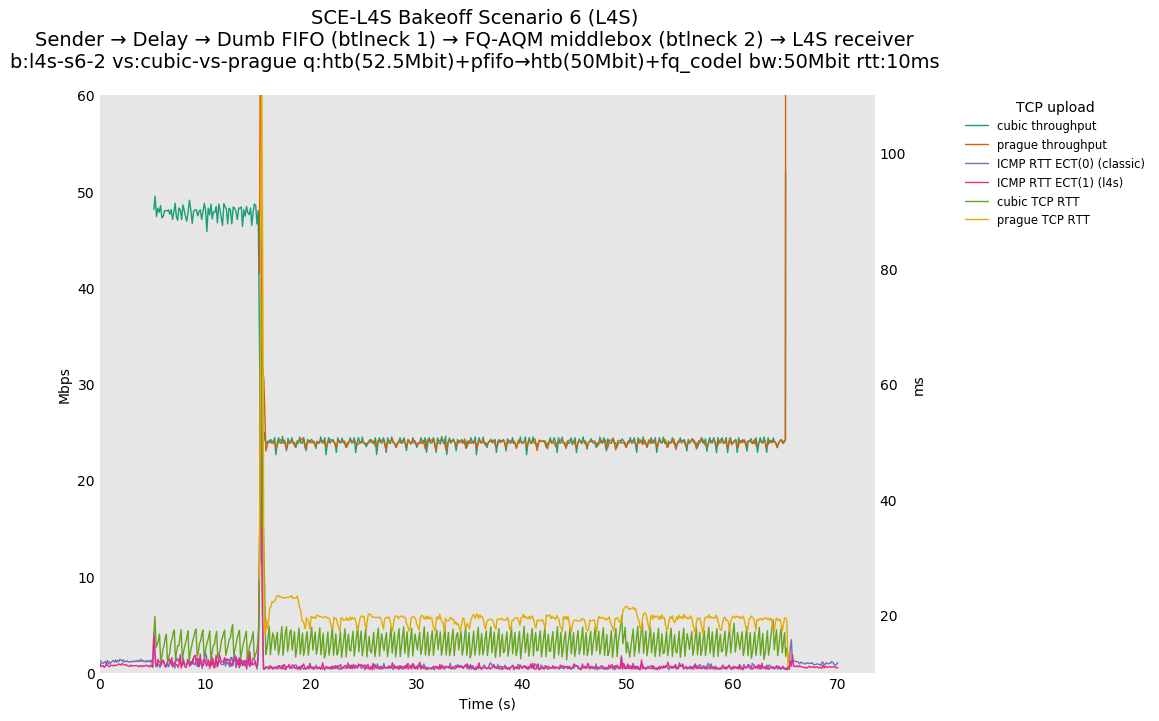
SCE vs L4S, Reno-SCE vs Cubic or Prague vs Cubic at 80ms
❗ When the flow order is reversed, so that TCP Prague is after its slow-start exit, we see an ~50ms TCP RTT spike that lasts around 5 seconds.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Because SCE is marked at lower queue depths than CE, non-SCE flows will outcompete SCE flows in a single queue without a change to the SCE marking ramp, as presented at IETF 105. This is effective, however it trades off some of the benefits of SCE, and requires tuning, which may be dependent on the link or traffic conditions.
Another solution is fair queueing. One of the arguments against this is the resource requirements for fair queueing, which led to the proposed Lightweight Fair Queueing and Cheap Nasty Queueing. Another argument is the perception that FQ can do harm to periodic bursty flows, however we have not yet shown this to be the case with hard evidence, and the SCE team is in general in favor of FQ.
We continue to explore alternative solutions to this challenge, and will seek to quantify any potential side effects of FQ, however this is a decades old debate that may not be resolved any time soon.
Fairness characteristics for dualpi2 are RTT dependent, and convergence times for TCP Prague are about 2x that of Reno-SCE at 80ms. See the two-flow observations in Scenario 1.
In Scenario 2, Scenario 5 and Scenario
6, we observed that TCP Prague when used with CoDel resulted in
TCP RTT spikes. Although the spikes during slow start were avoided by changes
published as of the tag testing/5-11-2019, spikes still occur when a second
flow is introduced after slow start.
This is due to the fact that the L4S architecture redefines CE to be a fine-grained congestion control signal that is expected to be marked at shallower queue depths. When it's not, as with the RFC 3168 compliant AQMs in use today, it takes longer for Prague to reduce it's cwnd to the optimal level.
This interaction is expected to be worse for CoDel than for some other AQMs, because CoDel's marking rate stays constant as queue depth increases, whereas the marking rate rises quickly with queue depth for PIE and RED, for example.
When TCP Prague receives CE signals from a non-L4S-aware AQM, as can happen in Scenario 3, for example, it can result in domination of L4S flows over classic flows sharing the same queue. This is due to the redefinition of CE, and the inability of the current implementation to detect when the bottleneck is a non-L4S-aware queue.
This issue may also lead to the high convergence times between TCP Prague flows when being signaled by a non-L4S-aware AQM, such as seen later in Scenario 3 (as those flows may expect a higher CE signaling rate).
In this update, the same original six scenarios were run, but using the L4S code
published with the tag testing/5-11-2019. Also, in addition to cubic vs
prague, prague vs cubic (reversed flow start order) was also run.
- In scenario 1 and elsewhere, the previously reported intermittent TCP Prague utilization issues appear to be fixed.
- In scenario 1, TCP Prague vs Cubic now does converge to fairness, but appears to have fairly long convergence times (~40s at 80ms RTT). Convergence times in other scenarios are similarly long.
- In scenario 2, scenario 5 and scenario 6, the previously reported L4S interaction with CoDel seems to be partially, but not completely fixed. By reversing the flow start order (prague vs cubic instead of cubic vs prague, second flow delayed by 10 seconds), we can see that while the TCP RTT spikes no longer occur at flow start, they are still present when a second flow is introduced after slow-start exit.
- In scenario 3 (single queue AQM at 10ms RTT), the previously reported unfairness between TCP Prague and Cubic grew larger, from ~4.1x (40.55/9.81Mbit) to ~7.7x (44.25/5.78Mbit). This trend appears to be consistent at other RTT delays in the same scenario (0ms and 80ms).
Reproducing these results requires setting up the topology described in Test Setup, and installing the required kernels and software.
The following table provides clone commands as well as relatively minimal sample
kernel configurations for virtual machine installations, which may be used to
replace the existing .config file in the kernel tree.
| Kernel | Clone Command | Sample Config |
|---|---|---|
| SCE | git clone https://github.com/chromi/sce/ |
config-sce |
| L4S | git clone https://github.com/L4STeam/linux |
config-l4s |
Refer to or use the included kbuild.sh file to build the kernel and deploy it to the test nodes. While using this file is not required, it can be useful in that:
- It supports building and deploying the kernel in parallel to all the test nodes with one command.
- It places a text file with git information in the boot directory of each node, which is included in the output during setup.
Before using it:
- Edit the settings for the
targetsvariables if your hostnames are not c[1-2], m[1-4], and s[1-2]. - Make sure your user has ssh access without a password to each test node
as
root.
Sample invocation that builds, packages, then deploys to and reboots each node in parallel:
kbuild.sh cycle
The command must be run at the root of the kernel source tree, once for the SCE kernel and once for the L4S kernel.
The clients require Flent, and the servers require netserver (see Test Setup). Flent should be compiled from source, as we use changes that are not in the official latest release as of version 1.3.0.
The instructions below are guidelines for Ubuntu 19.10 (uses Debian packaging), and may need to be modified for your distribution and version.
Clients require netperf, and servers require netserver, both compiled from the netperf repo.
sudo apt-get install autoconf automake
git clone https://github.com/HewlettPackard/netperf
cd netperf
./autogen.sh
./configure --enable-dirty=yes --enable-demo=yes
make
sudo make install
Running netserver at startup (on server boxes):
First add /etc/systemd/system/netserver.service:
[Unit]
Description=netperf server
After=network.target
[Service]
ExecStart=/usr/local/bin/netserver -D
User=nobody
[Install]
WantedBy=multi-user.target
Then:
sudo systemctl enable netserver
sudo systemctl start netserver
Clients require FPing.
sudo apt-get install fping
Clients may optionally install scetrace, which analyzes the pcap file for congestion control related statistics and produces a JSON file as output. If scetrace is not present, this analysis will be skipped.
Note that scetrace was designed for SCE and does not have support for L4S or AccECN, so some statistics are neither useful for nor applicable to L4S.
Clients require jq for some post-processing tasks of the JSON in the
.flent.gz file.
sudo apt-get install jq
Clients may optionally install the GNU parallel command, which makes some post-processing tasks faster with multiple CPUs, including running bzip2 on each pcap file.
sudo apt-get install parallel
Clients require Flent.
# install python 3
sudo apt-get install python3
# verify python 3 is the default or make it so, e.g.:
sudo update-alternatives --install /usr/bin/python python /usr/bin/python3 10
sudo apt-get install python3-pip
sudo pip install setuptools matplotlib
git clone https://github.com/tohojo/flent
cd flent
make
sudo make install
Edit bakeoff.batch to change any settings at the top of the file to
suit your environment. Note that:
- Flent is run with sudo so it can manually set the CC algorithm, and so that TCP stats polled with the ss utility are available.
- In order to set up and tear down the test nodes, the root user must have ssh access to each of the nodes without a password.
- The user used for management on each node must have sudo access without a password.
The file run.sh may be used to run some or all of the tests. Run it
without an argument for usage. A typical invocation which runs all SCE tests:
./run.sh sce
Run scenarios 5 and 6 (regex accepted):
./run.sh "sce-s[5-6]"
Show all L4S tests that would be run:
./run.sh l4s dry
runbg.sh runs tests in the background, allowing the user to log out.
Edit the variables in run.sh for Pushover notifications on completion.
Removes all results directories with standard naming. It is recommended to rename results directories to something else if they are to be kept, then use clean.sh to clean up results which are not needed.
Shows all log files from the latest result, defaulting to setup logs, e.g.:
./show.sh # shows setup logs
./show.sh teardown # shows teardown logs
./show.sh process # shows post-processing logs
Syncs files between C1 and C2, e.g.
./sync_clients.sh push # push files from current to other
./sync_clients.sh pull dry # show what files would be pulled from other to current
This is what we plan to do next:
- Add a scenario with a simulated bursty link using netem slotting
- Test CNQ.
- Explore the effects of changing TCP Prague's alpha from 0 to 1.
- Add a fairness scenario that compares 2 classic vs 1 Prague flow with dualpi2.
- Add a scenario with a sudden capacity increase, then decrease
- Add a scenario with a sudden RTT increase, then decrease
- Add a scenario with bi-directional traffic (start with rrul_be)
- Add a few asymmetric link scenarios, at least one where the reduced ACK rate limits throughput.
- Test with the PIE and RED AQMs.
This is an unstructured collection area for things that may be tested in the future:
- Bottleneck shifts (SCE to non-SCE, DualQ to 3168)
- More flows
- Packet loss
- Packet re-ordering
- Very high and very low bandwidths
- Very high and very low RTTs
- Multipath routing
- Asymmetric delays
Many thanks go out to:
- Jonathan Morton for deciphering and explaining many complex results
- the L4S team for working with us to quickly prepare their code for testing
- Sebastian Moeller for providing the illuminating Scenario 5
- Toke Høiland-Jørgensen for helping with key changes to Flent