Recorder - Unhandled database error while processing task (multiple types and occurrences after upgrade to 2023.4) #90974
Comments
|
Do you have the older MariaDB logs from when the migration happened? |
A backup was completed 8 hours ago, so maybe I can extract it from there? @bdraco I have a backup downloaded from 10AM today, but I'm not sure how to extract logs from the backup of if that's even possible. Any pointers on how to extract and read those without doing a restore? |
|
Also, it wasn't clear if your database is still dropping connections or if everything is working now. Dropped connection means that query too way too long, or there is actual database corruption from a disk/hardware/MariaDB bug which should show up in the log. |
|
Also the database size won't shrink after the migration until the 2nd Sunday of the month or when you manually reclaim space by calling the recorder.purge service to repack |
It looks like the connection is working now as each sensor history shows a gap from 8PM yesterday to 4:30PM today, and it appears to be writing new information. So I believe it's "working" now.... It seems like things just stopped at 8PM last night, but the reboot effectively kick started everything and then resulted in those logs I shared above. There haven't been more errors in the logs reported since the ones I shared above. Would there be logs in my 10AM Backup? If so, how do I extract it? |
Its a tarball so you can open it in most compression software. I expect you hit the memory circuit breaker that prevents the recorder from using all available memory during migration. The current design is a fixed limit but we are going to redesign it to increase the limit here #90894 |
Yeah, I've tried multiple apps to open it up, but each of the tarball files within give me an error indicating it's not an archive. And I'm not sure where the logs would be exactly....that's why I was asking if it was even possible to do this. Or would this memory circuit breaker item mean that the auto backup is not good and that's the error I'm getting? |
There should be another tarball inside the backup with
No its not related |
Yeah, I just keep getting errors on each of the tarballs inside like core_maridadb and homeassistant that it cannot be opened because it is not an archive. This is why I'm wondering if the system was hung up on the backup due to this schema migration freeze or whatever happened and as a result, this backup I have from 10AM is no good. |
|
Strike that - I just pulled a backup from yesterday and I'm getting the same thing. So this means I should have the logs that might be helpful to confirm your suspicion, but every app I try to use to open it tells me it can't and it's not an archive. I'll keep searching, but any pointers on how to get these logs would be helpful. |
|
Which operating system are you using to try to open it? |
Windows. I've tried several apps and all of them (including 7-Zip) tell me the individual tarballs within are not archives and cannot be opened. |
|
7zip should do it for sure. Can you post screenshots? |
|
|
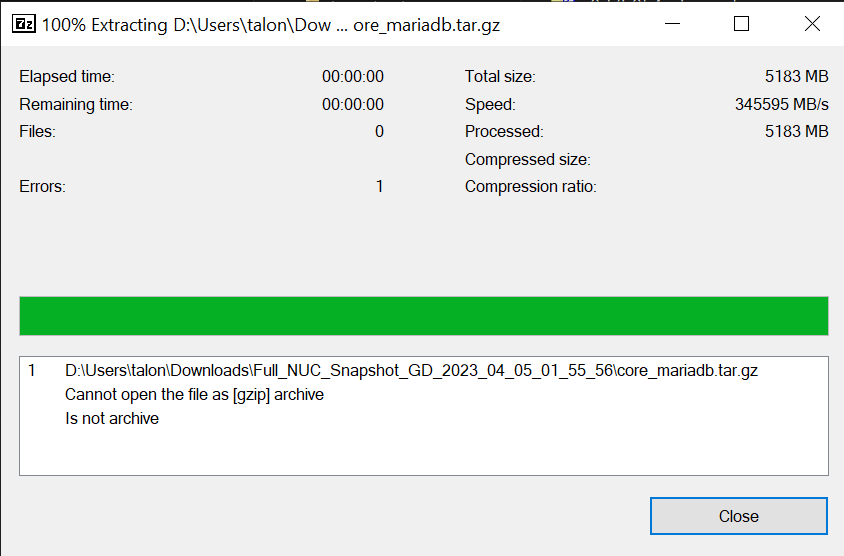
|
I'm getting this same error no matter which file I try from either backup. It's the same if I first extract the large backup into a folder and try on the individual file OR if I just open the backup in Z-Zip and keep navigating down to the mariadb file. UPDATE - ahhh, I have a password on the backup...I bet you that's why I'm getting that error.
Would you recommend calling record.purge manually? I just don't want to mess this up any more than I have with the data I have missing from today... |
Yup thats it. You can't open it with traditional tools.
You can call it with something like this to ensure it won't remove any data unless its a year old:
|
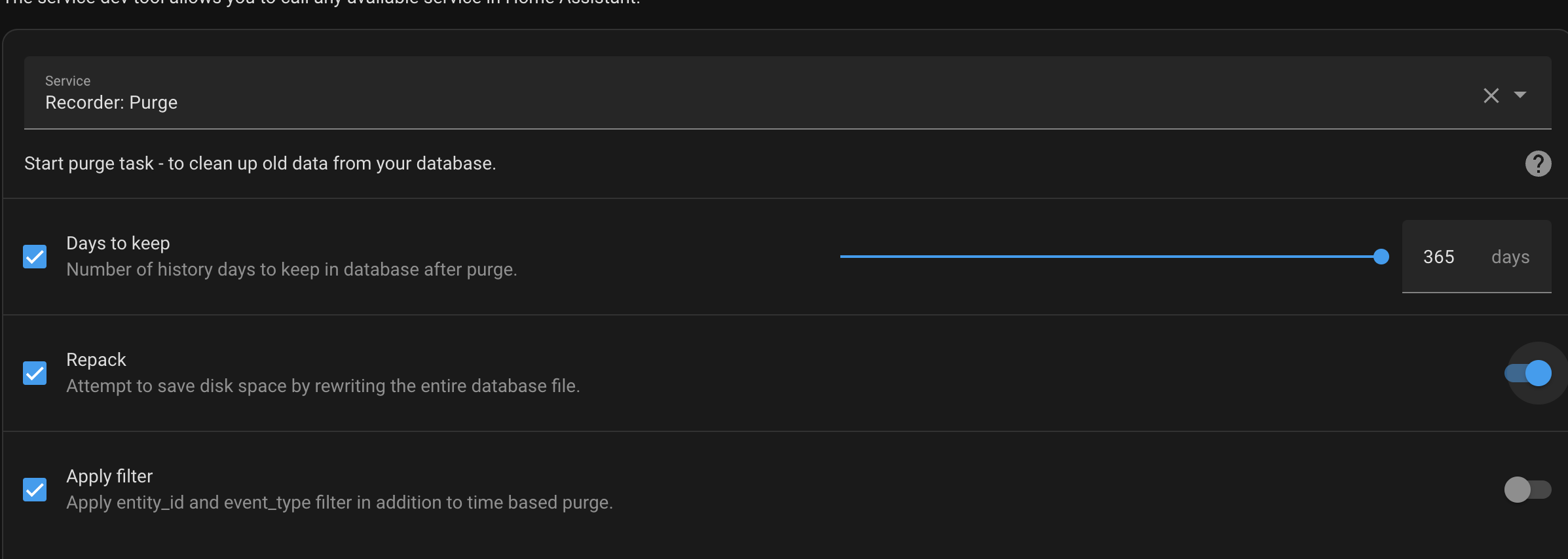
I'm trying some python script to decrypt it, but have not been successful so far.... |
|
Thanks, unfortunately I have no clue how to use that. I'm trying this script right now, but I now am running into this error... This issue has convinced me to disable password protecting my HA backups....this is truly an unnecessary pain just to get the log files... |
|
I’ve hit the same issue with the database migration and only noticed it 24 hours later. If the migration stops because of memory issues maybe the user should be somehow informed about it. |
We don't know if that's the reason. If you have logs please post them |
|
This is the only entry I see in the log from yesterday, when I upgraded: 2023-04-07 15:02:14 28 [Warning] Aborted connection 28 to db: 'hassio' user: 'hassio' host: '192.168.10.32' (Got an error reading communication packets)
2023-04-08 18:15:49 0 [Note] mariadbd (initiated by: unknown): Normal shutdown |
|
Home Assistant logged the following: |
Is mariadb still running in the container? |
|
It was. I have since restarted both containers (HA core + mariadb). |
|
Was there any indication about what caused mariadb to shutdown?
|
|
That was me. I restarted both containers after I had figured out that the
recorder was not working ok.
…On Sat, 8 Apr 2023 at 23:37, J. Nick Koston ***@***.***> wrote:
Was there any indication about what caused mariadb to shutdown?
2023-04-08 18:15:49 0 [Note] mariadbd (initiated by: unknown): Normal
shutdown seems to indicate something triggered it to shutdown, and since
there isn't code in Home Assistant core to shutdown the MariaDB server it
would be interesting to know where its coming from.
—
Reply to this email directly, view it on GitHub
<#90974 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AABJXH6Y7YW6A2SE4CZZDVTXAHLDLANCNFSM6AAAAAAWV4NCZM>
.
You are receiving this because you commented.Message ID:
***@***.***>
|
|
Per my post here in the HA Community forums on the release notes, since I haven't figured out how to extract my mariadb logs from an encrypted backup, I starting to believe my issue was caused by not having enough free space on my SSD. I believe I had only 20gb of free space at the time of migration, which sounds like it was not enough to perform the migration successfully. I didn't watch the video until today where this was mentioned and did not see anything about this requirement in the release notes before upgrading (or rebooting after I noticed the lack of data after 24 hours). If my mariadb logs would still be useful in determining root cause, I will gladly share those if I can some specific guidance on how to extract it from the encrypted backup without restoring my HA instance. |
|
I'm not sure if this was related, but at 10:23AM ET, my HA instance became unresponsive and automatically restarted. During the restart, it was waiting for Recorder to start and nothing else would load....after about 5 minutes of still waiting and no progress or information updates in the logs, I finally manually pulled the plug on my NUC to restart the device. Upon the next reboot, everything loaded, however the first item in the logs was this: and MariaDB logs show this: The only things I've changed since upgrading to 2023.4.2 is my purge time from 90 to 60 days, and then forced a repack to see what impact this had on my DB size (18GB to 15GB). My backups are still growing and are now 7.4GB and I've got 102GB of free space on my drive (I incorrectly said I had a 128GB SSD, but it's really a 240GB). The net for now is everything appears to be working except for the statics appear to have stopped around 10:10AM and then resumed around 10:30AM, so I lost 20 minutes of data readings during this time for some reason....similar to what happened during the 24 hours + of the database scheme update... |
|
And it just restarted again at 12:15 for no clear reason... Here's the first item in the logs now: Here are the MariaDB logs: @bdraco could this all be related to the update? I really don't want to lose all my data, but I'm wondering if I need to expedite my transition back to the native database as it appears I'm continuing to have issues following this update release. |
|
2023-04-12 12:15:42 5 [Warning] Aborted connection 5 to db: 'homeassistant' user: 'hass' host: '172.30.32.1' (Got an error reading communication packets) That looks like the communication between the mariadb server and core is somehow being interrupted. There isn't enough information to tell whats going on here but there haven't been any changes on how we talk to the database so I expect there is more going on with your system and it's probably the same reason the update had trouble as well. |
Ok - anything in particular I should do or enable to help gather more information? e.g. like a hidden debug mode or something? My MariaDB instance has been solid since 2021 and has not required me to do anything to it since 2023.4.0 last week, so I'm really at a loss to where to begin to figure this out. Ith's the official add-on installed on the same device. I have no reason to believe there's a hardware issue here. I've resolved the potential free space issue by reducing the number of local backups it keeps. If this continues, I might try to do a DB migration this weekend following this post given my limited SQL knowledge. |
|
You would likely need to watch the raw packets between the containers to see what's going on. That would be extremely difficult to debug and find the issue if you don't have previous experience doing it. Migrating seems like a good plan as it would avoid the communication issue entirely |
|
Right - I have no previous experience with that... As a sanity check, is there anything in the this post that looks odd to you for the migration? I'll try to carve out some time to do this soon. |
|
If you just want to keep statistics, koying's post looks like a pretty good solution. I haven't tested it myself but I don't see anything that seems like it would be an obvious issue https://community.home-assistant.io/t/migrating-from-mysql-mariadb-back-to-sqlite/545837/10?u=bdraco |
|
Thank you. Two more questions:
|
|
There hasn't been any activity on this issue recently. Due to the high number of incoming GitHub notifications, we have to clean some of the old issues, as many of them have already been resolved with the latest updates. |
The problem
Almost 24 hours after upgrading to 2023.4, I noticed some odd behavior with my logs not loading for devices. The notification for the database schema change had already gone away, so I thought that meant it was done.
After rebooting my system, I now see several items in the logs with multiple occurrences related to recorder. I'm using MariaDB (version 2.5.2). I recognize this may be more complicated due to the add-on, but this appears to be an issue following the 2023.4 upgrade and schema change.
If I go to Logbook - I noticed before rebooting I could only see items until 8PM yesterday and nothing from today.
After rebooting, I'm now only able to see items from around that time of the reboot to now, but nbetween 8PM yesterday and 4:30PM today..... And my energy dashboard put everything at 4PM today for the reboot....it looks like it was frozen for hours and just now is starting to write data. Is all of that data gone?!??
Also, I noticed that my backup last night increased by 1GB (From 7GB to 8GB) from the previous day.
This is on an intel NUC i5 with 8GB of ram. I'm not finding any other performance changes like high CPU or RAM usage.
What version of Home Assistant Core has the issue?
2023.4
What was the last working version of Home Assistant Core?
2023.3.6
What type of installation are you running?
Home Assistant OS
Integration causing the issue
Recorder
Link to integration documentation on our website
https://www.home-assistant.io/integrations/recorder/
Diagnostics information
No response
Example YAML snippet
No response
Anything in the logs that might be useful for us?
Logger: homeassistant.components.recorder.util Source: components/recorder/util.py:571 Integration: Recorder (documentation, issues) First occurred: 16:33:18 (1 occurrences) Last logged: 16:33:18 Ended unfinished session (id=395 from 2023-04-05 19:22:14) Logger: homeassistant.components.recorder.util Source: components/recorder/util.py:213 Integration: Recorder (documentation, issues) First occurred: 16:46:43 (2 occurrences) Last logged: 16:46:43 Error executing query: (MySQLdb.OperationalError) (2013, 'Lost connection to MySQL server during query') [SQL: SELECT states.metadata_id, states.state, states.last_changed_ts, states.last_updated_ts, states.attributes, state_attributes.shared_attrs FROM states INNER JOIN (SELECT states.metadata_id AS max_metadata_id, max(states.last_updated_ts) AS max_last_updated FROM states WHERE states.last_updated_ts >= %s AND states.last_updated_ts < %s AND states.metadata_id IN (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s) GROUP BY states.metadata_id) AS anon_1 ON states.metadata_id = anon_1.max_metadata_id AND states.last_updated_ts = anon_1.max_last_updated LEFT OUTER JOIN state_attributes ON states.attributes_id = state_attributes.attributes_id] [parameters: (1680722534.0, 1680742499.999999, 243, 148, 205, 150, 99, 20, 97, 245, 246, 117, 108, 109, 291, 292, 153, 293, 294, 25, 295, 297, 298, 299, 300, 123, 94, 301, 302, 303, 83, 164, 49, 330, 1184, 1185, 1186, 1201, 1202, 1203, 1204, 1205, 538, 181, 539, 122, 135, 29, 55, 648 ... 314 parameters truncated ... 951, 952, 954, 955, 956, 957, 168, 147, 958, 192, 1152, 1153, 1154, 1155, 1156, 1157, 2338, 2335, 189, 1095, 212, 142, 80, 81, 755, 756, 759, 760, 761, 762, 763, 764, 765, 767, 771, 775, 777, 779, 781, 783, 785, 787, 789, 790, 139, 2332, 2429, 8, 2440, 2461)] (Background on this error at: https://sqlalche.me/e/20/e3q8) Traceback (most recent call last): File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 1964, in _exec_single_context self.dialect.do_execute( File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/default.py", line 748, in do_execute cursor.execute(statement, parameters) File "/usr/local/lib/python3.10/site-packages/MySQLdb/cursors.py", line 206, in execute res = self._query(query) File "/usr/local/lib/python3.10/site-packages/MySQLdb/cursors.py", line 319, in _query db.query(q) File "/usr/local/lib/python3.10/site-packages/MySQLdb/connections.py", line 254, in query _mysql.connection.query(self, query) MySQLdb.OperationalError: (2013, 'Lost connection to MySQL server during query') The above exception was the direct cause of the following exception: Traceback (most recent call last): File "/usr/src/homeassistant/homeassistant/components/recorder/util.py", line 129, in session_scope yield session File "/usr/src/homeassistant/homeassistant/components/sensor/recorder.py", line 405, in compile_statistics compiled = _compile_statistics(hass, session, start, end) File "/usr/src/homeassistant/homeassistant/components/sensor/recorder.py", line 440, in _compile_statistics _history_list = history.get_full_significant_states_with_session( File "/usr/src/homeassistant/homeassistant/components/recorder/history/__init__.py", line 55, in get_full_significant_states_with_session return _target( File "/usr/src/homeassistant/homeassistant/components/recorder/history/modern.py", line 305, in get_full_significant_states_with_session get_significant_states_with_session( File "/usr/src/homeassistant/homeassistant/components/recorder/history/modern.py", line 272, in get_significant_states_with_session return _sorted_states_to_dict( File "/usr/src/homeassistant/homeassistant/components/recorder/history/modern.py", line 718, in _sorted_states_to_dict for row in _get_rows_with_session( File "/usr/src/homeassistant/homeassistant/components/recorder/history/modern.py", line 629, in _get_rows_with_session return execute_stmt_lambda_element(session, stmt) File "/usr/src/homeassistant/homeassistant/components/recorder/util.py", line 213, in execute_stmt_lambda_element executed = session.execute(stmt) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/orm/session.py", line 2229, in execute return self._execute_internal( File "/usr/local/lib/python3.10/site-packages/sqlalchemy/orm/session.py", line 2124, in _execute_internal result: Result[Any] = compile_state_cls.orm_execute_statement( File "/usr/local/lib/python3.10/site-packages/sqlalchemy/orm/context.py", line 253, in orm_execute_statement result = conn.execute( File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 1414, in execute return meth( File "/usr/local/lib/python3.10/site-packages/sqlalchemy/sql/lambdas.py", line 605, in _execute_on_connection return connection._execute_clauseelement( File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 1638, in _execute_clauseelement ret = self._execute_context( File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 1842, in _execute_context return self._exec_single_context( File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 1983, in _exec_single_context self._handle_dbapi_exception( File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 2326, in _handle_dbapi_exception raise sqlalchemy_exception.with_traceback(exc_info[2]) from e File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 1964, in _exec_single_context self.dialect.do_execute( File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/default.py", line 748, in do_execute cursor.execute(statement, parameters) File "/usr/local/lib/python3.10/site-packages/MySQLdb/cursors.py", line 206, in execute res = self._query(query) File "/usr/local/lib/python3.10/site-packages/MySQLdb/cursors.py", line 319, in _query db.query(q) File "/usr/local/lib/python3.10/site-packages/MySQLdb/connections.py", line 254, in query _mysql.connection.query(self, query) sqlalchemy.exc.OperationalError: (MySQLdb.OperationalError) (2013, 'Lost connection to MySQL server during query') [SQL: SELECT states.metadata_id, states.state, states.last_changed_ts, states.last_updated_ts, states.attributes, state_attributes.shared_attrs FROM states INNER JOIN (SELECT states.metadata_id AS max_metadata_id, max(states.last_updated_ts) AS max_last_updated FROM states WHERE states.last_updated_ts >= %s AND states.last_updated_ts < %s AND states.metadata_id IN (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s) GROUP BY states.metadata_id) AS anon_1 ON states.metadata_id = anon_1.max_metadata_id AND states.last_updated_ts = anon_1.max_last_updated LEFT OUTER JOIN state_attributes ON states.attributes_id = state_attributes.attributes_id] [parameters: (1680722534.0, 1680742499.999999, 243, 148, 205, 150, 99, 20, 97, 245, 246, 117, 108, 109, 291, 292, 153, 293, 294, 25, 295, 297, 298, 299, 300, 123, 94, 301, 302, 303, 83, 164, 49, 330, 1184, 1185, 1186, 1201, 1202, 1203, 1204, 1205, 538, 181, 539, 122, 135, 29, 55, 648 ... 314 parameters truncated ... 951, 952, 954, 955, 956, 957, 168, 147, 958, 192, 1152, 1153, 1154, 1155, 1156, 1157, 2338, 2335, 189, 1095, 212, 142, 80, 81, 755, 756, 759, 760, 761, 762, 763, 764, 765, 767, 771, 775, 777, 779, 781, 783, 785, 787, 789, 790, 139, 2332, 2429, 8, 2440, 2461)] (Background on this error at: https://sqlalche.me/e/20/e3q8) Logger: homeassistant.components.recorder.util Source: components/recorder/util.py:213 Integration: Recorder (documentation, issues) First occurred: 16:46:46 (1 occurrences) Last logged: 16:46:46 Error executing query: (MySQLdb.OperationalError) (2002, "Can't connect to MySQL server on 'core-mariadb' (115)") (Background on this error at: https://sqlalche.me/e/20/e3q8) Traceback (most recent call last): File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 145, in __init__ self._dbapi_connection = engine.raw_connection() File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 3275, in raw_connection return self.pool.connect() File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 455, in connect return _ConnectionFairy._checkout(self) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 1271, in _checkout fairy = _ConnectionRecord.checkout(pool) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 724, in checkout with util.safe_reraise(): File "/usr/local/lib/python3.10/site-packages/sqlalchemy/util/langhelpers.py", line 147, in __exit__ raise exc_value.with_traceback(exc_tb) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 722, in checkout dbapi_connection = rec.get_connection() File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 842, in get_connection self.__connect() File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 905, in __connect with util.safe_reraise(): File "/usr/local/lib/python3.10/site-packages/sqlalchemy/util/langhelpers.py", line 147, in __exit__ raise exc_value.with_traceback(exc_tb) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 901, in __connect self.dbapi_connection = connection = pool._invoke_creator(self) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/create.py", line 636, in connect return dialect.connect(*cargs, **cparams) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/default.py", line 580, in connect return self.loaded_dbapi.connect(*cargs, **cparams) File "/usr/local/lib/python3.10/site-packages/MySQLdb/__init__.py", line 123, in Connect return Connection(*args, **kwargs) File "/usr/local/lib/python3.10/site-packages/MySQLdb/connections.py", line 185, in __init__ super().__init__(*args, **kwargs2) MySQLdb.OperationalError: (2002, "Can't connect to MySQL server on 'core-mariadb' (115)") The above exception was the direct cause of the following exception: Traceback (most recent call last): File "/usr/src/homeassistant/homeassistant/components/recorder/util.py", line 129, in session_scope yield session File "/usr/src/homeassistant/homeassistant/components/recorder/statistics.py", line 468, in compile_statistics modified_statistic_ids = _compile_statistics( File "/usr/src/homeassistant/homeassistant/components/recorder/statistics.py", line 504, in _compile_statistics if execute_stmt_lambda_element(session, _get_first_id_stmt(start)): File "/usr/src/homeassistant/homeassistant/components/recorder/util.py", line 213, in execute_stmt_lambda_element executed = session.execute(stmt) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/orm/session.py", line 2229, in execute return self._execute_internal( File "/usr/local/lib/python3.10/site-packages/sqlalchemy/orm/session.py", line 2114, in _execute_internal conn = self._connection_for_bind(bind) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/orm/session.py", line 1981, in _connection_for_bind return trans._connection_for_bind(engine, execution_options) File "<string>", line 2, in _connection_for_bind File "/usr/local/lib/python3.10/site-packages/sqlalchemy/orm/state_changes.py", line 137, in _go ret_value = fn(self, *arg, **kw) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/orm/session.py", line 1108, in _connection_for_bind conn = bind.connect() File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 3251, in connect return self._connection_cls(self) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 147, in __init__ Connection._handle_dbapi_exception_noconnection( File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 2413, in _handle_dbapi_exception_noconnection raise sqlalchemy_exception.with_traceback(exc_info[2]) from e File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 145, in __init__ self._dbapi_connection = engine.raw_connection() File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 3275, in raw_connection return self.pool.connect() File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 455, in connect return _ConnectionFairy._checkout(self) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 1271, in _checkout fairy = _ConnectionRecord.checkout(pool) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 724, in checkout with util.safe_reraise(): File "/usr/local/lib/python3.10/site-packages/sqlalchemy/util/langhelpers.py", line 147, in __exit__ raise exc_value.with_traceback(exc_tb) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 722, in checkout dbapi_connection = rec.get_connection() File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 842, in get_connection self.__connect() File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 905, in __connect with util.safe_reraise(): File "/usr/local/lib/python3.10/site-packages/sqlalchemy/util/langhelpers.py", line 147, in __exit__ raise exc_value.with_traceback(exc_tb) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 901, in __connect self.dbapi_connection = connection = pool._invoke_creator(self) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/create.py", line 636, in connect return dialect.connect(*cargs, **cparams) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/default.py", line 580, in connect return self.loaded_dbapi.connect(*cargs, **cparams) File "/usr/local/lib/python3.10/site-packages/MySQLdb/__init__.py", line 123, in Connect return Connection(*args, **kwargs) File "/usr/local/lib/python3.10/site-packages/MySQLdb/connections.py", line 185, in __init__ super().__init__(*args, **kwargs2) sqlalchemy.exc.OperationalError: (MySQLdb.OperationalError) (2002, "Can't connect to MySQL server on 'core-mariadb' (115)") (Background on this error at: https://sqlalche.me/e/20/e3q8) Logger: homeassistant.components.recorder.util Source: components/recorder/util.py:614 Integration: Recorder (documentation, issues) First occurred: 16:46:43 (2 occurrences) Last logged: 16:46:46 Error executing compile missing statistics: (MySQLdb.OperationalError) (2013, 'Lost connection to MySQL server during query') [SQL: SELECT states.metadata_id, states.state, states.last_changed_ts, states.last_updated_ts, states.attributes, state_attributes.shared_attrs FROM states INNER JOIN (SELECT states.metadata_id AS max_metadata_id, max(states.last_updated_ts) AS max_last_updated FROM states WHERE states.last_updated_ts >= %s AND states.last_updated_ts < %s AND states.metadata_id IN (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s) GROUP BY states.metadata_id) AS anon_1 ON states.metadata_id = anon_1.max_metadata_id AND states.last_updated_ts = anon_1.max_last_updated LEFT OUTER JOIN state_attributes ON states.attributes_id = state_attributes.attributes_id] [parameters: (1680722534.0, 1680742499.999999, 243, 148, 205, 150, 99, 20, 97, 245, 246, 117, 108, 109, 291, 292, 153, 293, 294, 25, 295, 297, 298, 299, 300, 123, 94, 301, 302, 303, 83, 164, 49, 330, 1184, 1185, 1186, 1201, 1202, 1203, 1204, 1205, 538, 181, 539, 122, 135, 29, 55, 648 ... 314 parameters truncated ... 951, 952, 954, 955, 956, 957, 168, 147, 958, 192, 1152, 1153, 1154, 1155, 1156, 1157, 2338, 2335, 189, 1095, 212, 142, 80, 81, 755, 756, 759, 760, 761, 762, 763, 764, 765, 767, 771, 775, 777, 779, 781, 783, 785, 787, 789, 790, 139, 2332, 2429, 8, 2440, 2461)] (Background on this error at: https://sqlalche.me/e/20/e3q8) Error executing compile statistics: (MySQLdb.OperationalError) (2002, "Can't connect to MySQL server on 'core-mariadb' (115)") (Background on this error at: https://sqlalche.me/e/20/e3q8) Logger: homeassistant.components.recorder.core Source: components/recorder/core.py:1201 Integration: Recorder (documentation, issues) First occurred: 16:46:45 (3 occurrences) Last logged: 16:46:47 Unhandled database error while processing task KeepAliveTask(): (MySQLdb.OperationalError) (2002, "Can't connect to MySQL server on 'core-mariadb' (115)") (Background on this error at: https://sqlalche.me/e/20/e3q8) Traceback (most recent call last): File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 145, in __init__ self._dbapi_connection = engine.raw_connection() File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 3275, in raw_connection return self.pool.connect() File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 455, in connect return _ConnectionFairy._checkout(self) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 1271, in _checkout fairy = _ConnectionRecord.checkout(pool) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 724, in checkout with util.safe_reraise(): File "/usr/local/lib/python3.10/site-packages/sqlalchemy/util/langhelpers.py", line 147, in __exit__ raise exc_value.with_traceback(exc_tb) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 722, in checkout dbapi_connection = rec.get_connection() File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 842, in get_connection self.__connect() File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 905, in __connect with util.safe_reraise(): File "/usr/local/lib/python3.10/site-packages/sqlalchemy/util/langhelpers.py", line 147, in __exit__ raise exc_value.with_traceback(exc_tb) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 901, in __connect self.dbapi_connection = connection = pool._invoke_creator(self) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/create.py", line 636, in connect return dialect.connect(*cargs, **cparams) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/default.py", line 580, in connect return self.loaded_dbapi.connect(*cargs, **cparams) File "/usr/local/lib/python3.10/site-packages/MySQLdb/__init__.py", line 123, in Connect return Connection(*args, **kwargs) File "/usr/local/lib/python3.10/site-packages/MySQLdb/connections.py", line 185, in __init__ super().__init__(*args, **kwargs2) MySQLdb.OperationalError: (2002, "Can't connect to MySQL server on 'core-mariadb' (115)") The above exception was the direct cause of the following exception: Traceback (most recent call last): File "/usr/src/homeassistant/homeassistant/components/recorder/core.py", line 836, in _process_one_task_or_recover return task.run(self) File "/usr/src/homeassistant/homeassistant/components/recorder/tasks.py", line 293, in run instance._send_keep_alive() File "/usr/src/homeassistant/homeassistant/components/recorder/core.py", line 1201, in _send_keep_alive self.event_session.connection().scalar(select(1)) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/orm/session.py", line 1965, in connection return self._connection_for_bind( File "/usr/local/lib/python3.10/site-packages/sqlalchemy/orm/session.py", line 1981, in _connection_for_bind return trans._connection_for_bind(engine, execution_options) File "<string>", line 2, in _connection_for_bind File "/usr/local/lib/python3.10/site-packages/sqlalchemy/orm/state_changes.py", line 137, in _go ret_value = fn(self, *arg, **kw) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/orm/session.py", line 1108, in _connection_for_bind conn = bind.connect() File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 3251, in connect return self._connection_cls(self) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 147, in __init__ Connection._handle_dbapi_exception_noconnection( File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 2413, in _handle_dbapi_exception_noconnection raise sqlalchemy_exception.with_traceback(exc_info[2]) from e File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 145, in __init__ self._dbapi_connection = engine.raw_connection() File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 3275, in raw_connection return self.pool.connect() File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 455, in connect return _ConnectionFairy._checkout(self) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 1271, in _checkout fairy = _ConnectionRecord.checkout(pool) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 724, in checkout with util.safe_reraise(): File "/usr/local/lib/python3.10/site-packages/sqlalchemy/util/langhelpers.py", line 147, in __exit__ raise exc_value.with_traceback(exc_tb) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 722, in checkout dbapi_connection = rec.get_connection() File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 842, in get_connection self.__connect() File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 905, in __connect with util.safe_reraise(): File "/usr/local/lib/python3.10/site-packages/sqlalchemy/util/langhelpers.py", line 147, in __exit__ raise exc_value.with_traceback(exc_tb) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 901, in __connect self.dbapi_connection = connection = pool._invoke_creator(self) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/create.py", line 636, in connect return dialect.connect(*cargs, **cparams) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/default.py", line 580, in connect return self.loaded_dbapi.connect(*cargs, **cparams) File "/usr/local/lib/python3.10/site-packages/MySQLdb/__init__.py", line 123, in Connect return Connection(*args, **kwargs) File "/usr/local/lib/python3.10/site-packages/MySQLdb/connections.py", line 185, in __init__ super().__init__(*args, **kwargs2) sqlalchemy.exc.OperationalError: (MySQLdb.OperationalError) (2002, "Can't connect to MySQL server on 'core-mariadb' (115)") (Background on this error at: https://sqlalche.me/e/20/e3q8) Logger: homeassistant.components.recorder.core Source: components/recorder/util.py:213 Integration: Recorder (documentation, issues) First occurred: 16:46:43 (1249 occurrences) Last logged: 16:46:48 Unhandled database error while processing task EventTask(event=<Event state_changed[L]: entity_id=sensor.emporiavue2_circuit_16_power, old_state=<state sensor.emporiavue2_circuit_16_power=90.4; state_class=measurement, unit_of_measurement=W, device_class=power, friendly_name=16 - Kitchen & Fridge - Power @ 2023-04-06T16:35:30.412444-04:00>, new_state=<state sensor.emporiavue2_circuit_16_power=89.9; state_class=measurement, unit_of_measurement=W, device_class=power, friendly_name=16 - Kitchen & Fridge - Power @ 2023-04-06T16:35:33.527551-04:00>>): (MySQLdb.OperationalError) (2002, "Can't connect to MySQL server on 'core-mariadb' (115)") (Background on this error at: https://sqlalche.me/e/20/e3q8) Unhandled database error while processing task EventTask(event=<Event state_changed[L]: entity_id=sensor.emporiavue2_circuit_17_power, old_state=<state sensor.emporiavue2_circuit_17_power=4.5; state_class=measurement, unit_of_measurement=W, device_class=power, friendly_name=17 - EVSE Port C - Power @ 2023-04-06T16:35:30.425842-04:00>, new_state=<state sensor.emporiavue2_circuit_17_power=5.2; state_class=measurement, unit_of_measurement=W, device_class=power, friendly_name=17 - EVSE Port C - Power @ 2023-04-06T16:35:33.537403-04:00>>): (MySQLdb.OperationalError) (2002, "Can't connect to MySQL server on 'core-mariadb' (115)") (Background on this error at: https://sqlalche.me/e/20/e3q8) Unhandled database error while processing task EventTask(event=<Event state_changed[L]: entity_id=sensor.emporiavue2_total_daily_energy, old_state=<state sensor.emporiavue2_total_daily_energy=25631; state_class=total_increasing, unit_of_measurement=Wh, device_class=energy, friendly_name=Emporia Total Daily Energy @ 2023-04-06T16:35:30.632568-04:00>, new_state=<state sensor.emporiavue2_total_daily_energy=25632; state_class=total_increasing, unit_of_measurement=Wh, device_class=energy, friendly_name=Emporia Total Daily Energy @ 2023-04-06T16:35:33.636255-04:00>>): (MySQLdb.OperationalError) (2002, "Can't connect to MySQL server on 'core-mariadb' (115)") (Background on this error at: https://sqlalche.me/e/20/e3q8) Unhandled database error while processing task EventTask(event=<Event state_changed[L]: entity_id=sensor.emporiavue2_total_power, old_state=<state sensor.emporiavue2_total_power=1257.4; unit_of_measurement=W, friendly_name=Emporia Total Power @ 2023-04-06T16:35:30.633392-04:00>, new_state=<state sensor.emporiavue2_total_power=1250.4; unit_of_measurement=W, friendly_name=Emporia Total Power @ 2023-04-06T16:35:33.637190-04:00>>): (MySQLdb.OperationalError) (2002, "Can't connect to MySQL server on 'core-mariadb' (115)") (Background on this error at: https://sqlalche.me/e/20/e3q8) Unhandled database error while processing task EventTask(event=<Event state_changed[L]: entity_id=sensor.emporiavue2_total_fcsp_power, old_state=<state sensor.emporiavue2_total_fcsp_power=4.5; unit_of_measurement=W, icon=mdi:ev-station, friendly_name=emporiavue2 Total FCSP Power @ 2023-04-06T16:35:30.756378-04:00>, new_state=<state sensor.emporiavue2_total_fcsp_power=5.2; unit_of_measurement=W, icon=mdi:ev-station, friendly_name=emporiavue2 Total FCSP Power @ 2023-04-06T16:35:33.762581-04:00>>): (MySQLdb.OperationalError) (2002, "Can't connect to MySQL server on 'core-mariadb' (115)") (Background on this error at: https://sqlalche.me/e/20/e3q8) Traceback (most recent call last): File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 145, in __init__ self._dbapi_connection = engine.raw_connection() File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 3275, in raw_connection return self.pool.connect() File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 455, in connect return _ConnectionFairy._checkout(self) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 1271, in _checkout fairy = _ConnectionRecord.checkout(pool) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 724, in checkout with util.safe_reraise(): File "/usr/local/lib/python3.10/site-packages/sqlalchemy/util/langhelpers.py", line 147, in __exit__ raise exc_value.with_traceback(exc_tb) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 722, in checkout dbapi_connection = rec.get_connection() File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 871, in get_connection self.__connect() File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 905, in __connect with util.safe_reraise(): File "/usr/local/lib/python3.10/site-packages/sqlalchemy/util/langhelpers.py", line 147, in __exit__ raise exc_value.with_traceback(exc_tb) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 901, in __connect self.dbapi_connection = connection = pool._invoke_creator(self) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/create.py", line 636, in connect return dialect.connect(*cargs, **cparams) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/default.py", line 580, in connect return self.loaded_dbapi.connect(*cargs, **cparams) File "/usr/local/lib/python3.10/site-packages/MySQLdb/__init__.py", line 123, in Connect return Connection(*args, **kwargs) File "/usr/local/lib/python3.10/site-packages/MySQLdb/connections.py", line 185, in __init__ super().__init__(*args, **kwargs2) MySQLdb.OperationalError: (2002, "Can't connect to MySQL server on 'core-mariadb' (115)") The above exception was the direct cause of the following exception: Traceback (most recent call last): File "/usr/src/homeassistant/homeassistant/components/recorder/core.py", line 836, in _process_one_task_or_recover return task.run(self) File "/usr/src/homeassistant/homeassistant/components/recorder/tasks.py", line 281, in run instance._process_one_event(self.event) File "/usr/src/homeassistant/homeassistant/components/recorder/core.py", line 942, in _process_one_event self._process_state_changed_event_into_session(event) File "/usr/src/homeassistant/homeassistant/components/recorder/core.py", line 1053, in _process_state_changed_event_into_session attributes_id := state_attributes_manager.get( File "/usr/src/homeassistant/homeassistant/components/recorder/table_managers/state_attributes.py", line 82, in get return self.get_many(((shared_attr, data_hash),), session)[shared_attr] File "/usr/src/homeassistant/homeassistant/components/recorder/table_managers/state_attributes.py", line 103, in get_many return results | self._load_from_hashes(missing_hashes, session) File "/usr/src/homeassistant/homeassistant/components/recorder/table_managers/state_attributes.py", line 116, in _load_from_hashes for attributes_id, shared_attrs in execute_stmt_lambda_element( File "/usr/src/homeassistant/homeassistant/components/recorder/util.py", line 213, in execute_stmt_lambda_element executed = session.execute(stmt) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/orm/session.py", line 2229, in execute return self._execute_internal( File "/usr/local/lib/python3.10/site-packages/sqlalchemy/orm/session.py", line 2114, in _execute_internal conn = self._connection_for_bind(bind) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/orm/session.py", line 1981, in _connection_for_bind return trans._connection_for_bind(engine, execution_options) File "<string>", line 2, in _connection_for_bind File "/usr/local/lib/python3.10/site-packages/sqlalchemy/orm/state_changes.py", line 137, in _go ret_value = fn(self, *arg, **kw) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/orm/session.py", line 1108, in _connection_for_bind conn = bind.connect() File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 3251, in connect return self._connection_cls(self) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 147, in __init__ Connection._handle_dbapi_exception_noconnection( File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 2413, in _handle_dbapi_exception_noconnection raise sqlalchemy_exception.with_traceback(exc_info[2]) from e File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 145, in __init__ self._dbapi_connection = engine.raw_connection() File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/base.py", line 3275, in raw_connection return self.pool.connect() File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 455, in connect return _ConnectionFairy._checkout(self) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 1271, in _checkout fairy = _ConnectionRecord.checkout(pool) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 724, in checkout with util.safe_reraise(): File "/usr/local/lib/python3.10/site-packages/sqlalchemy/util/langhelpers.py", line 147, in __exit__ raise exc_value.with_traceback(exc_tb) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 722, in checkout dbapi_connection = rec.get_connection() File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 871, in get_connection self.__connect() File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 905, in __connect with util.safe_reraise(): File "/usr/local/lib/python3.10/site-packages/sqlalchemy/util/langhelpers.py", line 147, in __exit__ raise exc_value.with_traceback(exc_tb) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/pool/base.py", line 901, in __connect self.dbapi_connection = connection = pool._invoke_creator(self) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/create.py", line 636, in connect return dialect.connect(*cargs, **cparams) File "/usr/local/lib/python3.10/site-packages/sqlalchemy/engine/default.py", line 580, in connect return self.loaded_dbapi.connect(*cargs, **cparams) File "/usr/local/lib/python3.10/site-packages/MySQLdb/__init__.py", line 123, in Connect return Connection(*args, **kwargs) File "/usr/local/lib/python3.10/site-packages/MySQLdb/connections.py", line 185, in __init__ super().__init__(*args, **kwargs2) sqlalchemy.exc.OperationalError: (MySQLdb.OperationalError) (2002, "Can't connect to MySQL server on 'core-mariadb' (115)") (Background on this error at: https://sqlalche.me/e/20/e3q8)Additional information
Here are my logs from MariaDB (version 2.5.2) following the last reboot and also restart of the add-on.
The text was updated successfully, but these errors were encountered: