Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Refactor Horovod documentation (#25)
- Loading branch information
Showing
8 changed files
with
446 additions
and
423 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1,2 +1,2 @@ | ||
| recursive-include * *.h *.cc | ||
| include README.md LICENSE | ||
| recursive-include * *.h *.cc *.md | ||
| include LICENSE |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,27 @@ | ||
| ## Concepts | ||
|
|
||
| Horovod core principles are based on [MPI](http://mpi-forum.org/) concepts such as *size*, *rank*, | ||
| *local rank*, *allreduce*, *allgather* and *broadcast*. These are best explained by example. Say we launched | ||
| a training script on 4 servers, each having 4 GPUs. If we launched one copy of the script per GPU: | ||
|
|
||
| 1. *Size* would be the number of processes, in this case 16. | ||
|
|
||
| 2. *Rank* would be the unique process ID from 0 to 15 (*size* - 1). | ||
|
|
||
| 3. *Local rank* would be the unique process ID within the server from 0 to 3. | ||
|
|
||
| 4. *Allreduce* is an operation that aggregates data among multiple processes and distributes | ||
| results back to them. *Allreduce* is used to average dense tensors. Here's an illustration from the | ||
| [MPI Tutorial](http://mpitutorial.com/tutorials/mpi-reduce-and-allreduce/): | ||
|
|
||
| 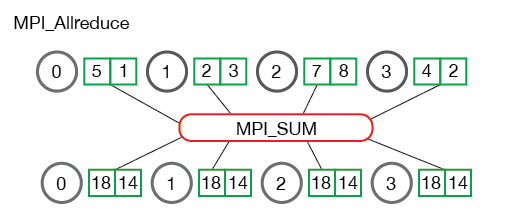 | ||
|
|
||
| 5. *Allgather* is an operation that gathers data from all processes on every process. *Allgather* is used to collect | ||
| values of sparse tensors. Here's an illustration from the [MPI Tutorial](http://mpitutorial.com/tutorials/mpi-scatter-gather-and-allgather/): | ||
|
|
||
| 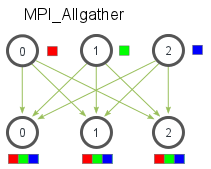 | ||
|
|
||
| 6. *Broadcast* is an operation that broadcasts data from one process, identified by root rank, onto every other process. | ||
| Here's an illustration from the [MPI Tutorial](http://mpitutorial.com/tutorials/mpi-broadcast-and-collective-communication/): | ||
|
|
||
| 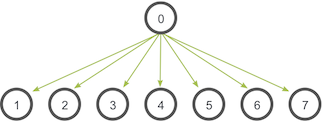 |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,112 @@ | ||
| ## Horovod on GPU | ||
|
|
||
| To use Horovod on GPU, read the options below and see which one applies to you best. | ||
|
|
||
| ### Have GPUs? | ||
|
|
||
| In most situations, using NCCL 2 will significantly improve performance over the CPU version. NCCL 2 provides the *allreduce* | ||
| operation optimized for NVIDIA GPUs and a variety of networking devices, such as RoCE or InfiniBand. | ||
|
|
||
| 1. Install [NCCL 2](https://developer.nvidia.com/nccl). | ||
|
|
||
| Steps to install NCCL 2 are listed [here](http://docs.nvidia.com/deeplearning/sdk/nccl-install-guide/index.html). | ||
|
|
||
| If you have installed NCCL 2 using the `nccl-<version>.txz` package, you should add the library path to `LD_LIBRARY_PATH` | ||
| environment variable or register it in `/etc/ld.so.conf`. | ||
|
|
||
| ```bash | ||
| $ export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/nccl-<version>/lib | ||
| ``` | ||
|
|
||
| 2. Install [Open MPI](https://www.open-mpi.org/) or another MPI implementation. | ||
|
|
||
| Steps to install Open MPI are listed [here](https://www.open-mpi.org/faq/?category=building#easy-build). | ||
|
|
||
| 3. Install the `horovod` pip package. | ||
|
|
||
| If you have installed NCCL 2 using the `nccl-<version>.txz` package, you should specify the path to NCCL 2 using the `HOROVOD_NCCL_HOME` | ||
| environment variable. | ||
|
|
||
| ```bash | ||
| $ HOROVOD_NCCL_HOME=/usr/local/nccl-<version> HOROVOD_GPU_ALLREDUCE=NCCL pip install --no-cache-dir horovod | ||
| ``` | ||
|
|
||
| If you have installed NCCL 2 using the Ubuntu package, you can simply run: | ||
|
|
||
| ```bash | ||
| $ HOROVOD_GPU_ALLREDUCE=NCCL pip install --no-cache-dir horovod | ||
| ``` | ||
|
|
||
| **Note**: Some models with a high computation to communication ratio benefit from doing allreduce on CPU, even if a | ||
| GPU version is available. To force allreduce to happen on CPU, pass `device_dense='/cpu:0'` to `hvd.DistributedOptimizer`: | ||
|
|
||
| ```python | ||
| opt = hvd.DistributedOptimizer(opt, device_dense='/cpu:0') | ||
| ``` | ||
|
|
||
| ### Advanced: Have GPUs and networking with GPUDirect? | ||
|
|
||
| [GPUDirect](https://developer.nvidia.com/gpudirect) allows GPUs to transfer memory among each other without CPU | ||
| involvement, which significantly reduces latency and load on CPU. NCCL 2 is able to use GPUDirect automatically for | ||
| *allreduce* operation if it detects it. | ||
|
|
||
| Additionally, Horovod uses *allgather* and *broadcast* operations from MPI. They are used for averaging sparse tensors | ||
| that are typically used for embeddings, and for broadcasting initial state. To speed these operations up with GPUDirect, | ||
| make sure your MPI implementation supports CUDA and add `HOROVOD_GPU_ALLGATHER=MPI HOROVOD_GPU_BROADCAST=MPI` to the pip | ||
| command. | ||
|
|
||
| 1. Install [NCCL 2](https://developer.nvidia.com/nccl). | ||
|
|
||
| Steps to install NCCL 2 are listed [here](http://docs.nvidia.com/deeplearning/sdk/nccl-install-guide/index.html). | ||
|
|
||
| If you have installed NCCL 2 using the `nccl-<version>.txz` package, you should add the library path to `LD_LIBRARY_PATH` | ||
| environment variable or register it in `/etc/ld.so.conf`. | ||
|
|
||
| ```bash | ||
| $ export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/nccl-<version>/lib | ||
| ``` | ||
|
|
||
| 2. Install [nv_peer_memory](http://www.mellanox.com/page/products_dyn?product_family=116) driver. | ||
|
|
||
| Follow instructions from that page, and make sure to do `/etc/init.d/nv_peer_mem start` in the end. | ||
|
|
||
| 3. Install [Open MPI](https://www.open-mpi.org/) or another MPI implementation with CUDA support. | ||
|
|
||
| Steps to install Open MPI are listed [here](https://www.open-mpi.org/faq/?category=building#easy-build). You should make | ||
| sure you build it with [CUDA support](https://www.open-mpi.org/faq/?category=building#build-cuda). | ||
|
|
||
| 4. Install the `horovod` pip package. | ||
|
|
||
| If you have installed NCCL 2 using the `nccl-<version>.txz` package, you should specify the path to NCCL 2 using the `HOROVOD_NCCL_HOME` | ||
| environment variable. | ||
|
|
||
| ```bash | ||
| $ HOROVOD_NCCL_HOME=/usr/local/nccl-<version> HOROVOD_GPU_ALLREDUCE=NCCL HOROVOD_GPU_ALLGATHER=MPI HOROVOD_GPU_BROADCAST=MPI pip install --no-cache-dir horovod | ||
| ``` | ||
|
|
||
| If you have installed NCCL 2 using the Ubuntu package, you can simply run: | ||
|
|
||
| ```bash | ||
| $ HOROVOD_GPU_ALLREDUCE=NCCL HOROVOD_GPU_ALLGATHER=MPI HOROVOD_GPU_BROADCAST=MPI pip install --no-cache-dir horovod | ||
| ``` | ||
|
|
||
| **Note**: Allgather allocates an output tensor which is proportionate to the number of processes participating in the | ||
| training. If you find yourself running out of GPU memory, you can force allreduce to happen on CPU by passing | ||
| `device_sparse='/cpu:0'` to `hvd.DistributedOptimizer`: | ||
|
|
||
| ```python | ||
| opt = hvd.DistributedOptimizer(opt, device_sparse='/cpu:0') | ||
| ``` | ||
|
|
||
| ### Advanced: Have MPI optimized for your network? | ||
|
|
||
| If you happen to have network hardware not supported by NCCL 2 or your MPI vendor's implementation on GPU is faster, | ||
| you can also use the pure MPI version of *allreduce*, *allgather* and *broadcast* on GPU. | ||
|
|
||
| 1. Make sure your MPI implementation is installed. | ||
|
|
||
| 2. Install the `horovod` pip package. | ||
|
|
||
| ```bash | ||
| $ HOROVOD_GPU_ALLREDUCE=MPI HOROVOD_GPU_ALLGATHER=MPI HOROVOD_GPU_BROADCAST=MPI pip install --no-cache-dir horovod | ||
| ``` |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,16 @@ | ||
| ## Inference | ||
|
|
||
| What about inference? Inference may be done outside of the Python script that was used to train the model. If you do this, it | ||
| will not have references to the Horovod library. | ||
|
|
||
| To run inference on a checkpoint generated by the Horovod-enabled training script you should optimize the graph and only | ||
| keep operations necessary for a forward pass through model. The [Optimize for Inference](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/tools/optimize_for_inference.py) | ||
| script from the TensorFlow repository will do that for you. | ||
|
|
||
| If you want to convert your checkpoint to [Frozen Graph](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/tools/freeze_graph.py), | ||
| you should do so after doing the optimization described above, otherwise the [Freeze Graph](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/tools/freeze_graph.py) | ||
| script will fail to load Horovod op: | ||
|
|
||
| ``` | ||
| ValueError: No op named HorovodAllreduce in defined operations. | ||
| ``` |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,28 @@ | ||
| ## Tensor Fusion | ||
|
|
||
| One of the unique things about Horovod is its ability to interleave communication and computation coupled with the ability | ||
| to batch small *allreduce* operations, which results in improved performance. We call this batching feature Tensor Fusion. | ||
|
|
||
| Tensor Fusion works by attempting to combine all the tensors that are ready to be reduced at given moment of time into | ||
| one reduction operation. The algorithm of Tensor Fusion is as follows: | ||
|
|
||
| 1. Determine which tensors are ready to be reduced. Select first few tensors that fit in `HOROVOD_FUSION_THRESHOLD` | ||
| bytes and have the same data type. | ||
| 2. Allocate fusion buffer of size `HOROVOD_FUSION_THRESHOLD` if it was not allocated before. Default fusion buffer size | ||
| is 64 MB. | ||
| 3. Copy data of selected tensors into the fusion buffer. | ||
| 4. Execute the *allreduce* operation on the fusion buffer. | ||
| 5. Copy data from the fusion buffer into the output tensors. | ||
| 6. Repeat until there are no more tensors to reduce in this cycle. | ||
|
|
||
| The fusion buffer size can be tweaked using the `HOROVOD_FUSION_THRESHOLD` environment variable: | ||
|
|
||
| ```bash | ||
| $ HOROVOD_FUSION_THRESHOLD=33554432 mpirun -np 4 -x HOROVOD_FUSION_THRESHOLD python train.py | ||
| ``` | ||
|
|
||
| Setting the `HOROVOD_FUSION_THRESHOLD` environment variable to zero disables Tensor Fusion: | ||
|
|
||
| ```bash | ||
| $ HOROVOD_FUSION_THRESHOLD=0 mpirun -np 4 -x HOROVOD_FUSION_THRESHOLD python train.py | ||
| ``` |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,43 @@ | ||
| ## Analyzing Horovod Performance | ||
|
|
||
| Horovod has the ability to record the timeline of its activity, called Horovod Timeline. | ||
|
|
||
| 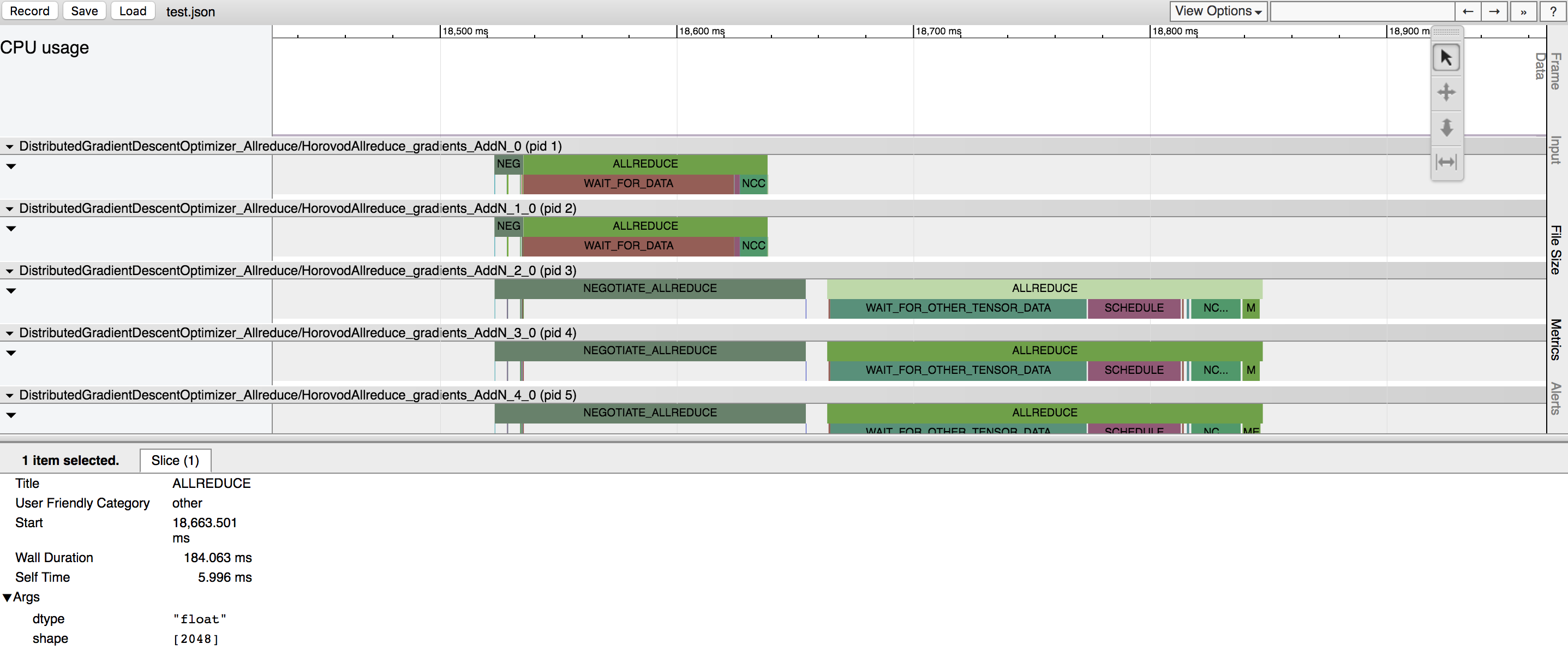 | ||
|
|
||
| To record a Horovod Timeline, set the `HOROVOD_TIMELINE` environment variable to the location of the timeline | ||
| file to be created. This file is only recorded on rank 0, but it contains information about activity of all workers. | ||
|
|
||
| ```bash | ||
| $ HOROVOD_TIMELINE=/path/to/timeline.json mpirun -np 4 -x HOROVOD_TIMELINE python train.py | ||
| ``` | ||
|
|
||
| You can then open the timeline file using the `chrome://tracing` facility of the [Chrome](https://www.google.com/chrome/browser/) browser. | ||
|
|
||
| In the example above, you can see few tensors being reduced. There are two major phases for each tensor reduction: | ||
|
|
||
| 1. **Negotiation** - a phase when all workers send to rank 0 signal that they're ready to reduce the given tensor. | ||
|
|
||
| * Each worker reporting readiness is represented by a tick under the *NEGOTIATE_ALLREDUCE* bar, so you can see which | ||
| workers were early and which were late. | ||
|
|
||
| * Immediately after negotiation, rank 0 sends all other workers signal to start reducing the tensor. | ||
|
|
||
| 2. **Processing** - a phase when the operation actually happens. It is further subdivided into multiple sub-phases: | ||
|
|
||
| * *WAIT_FOR_DATA* indicates time taken to wait for GPU to finish computing input to the *allreduce*, *allgather*, or | ||
| *broadcast* operations. This happens because TensorFlow tries to smartly interleave scheduling and GPU computation. | ||
| This is only applicable to situations where the Horovod operation is placed on GPU. | ||
|
|
||
| * *WAIT_FOR_OTHER_TENSOR_DATA* indicates time taken to wait for GPU to finish computing other inputs for other operations | ||
| that are part of the same fusion batch. | ||
|
|
||
| * *SCHEDULE* indicates how much time it took to schedule memory copies into and out of the fusion buffer and the NCCL | ||
| operation itself. | ||
|
|
||
| * *QUEUE* happens when reduction is done with NCCL, and the previous NCCL operation did not finish yet. | ||
|
|
||
| * *MEMCPY_IN_FUSION_BUFFER* and *MEMCPY_OUT_FUSION_BUFFER* indicate time taken to copy data into and out of the fusion | ||
| buffer. | ||
|
|
||
| * *NCCL_ALLREDUCE*, *MPI_ALLREDUCE*, *MPI_ALLGATHER*, or *MPI_BCAST* indicate time taken to do the actual operation on GPU | ||
| (or CPU) and highlights whether the operation was performed using NCCL or pure MPI. |
Oops, something went wrong.