Adasum algorithm for allreduce #1484
Closed
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
commit 44fd7f8 Merge: a3d5910 17e8d9c Author: Tixxx <tix@microsoft.com> Date: Thu Sep 5 14:34:51 2019 -0700 Merge pull request #11 from Tixxx/saemal/msallreducecudakernels Saemal/msallreducecudakernels commit 17e8d9c Merge: 03e225d a3d5910 Author: Saeed Maleki <30272783+saeedmaleki@users.noreply.github.com> Date: Wed Sep 4 15:55:17 2019 -0700 Merge branch 'tix/vhddwithlocalreduction' into saemal/msallreducecudakernels commit 03e225d Author: Ubuntu <ubuntu@ip-172-31-4-98.us-west-2.compute.internal> Date: Wed Sep 4 22:35:16 2019 +0000 tested ring allreduce for msallreduce commit 66305fa Author: Ubuntu <ubuntu@ip-172-31-4-98.us-west-2.compute.internal> Date: Wed Sep 4 01:36:39 2019 +0000 fixed the ring order commit 9331635 Author: Saeed Maleki <saemal@microsoft.com> Date: Fri Aug 30 20:40:28 2019 +0000 fixed most bugs commit a15ec1d Author: Saeed Maleki <saemal@microsoft.com> Date: Tue Aug 27 19:58:29 2019 +0000 checking before the nd40 goes away commit a3d5910 Author: Tix <tix@microsoft.com> Date: Tue Aug 27 11:19:12 2019 -0700 changed init and finalize logic in ms_cuda_msallreduce commit cd4aaed Author: Saeed Maleki <saemal@microsoft.com> Date: Mon Aug 26 22:53:07 2019 +0000 testing the ring allreduce commit 254cd7f Merge: d485099 e74f098 Author: Tixxx <tix@microsoft.com> Date: Mon Aug 26 12:30:22 2019 -0700 Merge pull request #10 from Tixxx/saemal/kernelcallsformsallreduce Saemal/kernelcallsformsallreduce commit e74f098 Author: Tix <tix@microsoft.com> Date: Mon Aug 26 12:04:29 2019 -0700 fixed copying from device to host commit fc4c733 Merge: d485099 4491b32 Author: Tix <tix@microsoft.com> Date: Mon Aug 26 11:00:27 2019 -0700 Merge branch 'saemal/kernelcallsformsallreduce' of https://github.com/Tixxx/horovod into saemal/kernelcallsformsallreduce commit f518e95 Author: Saeed Maleki <saemal@microsoft.com> Date: Fri Aug 23 22:52:34 2019 +0000 merged with ring allreducew commit e8bcec9 Merge: 4491b32 45b3488 Author: Saeed Maleki <saemal@microsoft.com> Date: Fri Aug 23 21:38:06 2019 +0000 Merge branch 'olsaarik/ringplusvhdd' into saemal/msallreducecudakernels commit 4491b32 Author: Saeed Maleki <saemal@microsoft.com> Date: Fri Aug 23 21:32:20 2019 +0000 fixed bug in setup.py commit 45b3488 Author: Olli Saarikivi <olsaarik@microsoft.com> Date: Fri Aug 23 21:28:38 2019 +0000 Fix variable declarations commit a1093e2 Author: Olli Saarikivi <olsaarik@microsoft.com> Date: Fri Aug 23 21:11:50 2019 +0000 Set ring cuda msallreduce as default commit eda4e4e Author: Saeed Maleki <saemal@microsoft.com> Date: Fri Aug 23 18:20:20 2019 +0000 cuda kernels compiles now -- need to fix for -arch=sm_ <60 commit 84288ad Author: Olli Saarikivi <olsaarik@microsoft.com> Date: Fri Aug 23 17:54:01 2019 +0000 Add hierarchical ring vhdd msallreduce commit d485099 Author: Tix <tix@microsoft.com> Date: Fri Aug 23 06:33:40 2019 -0700 fixed a type error in msallreduce commit 6604900 Merge: 71a82d9 2595113 Author: Saeed Maleki <saemal@microsoft.com> Date: Thu Aug 22 18:44:20 2019 +0000 Merge branch 'saemal/msallreducecudakernels' of https://github.com/Tixxx/horovod into saemal/msallreducecudakernels commit 71a82d9 Author: Saeed Maleki <saemal@microsoft.com> Date: Thu Aug 22 18:44:19 2019 +0000 fixing bugs with setup.py commit 2595113 Author: Saeed Maleki <saemal@microsoft.com> Date: Thu Aug 22 18:42:44 2019 +0000 added the CMakeList file for cuda kernel commit 799fc47 Author: Saeed Maleki <saemal@microsoft.com> Date: Thu Aug 22 07:36:32 2019 +0000 cuda kernel compiles now commit 925d3e4 Author: Saeed Maleki <saemal@microsoft.com> Date: Tue Aug 20 17:29:53 2019 -0700 added kernel calls and the hooks for calling them commit e69452a Author: Saeed Maleki <saemal@microsoft.com> Date: Tue Aug 20 17:29:21 2019 -0700 added kernel calls and the hooks for calling them commit d6408c9 Author: Tix <tix@microsoft.com> Date: Tue Aug 20 14:56:46 2019 -0700 fixed correctness bug commit eabaa57 Merge: 4245b57 75363ef Author: Tixxx <tix@microsoft.com> Date: Fri Aug 16 09:39:46 2019 -0700 Merge pull request #7 from Tixxx/tix/vhddwithlocalreductiongpu tixTix/vhddwithlocalreductiongpu commit 75363ef Author: Tix <tix@microsoft.com> Date: Fri Aug 16 09:26:29 2019 -0700 PR comments assign streams based on layerid and number of threads. Name change for cublas initilization method commit e3c75f7 Author: Tix <tix@microsoft.com> Date: Thu Aug 15 17:18:43 2019 -0700 fixed mem leak. fixed seg fault. improved stream usage. commit da32b1f Author: Tix <tix@microsoft.com> Date: Thu Aug 15 01:27:02 2019 -0700 fixed multithreading issue with tensorflow give each thread a cuda stream fixed communicator bug caused by merge commit 30056aa Merge: 756b4fa 4245b57 Author: Tix <tix@microsoft.com> Date: Wed Aug 14 23:48:56 2019 -0700 Merge branch 'tix/vhddwithlocalreduction' of https://github.com/Tixxx/horovod into tix/vhddwithlocalreductiongpu commit 756b4fa Author: Tix <tix@microsoft.com> Date: Wed Aug 14 22:48:00 2019 -0700 added fp16 support for gpu commit 4245b57 Merge: 2a1eedf 04fa0e4 Author: klipto <todd.mytkowicz@gmail.com> Date: Wed Aug 14 17:17:11 2019 -0700 Merge pull request #9 from Tixxx/tree_local_reduce tree local reduce commit 04fa0e4 Author: Saeed Maleki <saemal@microsoft.com> Date: Thu Aug 15 00:15:39 2019 +0000 simple fix commit 1f5c22f Author: Saeed Maleki <saemal@microsoft.com> Date: Wed Aug 14 23:58:15 2019 +0000 tree local reduce commit 33dbe83 Author: Tix <tix@microsoft.com> Date: Tue Aug 13 15:56:53 2019 -0700 fixed cuda init to make gpu reduction work commit 93d7b37 Author: Tix <tix@microsoft.com> Date: Mon Aug 12 15:37:14 2019 -0700 addressed some comments in pr commit bc889f3 Author: Tix <tix@microsoft.com> Date: Mon Aug 12 14:19:46 2019 -0700 integration branch commit 68de8a1 Author: Tix <tix@microsoft.com> Date: Mon Aug 12 14:18:09 2019 -0700 changed to cublasxxxEx call and only with float32 commit 8312976 Author: Tix <tix@microsoft.com> Date: Mon Aug 12 13:29:42 2019 -0700 compile pass. divide by zero exception in float to double casting commit 505aed1 Author: Tix <tix@microsoft.com> Date: Mon Aug 12 10:42:26 2019 -0700 adding gpu support for ms allreduce logic in progress commit 2a1eedf Merge: a1913e8 d33fa92 Author: Vadim Eksarevskiy <42353187+vaeksare@users.noreply.github.com> Date: Fri Aug 9 15:57:29 2019 -0700 Merge pull request #5 from vaeksare/vaeksare/separate_average Vaeksare/separate average commit d33fa92 Author: Vadim Eksarevskiy <vaeksare@microsoft.com> Date: Fri Aug 9 14:54:15 2019 -0700 deleted accidental binary files commit 2e63692 Author: Vadim Eksarevskiy <vaeksare@microsoft.com> Date: Fri Aug 9 14:51:00 2019 -0700 refactored msallreduce to be a separate op in horovod commit a1913e8 Merge: 3a8cdd2 9accd83 Author: klipto <toddm@microsoft.com> Date: Fri Aug 9 14:15:47 2019 -0700 Merge branch 'tix/vhddwithlocalreduction' of https://github.com/Tixxx/horovod into tix/vhddwithlocalreduction commit 3a8cdd2 Author: klipto <toddm@microsoft.com> Date: Fri Aug 9 14:06:02 2019 -0700 workaround for # of elements/size issue commit 55e6ce1 Author: root <root@GCRHYPCBJ016.redmond.corp.microsoft.com> Date: Fri Aug 9 13:29:42 2019 -0700 fixed load and added guard for potential bug commit 9accd83 Author: Tix <tix@microsoft.com> Date: Fri Aug 9 11:28:48 2019 -0700 simplified average logic commit e364f14 Merge: 278e86c 3dde0e4 Author: Tix <tix@microsoft.com> Date: Thu Aug 8 10:09:14 2019 -0700 Merge branch 'tix/vhddwithallreduce' into tix/vhddwithlocalreduction commit 278e86c Author: Tix <tix@microsoft.com> Date: Wed Aug 7 17:02:52 2019 -0700 merge with tf fixes commit 3dde0e4 Merge: 83e68e1 a0b9469 Author: klipto <todd.mytkowicz@gmail.com> Date: Wed Aug 7 16:32:43 2019 -0700 Merge pull request #4 from Tixxx/adding_test_functionality Added a test for fp16,32,64 tensor allreduce correctness commit a0b9469 Author: Todd Mytkowicz <toddm@microsoft.com> Date: Wed Aug 7 13:52:44 2019 -0700 Added a test for fp16,32,64 tensor allreduce correctness commit 83e68e1 Author: Tix <tix@microsoft.com> Date: Wed Aug 7 13:33:47 2019 -0700 replaced local reduction with mpi allreduce commit c1e5f9c Author: Tix <tix@microsoft.com> Date: Tue Aug 6 14:34:56 2019 -0700 added more optimization flags for compiler commit 5509baf Author: Tix <tix@microsoft.com> Date: Tue Aug 6 09:29:21 2019 -0700 integrated with the vhdd bug fix commit dfda595 Merge: c3c0257 efe1886 Author: Vadim Eksarevskiy <42353187+vaeksare@users.noreply.github.com> Date: Mon Aug 5 18:20:30 2019 -0700 Merge pull request #2 from vaeksare/vaeksare/hvdd pytorch workaround commit efe1886 Author: Vadim Eksarevskiy <vaeksare@microsoft.com> Date: Mon Aug 5 18:18:19 2019 -0700 pytorch workaround commit c3c0257 Author: Tix <tix@microsoft.com> Date: Mon Aug 5 17:50:39 2019 -0700 merged with vhdd. merged with fix in TF averaging logic. commit b02994a Author: Tix <tix@microsoft.com> Date: Mon Aug 5 11:37:23 2019 -0700 added float16 data type commit 6116e7e Author: Tix <tix@microsoft.com> Date: Fri Aug 2 18:44:20 2019 -0700 fixed averaging bug in tensorflow commit b8cab29 Author: Tix <tix@microsoft.com> Date: Thu Aug 1 14:29:56 2019 -0700 added new parasail algo commit fa658eb Author: Tix <tix@microsoft.com> Date: Thu Aug 1 09:37:34 2019 -0700 integrated new parasail algorithm commit 4402dac Author: Tix <tix@microsoft.com> Date: Tue Jul 30 10:43:29 2019 -0700 added single and multiple large tensor test commit f6e6c89 Author: Tix <tix@microsoft.com> Date: Fri Jul 26 17:22:47 2019 -0700 merged with local change commit 6d5fd6c Author: Tix <tix@microsoft.com> Date: Fri Jul 26 17:21:04 2019 -0700 merged with temp_buffer commit 46e6ab4 Merge: 9c0a7ac cb29e32 Author: Vadim Eksarevskiy <vaeksare@microsoft.com> Date: Fri Jul 26 14:34:02 2019 -0700 fix merge conflict in global state commit 9c0a7ac Author: Vadim Eksarevskiy <vaeksare@microsoft.com> Date: Fri Jul 26 13:44:36 2019 -0700 added basic pytorch tests for msallreduce commit c5b1a7f Author: Vadim Eksarevskiy <vaeksare@microsoft.com> Date: Thu Jul 25 17:27:22 2019 -0700 added temp buffer for msallreduce op commit a7c14a5 Author: Tix <tix@microsoft.com> Date: Fri Jul 26 13:52:16 2019 -0700 fixed some issues with broadcast when fusing respones. Added more logging. commit cb29e32 Author: Vadim Eksarevskiy <vaeksare@microsoft.com> Date: Fri Jul 26 13:44:36 2019 -0700 added basic pytorch tests for msallreduce commit bc40e87 Author: Vadim Eksarevskiy <vaeksare@microsoft.com> Date: Thu Jul 25 17:27:22 2019 -0700 added temp buffer for msallreduce op commit b644b1b Author: Tix <tix@microsoft.com> Date: Thu Jul 25 14:01:43 2019 -0700 fixed seg fault. added multi-tensor test commit 7babc10 Author: Tix <tix@microsoft.com> Date: Wed Jul 24 22:45:52 2019 -0700 fixed seg fault for 1 tensor case, still happens for multipl tensors commit 81f4de3 Author: Tix <tix@microsoft.com> Date: Wed Jul 24 13:40:29 2019 -0700 committing rest of the parallel code. debugging seg fault.. commit 5fadb9d Author: Tix <tix@microsoft.com> Date: Tue Jul 23 21:50:23 2019 -0700 incorporated threadpool and changed global state class. Added test. commit 4bf49e6 Author: Tix <tix@microsoft.com> Date: Tue Jul 23 14:22:51 2019 -0700 added more logging and data types for ms allreduce commit e4e3bb6 Author: Tix <tix@microsoft.com> Date: Tue Jul 16 15:15:47 2019 -0700 moved p2p comm implementations to header file commit 730e9fb Author: Tix <tix@microsoft.com> Date: Tue Jul 16 13:00:36 2019 -0700 first commit of p2p comm together with parasail op
fixed gpu build
1. removed template functions, replaced with one template class to contain adasum logic 2. separated mpi from adasum logic. adasum is now independent from comm 3. modularized reduction functions
2. added a function switch in cuda operations
Various bug fixes
This is required for the new NCCL+Adasum hierarchical allreduce. Alternatively that could be split to a new op.
2. factored out ring allreduce functions 3. fixed some bugs related to response cache and mpi calls
Add tracing prints for which adasum algo is called.
…horovod into tix/master_rebase_cleanup
2. changed enabled function to return true based on adasum env
… cpu computations as well. added a cudaSetDevice call when multi-threading added ADASUM in response cache
Tix/master rebase cleanup
Create rings based on NVlink topology.
Algorithm and core implementation courtesy of Saeed Maleki.
Reorder functions in adasum.h
Delta optimizers for both torch and tensorflow
…ix/delta_perf_hook
Tix/delta perf hook
|
closing this one and reopening another one with updated history |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Adasum
What is Adasum
Scaling DNN training to many GPUs always comes at a convergence degradation. This is because with larger batch sizes, gradients are averaged and the learning rate per example is smaller. To address this, learning rate is usually scaled up but this can lead to divergence of model parameters. Adasum addresses these two issues without introducing any hyper-parameter.
Suppose there are two almost-parallel gradients from two different GPUs, g1 and g2, and they need to be reduced as shown in the figure below. The two common practices for reductions are g1+g2, the gray vector or (g1+g2)/2, the green vector. g1+g2 may cause divergence of the model since it is effectively moving in the direction of g1 or g2 by two times the magnitude of g1 or g2. Therefore, generally (g1+g2)/2 is safer and more desired.

Now consider the two orthogonal gradients g1 and g2 in the figure below. Since g1 and g2 are in two different dimensions and independent of each other, g1+g2 may not cause divergence.
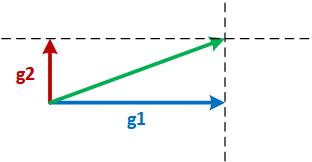
Finally, consider the third scenario where g1 and g2 are neither parallel nor orthogonal as shown in the figure below. In such a case, Adasum projects g2 on the orthogonal space of g1 (the pink vector) and adds that with g1 to produce the reduced vector. In this case, the final vector moves in each dimension only as much as each of g1 or g2 and therefore causes no divergence.
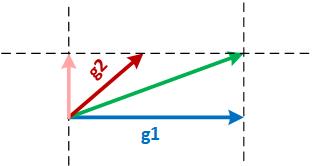
This idea extends to many gradients as well. Suppose there are 2^n gradients coming from 2^n different GPUs. Adasum inductively takes pairs of gradients and reduces them using the method above until all of them are reduced into one gradient.
Highlights of code changes
We provide an algorithmic interface which does not have any dependency on a particular communication library for extensibility. An MPI version of implementation of Adasum has been provided to support new operations we have added to Horovod. Here is the list of changes that we propose:
Adasum class in
horovod/common/ops/adasum/adasum.h: Algorithmic interface of Adasum which contains the main logic.AdasumMPI class in
horovod/common/ops/adasum/adasum_mpi.handadasum_mpi.cc: An MPI implementation of Adasum algorithm.AdasumMPIAllreduceOp class in
horovod/common/ops/adasum_mpi_operations.handadasum_mpi_operations.cc: A new operation class that inherits from AdasumMPI and Horovod's AllreduceOp. This utilizes the fusion buffer to perform efficient Adasum reductions on CPU when HOROVOD_GPU_ALLREDUCE is set to None.AdasumCudaAllreduceOp class in
horovod/common/ops/adasum_cuda_operations.handadasum_cuda_operations.cc: A new operation class that inherits from AdasumMPI and Horovod's NCCLAllreduce. This is a hierarchical operation that uses NCCL to perform intra-node sum-averaging and Adasum algorithm for inter-node reductions. This op requires Horovod to be compiled with HOROVOD_GPU_ALLREDUCE=NCCLA new response and request type has been introduced in addition to existing ones:
enum ResponseType { ALLREDUCE = 0, ALLGATHER = 1, BROADCAST = 2, ADASUM = 3, ERROR = 4};HOROVOD_ADASUM_MPI_CHUNK_SIZEhas been introduced to improve MPI communication efficiency for some platform configurations(i.e. Azure NC series machines + IntelMPI).In addition to the above changes in Horovod's common library, we also added a list of changes to framework layer for both Tensorflow and Pytorch to enable easy use of Adasum:
An enum that contains a list of allreduce operations has been introduced for users to select among Average, Sum or Adasum. This improves extensibility to add more ops in the future and backward compatibility.
An optional parameter
ophas been added to DistributedOptimizer and allreduce API for users to specify which operation to perform.A new distributed optimizer has been added to both frameworks to support Adasum algorithm. Since the nature of Adasum requires it to operate on the full magnitude of the gradient, the newly added distributed optimizer uses the difference in magnitude of weights between before and after the optimizer performs a step to deliver a more accurate estimation. When
op=hvd.Adasumis specified, the new optimizer will be used.DistributedOptimizer example for Tensorflow:
opt = tf.train.AdamOptimizer(0.001)opt = hvd.DistributedOptimizer(opt, backward_passes_per_step=5, op=hvd.Adasum)Allreduce example for Tensorflow:
hvd.allreduce(tensor, op=hvd.Adasum)DistributedOptimizer example for Pytorch:
optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum)optimizer = hvd.DistributedOptimizer(optimizer, named_parameters=model.named_parameters(), compression=compression, backward_passes_per_step = 5, op=hvd.Adasum)Allreduce example for Pytorch:
hvd.allreduce(tensor, op=hvd.Adasum)Additional notes
Adasum ensures correct convergence behavior even with large effective batch sizes.
As the number of ranks scales up, the learning rate does not need to be scaled if using CPU to do Adasum reduction. If HOROVOD_GPU_ALLREDUCE=NCCL flag is used to compile Horovod, Adasum needs the learning rate to be scaled by the number of GPUs locally on a node.
Pytorch training in fp16 format is not yet supported by this pull request. We are in the process of integrating Apex into the new optimizer to enabled full mixed precision training with Adasum in Pytorch.
When
HOROVOD_GPU_ALLREDUCE=NCCLflag is used to compile Horovod and training is run on a single node, only averaging through NCCL library is used to perform reductions and no Adasum algorithm will take place in this configuration.