Introducing Adasum algorithm to do allreduction. #1485
Conversation
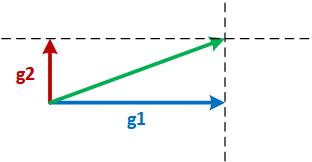
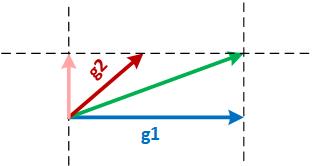
AdasumWhat is AdasumScaling DNN training to many GPUs always comes at a convergence degradation. This is because with larger batch sizes, gradients are averaged and the learning rate per example is smaller. To address this, learning rate is usually scaled up but this can lead to divergence of model parameters. Adasum addresses these two issues without introducing any hyper-parameter. Suppose there are two almost-parallel gradients from two different GPUs, g1 and g2, and they need to be reduced as shown in the figure below. The two common practices for reductions are g1+g2, the gray vector or (g1+g2)/2, the green vector. g1+g2 may cause divergence of the model since it is effectively moving in the direction of g1 or g2 by two times the magnitude of g1 or g2. Therefore, generally (g1+g2)/2 is safer and more desired. Now consider the two orthogonal gradients g1 and g2 in the figure below. Since g1 and g2 are in two different dimensions and independent of each other, g1+g2 may not cause divergence. Finally, consider the third scenario where g1 and g2 are neither parallel nor orthogonal as shown in the figure below. In such a case, Adasum projects g2 on the orthogonal space of g1 (the pink vector) and adds that with g1 to produce the reduced vector. In this case, the final vector moves in each dimension only as much as each of g1 or g2 and therefore causes no divergence. This idea extends to many gradients as well. Suppose there are 2^n gradients coming from 2^n different GPUs. Adasum inductively takes pairs of gradients and reduces them using the method above until all of them are reduced into one gradient. Highlights of code changesWe provide an algorithmic interface which does not have any dependency on a particular communication library for extensibility. An MPI version of implementation of Adasum has been provided to support new operations we have added to Horovod. Here is the list of changes that we propose:
In addition to the above changes in Horovod's common library, we also added a list of changes to framework layer for both Tensorflow and Pytorch to enable easy use of Adasum:
Additional notes
|

c315af2
to
a0e2a48
Compare
46e00f0
to
731552e
Compare
|
@jaliyae is added to the review. #Closed |
|
re-opening to trigger CI |
afcadd7
to
b2bcf91
Compare
1. Adasum operations for both CPU and NCCL build of Horovod 2. Framework support in Tensorflow and Pytorch to enable Adasum 3. A new optimizer added for Tensorflow and Pytorch to deliver more accurate estimation when using Adasum Main contributors: Olli Saarikivi (olsaarik) Vadim Eksarevskiy (vaeksare) Jaliya Ekanayake (jaliyae) Todd Mytkowicz (klipto) Saeed Maleki(saeedmaleki) Sergii Dymchenko(kit1980) Signed-off-by: Tix <tix@microsoft.com>
Signed-off-by: Tix <tix@microsoft.com>
Signed-off-by: Tix <tix@microsoft.com>
Signed-off-by: Tix <tix@microsoft.com>
made test to be compatible with python27 Signed-off-by: Tix <tix@microsoft.com>
Signed-off-by: Tix <tix@microsoft.com>
added adasum as an option in pytorch resnet example Signed-off-by: Tix <tix@microsoft.com>
Signed-off-by: Tix <tix@microsoft.com>
Signed-off-by: Tix <tix@microsoft.com>
Signed-off-by: Tix <tix@microsoft.com>
fixed incorrect lr scaling in examples when using Adasum improved tf test to support tf 2.0 Signed-off-by: Tix <tix@microsoft.com>
Signed-off-by: Tix <tix@microsoft.com>
…alized. dont run cpu tests if mpi is not available Signed-off-by: Tix <tix@microsoft.com>
Signed-off-by: Tix <tix@microsoft.com>
Signed-off-by: Tix <tix@microsoft.com>
Signed-off-by: Tix <tix@microsoft.com>
SKip Gloo tests for Adasum Signed-off-by: Tix <tix@microsoft.com>
…t Horovod is compiled without GPU-ALLREDUCE flag. Signed-off-by: Tix <tix@microsoft.com>
Fixed mxnet import failure. Signed-off-by: Tix <tix@microsoft.com>
Signed-off-by: Tix <tix@microsoft.com>
88b0a0d
to
08cf4e9
Compare
There was a problem hiding this comment.
Everything looks good from our end. Let's go ahead and merge this with plans for a few followup PRs:
- Documentation describing Adasum (could use description from this PR) along with guidance on when to expect it to significantly improve results.
- TensorFlow 2.0 support.
- Keras support.
|
@Tixxx Are there any comparative experiment results for Adasum showing the speed and accuracy of the training for some benchmarks? |
|
@Tixxx does AdaSum guarantee two critical convergence properties of SGD?
|
Hi @thyeros, The expected value of the computed gradients with Adasum is not necessarily the true gradient of all training example but has a positive inner product with it. Note that the loss value decreases if the model is update with any direction that has a positive inner product with the gradient (provided that the higher order term in Taylor series are negligible). The variance for the gradients computed with Adasum is bounded as long as the learning is scheduled properly. |
* Introducing Adasum algorithm to do allreduction. 1. Adasum operations for both CPU and NCCL build of Horovod 2. Framework support in Tensorflow and Pytorch to enable Adasum 3. A new optimizer added for Tensorflow and Pytorch to deliver more accurate estimation when using Adasum Main contributors: Olli Saarikivi (olsaarik) Vadim Eksarevskiy (vaeksare) Jaliya Ekanayake (jaliyae) Todd Mytkowicz (klipto) Saeed Maleki(saeedmaleki) Sergii Dymchenko(kit1980) Signed-off-by: Tix <tix@microsoft.com>
| @@ -96,6 +97,10 @@ def extension_available(ext_base_name, verbose=False): | |||
| return _check_extension_lambda( | |||
| ext_base_name, available_fn, 'built', verbose) or False | |||
|
|
|||
| def gpu_available(ext_base_name, verbose=False): | |||
| available_fn = lambda ext: ext._check_has_gpu() | |||
There was a problem hiding this comment.
Hi, I got the following errors with horovodrun:
Checking whether extension tensorflow was running with GPU.
Traceback (most recent call last):
File "/home/xianyang/opt/miniconda3/lib/python3.7/site-packages/horovod/common/util.py", line 73, in _target_fn
ext = importlib.import_module('.' + ext_base_name, 'horovod')
File "/home/xianyang/opt/miniconda3/lib/python3.7/importlib/__init__.py", line 127, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 1006, in _gcd_import
File "<frozen importlib._bootstrap>", line 983, in _find_and_load
File "<frozen importlib._bootstrap>", line 967, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 677, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 728, in exec_module
File "<frozen importlib._bootstrap>", line 219, in _call_with_frames_removed
File "/home/xianyang/opt/miniconda3/lib/python3.7/site-packages/horovod/tensorflow/__init__.py", line 43, in <module>
has_gpu = gpu_available('tensorflow')
File "/home/xianyang/opt/miniconda3/lib/python3.7/site-packages/horovod/common/util.py", line 103, in gpu_available
ext_base_name, available_fn, 'running with GPU', verbose) or False
File "/home/xianyang/opt/miniconda3/lib/python3.7/site-packages/horovod/common/util.py", line 90, in _check_extension_lambda
p.start()
File "/home/xianyang/opt/miniconda3/lib/python3.7/multiprocessing/process.py", line 110, in start
'daemonic processes are not allowed to have children'
AssertionError: daemonic processes are not allowed to have children
Extension tensorflow was NOT running with GPU.
This could be reproduced with:
horovod.common.util.gpu_available('tensorflow', True)
Add extra checks for x86 compiler flags and x86 AVX headers/functions Signed-off-by: Nicolas V Castet <nvcastet@us.ibm.com>
Add extra checks for x86 compiler flags and x86 AVX headers/functions Signed-off-by: Nicolas V Castet <nvcastet@us.ibm.com>
|
@eric-haibin-lin, we will share a perf study soon along with a userguide for AdaSum. |
|
@jaliyae thanks! look forward to it |
Main contributors:
Olli Saarikivi (olsaarik)
Vadim Eksarevskiy (vaeksare)
Jaliya Ekanayake (jaliyae)
Todd Mytkowicz (klipto)
Saeed Maleki(saeedmaleki)
Sergii Dymchenko(kit1980)
Tianju Xu(Tixxx)