A curated list for Efficient Large Language Models:
- Knowledge Distillation
- Network Pruning
- Quantization
- Inference Acceleration
- Efficient MOE
- Efficient Architecture of LLM
- Text Compression
- Low-Rank Decomposition
- Hardware/System
- Tuning
- Survey
- Leaderboard
- Sep 27, 2023: Add tag
for papers accepted at NeurIPS'23.
- Sep 6, 2023: Add a new subdirectory project/ to organize those projects that are designed for developing a lightweight LLM.
- July 11, 2023: In light of the numerous publications that conducts experiments using PLMs (such as BERT, BART) currently, a new subdirectory efficient_plm/ is created to house papers that are applicable to PLMs but have yet to be verified for their effectiveness on LLMs (not implying that they are not suitable on LLM).
If you'd like to include your paper, or need to update any details such as conference information or code URLs, please feel free to submit a pull request. You can generate the required markdown format for each paper by filling in the information in generate_item.py and execute python generate_item.py. We warmly appreciate your contributions to this list. Alternatively, you can email me with the links to your paper and code, and I would add your paper to the list at my earliest convenience.



















































































































































| Title & Authors | Introduction | Links |
|---|---|---|
 GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers Elias Frantar, Saleh Ashkboos, Torsten Hoefler, Dan Alistarh |
 |
Github Paper |
 SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, Song Han |
 |
Github Paper |
 QLoRA: Efficient Finetuning of Quantized LLMs Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, Luke Zettlemoyer |
 |
Github Paper |
 QuIP: 2-Bit Quantization of Large Language Models With Guarantees Jerry Chee, Yaohui Cai, Volodymyr Kuleshov, Christopher De SaXQ |
 |
Github Paper |
Memory-Efficient Fine-Tuning of Compressed Large Language Models via sub-4-bit Integer Quantization Jeonghoon Kim, Jung Hyun Lee, Sungdong Kim, Joonsuk Park, Kang Min Yoo, Se Jung Kwon, Dongsoo Lee |
 |
Paper |
Quantizable Transformers: Removing Outliers by Helping Attention Heads Do Nothing Yelysei Bondarenko, Markus Nagel, Tijmen Blankevoort |
 |
Github Paper |
 LLM-FP4: 4-Bit Floating-Point Quantized Transformers Shih-yang Liu, Zechun Liu, Xijie Huang, Pingcheng Dong, Kwang-Ting Cheng |
 |
Github Paper |
Enhancing Computation Efficiency in Large Language Models through Weight and Activation Quantization Jangwhan Lee, Minsoo Kim, Seungcheol Baek, Seok Joong Hwang, Wonyong Sung, Jungwook Choi |
 |
Paper |
Agile-Quant: Activation-Guided Quantization for Faster Inference of LLMs on the Edge Xuan Shen, Peiyan Dong, Lei Lu, Zhenglun Kong, Zhengang Li, Ming Lin, Chao Wu, Yanzhi Wang |
 |
Paper |
 OmniQuant: Omnidirectionally Calibrated Quantization for Large Language Models Wenqi Shao, Mengzhao Chen, Zhaoyang Zhang, Peng Xu, Lirui Zhao, Zhiqian Li, Kaipeng Zhang, Peng Gao, Yu Qiao, Ping Luo |
 |
Github Paper |
 AffineQuant: Affine Transformation Quantization for Large Language Models Yuexiao Ma, Huixia Li, Xiawu Zheng, Feng Ling, Xuefeng Xiao, Rui Wang, Shilei Wen, Fei Chao, Rongrong Ji |
 |
Github Paper |
GPT-Zip: Deep Compression of Finetuned Large Language Models Berivan Isik, Hermann Kumbong, Wanyi Ning, Xiaozhe Yao, Sanmi Koyejo, Ce Zhang |
 |
Paper |
 Watermarking LLMs with Weight Quantization Linyang Li, Botian Jiang, Pengyu Wang, Ke Ren, Hang Yan, Xipeng Qiu |
 |
Github Paper |
 AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Xingyu Dang, Song Han |
 |
Github Paper |
 RPTQ: Reorder-based Post-training Quantization for Large Language Models Zhihang Yuan and Lin Niu and Jiawei Liu and Wenyu Liu and Xinggang Wang and Yuzhang Shang and Guangyu Sun and Qiang Wu and Jiaxiang Wu and Bingzhe Wu |
 |
Github Paper |
| ZeroQuant-V2: Exploring Post-training Quantization in LLMs from Comprehensive Study to Low Rank Compensation Zhewei Yao, Xiaoxia Wu, Cheng Li, Stephen Youn, Yuxiong He |
 |
Paper |
 SqueezeLLM: Dense-and-Sparse Quantization Sehoon Kim, Coleman Hooper, Amir Gholami, Zhen Dong, Xiuyu Li, Sheng Shen, Michael W. Mahoney, Kurt Keutzer |
 |
Github Paper |
| Outlier Suppression+: Accurate quantization of large language models by equivalent and optimal shifting and scaling Xiuying Wei , Yunchen Zhang, Yuhang Li, Xiangguo Zhang, Ruihao Gong, Jinyang Guo, Xianglong Liu |
 |
Paper |
| Integer or Floating Point? New Outlooks for Low-Bit Quantization on Large Language Models Yijia Zhang, Lingran Zhao, Shijie Cao, Wenqiang Wang, Ting Cao, Fan Yang, Mao Yang, Shanghang Zhang, Ningyi Xu |
 |
Paper |
| LLM-QAT: Data-Free Quantization Aware Training for Large Language Models Zechun Liu, Barlas Oguz, Changsheng Zhao, Ernie Chang, Pierre Stock, Yashar Mehdad, Yangyang Shi, Raghuraman Krishnamoorthi, Vikas Chandra |
 |
Paper |
 SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression Tim Dettmers, Ruslan Svirschevski, Vage Egiazarian, Denis Kuznedelev, Elias Frantar, Saleh Ashkboos, Alexander Borzunov, Torsten Hoefler, Dan Alistarh |
 |
Github Paper |
 OWQ: Lessons learned from activation outliers for weight quantization in large language models Changhun Lee, Jungyu Jin, Taesu Kim, Hyungjun Kim, Eunhyeok Park |
 |
Github Paper |
 Do Emergent Abilities Exist in Quantized Large Language Models: An Empirical Study Peiyu Liu, Zikang Liu, Ze-Feng Gao, Dawei Gao, Wayne Xin Zhao, Yaliang Li, Bolin Ding, Ji-Rong Wen |
 |
Github Paper |
| ZeroQuant-FP: A Leap Forward in LLMs Post-Training W4A8 Quantization Using Floating-Point Formats Xiaoxia Wu, Zhewei Yao, Yuxiong He |
 |
Paper |
| FPTQ: Fine-grained Post-Training Quantization for Large Language Models Qingyuan Li, Yifan Zhang, Liang Li, Peng Yao, Bo Zhang, Xiangxiang Chu, Yerui Sun, Li Du, Yuchen Xie |
 |
Paper |
| QuantEase: Optimization-based Quantization for Language Models - An Efficient and Intuitive Algorithm Kayhan Behdin, Ayan Acharya, Aman Gupta, Qingquan Song, Siyu Zhu, Sathiya Keerthi, Rahul Mazumder |
 |
Github Paper |
| Norm Tweaking: High-performance Low-bit Quantization of Large Language Models Liang Li, Qingyuan Li, Bo Zhang, Xiangxiang Chu |
 |
Paper |
| Optimize Weight Rounding via Signed Gradient Descent for the Quantization of LLMs Wenhua Cheng, Weiwei Zhang, Haihao Shen, Yiyang Cai, Xin He, Kaokao Lv |
 |
Github Paper |
 QA-LoRA: Quantization-Aware Low-Rank Adaptation of Large Language Models Yuhui Xu, Lingxi Xie, Xiaotao Gu, Xin Chen, Heng Chang, Hengheng Zhang, Zhensu Chen, Xiaopeng Zhang, Qi Tian |
 |
Github Paper |
| ModuLoRA: Finetuning 3-Bit LLMs on Consumer GPUs by Integrating with Modular Quantizers Junjie Yin, Jiahao Dong, Yingheng Wang, Christopher De Sa, Volodymyr Kuleshov |
 |
Paper |
 PB-LLM: Partially Binarized Large Language Models Yuzhang Shang, Zhihang Yuan, Qiang Wu, Zhen Dong |
 |
Github Paper |
| Dual Grained Quantization: Efficient Fine-Grained Quantization for LLM Luoming Zhang, Wen Fei, Weijia Wu, Yefei He, Zhenyu Lou, Hong Zhou |
 |
Paper |
| QFT: Quantized Full-parameter Tuning of LLMs with Affordable Resources Zhikai Li, Xiaoxuan Liu, Banghua Zhu, Zhen Dong, Qingyi Gu, Kurt Keutzer |
 |
Paper |
| QLLM: Accurate and Efficient Low-Bitwidth Quantization for Large Language Models Jing Liu, Ruihao Gong, Xiuying Wei, Zhiwei Dong, Jianfei Cai, Bohan Zhuang |
 |
Paper |
| LoftQ: LoRA-Fine-Tuning-Aware Quantization for Large Language Models Yixiao Li, Yifan Yu, Chen Liang, Pengcheng He, Nikos Karampatziakis, Weizhu Chen, Tuo Zhao |
 |
Paper |
| TEQ: Trainable Equivalent Transformation for Quantization of LLMs Wenhua Cheng, Yiyang Cai, Kaokao Lv, Haihao Shen |
 |
Github Paper |
| BitNet: Scaling 1-bit Transformers for Large Language Models Hongyu Wang, Shuming Ma, Li Dong, Shaohan Huang, Huaijie Wang, Lingxiao Ma, Fan Yang, Ruiping Wang, Yi Wu, Furu Wei |
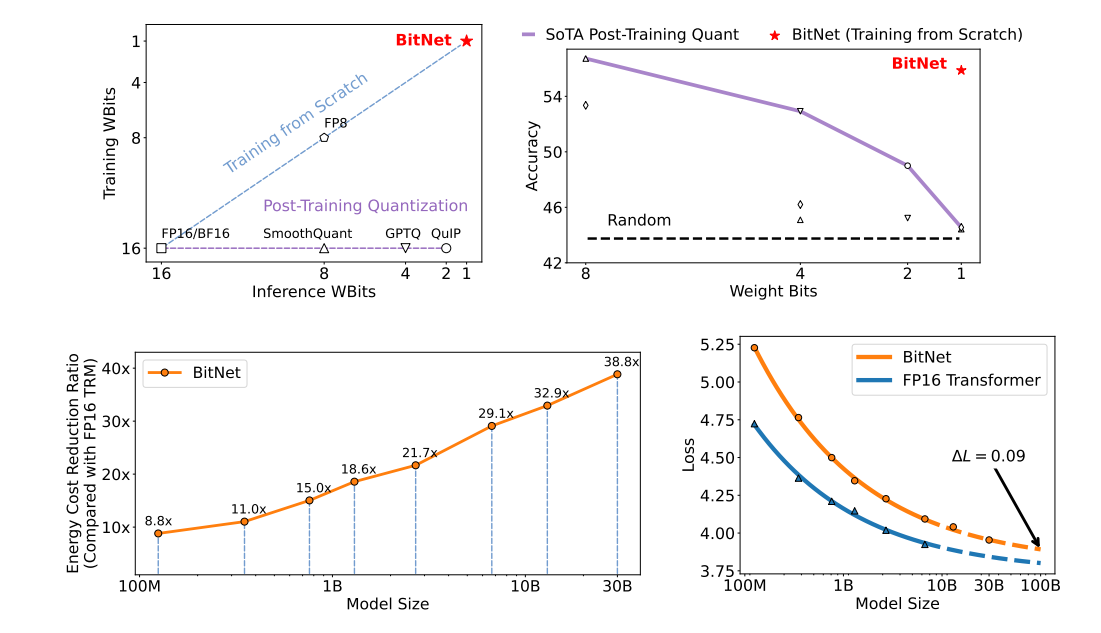 |
Paper |
| Atom: Low-bit Quantization for Efficient and Accurate LLM Serving Yilong Zhao, Chien-Yu Lin, Kan Zhu, Zihao Ye, Lequn Chen, Size Zheng, Luis Ceze, Arvind Krishnamurthy, Tianqi Chen, Baris Kasikci |
 |
Paper |
| AWEQ: Post-Training Quantization with Activation-Weight Equalization for Large Language Models Baisong Li, Xingwang Wang, Haixiao Xu |
 |
Paper |
 AFPQ: Asymmetric Floating Point Quantization for LLMs Yijia Zhang, Sicheng Zhang, Shijie Cao, Dayou Du, Jianyu Wei, Ting Cao, Ningyi Xu |
 |
Github Paper |
| A Speed Odyssey for Deployable Quantization of LLMs Qingyuan Li, Ran Meng, Yiduo Li, Bo Zhang, Liang Li, Yifan Lu, Xiangxiang Chu, Yerui Sun, Yuchen Xie |
 |
Paper |
 LQ-LoRA: Low-rank Plus Quantized Matrix Decomposition for Efficient Language Model Finetuning Han Guo, Philip Greengard, Eric P. Xing, Yoon Kim |
 |
Github Paper |
| Enabling Fast 2-bit LLM on GPUs: Memory Alignment, Sparse Outlier, and Asynchronous Dequantization Jinhao Li, Shiyao Li, Jiaming Xu, Shan Huang, Yaoxiu Lian, Jun Liu, Yu Wang, Guohao Dai |
 |
Paper |
 SmoothQuant+: Accurate and Efficient 4-bit Post-Training WeightQuantization for LLM Jiayi Pan, Chengcan Wang, Kaifu Zheng, Yangguang Li, Zhenyu Wang, Bin Feng |
 |
Github Paper |
| ZeroQuant(4+2): Redefining LLMs Quantization with a New FP6-Centric Strategy for Diverse Generative Tasks Xiaoxia Wu, Haojun Xia, Stephen Youn, Zhen Zheng, Shiyang Chen, Arash Bakhtiari, Michael Wyatt, Yuxiong He, Olatunji Ruwase, Leon Song, Zhewei Yao |
 |
Github Paper |
 Extreme Compression of Large Language Models via Additive Quantization Vage Egiazarian, Andrei Panferov, Denis Kuznedelev, Elias Frantar, Artem Babenko, Dan Alistarh |
 |
Github Paper |
| FP6-LLM: Efficiently Serving Large Language Models Through FP6-Centric Algorithm-System Co-Design Haojun Xia, Zhen Zheng, Xiaoxia Wu, Shiyang Chen, Zhewei Yao, Stephen Youn, Arash Bakhtiari, Michael Wyatt, Donglin Zhuang, Zhongzhu Zhou, Olatunji Ruwase, Yuxiong He, Shuaiwen Leon Song |
 |
Paper |
 KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W. Mahoney, Yakun Sophia Shao, Kurt Keutzer, Amir Gholami |
 |
Github Paper |
| L4Q: Parameter Efficient Quantization-Aware Training on Large Language Models via LoRA-wise LSQ Hyesung Jeon, Yulhwa Kim, Jae-joon Kim |
 |
Paper |
 QuIP#: Even Better LLM Quantization with Hadamard Incoherence and Lattice Codebooks Albert Tseng, Jerry Chee, Qingyao Sun, Volodymyr Kuleshov, Christopher De Sa |
 |
Github Paper |
 BiLLM: Pushing the Limit of Post-Training Quantization for LLMs Wei Huang, Yangdong Liu, Haotong Qin, Ying Li, Shiming Zhang, Xianglong Liu, Michele Magno, Xiaojuan Qi |
 |
Github Paper |
 Accurate LoRA-Finetuning Quantization of LLMs via Information Retention Haotong Qin, Xudong Ma, Xingyu Zheng, Xiaoyang Li, Yang Zhang, Shouda Liu, Jie Luo, Xianglong Liu, Michele Magno |
 |
Github Paper |
| ApiQ: Finetuning of 2-Bit Quantized Large Language Model Baohao Liao, Christof Monz |
 |
Paper |
| Towards Next-Level Post-Training Quantization of Hyper-Scale Transformers Junhan Kim, Kyungphil Park, Chungman Lee, Ho-young Kim, Joonyoung Kim, Yongkweon Jeon |
 |
Paper |
 EdgeQAT: Entropy and Distribution Guided Quantization-Aware Training for the Acceleration of Lightweight LLMs on the Edge Xuan Shen, Zhenglun Kong, Changdi Yang, Zhaoyang Han, Lei Lu, Peiyan Dong, Cheng Lyu, Chih-hsiang Li, Xuehang Guo, Zhihao Shu, Wei Niu, Miriam Leeser, Pu Zhao, Yanzhi Wang |
 |
Github Paper |
 BitDistiller: Unleashing the Potential of Sub-4-Bit LLMs via Self-Distillation Dayou Du, Yijia Zhang, Shijie Cao, Jiaqi Guo, Ting Cao, Xiaowen Chu, Ningyi Xu |
 |
Github Paper |
| WKVQuant: Quantizing Weight and Key/Value Cache for Large Language Models Gains More Yuxuan Yue, Zhihang Yuan, Haojie Duanmu, Sifan Zhou, Jianlong Wu, Liqiang Nie |
 |
Paper |
| DB-LLM: Accurate Dual-Binarization for Efficient LLMs Hong Chen, Chengtao Lv, Liang Ding, Haotong Qin, Xiabin Zhou, Yifu Ding, Xuebo Liu, Min Zhang, Jinyang Guo, Xianglong Liu, Dacheng Tao |
 |
Paper |
| OneBit: Towards Extremely Low-bit Large Language Models Yuzhuang Xu, Xu Han, Zonghan Yang, Shuo Wang, Qingfu Zhu, Zhiyuan Liu, Weidong Liu, Wanxiang Che |
 |
Paper |
 BitDelta: Your Fine-Tune May Only Be Worth One Bit James Liu, Guangxuan Xiao, Kai Li, Jason D. Lee, Song Han, Tri Dao, Tianle Cai |
 |
Github Paper |
| Any-Precision LLM: Low-Cost Deployment of Multiple, Different-Sized LLMs Yeonhong Park, Jake Hyun, SangLyul Cho, Bonggeun Sim, Jae W. Lee |
 |
Paper |
APTQ: Attention-aware Post-Training Mixed-Precision Quantization for Large Language Models Ziyi Guan, Hantao Huang, Yupeng Su, Hong Huang, Ngai Wong, Hao Yu |
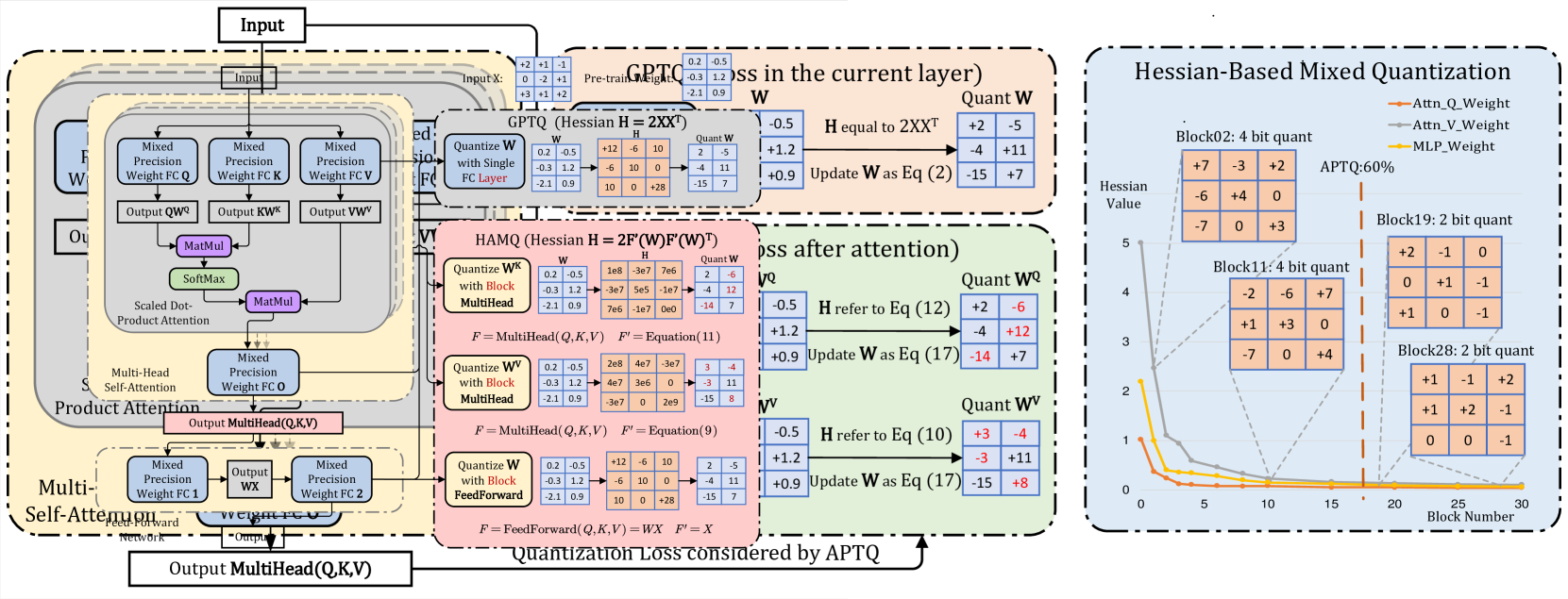 |
Paper |
 GPTVQ: The Blessing of Dimensionality for LLM Quantization Mart van Baalen, Andrey Kuzmin, Markus Nagel, Peter Couperus, Cedric Bastoul, Eric Mahurin, Tijmen Blankevoort, Paul Whatmough |
 |
Github Paper |
| A Comprehensive Evaluation of Quantization Strategies for Large Language Models Renren Jin, Jiangcun Du, Wuwei Huang, Wei Liu, Jian Luan, Bin Wang, Deyi Xiong |
 |
Paper |
| The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits Shuming Ma, Hongyu Wang, Lingxiao Ma, Lei Wang, Wenhui Wang, Shaohan Huang, Li Dong, Ruiping Wang, Jilong Xue, Furu Wei |
 |
Paper |
 Evaluating Quantized Large Language Models Shiyao Li, Xuefei Ning, Luning Wang, Tengxuan Liu, Xiangsheng Shi, Shengen Yan, Guohao Dai, Huazhong Yang, Yu Wang |
 |
Github Paper |
| No Token Left Behind: Reliable KV Cache Compression via Importance-Aware Mixed Precision Quantization June Yong Yang, Byeongwook Kim, Jeongin Bae, Beomseok Kwon, Gunho Park, Eunho Yang, Se Jung Kwon, Dongsoo Lee |
 |
Paper |
| FlattenQuant: Breaking Through the Inference Compute-bound for Large Language Models with Per-tensor Quantization Yi Zhang, Fei Yang, Shuang Peng, Fangyu Wang, Aimin Pan |
 |
Paper |
 QAQ: Quality Adaptive Quantization for LLM KV Cache Shichen Dong, Wen Cheng, Jiayu Qin, Wei Wang |
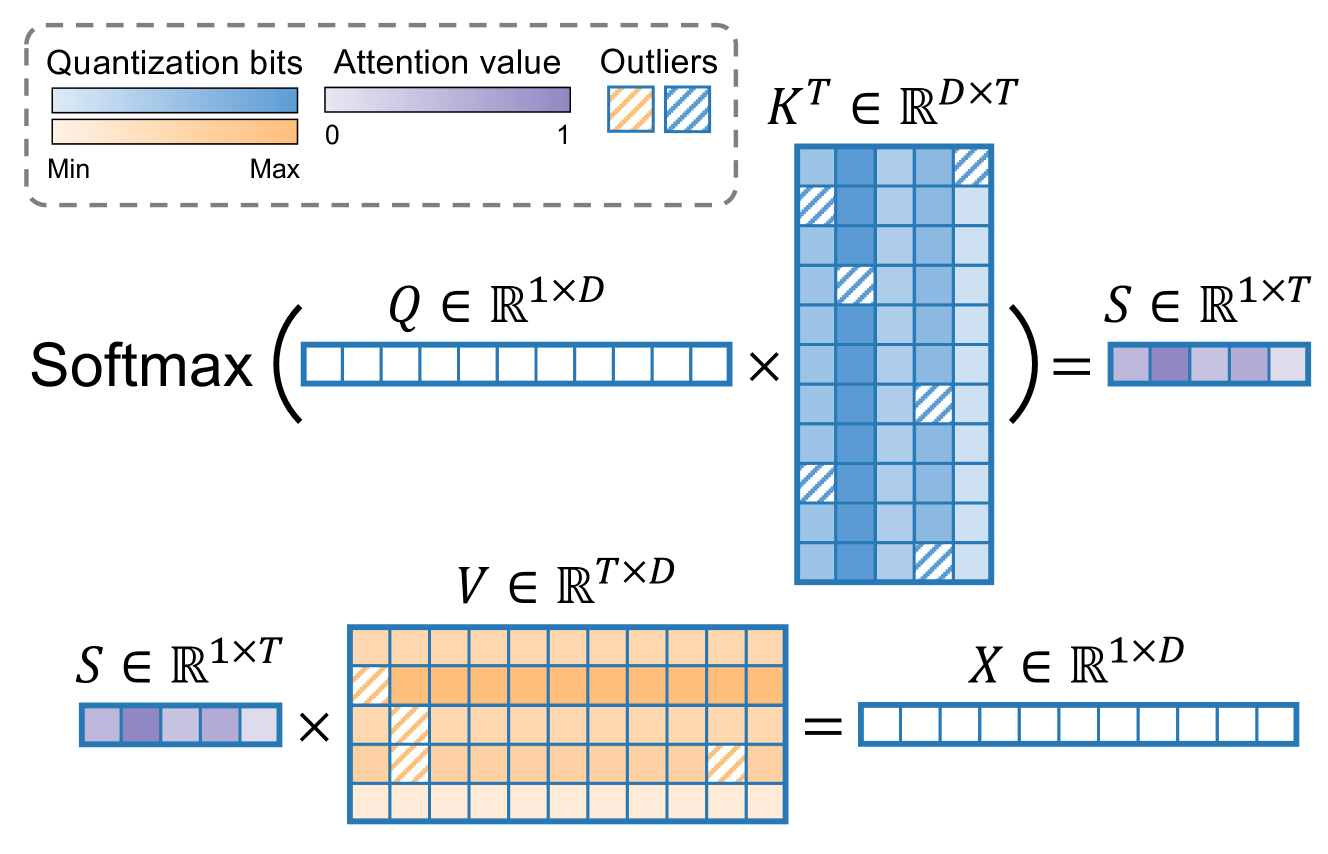 |
Github Paper |
| What Makes Quantization for Large Language Models Hard? An Empirical Study from the Lens of Perturbation Zhuocheng Gong, Jiahao Liu, Jingang Wang, Xunliang Cai, Dongyan Zhao, Rui Yan |
 |
Paper |
| FrameQuant: Flexible Low-Bit Quantization for Transformers Harshavardhan Adepu, Zhanpeng Zeng, Li Zhang, Vikas Singh |
 |
Paper |
 QuaRot: Outlier-Free 4-Bit Inference in Rotated LLMs Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L. Croci, Bo Li, Martin Jaggi, Dan Alistarh, Torsten Hoefler, James Hensman |
 |
Github Paper |
| Accurate Block Quantization in LLMs with Outliers Nikita Trukhanov, Ilya Soloveychik |
 |
Paper |
| Cherry on Top: Parameter Heterogeneity and Quantization in Large Language Models Wanyun Cui, Qianle Wang |
 |
Paper |
| Increased LLM Vulnerabilities from Fine-tuning and Quantization Divyanshu Kumar, Anurakt Kumar, Sahil Agarwal, Prashanth Harshangi |
 |
Paper |
| Quantization of Large Language Models with an Overdetermined Basis Daniil Merkulov, Daria Cherniuk, Alexander Rudikov, Ivan Oseledets, Ekaterina Muravleva, Aleksandr Mikhalev, Boris Kashin |
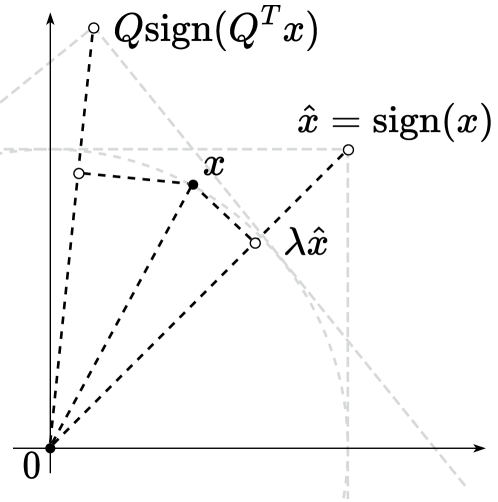 |
Paper |
 decoupleQ: Towards 2-bit Post-Training Uniform Quantization via decoupling Parameters into Integer and Floating Points Yi Guo, Fanliu Kong, Xiaoyang Li, Hui Li, Wei Chen, Xiaogang Tian, Jinping Cai, Yang Zhang, Shouda Liu |
 |
Github Paper |
| Lossless and Near-Lossless Compression for Foundation Models Moshik Hershcovitch, Leshem Choshen, Andrew Wood, Ilias Enmouri, Peter Chin, Swaminathan Sundararaman, Danny Harnik |
Paper | |
 How Good Are Low-bit Quantized LLaMA3 Models? An Empirical Study Wei Huang, Xudong Ma, Haotong Qin, Xingyu Zheng, Chengtao Lv, Hong Chen, Jie Luo, Xiaojuan Qi, Xianglong Liu, Michele Magno |
 |
Github Paper Model |































































































| Title & Authors | Introduction | Links |
|---|---|---|
 Rethinking Optimization and Architecture for Tiny Language Models Yehui Tang, Fangcheng Liu, Yunsheng Ni, Yuchuan Tian, Zheyuan Bai, Yi-Qi Hu, Sichao Liu, Shangling Jui, Kai Han, Yunhe Wang |
 |
Github Paper |
| Tandem Transformers for Inference Efficient LLMs Aishwarya P S, Pranav Ajit Nair, Yashas Samaga, Toby Boyd, Sanjiv Kumar, Prateek Jain, Praneeth Netrapalli |
 |
Paper |
| Scaling Efficient LLMs B.N. Kausik |
 |
Paper |
| MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases Zechun Liu, Changsheng Zhao, Forrest Iandola, Chen Lai, Yuandong Tian, Igor Fedorov, Yunyang Xiong, Ernie Chang, Yangyang Shi, Raghuraman Krishnamoorthi, Liangzhen Lai, Vikas Chandra |
 |
Paper |
| Think Big, Generate Quick: LLM-to-SLM for Fast Autoregressive Decoding Benjamin Bergner, Andrii Skliar, Amelie Royer, Tijmen Blankevoort, Yuki Asano, Babak Ehteshami Bejnordi |
 |
Paper |
 MobiLlama: Towards Accurate and Lightweight Fully Transparent GPT Omkar Thawakar, Ashmal Vayani, Salman Khan, Hisham Cholakal, Rao M. Anwer, Michael Felsberg, Tim Baldwin, Eric P. Xing, Fahad Shahbaz Khan |
 |
Github Paper Model |
| Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models Soham De, Samuel L. Smith, Anushan Fernando, Aleksandar Botev, George Cristian-Muraru, Albert Gu, Ruba Haroun, Leonard Berrada, Yutian Chen, Srivatsan Srinivasan, Guillaume Desjardins, Arnaud Doucet, David Budden, Yee Whye Teh, Razvan Pascanu, Nando De Freitas, Caglar Gulcehre |
 |
Paper |
 DiJiang: Efficient Large Language Models through Compact Kernelization Hanting Chen, Zhicheng Liu, Xutao Wang, Yuchuan Tian, Yunhe Wang |
 |
Github Paper |
 Megalodon: Efficient LLM Pretraining and Inference with Unlimited Context Length Xuezhe Ma, Xiaomeng Yang, Wenhan Xiong, Beidi Chen, Lili Yu, Hao Zhang, Jonathan May, Luke Zettlemoyer, Omer Levy, Chunting Zhou |
 |
Github Paper |


























FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, Christopher Ré. [Paper][Github]
Efficiently Scaling Transformer Inference. Reiner Pope, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury, Anselm Levskaya, Jonathan Heek, Kefan Xiao, Shivani Agrawal, Jeff Dean. [Paper]
FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU. Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Ryabinin, Daniel Y. Fu, Zhiqiang Xie, Beidi Chen, Clark Barrett, Joseph E. Gonzalez, Percy Liang, Christopher Ré, Ion Stoica, Ce Zhang. [Paper][Github]
Efficient Memory Management for Large Language Model Serving with PagedAttention. Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, Ion Stoica. [Paper][Github]
Efficient LLM Inference on CPUs. Haihao Shen, Hanwen Chang, Bo Dong, Yu Luo, Hengyu Meng. [Paper][Github]
- EdgeMoE: Fast On-Device Inference of MoE-based Large Language Models. Rongjie Yi, Liwei Guo, Shiyun Wei, Ao Zhou, Shangguang Wang, Mengwei Xu. [Paper]
GPT4AIGChip: Towards Next-Generation AI Accelerator Design Automation via Large Language Models. Yonggan Fu, Yongan Zhang, Zhongzhi Yu, Sixu Li, Zhifan Ye, Chaojian Li, Cheng Wan, Yingyan Lin. [Paper]
- Rethinking Memory and Communication Cost for Efficient Large Language Model Training. Chan Wu, Hanxiao Zhang, Lin Ju, Jinjing Huang, Youshao Xiao, Zhaoxin Huan, Siyuan Li, Fanzhuang Meng, Lei Liang, Xiaolu Zhang, Jun Zhou. [Paper]
- Chameleon: a Heterogeneous and Disaggregated Accelerator System for Retrieval-Augmented Language Models. Wenqi Jiang, Marco Zeller, Roger Waleffe, Torsten Hoefler, Gustavo Alonso. [Paper]
- FlashDecoding++: Faster Large Language Model Inference on GPUs. Ke Hong, Guohao Dai, Jiaming Xu, Qiuli Mao, Xiuhong Li, Jun Liu, Kangdi Chen, Hanyu Dong, Yu Wang. [Paper]
Striped Attention: Faster Ring Attention for Causal Transformers. William Brandon, Aniruddha Nrusimha, Kevin Qian, Zachary Ankner, Tian Jin, Zhiye Song, Jonathan Ragan-Kelley. [Paper][Github]
PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU. Yixin Song, Zeyu Mi, Haotong Xie, Haibo Chen. [Paper][Github]
- LLM in a flash: Efficient Large Language Model Inference with Limited Memory. Keivan Alizadeh, Iman Mirzadeh, Dmitry Belenko, Karen Khatamifard, Minsik Cho, Carlo C Del Mundo, Mohammad Rastegari, Mehrdad Farajtabar. [Paper]
- FlightLLM: Efficient Large Language Model Inference with a Complete Mapping Flow on FPGA. Shulin Zeng, Jun Liu, Guohao Dai, Xinhao Yang, Tianyu Fu, Hongyi Wang, Wenheng Ma, Hanbo Sun, Shiyao Li, Zixiao Huang, Yadong Dai, Jintao Li, Zehao Wang, Ruoyu Zhang, Kairui Wen, Xuefei Ning, Yu Wang. [Paper]
- Efficient LLM inference solution on Intel GPU. Hui Wu, Yi Gan, Feng Yuan, Jing Ma, Wei Zhu, Yutao Xu, Hong Zhu, Yuhua Zhu, Xiaoli Liu, Jinghui Gu. [Paper][Github]
Inferflow: an Efficient and Highly Configurable Inference Engine for Large Language Models. Shuming Shi, Enbo Zhao, Deng Cai, Leyang Cui, Xinting Huang, Huayang Li. [Paper][Github]
DeepSpeed-FastGen: High-throughput Text Generation for LLMs via MII and DeepSpeed-Inference. Connor Holmes, Masahiro Tanaka, Michael Wyatt, Ammar Ahmad Awan, Jeff Rasley, Samyam Rajbhandari, Reza Yazdani Aminabadi, Heyang Qin, Arash Bakhtiari, Lev Kurilenko, Yuxiong He. [Paper][Github]
QUICK: Quantization-aware Interleaving and Conflict-free Kernel for efficient LLM inference. Taesu Kim, Jongho Lee, Daehyun Ahn, Sarang Kim, Jiwoong Choi, Minkyu Kim, Hyungjun Kim. [Paper][Github]
FlexLLM: A System for Co-Serving Large Language Model Inference and Parameter-Efficient Finetuning. Xupeng Miao, Gabriele Oliaro, Xinhao Cheng, Mengdi Wu, Colin Unger, Zhihao Jia. [Paper][Github]
- BurstAttention: An Efficient Distributed Attention Framework for Extremely Long Sequences. Sun Ao, Weilin Zhao, Xu Han, Cheng Yang, Zhiyuan Liu, Chuan Shi, Maosong Sun, Shengnan Wang, Teng Su. [Paper]
Efficiently Programming Large Language Models using SGLang. Lianmin Zheng*, Liangsheng Yin, Zhiqiang Xie, Jeff Huang, Chuyue Sun, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, Ying Sheng*. [Paper] [Github]
- MELTing point: Mobile Evaluation of Language Transformers. MELTing point: Mobile Evaluation of Language Transformers. [Paper]
- DeFT: Flash Tree-attention with IO-Awareness for Efficient Tree-search-based LLM Inference. Jinwei Yao, Kaiqi Chen, Kexun Zhang, Jiaxuan You, Binhang Yuan, Zeke Wang, Tao Lin. [Paper]
- Transformer-Lite: High-efficiency Deployment of Large Language Models on Mobile Phone GPUs. Luchang Li, Sheng Qian, Jie Lu, Lunxi Yuan, Rui Wang, Qin Xie. [Paper]
- LoongServe: Efficiently Serving Long-context Large Language Models with Elastic Sequence Parallelism. Bingyang Wu, Shengyu Liu, Yinmin Zhong, Peng Sun, Xuanzhe Liu, Xin Jin. [Paper]
Mélange: Cost Efficient Large Language Model Serving by Exploiting GPU Heterogeneity. Tyler Griggs, Xiaoxuan Liu, Jiaxiang Yu, Doyoung Kim, Wei-Lin Chiang, Alvin Cheung, Ion Stoica. [Paper][Github]
- Expert Router: Orchestrating Efficient Language Model Inference through Prompt Classification. Josef Pichlmeier, Philipp Ross, Andre Luckow. [Paper]










- CPET: Effective Parameter-Efficient Tuning for Compressed Large Language Models. Weilin Zhao, Yuxiang Huang, Xu Han, Zhiyuan Liu, Zhengyan Zhang, Maosong Sun. [Paper]
ReMax: A Simple, Effective, and Efficient Method for Aligning Large Language Models. Ziniu Li, Tian Xu, Yushun Zhang, Yang Yu, Ruoyu Sun, Zhi-Quan Luo. [Paper][Github]
- TRANSOM: An Efficient Fault-Tolerant System for Training LLMs. Baodong Wu, Lei Xia, Qingping Li, Kangyu Li, Xu Chen, Yongqiang Guo, Tieyao Xiang, Yuheng Chen, Shigang Li. [Paper]
- DEFT: Data Efficient Fine-Tuning for Large Language Models via Unsupervised Core-Set Selection. Devleena Das, Vivek Khetan. [Paper]
LongQLoRA: Efficient and Effective Method to Extend Context Length of Large Language Models. Jianxin Yang. [Paper][Github]
Sparse Fine-tuning for Inference Acceleration of Large Language Models. Eldar Kurtic, Denis Kuznedelev, Elias Frantar, Michael Goin, Dan Alistarh. [Paper][Github][Github]
ComPEFT: Compression for Communicating Parameter Efficient Updates via Sparsification and Quantization. Prateek Yadav, Leshem Choshen, Colin Raffel, Mohit Bansal. [Paper][Github]
- Towards Better Parameter-Efficient Fine-Tuning for Large Language Models: A Position Paper. Chengyu Wang, Junbing Yan, Wei Zhang, Jun Huang. [Paper]
SPT: Fine-Tuning Transformer-based Language Models Efficiently with Sparsification. Yuntao Gui, Xiao Yan, Peiqi Yin, Han Yang, James Cheng. [Paper][Github]
LoRA+: Efficient Low Rank Adaptation of Large Models. Soufiane Hayou, Nikhil Ghosh, Bin Yu. [Paper][Github]
- Sparse MeZO: Less Parameters for Better Performance in Zeroth-Order LLM Fine-Tuning. Yong Liu, Zirui Zhu, Chaoyu Gong, Minhao Cheng, Cho-Jui Hsieh, Yang You. [Paper]
DropBP: Accelerating Fine-Tuning of Large Language Models by Dropping Backward Propagation. Sunghyeon Woo, Baeseong Park, Byeongwook Kim, Minjung Jo, Sejung Kwon, Dongsuk Jeon, Dongsoo Lee. [Paper][Github]
- LoRA-SP: Streamlined Partial Parameter Adaptation for Resource-Efficient Fine-Tuning of Large Language Models. Yichao Wu, Yafei Xiang, Shuning Huo, Yulu Gong, Penghao Liang. [Paper]
- Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey. Zeyu Han, Chao Gao, Jinyang Liu, Jeff (Jun)Zhang, Sai Qian Zhang. [Paper]
AILS-NTUA at SemEval-2024 Task 6: Efficient model tuning for hallucination detection and analysis. Natalia Griogoriadou, Maria Lymperaiou, Giorgos Filandrianos, Giorgos Stamou. [Paper][Github]
BAdam: A Memory Efficient Full Parameter Training Method for Large Language Models. Qijun Luo, Hengxu Yu, Xiao Li. [Paper][Github]
- Intuition-aware Mixture-of-Rank-1-Experts for Parameter Efficient Finetuning. Yijiang Liu, Rongyu Zhang, Huanrui Yang, Kurt Keutzer, Yuan Du, Li Du, Shanghang Zhang. [Paper]









- A Survey on Model Compression for Large Language Models. Xunyu Zhu, Jian Li, Yong Liu, Can Ma, Weiping Wang. [Paper]
The Efficiency Spectrum of Large Language Models: An Algorithmic Survey. Tianyu Ding, Tianyi Chen, Haidong Zhu, Jiachen Jiang, Yiqi Zhong, Jinxin Zhou, Guangzhi Wang, Zhihui Zhu, Ilya Zharkov, Luming Liang. [Paper][Github]
Efficient Large Language Models: A Survey. Zhongwei Wan, Xin Wang, Che Liu, Samiul Alam, Yu Zheng, Zhongnan Qu, Shen Yan, Yi Zhu, Quanlu Zhang, Mosharaf Chowdhury, Mi Zhang. [Paper][Github]
- Towards Efficient Generative Large Language Model Serving: A Survey from Algorithms to Systems. Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Hongyi Jin, Tianqi Chen, Zhihao Jia. [Paper]
Beyond Efficiency: A Systematic Survey of Resource-Efficient Large Language Models. Guangji Bai, Zheng Chai, Chen Ling, Shiyu Wang, Jiaying Lu, Nan Zhang, Tingwei Shi, Ziyang Yu, Mengdan Zhu, Yifei Zhang, Carl Yang, Yue Cheng, Liang Zhao. [Paper][Github]
A Survey of Resource-efficient LLM and Multimodal Foundation Models. Mengwei Xu, Wangsong Yin, Dongqi Cai, Rongjie Yi, Daliang Xu, Qipeng Wang, Bingyang Wu, Yihao Zhao, Chen Yang, Shihe Wang, Qiyang Zhang, Zhenyan Lu, Li Zhang, Shangguang Wang, Yuanchun Li, Yunxin Liu, Xin Jin, Xuanzhe Liu. [Paper][Github]
- A Survey on Hardware Accelerators for Large Language Models. Christoforos Kachris. [Paper]
Personal LLM Agents: Insights and Survey about the Capability, Efficiency and Security. Yuanchun Li, Hao Wen, Weijun Wang, Xiangyu Li, Yizhen Yuan, Guohong Liu, Jiacheng Liu, Wenxing Xu, Xiang Wang, Yi Sun, Rui Kong, Yile Wang, Hanfei Geng, Jian Luan, Xuefeng Jin, Zilong Ye, Guanjing Xiong, Fan Zhang, Xiang Li, Mengwei Xu, Zhijun Li, Peng Li, Yang Liu, Ya-Qin Zhang, Yunxin Liu. [Paper][Github]
- A Comprehensive Survey of Compression Algorithms for Language Models. Seungcheol Park, Jaehyeon Choi, Sojin Lee, U Kang. [Paper]
- A Survey on Transformer Compression. Yehui Tang, Yunhe Wang, Jianyuan Guo, Zhijun Tu, Kai Han, Hailin Hu, Dacheng Tao. [Paper]
- Model Compression and Efficient Inference for Large Language Models: A Survey. Wenxiao Wang, Wei Chen, Yicong Luo, Yongliu Long, Zhengkai Lin, Liye Zhang, Binbin Lin, Deng Cai, Xiaofei He. [Paper]
A Survey on Knowledge Distillation of Large Language Models. Xiaohan Xu, Ming Li, Chongyang Tao, Tao Shen, Reynold Cheng, Jinyang Li, Can Xu, Dacheng Tao, Tianyi Zhou. [Paper][Github]
Unlocking Efficiency in Large Language Model Inference: A Comprehensive Survey of Speculative Decoding. Heming Xia, Zhe Yang, Qingxiu Dong, Peiyi Wang, Yongqi Li, Tao Ge, Tianyu Liu, Wenjie Li, Zhifang Sui. [Paper][Github][Blog]
Faster and Lighter LLMs: A Survey on Current Challenges and Way Forward. Arnav Chavan, Raghav Magazine, Shubham Kushwaha, Mérouane Debbah, Deepak Gupta. [Paper][Github]
- Efficient Prompting Methods for Large Language Models: A Survey. Kaiyan Chang, Songcheng Xu, Chenglong Wang, Yingfeng Luo, Tong Xiao, Jingbo Zhu. [Paper]
- A Survey on Efficient Inference for Large Language Models. Zixuan Zhou, Xuefei Ning, Ke Hong, Tianyu Fu, Jiaming Xu, Shiyao Li, Yuming Lou, Luning Wang, Zhihang Yuan, Xiuhong Li, Shengen Yan, Guohao Dai, Xiao-Ping Zhang, Yuhan Dong, Yu Wang. [Paper]








| Platform | Access |
|---|---|
| Huggingface LLM Perf Leaderboard | [Source] |
| LLM Safety Leaderboard (for compressed models)} | [Source] |
| LLMPerf Leaderboard | [Source] |
| LLM API Hosts Leaderboard | [Source] |
| ML.ENERGY Leaderboard | [Source] |
| Models Leaderboard | [Source] |
| Provider Leaderboard | [Source] |