[fx/profiler] tuned the calculation of memory estimation #1619
Conversation
| # https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cudnn/BatchNorm.cpp | ||
| @register_meta(aten.cudnn_batch_norm.default) | ||
| def meta_cudnn_bn(input: torch.Tensor, weight, bias, running_mean, running_var, training, momentum, eps): | ||
| n_input = input.size(1) | ||
|
|
||
| output = torch.empty_like(input) | ||
| running_mean = torch.empty((n_input), device='meta') | ||
| running_var = torch.empty((n_input), device='meta') | ||
| reserve = torch.empty((0), dtype=torch.uint8, device='meta') | ||
| return output, running_mean, running_var, reserve | ||
|
|
||
|
|
||
| # https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cudnn/BatchNorm.cpp | ||
| # NB: CuDNN only implements the backward algorithm for batchnorm | ||
| # in training mode (evaluation mode batchnorm has a different algorithm), | ||
| # which is why this doesn't accept a 'training' parameter. | ||
| @register_meta(aten.cudnn_batch_norm_backward.default) | ||
| def meta_cudnn_bn_backward(dY: torch.Tensor, input: torch.Tensor, weight: torch.Tensor, running_mean, running_var, | ||
| save_mean, save_invstd, eps, reserve): | ||
| dX = torch.empty_like(input) | ||
| dgamma = torch.empty_like(weight) | ||
| dbeta = torch.empty_like(weight) | ||
| return dX, dgamma, dbeta | ||
|
|
||
|
|
||
| @register_meta(aten.native_layer_norm.default) | ||
| def meta_ln(input: torch.Tensor, normalized_shape, weight, bias, eps): | ||
| bs = input.size(0) | ||
| n_input = input.size(1) | ||
|
|
||
| output = torch.empty_like(input) | ||
| running_mean = torch.empty((bs, n_input, 1), device='meta') | ||
| running_var = torch.empty((bs, n_input, 1), device='meta') | ||
| return output, running_mean, running_var |
There was a problem hiding this comment.
A sad truth is autograd on cuda use cudnn_batch_norm
| def meta_native_dropout_default(input: torch.Tensor, p: float, train: bool = False): | ||
| # notice that mask is bool | ||
| output = torch.empty_like(input) | ||
| mask = torch.empty_like(input, dtype=torch.bool) | ||
| return output, mask | ||
|
|
||
|
|
||
| # https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/Dropout.cpp | ||
| @register_meta(aten.native_dropout_backward.default) | ||
| def meta_native_dropout_backward_default(grad: torch.Tensor, mask: torch.Tensor, scale: float): | ||
| return torch.empty_like(grad) |
There was a problem hiding this comment.
Another sad truth is autograd on cuda use native_dropout
| xbar += n.meta['fwd_mem_tmp'] | ||
| if any(map(lambda x: x.meta['save_fwd_in'], n.users)): | ||
| xbar += n.meta['fwd_mem_out'] |
There was a problem hiding this comment.
Not every node has fwd_mem_out.
| @@ -224,7 +222,7 @@ def output(self, target: 'Target', args: Tuple[Argument, ...], kwargs: Dict[str, | |||
| result (Any): The argument value that was retrieved | |||
| meta_info (MetaInfo): The memory cost and FLOPs estimated with `MetaTensor`. | |||
| """ | |||
| return args[0], GraphInfo(fwd_mem_in=activation_size(args[0])) | |||
| return args[0], GraphInfo(save_fwd_in=True) | |||
There was a problem hiding this comment.
output node saves the last fwd_mem_out for sure
| elif is_phase(n, Phase.BACKWARD): | ||
| if len(n.users): | ||
| graph_info.bwd_mem_tmp = max(graph_info.bwd_mem_tmp, _peak_memory(deps)) | ||
| else: | ||
| # TODO: some of the bwd_mem_out might be model parameters. | ||
| # basically a backward node without user is a `grad_out` node | ||
| graph_info.bwd_mem_out += activation_size(n.meta['out']) | ||
| graph_info.bwd_mem_out += activation_size(n.meta['saved_tensor']) | ||
| for input_n in n.all_input_nodes: | ||
| if input_n in deps: | ||
| deps[input_n] -= 1 |
There was a problem hiding this comment.
these analysis are still naive, so sad
| if META_COMPATIBILITY: | ||
| aten = torch.ops.aten | ||
|
|
||
| WEIRD_OPS = [ | ||
| torch.where, | ||
| ] | ||
|
|
||
| INPLACE_ATEN = [ | ||
| aten.add_.Tensor, | ||
| aten.sub_.Tensor, | ||
| aten.div_.Tensor, | ||
| aten.div_.Scalar, | ||
| aten.mul_.Tensor, | ||
| aten.bernoulli_.float, | ||
|
|
||
| # inplace reshaping | ||
| aten.copy_.default, | ||
| aten.detach.default, | ||
| aten.t.default, | ||
| aten.transpose.int, | ||
| aten.view.default, | ||
| aten._unsafe_view.default, | ||
| ] | ||
|
|
||
| NORMALIZATION_ATEN = [ | ||
| aten.native_batch_norm.default, | ||
| aten.native_layer_norm.default, | ||
| # aten.max_pool2d_with_indices.default, | ||
| ] | ||
|
|
||
| CLONE_ATEN = [ | ||
| aten.clone.default, | ||
| ] | ||
|
|
||
| __all__ += ['INPLACE_ATEN', 'WEIRD_OPS', 'NORMALIZATION_ATEN', 'CLONE_ATEN'] | ||
|
|
||
| else: | ||
| # TODO fill out the inplace ops | ||
| INPLACE_OPS = [ | ||
| add, | ||
| sub, | ||
| mul, | ||
| floordiv, | ||
| neg, | ||
| pos, | ||
| getitem, | ||
| setitem, | ||
| getattr, | ||
| torch.Tensor.cpu, | ||
| ] | ||
|
|
||
| # TODO: list all call_methods that are inplace here | ||
| INPLACE_METHOD = [ | ||
| 'transpose', | ||
| 'permute', | ||
| # TODO: reshape may return a copy of the data if the data is not contiguous | ||
| 'reshape', | ||
| 'dim', | ||
| 'flatten', | ||
| 'size', | ||
| 'view', | ||
| 'unsqueeze', | ||
| 'to', | ||
| 'type', | ||
| 'flatten', | ||
| ] | ||
|
|
||
| # TODO: list all call_methods that are not inplace here | ||
| NON_INPLACE_METHOD = [ | ||
| 'chunk', | ||
| 'contiguous', | ||
| 'expand', | ||
| 'mean', | ||
| 'split', | ||
| ] | ||
| __all__ += ['INPLACE_OPS', 'INPLACE_METHOD', 'NON_INPLACE_METHOD'] |
There was a problem hiding this comment.
move them to constant.py
| @@ -201,6 +202,8 @@ def zero_flop_jit(*args): | |||
| # normalization | |||
| aten.native_batch_norm.default: batchnorm_flop_jit, | |||
| aten.native_batch_norm_backward.default: batchnorm_flop_jit, | |||
| aten.cudnn_batch_norm.default: batchnorm_flop_jit, | |||
| aten.cudnn_batch_norm_backward.default: partial(batchnorm_flop_jit, training=True), | |||
There was a problem hiding this comment.
notice that cudnn_batch_norm_backward is different because it is only used when training=True
| # super-dainiu: | ||
| # x.detach() will change the unique identifier of data_ptr | ||
| # we need to handle this in a stupid way |
There was a problem hiding this comment.
x.detach() will change the unique identifier of data_ptr. we need to handle this in a stupid way
| from .tensor import MetaTensor | ||
| from .opcount import flop_mapping | ||
|
|
||
| __all__ = ['profile_function', 'profile_module', 'profile_method'] | ||
|
|
||
| # super-dainiu: this cache should be global, otherwise it cannot | ||
| # track duplicated tensors between nodes | ||
| cache = set() |
There was a problem hiding this comment.
this cache should be global, otherwise it cannot track duplicated tensors between nodes
| # still run the profiling but discard some results regarding `module`. | ||
| inplace = getattr(module, 'inplace', False) | ||
| if inplace: | ||
| module.inplace = False |
There was a problem hiding this comment.
no longer skip profiling for inplace=True
|
|

What's modified?
To do
MetaInfoPropon arbitrary physical devices, we need to wrap atorch.TensorwithMetaTensor, which has a property offake_device.fake_deviceis used by__torch_dispatch__to find antorch.ops.atenfor execution, while in real execution, the tensor is moved back todevice='meta'. So now you should doMetaInfoPropon atm.resnet18on CPU with the following script.And on GPU with the following script.
Now you might observe some different patterns in estimated memory, because
torch.autogradbehaves differently on different devices.Improvements
The computation graph is completely different when executing on 'cpu' and 'cuda'.
Tensor
dtypemay change during execution.Not every tensor that passes through
torch.autograd.graph.saved_tensors_hooksis saved to device.tensor.data_ptr()marks its physical address. No duplicatedtensor.data_ptr()should be saved.tensor.data_ptr()=0ondevice='meta'tensorwith the unique identifier oftensor.data_ptras atorch._C function.See the graph below for illustrations.
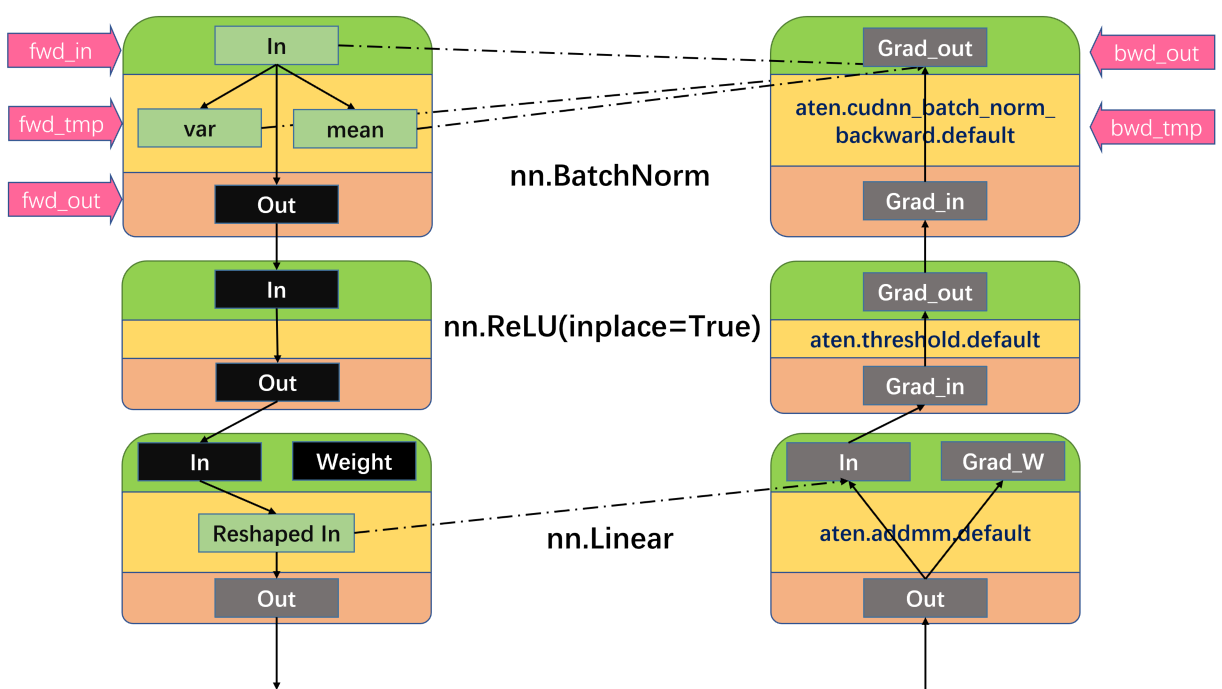
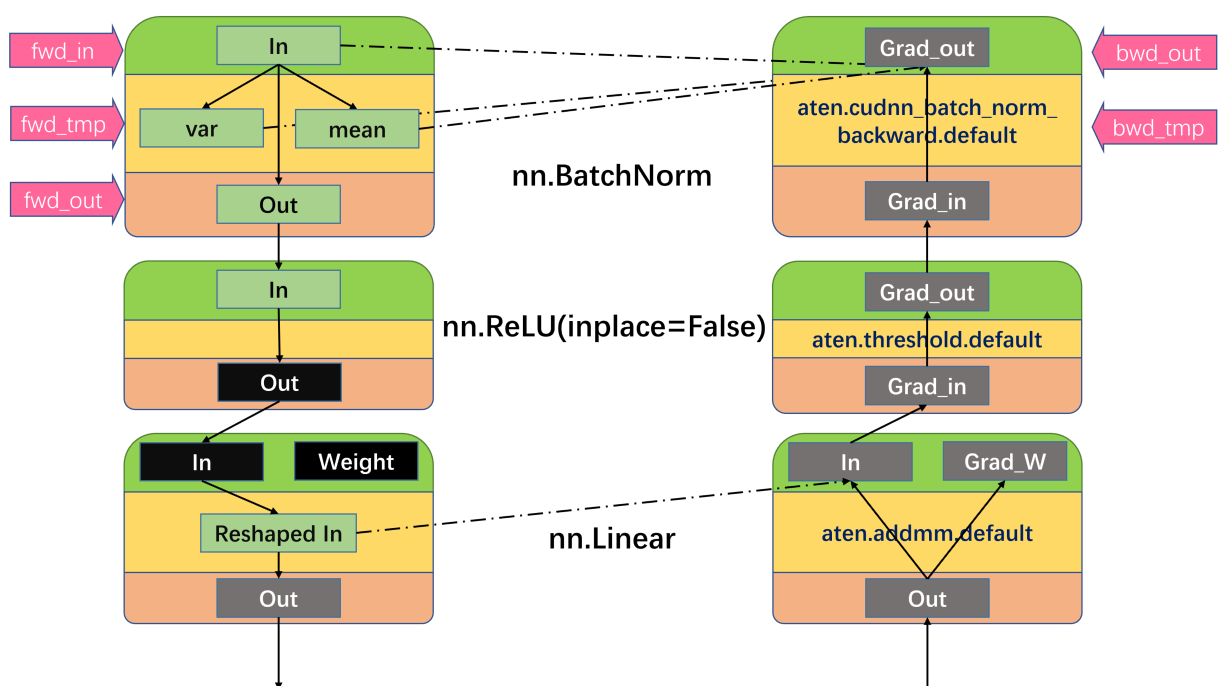
fwd_incan this node havefwd_out.nn.MultiheadAttentionhas(x, x, x)as input, but only onexshould be saved for backward.Concerns
Backward memory is indeed too hard to estimate.