Download Spark-multiple-job-Examples
Download simplevoronoi and place simplevoronoi-version-SNAPSHOT.jar in Spark-multiple-job-Examples/lib directory
cd Spark-multiple-job-Examples and run
sbt
> package
After successful complete in directory target/scala-2.10/spark_multiple_job_examples_2.10-SNAPSHOT-0.1.jar should be created now we will run classes from this jar as spark jobs
twitter4j-core
Twitter4j Stream
spark-streaming
spark-streaming-twitter
simplevoronoi
Download listed libraries some where on disc
and add these in SPARK_CLASSPATH in your user .bashrc file or spark-env.sh file
in this tutorial we export these in spark-env.sh so add these lines in you SparkHome/conf/spark-env.sh
export SPARK_CLASSPATH=PathToFile/twitter4j-core-3.0.3.jar:$SPARK_CLASSPATH
export SPARK_CLASSPATH=PathToFile/twitter4j-stream-3.0.3.jar:$SPARK_CLASSPATH
export SPARK_CLASSPATH=PathToFile/spark-streaming-twitter_2.10-1.4.1.jar:$SPARK_CLASSPATH
export SPARK_CLASSPATH=PathToFile/simplevoronoi-0.2-SNAPSHOT.jar:$SPARK_CLASSPATH
1.1: we need twitter API credentials if you dont have create frist here
1.2: create a file with Twitter API credentiale like name twitter-credentials.txt
1.3: enter credential
TWITTER_API_KEY=ApiKey
TWITTER_API_SECRET=ApiSecret
TWITTER_ACCESS_TOKEN=AccessToken
TWITTER_ACCESS_TOKEN_SECRET=AccessTokenSecret
1.4: run sbt job to write live stream from twitter in a csv file
sbt "run-main xulu.FetchTweets twitter-credentials.txt tweets.csv"
This job write tweets in fomate "Longitude,Latitude,Text "
to change modifie FetchTweets.scala and run again
shell output
-56.544541,-29.089541,Por que ni estamos jugando,
-69.922686,18.462675,Aprenda hablar amigo
-118.565107,34.280215,today a boy told me I'm pretty
121.039399,14.72272,@Kringgelss labuyoo. Hahaha
-34.875339,-7.158832@keithmeneses_ oi td bem? sdds 😔💚
103.766123,1.380696,Xian Lim on iShine 3 2
......
When you have enough tweets, stop the program by pressing CTRL + C
2.1:
Edit file Spark-multiple-job-Examples/src/mian/scala/xulu/TwitterLiveStreaming.scala
find the line ssc.checkpoint("hdfs://HDFS_IP:9000/checkpoint") at end of file.
replace HDFS_IP with Hadoop master IP and rebuild jar file
cd Spark-multiple-job-Examples and run
sbt
> package
cd to spark home
bin/spark-submit --class xulu.TwitterLiveStreaming --master spark://sparkMasterIP:7077 PathTo/spark_multiple_job_examples_2.10-SNAPSHOT-0.1.jar (Optional kyeWords separated by space)
This example should only print tweet text from Twitter live stream on shell
you are able to do write it any where or change the query
modifie TwitterLiveStreaming.scala and rebluild you jar and run again
In this example, we will be using the k-means clustering algorithm implemented in Spark Machine Learning Library(MLLib) to segment the dataset by geolocation.
3.1: we need twitter data to perform this example.
in example one we show how you write Twitter data in a file so run example one to fetch some data from Twitter.
For your convenience, we provide the file tweets_drink.csv
3.2: upload Twitter data tweets_drink.csv in to Hadoop
3.3: run the job
bin/spark-submit --class xulu.KMeansApp --master spark://SparkMasterIP:7077 PathTo/spark_multiple_job_examples_2.10-SNAPSHOT-0.1.jar hdfs://HDFS_IP:9000/UploadedLocation/tweets_drink.csv results/KmeanApp.png

4.1: Downlaod Twitter data about Drink
You can run the Example one With Keywords about Drink to get the tweets having a word related to a drink:
sbt "run-main xulu.FetchTweets twitter-credentials.txt tweets_drink.csv \ redbull schweppes coke cola pepsi fanta orangina soda \ coffee cafe expresso latte tea \ alcohol booze alcoholic whiskey tequila vodka booze cognac baccardi \ drink beer rhum liquor gin ouzo brandy mescal alcoholic wine drink"
When you have enough tweets, stop the program by pressing CTRL + C
Unfortunately only a fraction of all the tweets have geolocation information(the publisher has to tweet from a phone and has to opt in to send its position). So you might need to wait several hours (even days if the words are not popular) to get enough tweets to draw on a map. For your convenience, we provide the file tweets_drink.csv which already contains the tweets that we collected using those keywords.
The tweet file contains on each line, the tweet longitude ,latitude, and message:
4.2: upload Twitter data tweets_drink.csv in to Hadoop
4.3: run the job
bin/spark-submit --class xulu.HeatMap --master spark://SparkMasterIP:7077 PathTo/spark_multiple_job_examples_2.10-SNAPSHOT-0.1.jar hdfs://HDFS_IP:9000/UploadedLocation/tweets_drink.csv results/heatmapApp.png 0.5 coke pepsi
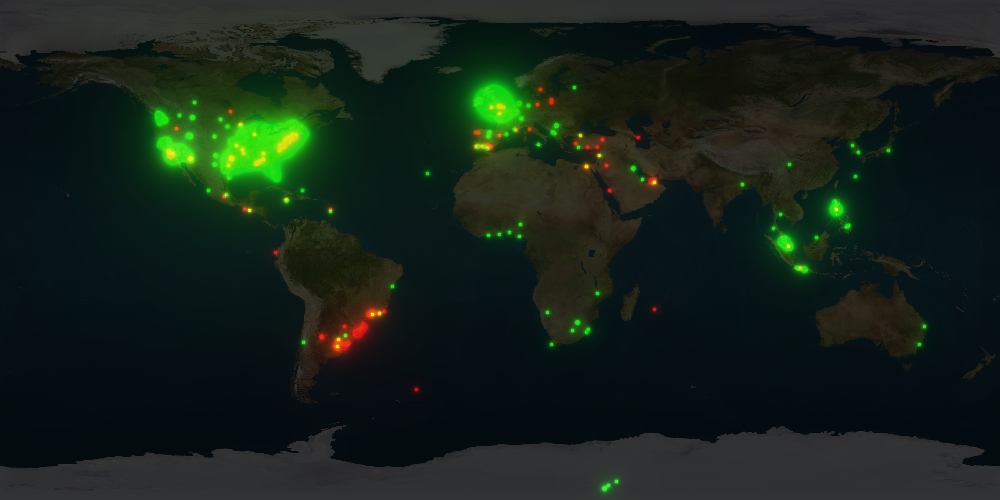
On this map, we can clearly see that the word 'coke'(in green) is used much more than the word 'pepsi'(in red) in the tweets. There are some places which are yellow, that means that there are tweets on coke and tweets on pepsi (yellow = red + green). Interestingly enough, we can see that coke is not used much in South America unlike pepsi which is used in Brazil and in Argentina.
https://chimpler.wordpress.com/2014/07/11/segmenting-audience-with-kmeans-and-voronoi-diagram-using-spark-and-mllib/https://chimpler.wordpress.com/2014/06/26/analyzing-your-audience-location-with-twitter-streams-and-heat-maps/