SQLEP 1.1.x Basic Tutorial
###The tutorial is updated for SQLP 2 and SQLEP 1.3
##Introduction
The SQL Processor Eclipse plugin (SQLEP) enables smart edition of the SQL Processor (SQLP) artifacts (the META SQL statements and so on). It works in a very simple fashion. After the installation every file with the extension qry is associated with this smart editor. The basic picture of this editor activated in STS is the next one:

It is based on the Xtext and offers all its advanced features, like syntax colloring, code completion, outline, validation and so on.
The Xtext based grammar is more advanced compared to the ANTLR based grammar used in the runtime. To prevent the runtime errors due to this restriction, the rule of thumb is to put all advanced artifacts into a separate file. For example, you can use the next two files
-
statements.qrycontains the standard SQLP artifacts (runtime artifacts), as they are described in Meta SQL Statements. This file is used in the runtime, as it's described in Simple Tutorial for example. -
definitions.qrycontains only artifacts (control artifacts), which are used by the SQLEP itself. In fact they are control directives, which help the Eclipse plugin to model the relationships between the runtime artifacts.
##Installation The simplest way to install the SQL Processor plugin is to copy the following jars into dropins directory:
- http://sql-processor.eu/plugins/org.sqlproc.dsl-1.3.0.jar
- http://sql-processor.eu/plugins/org.sqlproc.dsl.ui-1.3.0.jar
The dropins directory is located in the STS/Eclipse main directory. For example is can be ~/springsource/sts-3.0.0.RELEASE/dropins/ for STS. After that, it's necessary to restart the IDE. (Also the modelling plugins like Xtext should be installed, please see IDE Setup and Coding Standards).
##POJOs The POJO beans (input forms or result classes) used in the runtime artifacts can be processed in a couple of ways:
- the dynamic input values validation
- the dynamic input values content assist
- the static input values validation
- the static input values content assist
- the implicit output values validation
- the implicit output values content assist
- the explicit output values validation
- the explicit output values content assist
To enable these features, the following directive should be declared
resolve-pojo-on;
Next, all input forms and result classes should be defined. For example, let's take the sample used in the Wiki tutorials (https://github.com/hudec/sql-processor/tree/master/sql-samples/simple-jdbc). The following snippet lists all POJO beans used in this sample:
pojo person org.sqlproc.sample.simple.model.Person;
pojo contact org.sqlproc.sample.simple.model.Contact;
pojo media org.sqlproc.sample.simple.model.Media;
...
These definitions contain 3 columns
-
pojois a keyword - the symbolic name of the POJO used in the next definitions
- the full Java class name of the POJO. All the classes should be on the classpath of any project opened in the Eclipse/STS IDE.
Important - the next is no more true. For the new way please see SQLP 2.0 and SQLEP 1.3 Tutorial.
Now, to enable the dynamic input values (=identifiers) processing, they should be defined, like in the following snippet:
_ident ALL_PEOPLE person;_
_ident LIKE_PEOPLE person;_
_ident INSERT_PERSON person;_
_..._
These definitions contain 3 columns
* ident is a keyword
* the name of the META SQL statement (the runtime artifact)
* the symbolic name of the POJO (previously defined)
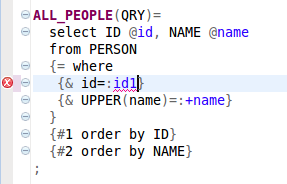
As a result, the validation of all dynamic input values in the META SQL statements (ALL_PEOPLE, LIKE_PEOPLE and INSERT_PERSON) is activated. It can be seen in the following picture, where the dynamic input value id1 is not an attribute in the POJO org.sqlproc.sample.simple.model.Person:
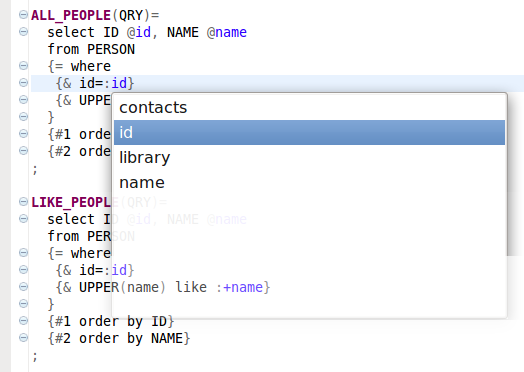
Similarly the content assist is activated. When you press a Ctrl-Space after a : control character, a list of all attributes in the POJO org.sqlproc.sample.simple.model.Person is offered:
Important - the next is no more true. For the new way please see SQLP 2.0 and SQLEP 1.3 Tutorial.
_To enable the static input values (=constants) processing, the keyword const instead of ident should be used. To enable the explicit output values (=output mapping rules) processing, the keyword out instead of ident should be used. Similarly to enable the output values (=columns) processing, the keyword col instead of ident should be used, like in the following snippet: _
_col ALL_PEOPLE person;_
_col LIKE_PEOPLE person;_
_col GET_PERSON person;_
_..._
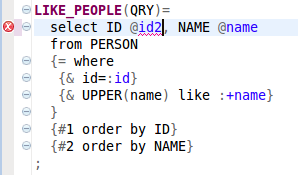
The following picture presents the output value validation in progress - the id2 isn't an attribute in the POJO org.sqlproc.sample.simple.model.Person:
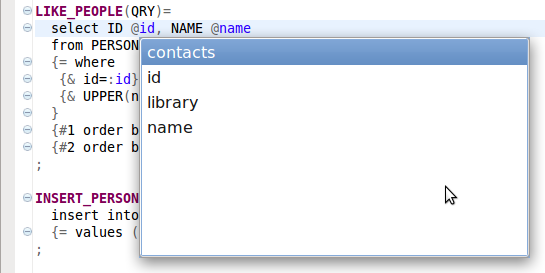
The next picture presents the content assist in action. When you press a Ctrl-Space after a @ control character, a list of all attributes in the POJO org.sqlproc.sample.simple.model.Person is offered.
In fact, everywhere, where the POJO attribute is used, the content assist can help to quickly pick up the correct one. Also the validation helps to identify all incorrect usage of them. This can speed up the process of the SQL Processor artifacts definition significantly. Also it prevents the exceptions in the runtime due to incorrect POJO objects usage.
##Database objects The database columns and tables used in the runtime artifacts can be processed in a couple of ways:
- the database tables validation
- the database tables content assist
- the database columns validation
- the database columns content assist
To enable these features, the following directive should be declared
database-is-online;
Moreover, the connection to the database should be established, like in the following snippet:
database-jdbc-driver oracle.jdbc.OracleDriver;
database-has-url jdbc:oracle:thin:@127.0.0.1:1521:xe;
database-login-username sqlsample;
database-login-password sqlsample;
database-active-schema SQLSAMPLE;
The database-... are keywords. Of course, the declared JDBC driver has to be on the classpath. Next, all used tables should be defined. For example, let's take the sample used in the Wiki tutorials (https://github.com/hudec/sql-processor/tree/master/sql-samples/simple-jdbc).
The following snippet lists all database tables used in this sample:
table person PERSON;
table contact CONTACT;
table media MEDIA;
...
These definitions contain 3 columns
-
tableis a keyword - the symbolic name of the table
- the table name in the database
In the case the database connection is in progress, you can use the content assist to pick up the correct table name. It can be seen in the following picture

The following picture presents the table name validation in progress - the CONTACT1 table doesn't exist in the database under the schema SQLSAMPLE:

In the META SQL statements all database tables names can be declared with the prefix %%. For example in the statement ALL_PEOPLE there's a usage %%PERSON:
ALL_PEOPLE(QRY,tab=person)=
select %ID @id, %NAME @name
from %%PERSON
{= where
{& %ID = :id}
{& UPPER(%NAME) = :+name}
}
{#1 order by %ID}
{#2 order by %NAME}
;
In the runtime, the control character sequence %% is ignored. It is only recognized by the Eclipse plugin to activate the validation and content assist in the process of META SQL statement definition. This can be seen in the following picture:
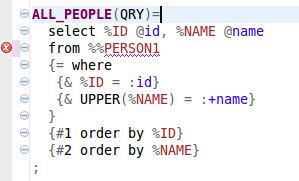
To enable these features, the usage of the database table in this META SQL statement has to be defined, like in the following snippet:
Important - the next is no more true. For the new way please see SQLP 2.0 and SQLEP 1.3 Tutorial.
_ dbcol ALL_PEOPLE person;_ dbcol LIKE_PEOPLE person; dbcol INSERT_PERSON person; ... dbcol ALL_PEOPLE_AND_CONTACTS person prefix p; dbcol ALL_PEOPLE_AND_CONTACTS contact prefix c; dbcol ALL_PEOPLE_AND_CONTACTS2 person prefix p; dbcol ALL_PEOPLE_AND_CONTACTS2 contact prefix c; ...
These definitions contain 3 or 5 columns
* dbcol is a keyword
* the META SQL statement name
* the symbolic name of the table (defined previously)
* prefix is a keyword
* the prefix value used in the META SQL statement
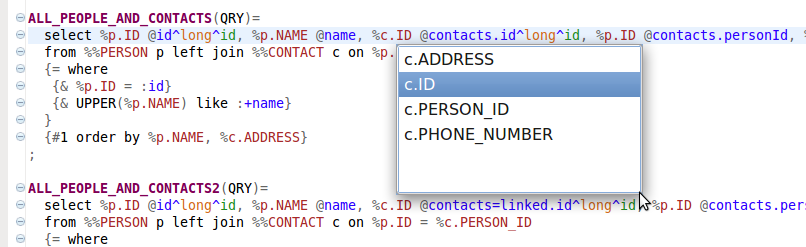
The result effect is that all the database columns usages are validated and the content assist can be utilized. In the META SQL statements all database columns names can be declared with the prefix %. For example in the statement ALL_ALL_PEOPLE_AND_CONTACTS there's a usage %c.ID:
ALL_PEOPLE_AND_CONTACTS(QRY,tab=person)=
select %p.ID @id(id), %p.NAME @name, %c.ID @contacts.id(id), %p.ID @contacts.personId, %c.ADDRESS @contacts.address
from %%PERSON p left join %%CONTACT c on %p.ID = %c.PERSON_ID
{= where
{& %p.ID = :id}
{& UPPER(%p.NAME) like :+name}
}
{#1 order by %p.NAME, %c.ADDRESS}
;
In the runtime, the control character % is ignored. It is only recognized by the Eclipse plugin to activate the validation and content assist in the process of META SQL statement definition. This can be seen in the following picture:
The %p.NAME1 is not a valid column in the table PERSON identified with the prefix p:
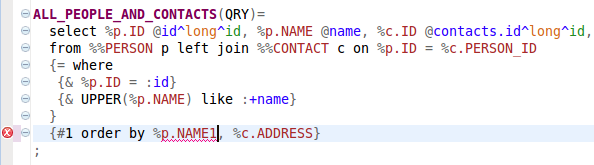
In fact, everywhere, where the database table (view) or column is used, the content assist can help to quickly pick up the correct one. Also the validation helps to identify all incorrect usage of them. This can speed up the process of the SQL Processor artifacts definition significantly. Also it prevents the exceptions in the runtime due to incorrect database objects usage.
##Outline Plugin provides an outline view to help you navigate your models. By default, it provides a hierarchical view on your SQL Processor runtime artifacts and allows you to sort tree elements alphabetically. Selecting an element in the outline highlights the corresponding element in the text editor. You can choose to synchronize the outline with the editor by clicking the Link with Editor button.
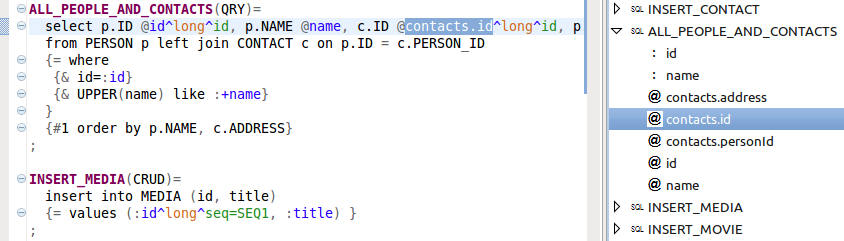
There are 3 types of the SQLP runtime artifacts - optional features (OPT), meta statements (SQL) and mapping rules (OUT). In the outline view there's also a possibility to filter these artifacts by types (OPT, SQL, OUT).
##General content assist The Content assist can help with the code completion not only for the SQL columns and POJO attributes. It covers all Xtext grammar keywords and a couple of enumerations.
For example, it can help with the SQL Processor artifacts types proposing their possible values:

Next example, it can help with the META types proposing their possible values:
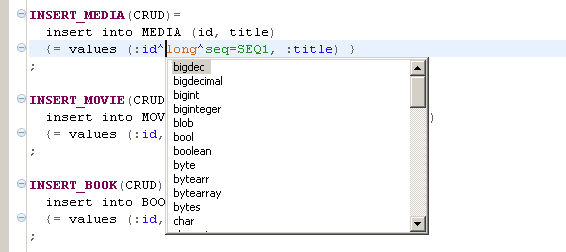
Some types are synonyms for the basic types, for example bool is synonym to boolean.
##CRUD templates SQLEP has defined 5 CRUD templates for the basic CRUD operations - select, insert, update, optimistic update and delete.
Here is a simple CRUD example – let's have a database table PERSON with the next (ORACLE) layout.
CREATE TABLE PERSON (
ID NUMBER(19) NOT NULL,
BIRTHDATE DATE NOT NULL,
CREATEDDATE TIMESTAMP,
CREATEDBY VARCHAR2(50),
LASTUPDATED TIMESTAMP,
LASTUPDATEDBY VARCHAR2(50),
VERSION NUMBER(19) NOT NULL,
CONTACT NUMBER(19),
SSN_NUMBER VARCHAR2(20) NOT NULL,
SSN_COUNTRY VARCHAR2(100) NOT NULL,
NAME_FIRST VARCHAR2(100) NOT NULL,
NAME_LAST VARCHAR2(100) NOT NULL,
SEX VARCHAR2(100) NOT NULL,
CLOTHES_SIZE NUMBER(10)
);
The related model is the Java class Person, which can be used also as a search form:
package org.sqlproc.engine.model;
import java.math.BigInteger;
import java.util.Date;
public class Person {
private Long id;
private java.sql.Date birthDate;
private Date createdDate;
private String createdBy;
private Date lastUpdated;
private String lastUpdatedBy;
private Long version;
private String first;
private String last;
// getters and setters
...
}
We'd like to have a person data in this table (=one database row). The result class is again the Java class Person. The META SQL query is going to be named GET_PERSON. First we write an empty statement in the meta statements file statements.qry:
GET_PERSON(CRUD)=
;
Now we define the next control directives in definitions.qry:
resolve-pojo-on;
database-is-online;
database-jdbc-driver oracle.jdbc.OracleDriver;
database-has-url jdbc:oracle:thin:@127.0.0.1:1521:xe;
database-login-username sqlsample;
database-login-password sqlsample;
database-active-schema SQLSAMPLE;
pojo person org.sqlproc.engine.model.Person;
table person PERSON;
When the definition file is actually finished, we can switch to the meta statement file. We put the cursor after the term GET_PERSON(CRUD,in=person,out=person,tab=person)= and press Ctrl+Space. The list of basic CRUD templates is shown and we can pick up the select CRUD statement. The result is:
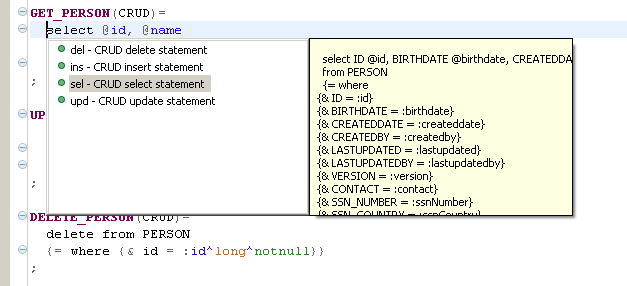
Some POJO attributes' names can be invalid as they are derived from the the names of the database columns using the camel case algorithm. We can utilize again the content assist to fix them based on the real attributes names. The result statemets.qry is the next one:
GET_PERSON(CRUD,in=person,out=person,tab=person)=
select %ID @id, %BIRTHDATE @birthDate, %CREATEDDATE @createdDate, %CREATEDBY @createdBy, %LASTUPDATED @lastUpdated, %LASTUPDATEDBY @lastUpdatedBy, %VERSION @version, %NAME_FIRST @first, %NAME_LAST @last
from %%PERSON
{= where
{& %ID = :id}
{& %BIRTHDATE = :birthDate}
{& %CREATEDDATE = :createdDate}
{& %CREATEDBY = :createdDy}
{& %LASTUPDATED = :lastUpdated}
{& %LASTUPDATEDBY = :lastUpdatedBy}
{& %VERSION = :version}
{& %NAME_FIRST = :first}
{& %NAME_LAST = :last}
}
;
Optimistic update is a special case, where the VERSION column (number) plays an important role. When you update the record, the VERSION value will be increased by 1.
UPDATE_PERSON(CRUD,in=person,out=person,tab=person)=
update PERSON
{= set (VERSION = :version + 1, BIRTHDATE = :birthDate, CREATEDDATE = :createdDate, CREATEDBY = :createdBy, LASTUPDATED = :lastUpdated, LASTUPDATEDBY = :lastUpdatedBy, CONTACT = :contact, SSN_NUMBER = :ssnNumber, SSN_COUNTRY = :ssnCountry, NAME_FIRST = :nameFirst, NAME_LAST = :nameLast, SEX = :sex, CLOTHES_SIZE = :clothesSize)}
{= where
{& ID = :id }
{& VERSION = :version }
}
;
##Advanced templates SQLEP has defined 2 more advanced templates to improve the coding efficiency:
-
pojos - it loads the definitions of all POJO classes (the output classes or search forms) on the classpath. To enable the POJOs detection, these classes must be annotated with
org.sqlproc.engine.annotation.Pojo. - tables - it loads the definitions of all database tables in the current schema
Remember - the definitions and statements files must be in same directory.
- check the Java POJO is in actual project or it's class is in dependency jar
- check
resolve-pojo-oncontrol directive in the definition file - change this directive to
resolve-pojo-off(and save this file) and back toresolve-pojo-on(and save this file)
- check the DB is online and the account isn't locked
- check the JDBC driver is in the classpath
- check the database attributes are correct in the definition file
- check
database-is-onlinecontrol directive in the definition file - change this directive to
database-is-offline(and save this file) and back todatabase-is-online(and save this file)
The SQL Processor Eclipse plugin (SQLEP) Tutorial for the former SQLP release can be found here SQLEP 1.0.0 Basic Tutorial