Accelerator not recognizing TPU in Google Colab and Kaggle Kernels #29
Comments
|
Yes it's only when you launch your training function with the |
|
same problem here: def _mp_fn(rank, flags): and in run_training() I do: for i in range(Config.EPOCHS): and I get: value for acc.device=xlr:1 What did I do wrong? |
|
Thanks for reporting. I haven't fully tested on Colab (the first use case is running script) so will need some time to set up a way of reproducing. In the meantime, could you share your notebook so I can have a full reproducer? |
|
this is a kaggle notebook from the current shopee comp - easiest probably: join the comp and upload I think the only thing you have to change is RETRAIN_MODEL='' a small bug: in train_fn() change |
|
Could you share which notebook it is? There are a lot of notebooks for this comp and a simple search with "accelerate" as a keyword does not yield anything. |
|
Also one thing that might be of help: I just did some testing on a Colab (will share an example soon) and I get your error ( Since this call initializes the distributed state, it can't be made in a cell of your I will see if I can work on a fix for this to make it easier to use. |
|
Thx for the fast answer! def run_training(): and get some "Exception in device=TPU:5: name 'accelerator' is not defined" - errors. Did I misunderstand "Since this call initializes the distributed state, it can't be made in a cell of your run_training, it has to be inside." ? |
|
It looks like the object |
|
shopee-pytorch-eca-nfnet-l0-image-training (1).zip Sorry thought just referencing the last notebook gives enough information |
|
Ah my mistake, I hadn't realized the notebooks was in the zip file, I thought it was the data 🤦 You are not passing around the |
|
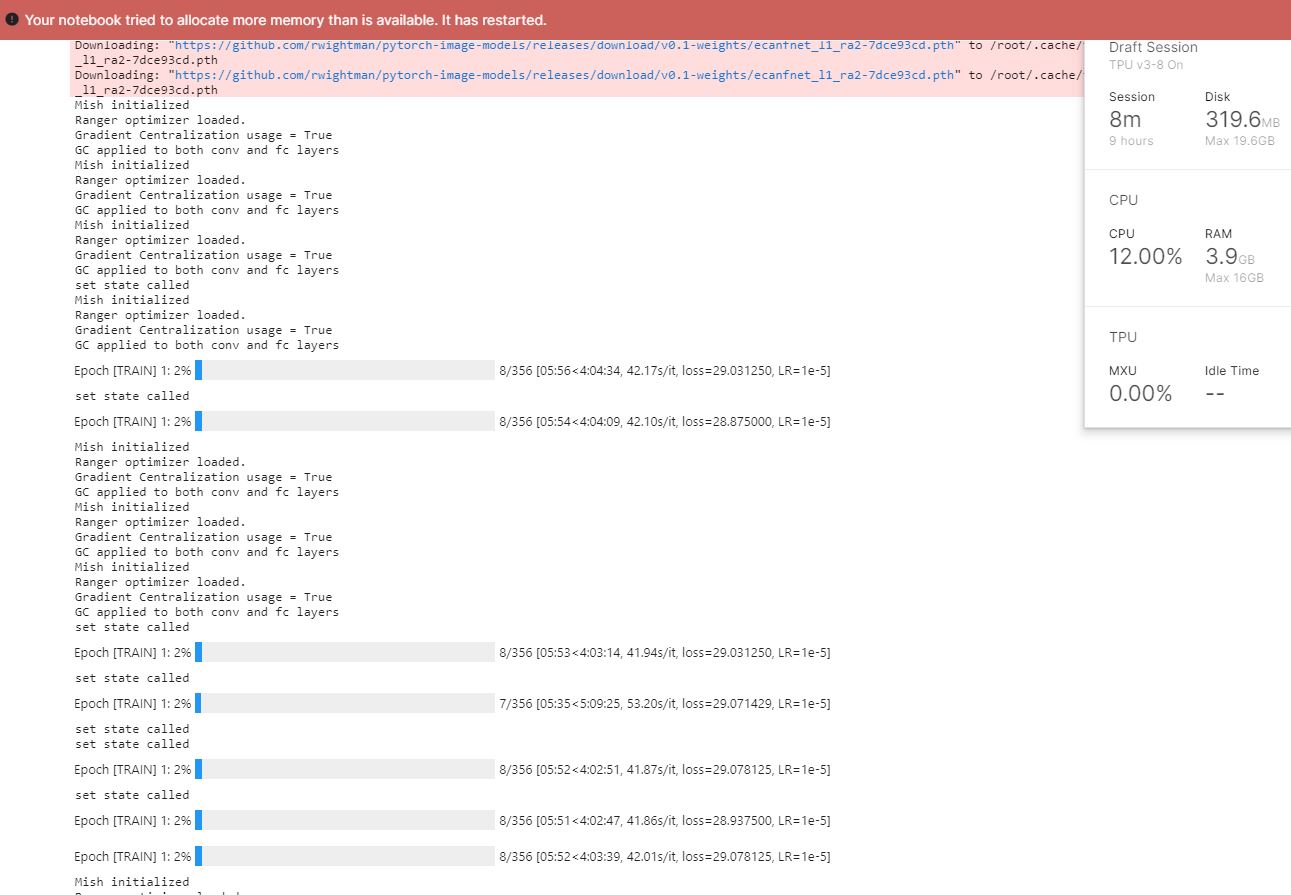
Thx - this solved the problem - but next experiment has been very strange.
|
|
Oh, that's because you have a call to You should add a Another thing to look at is to make sure you have fixed shapes (which you seem to have). In any case, the first step will always be very slow on TPU (as it compiles the whole graph for your training), it's after the first step that it goes faster. Hope that helps! |
|
I know tpu is slow in the beginning from my tf runs. I am new to pytorch and will try to implement your tips. If it goes well I will report. Thx again :) |
|
did not work out well - I commented out the loss.item call #fin_loss += loss.item() and the results: |
|
This is fixed by #44, there is now a |
|
I tried to run the notebook example (simple_nlp_example.ipynb) in Kaggle and I got the following error when trying to import transformers modules:
Please try running it here and see for yourself. |
|
Sounds like an issue on the Kaggle kernels, as it works fine on Colab. Does the error persist if you restart and retry? |
Yes it still persists. I found this discussion that was similar but did not help me solve my problem. https://www.kaggle.com/discussion/201365 |
I installed and imported accelerate in both Kaggle Kernels and Google Colab with TPU turned on but it doesn't seem to detect the TPU and instead detects CPU when running the following code:
The above snippet just outputs
cpuwhen ran on both aforementioned platforms with TPU enabled.Is there something that I am doing wrong?
PyTorch version: 1.7.0
Python version: 3.7.9
The text was updated successfully, but these errors were encountered: