RuntimeError: Cannot re-initialize CUDA in forked subprocess. To use CUDA with multiprocessing, you must use the 'spawn' start method #940
Comments
|
I need much more information than this, please provide if possible either the contents of each cell or the notebook itself. I can't do anything with what you've provided :) |
|
Wow, what great response time! here are the cells 0 1 train_dataset = torch.load('large_data/train_dataset.pth')2 def training_loop(num_train_epoch, per_device_train_batch_size, gradient_accumulation_steps):
default_args = {
"output_dir": "tmp",
"evaluation_strategy": "steps",
"num_train_epochs": num_train_epoch,
"log_level": "error",
"report_to": "none",
}
model = GPT2HeadWithValueModel.from_pretrained("gpt2")
training_args = TrainingArguments(
per_device_train_batch_size=per_device_train_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
gradient_checkpointing=True,
fp16=True,
**default_args,
)
train_dataloader = DataLoader(train_dataset, batch_size=training_args.per_device_train_batch_size)
optimizer = torch.optim.SGD(
model.parameters(),
lr=5e-5,
momentum=0.1,
weight_decay=0.1,
nesterov=True,
)
accelerator = Accelerator(fp16=training_args.fp16)
model, optimizer, train_dataloader = accelerator.prepare(model, optimizer, train_dataloader)
model.train()
for step, batch in enumerate(tqdm(train_dataloader), start=1):
inputs = torch.tensor(batch['input_ids'])
inputs = inputs.to(model.device)
outputs = model(inputs, return_dict=True)
logits = outputs.logits
shift_labels = inputs[..., 1:].contiguous()
shift_logits = logits[..., :-1, :].contiguous()
loss_func = torch.nn.CrossEntropyLoss()
loss = loss_func(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
loss = loss / training_args.gradient_accumulation_steps
accelerator.backward(loss)
if step % training_args.gradient_accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()3 num_train_epoch, per_device_train_batch_size, gradient_accumulation_steps = 1,2,4
args = (num_train_epoch, per_device_train_batch_size, gradient_accumulation_steps)
notebook_launcher(training_loop, args, num_processes=2) |
|
FYI we're also seeing a similar error reported by participants in the DreamBooth Hackathon when using T4 x 2 GPUs on Kaggle. Steps to reproduce
Here's the output from |
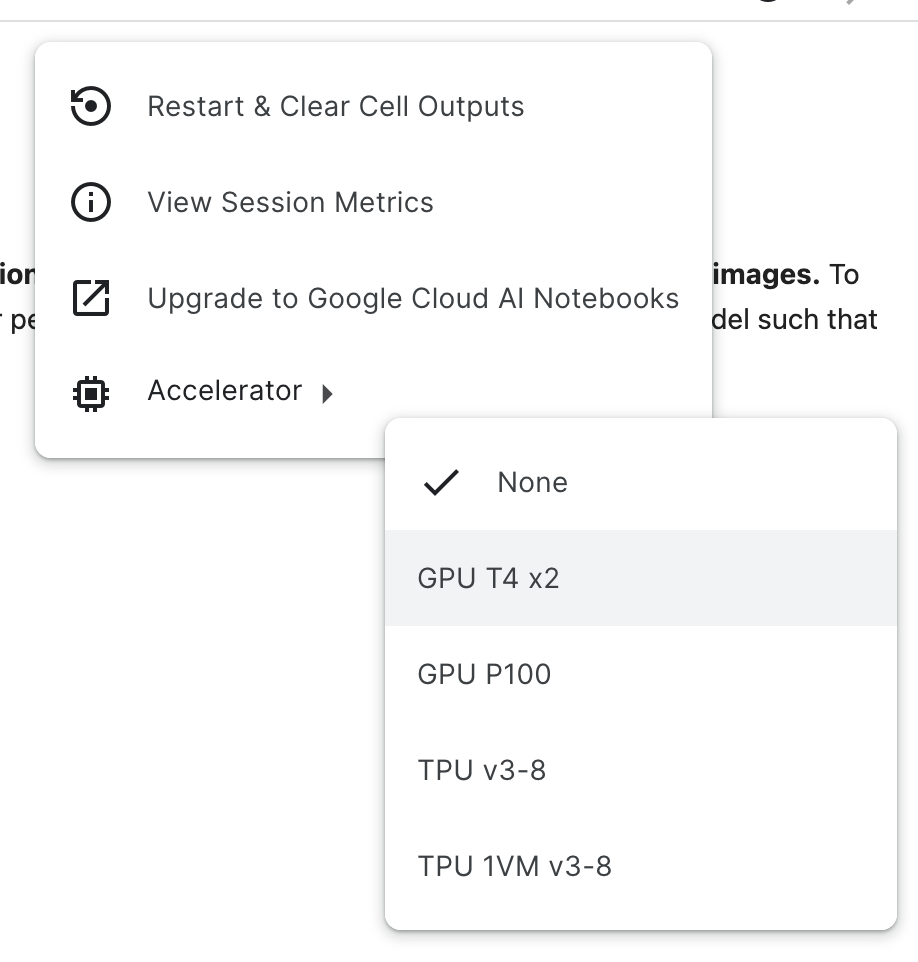
|
As I'm on vacation and can't look at this thoroughly I'll give you both a TL;DR of how to investigate it :) After every single cell, or at the end of it, include the following: torch.cuda.is_initialized()This must be If anything initializes |
|
Another thing to watch out for @lewtun pointed out to me is making sure any of the libraries you are using @clam004 aren't trying to initialize cuda later on in their library code. If doing it cell by cell and finding that nothing is being done, that means they're initializing |
|
Thanks @muellerzr , I did as you say and in every cell above I have verified that each has unfortunately I am still getting the same OK thanks for your help and enjoy your vacation, ill check back here in Jan 2023 |
|
Facing the same error when already I'm using Additional version Info: |
|
Was facing this issue due to a device variable initialized that was being done in the first cell Commenting this line resolved the issue. FYI: The |
|
Hi all. |
|
Had the same error, putting all my imports into my training_loop function fixed it, so my guess is some library that's being imported did something to trigger the cuda initialization or something like that. |
|
same error. Try to launch your script with "accelerate launch" on CLI, do not use "notebook_launcher()" inside the script. (follow the official guideline: https://github.com/huggingface/diffusers/blob/3b641eabe9876e7c48977b35331fda54ce972b4a/examples/unconditional_image_generation/README.md) |
|
I using T4 x 2 GPUs on Kaggle, face the same error. |
|
@Liweixin22 ensure that you haven't called anything to CUDA before running |
|
@muellerzr Here is the link of my notebook |
|
I am experiencing the same issue in the official diffusers training example notebook here. I downloaded the notebook and ran it on my system with dual-GPU setup and set
|
|
I'm facing the same issue, any updates on this? |
|
I'm facing the same issue, and I've encapsulated all the code within functions. The first line of code executed is notebook_launcher |
|
Hi @muellerzr Cell:0
Cell:1 Cell:2 RuntimeError: CUDA has been initialized before the Also, I tried looking at the GPU Memory before and after executing Cell:0, using After executing Cell:0 Could this mean that the import itself is leading to CUDA initialization, if so, how do we handle it? |
|
Try installing from git via |
Work for me, I uninstall the old version which For those whoes default pip install git+ssh://git@github.com/huggingface/accelerate.git |
|
Works for me too, thanks a lot @muellerzr for the prompt response! |
|
We'll have a release out this week with the non-braking version, thanks @Sewens @ghadiaravi13! |
|
This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread. Please note that issues that do not follow the contributing guidelines are likely to be ignored. |
|
I am still getting the same error on Kaggle T4s. It doesn't matter whether I load the model outside the training function or inside, the outcome is the same. |
|
This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread. Please note that issues that do not follow the contributing guidelines are likely to be ignored. |
|
@infamix i need a copy of your code to help |
|
@muellerzr the following code is breaking for me(First cell of the notebook): from accelerate import notebook_launcher
def test_nb_launcher():
from fastai.test_utils import synth_learner
import fastai.distributed # Updated
learn = synth_learner()
with learn.distrib_ctx(in_notebook=True): # Updated
learn.fit(3)
notebook_launcher(test_nb_launcher, num_processes=2)Running accelerate v0.24.1 import accelerate
accelerate.__version__ # '0.24.1'I'm also running this on a single node w/ 2x T4 GPUs. I'm guessing all the T4 reports are a coincidence because everyone's just trying to run on the two cheapest cloud gpu's they can get. 🤷 Edit: I forgot to include the |
|
This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread. Please note that issues that do not follow the contributing guidelines are likely to be ignored. |
|
Bump @muellerzr |
|
@csaroff ran just fine for me: import os
import torch
from accelerate import notebook_launcher
from fastai.test_utils import synth_learner
import fastai.distributed
os.environ["NCCL_P2P_DISABLE"]="1"
os.environ["NCCL_IB_DISABLE"]="1"
def test_nb_launcher():
learn = synth_learner()
with learn.distrib_ctx(in_notebook=True): # Updated
learn.fit(3)
notebook_launcher(test_nb_launcher, num_processes=2)Note: I'm using 2x 4090's, hence why the OS setting is needed (this will be automatic soon) |
|
This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread. Please note that issues that do not follow the contributing guidelines are likely to be ignored. |
Im using python3.8, pytorch 1.12.1, on Ubuntu 20.04.4 LTS (GNU/Linux 5.15.0-1029-azure x86_64) trying to use 2 V100 GPUs and CUDA Version: 11.6 from within my notebook using the notebook_launcher
notebook_launcher(training_loop, args, num_processes=2)
The text was updated successfully, but these errors were encountered: