The best way to learn and to avoid the illusion of competence is to test yourself. This will help you to find where you need to reinforce your knowledge.
<Question choices={[ { text: "The algorithm we use to train our Q-function", explain: "", correct: true }, { text: "A value function", explain: "It's an action-value function since it determines the value of being at a particular state and taking a specific action at that state", }, { text: "An algorithm that determines the value of being at a particular state and taking a specific action at that state", explain: "Q-function is the function that determines the value of being at a particular state and taking a specific action at that state.", }, { text: "A table", explain: "Q-learning is not a Q-table. The Q-function is the algorithm that will feed the Q-table." } ]} />
<Question choices={[ { text: "An algorithm we use in Q-Learning", explain: "", }, { text: "Q-table is the internal memory of our agent", explain: "", correct: true }, { text: "In Q-table each cell corresponds a state value", explain: "Each cell corresponds to a state-action value pair value. Not a state value.", } ]} />
Solution
Because if we have an optimal Q-function, we have an optimal policy since we know for each state what is the best action to take.

Solution
Epsilon Greedy Strategy is a policy that handles the exploration/exploitation trade-off.The idea is that we define epsilon ɛ = 1.0:
- With probability 1 — ɛ : we do exploitation (aka our agent selects the action with the highest state-action pair value).
- With probability ɛ : we do exploration (trying random action).
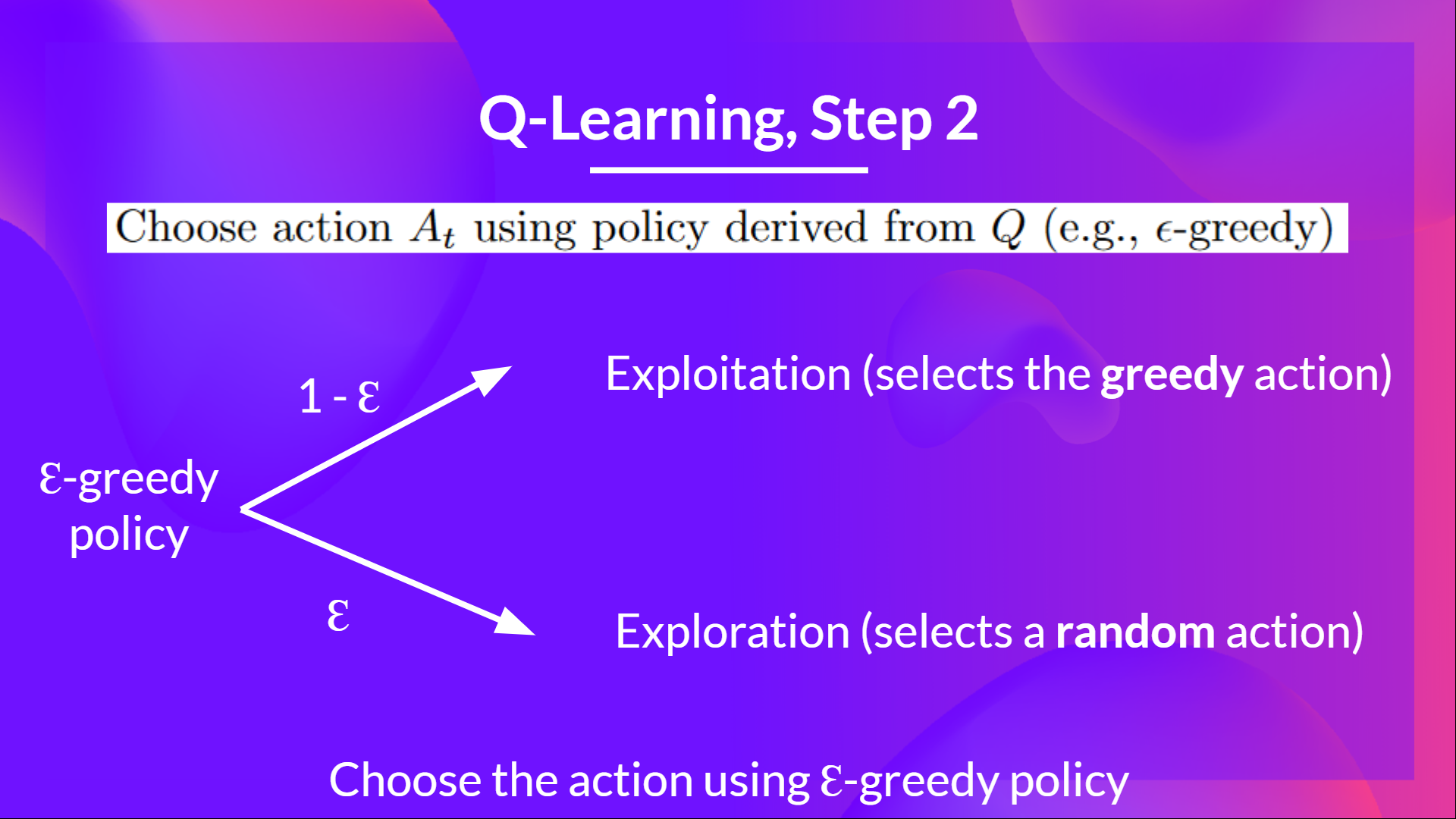
Solution
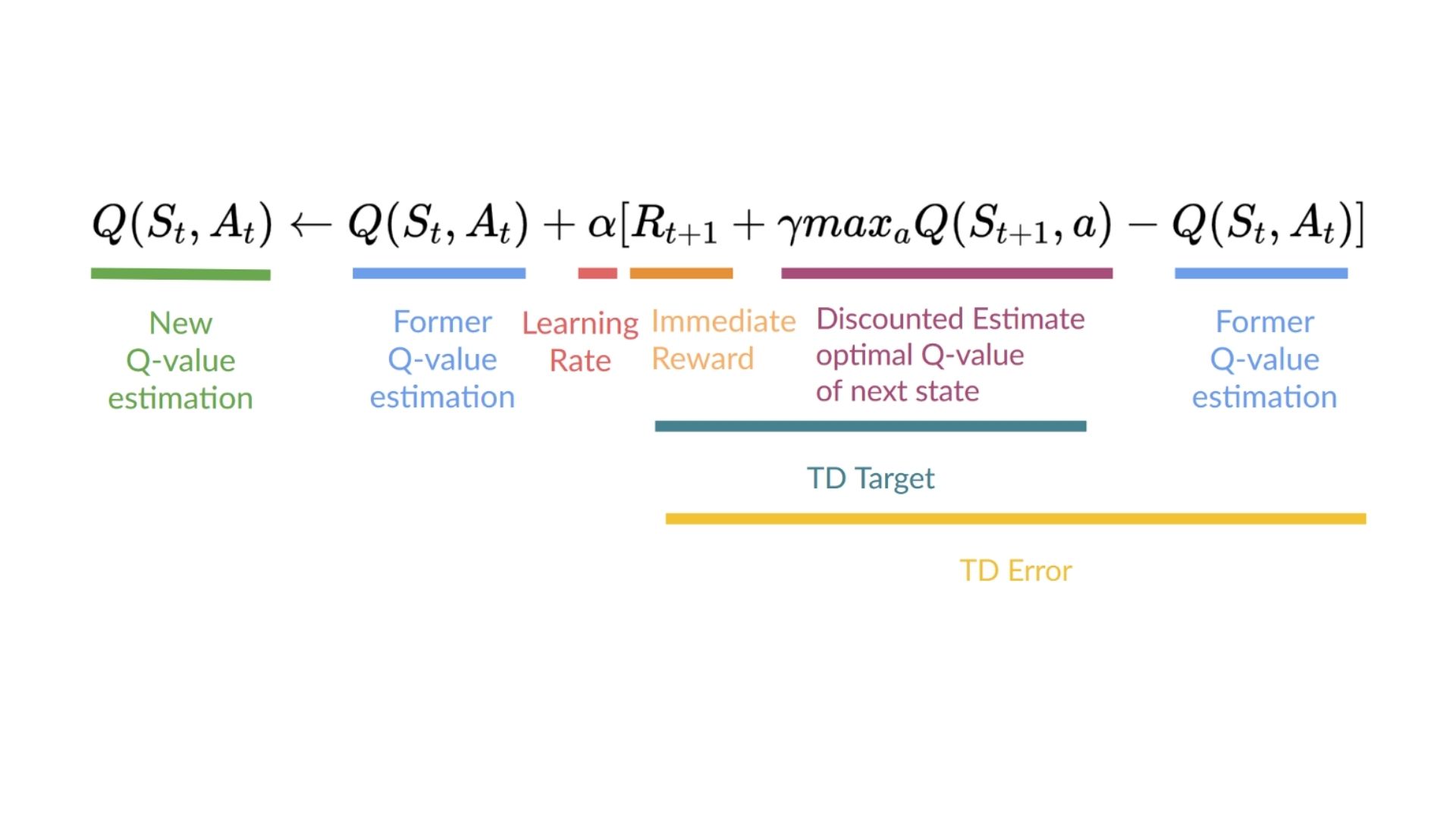
Solution

Congrats on finishing this Quiz 🥳, if you missed some elements, take time to read again the chapter to reinforce (😏) your knowledge.