The main goal of Reinforcement learning is to find the optimal policy \(\pi^{*}\) that will maximize the expected cumulative reward. Because Reinforcement Learning is based on the reward hypothesis: all goals can be described as the maximization of the expected cumulative reward.
For instance, in a soccer game (where you're going to train the agents in two units), the goal is to win the game. We can describe this goal in reinforcement learning as maximizing the number of goals scored (when the ball crosses the goal line) into your opponent's soccer goals. And minimizing the number of goals in your soccer goals.

In the first unit, we saw two methods to find (or, most of the time, approximate) this optimal policy \(\pi^{*}\).
-
In value-based methods, we learn a value function.
- The idea is that an optimal value function leads to an optimal policy \(\pi^{*}\).
- Our objective is to minimize the loss between the predicted and target value to approximate the true action-value function.
- We have a policy, but it's implicit since it is generated directly from the value function. For instance, in Q-Learning, we used an (epsilon-)greedy policy.
-
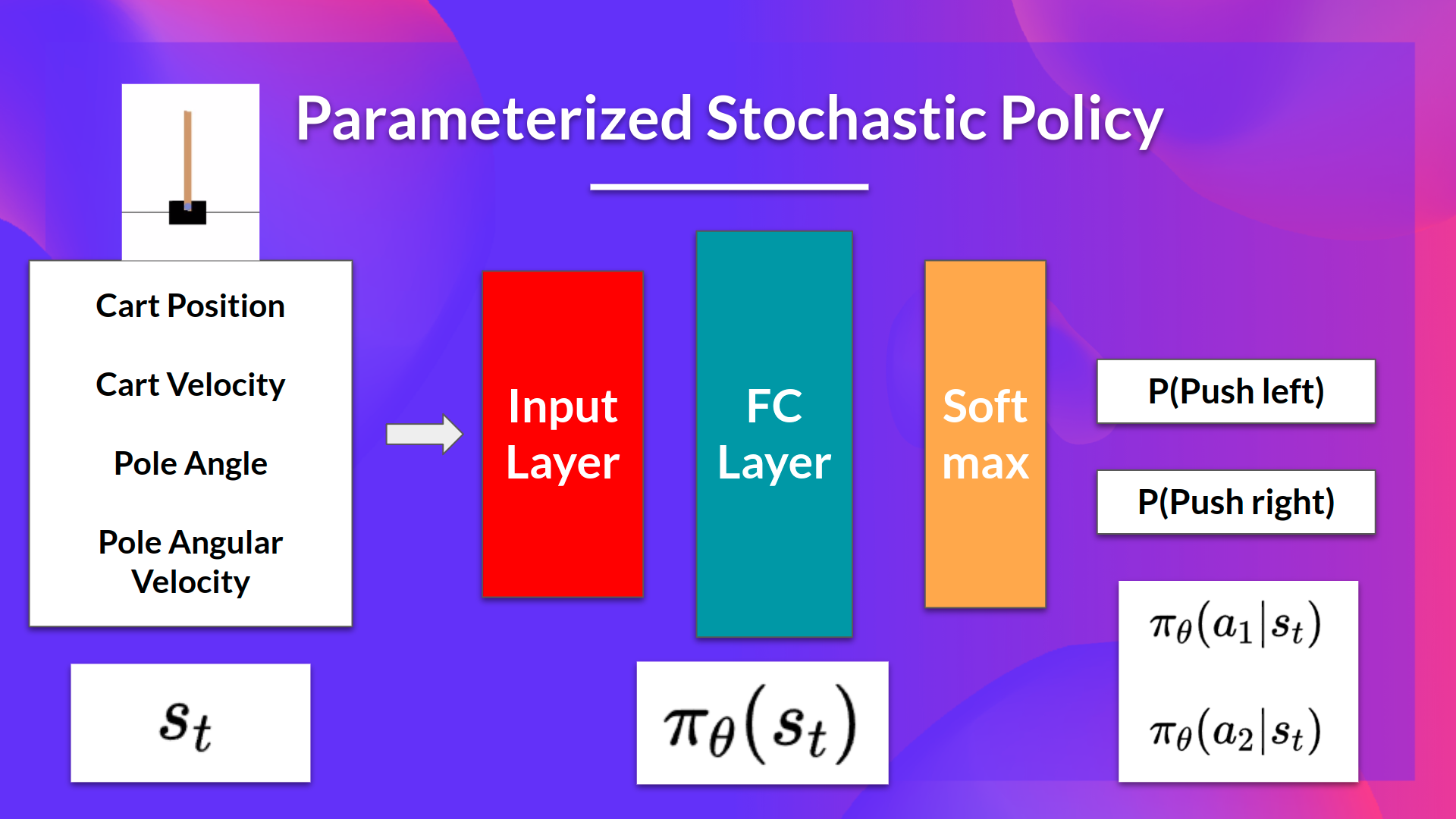
On the other hand, in policy-based methods, we directly learn to approximate \(\pi^{*}\) without having to learn a value function.
- The idea is to parameterize the policy. For instance, using a neural network \(\pi_\theta\), this policy will output a probability distribution over actions (stochastic policy).
-
- Our objective then is to maximize the performance of the parameterized policy using gradient ascent.
- To do that, we control the parameter \(\theta\) that will affect the distribution of actions over a state.

- Next time, we'll study the actor-critic method, which is a combination of value-based and policy-based methods.
Consequently, thanks to policy-based methods, we can directly optimize our policy \(\pi_\theta\) to output a probability distribution over actions \(\pi_\theta(a|s)\) that leads to the best cumulative return. To do that, we define an objective function \(J(\theta)\), that is, the expected cumulative reward, and we want to find the value \(\theta\) that maximizes this objective function.
Policy-gradient methods, what we're going to study in this unit, is a subclass of policy-based methods. In policy-based methods, the optimization is most of the time on-policy since for each update, we only use data (trajectories) collected by our most recent version of \(\pi_\theta\).
The difference between these two methods lies on how we optimize the parameter \(\theta\):
- In policy-based methods, we search directly for the optimal policy. We can optimize the parameter \(\theta\) indirectly by maximizing the local approximation of the objective function with techniques like hill climbing, simulated annealing, or evolution strategies.
- In policy-gradient methods, because it is a subclass of the policy-based methods, we search directly for the optimal policy. But we optimize the parameter \(\theta\) directly by performing the gradient ascent on the performance of the objective function \(J(\theta)\).
Before diving more into how policy-gradient methods work (the objective function, policy gradient theorem, gradient ascent, etc.), let's study the advantages and disadvantages of policy-based methods.