The following notebook walks through development of a Double Deep Q-Learning agent to play Atari Space Invaders, taking inspiration from RL tutorials from Jon Krohn's Deep Learning Illustrated and Aurélien Géron's Hands On Machine Learning with Scikit-Learn and Tensorflow. Learning has been scaled to a single machine, trained for 200,000 frames using a memory buffer of 60,000 experiences. Model training was performed ever three frames (per guidance from the DeepMind team), with ε-greedy learning over 20,000 decay steps, or roughly a third of total training. Additional modifications include using Huber loss as objective function for model training, implementatoin of "double" Q-learning (with online model weights copied to training model every 2,000 frames for 100 copy-events total), and inclusion of "spawn" and "respawn" skips over periods of user non-playability at the start of each game epsisode and user regeneration after loss of life (40 and 20 frames, respectively).

To train our RL agent, we will perform ε-greedy learning on processed images of Atari Space-Invaders, using a Double Deep Q-Learning approach to "exploitation." To expidite training, we'll retrain our model every three frames, with the value three selected in order to ensure that the environment's blinking "lasers" are visible to the RL agent (per DeepMind). We'll spend roughly a third of training time "exploring" our environment, ramping linearly from ε = 1 to ε = 0.1 over 20,000 decay steps (60,000 game frames). To improve performance, we'll freeze ε-greedy learning and model training for the first 40 frames of every game episode ("spawn" time, wherin the agent is unable to control game character
To process our image observations, we'll crop our image to the playable field of the Space Invaders game (roughly the space between the bottom of the agent-controlled spaceship and the mid-score area where the "mothership" will appear, downsample our image by 2x (to dimension 92 x 80, convert our observed pixel values to grey-scale, and scale values to [0,1].

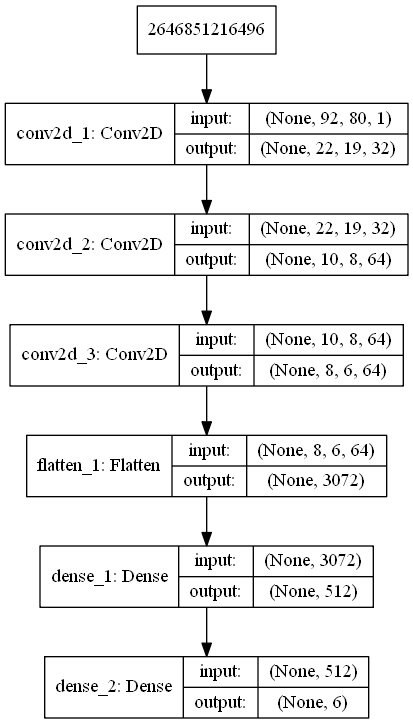
Our model architecture is inspired by the DeepMind Nature publication. It consists of three hidden CNN layers (a first 32-filter CNN layer of 8x8 convolutions passed over our images at stride 4, followed by a 64-filter CNN layer of 4x4 convolutions scanning at stride 2, and lastly second 64-filter CNN layer of 3x3 convolutions proceeding at stride 1) followed by a fully connected 512-node ReLU activation layer, and finally 6-output layer (mapping to the 6 playable actions of the SpaceInvaders game.
To train our ANN, we'll leverage the RMSProp SGD learning-rate optimizer, using the hyperparameters from the DeepMind Nature paper (learning_rate = 2.5 * 10 -4, ρ = 0.95, ε = .01). We'll skip the "reward" clipping approach used by the DeepMind folks, instead using Huber loss as our objective function (rather than Mean Square Error). For additional performance improvement, a Double DQN approach has been implemented, with core model weights copied to the training model every 2,000 training steps (6,000 played frames) for a total of 100 copies overall. We'll also allow our agent to play Space Invaders fully randomly for 5% of overall runtime (10,000 frames) before training begins, in order to collect sufficiently diverse experience for our model to begin training against.
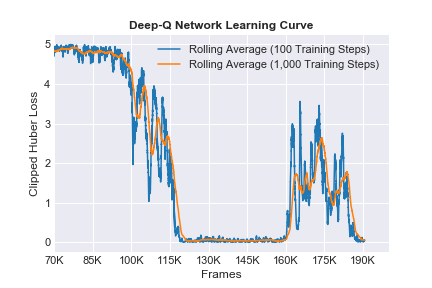
After ε-greedy learning, the RL agent trains quite effectively over the subsequent ~90K training frames. The model experiences some noisy training over the next ~15K frames, but this effect is flattened out over the final several training episodes.
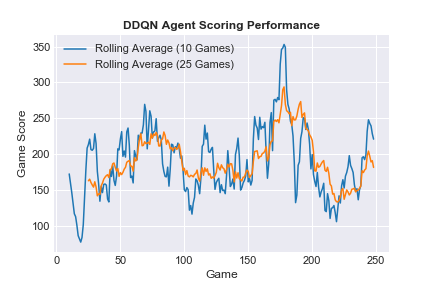
Consistent with our observed training performance, agent game scoring ramps with improving score over the first ~200 training episodes, with substantial gains from Game 95 (the first full episode with our minimum ε value) to about Game 200 (frame 160K). Scoring performance declines for the next 25 episodes (consistent with the training loss anomaly), before recovering for the final 25 episodes.
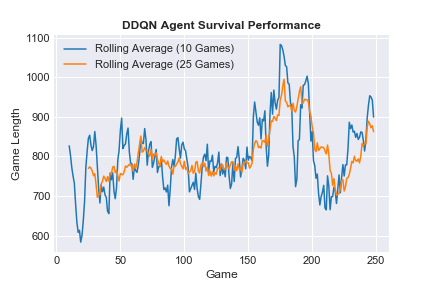
Similar behavior is observed in survival performance (game duration). Averaged game length is quite stable over ε-greedy, ramping quite quickly once agent training performance takes off. Game duration falls precipitously over the fallow agent performance period (Game 200 through Game 225, re-stabilizing over the final 25 episodes as loss improves.