Hướng dẫn: Directory
face_detectorchứa 2 file dùng để thực hiện face detection. Directorycaltech_faceschứa các ảnh khuôn mặt của nhiều người. Directoryhammiuchứa một số hàm hữu ích cho nhận diện khuôn mặt.
python face_recognition_LBPs.py --input caltech_facesThuật toán nhận diện khuôn mặt LBPs lần đầu tiên được giới thiệu vào năm 2004 bởi Ahonen et al.
LBPs sẽ chia ảnh ta thành

Ảnh gốc được chia thành các grid cells và sơ đồ trọng số Ảnh có 49 grid cells, mỗi cell sẽ có trọng số riêng của nó khi tính feature chung của khuôn mặt:
- LBP histogram cho cell trắng (như mắt) có trọng số lớn hơn 4 lần các cell khác. Đơn giản chỉ cần nhân 4 lần LBP histogram của cell trắng (có tính đến scaling và normalization.
- Cell xám nhạt (ligh gray cell) - vùng tai, miệng có trọng số 2
- Cell xám đậm (dark gray cell) - vùng má trong và trán có trọng số 1
- Các cell đen còn lại như mũi, vùng má ngoài... bị bỏ qua, không đóng góp gì vào feeature chung.
Những trọng số này được tìm ra bằng thực nghiệm bởi Ahonen et al. bằng cách hyperparameter tuning trên các tập dữ liệu.
Cuối cùng chúng ta nối các LBP histograms có trọng số từ 49 cells (có một số cell bị bỏ qua như nói ở trên) để hình thành nên final feature vector.
Quá trình nhận dạng khuôn mặt được thực hiện bởi kNN (
So với Eigenfaces thì LBPs chống nhiễu và cho kết quả tốt hơn do nó không dựa trên các raw pixels.
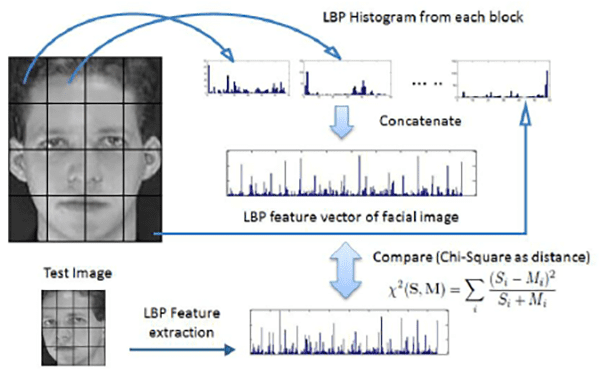
Nhận thấy face recognition với LBPs khá đơn giản:
- Trích xuất face ROI (dùng face detection)
- LBPs được trích xuất, có trọng số được nối lại
- kNN (k=1) với
$\chi^{2}$ distance - Đưa ra tên người với
$\chi^{2}$ distance nhỏ nhất
Khi có khuôn mặt mới LBPs không cần retrain lại từ đầu như Eigenfaces, đây là lợi thế rất lớn.
Để thực hành chúng ta sẽ sử dụng bộ dữ liệu Caltech faces với khoảng 450 ảnh (27 người). Mỗi ảnh được chụp dưới điều kiện ánh sáng, background, các biểu cảm khuôn mặt (facial expression) khác nhau.
Chúng ta vừa thực hiện xong face recognition với LBPs. Quá trình training khá nhanh, tuy nhiên quá trình inference chậm do phải duyệt qua tất cả các ảnh trong bộ dữ liệu. Để cải thiện tốc độ chúng ta có thể phải thay đổi thuật toán nearest neighbor