Code for the paper "Predicting Gaze in Egocentric Video by Learning Task-dependent Attention Transition" (ECCV2018)
This is the github repository containing the code for the paper "Predicting Gaze in Egocentric Video by Learning Task-dependent Attention Transition" by Yifei Huang, Minjie Cai, Zhenqiang Li and Yoichi Sato.
The code is tested to work correctly with:
Output gaze prediction using one image only!
-
Download pretrained models: spatial, late and put them into
path/to/models. -
Prepare some images named with
**_img.jpginpath/to/imgs/. -
Run
run_spatialstream.py --trained_model /path/to/models/spatial.pth.tar --trained_late /path/tp/models/late.pth.tar --dir /path/to/imgs/and see the results.
This module assumes fixation at predicted gaze position without any attention transition. Note the model is trained on GTEA Gaze+ dataset, I haven't tested images from other datasets, so images from the same dataset is recommended to use.
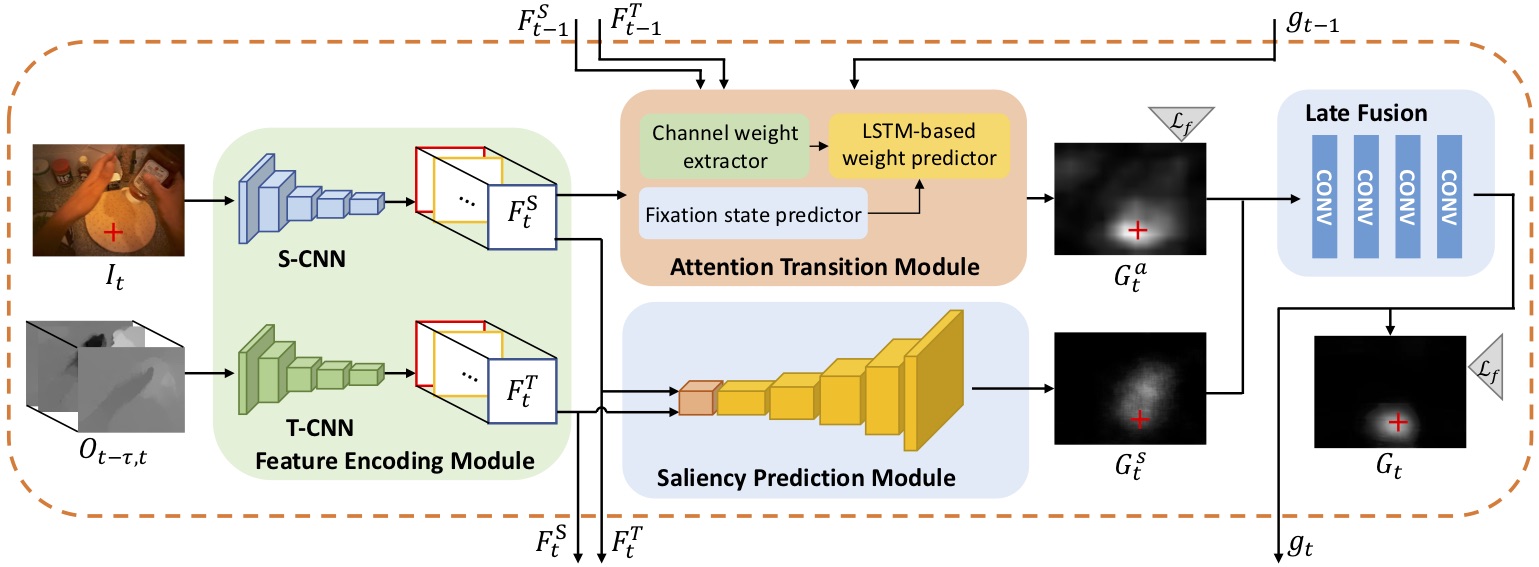
For simplicity of tuning, we separate the training of each module (SP, AT and LF)
We use GTEA Gaze+ and GTEA Gaze dataset.
For the optical flow images, use dense flow to extract all optical flow images, and put them into path/to/opticalflow/images (e.g. gtea_imgflow/). The flow images will be in different sub-folders like:
.
+---gtea_imgflow
|
+---Alireza_American
| +---flow_x_00001.jpg
+---flow_x_00002.jpg
.
.
+---flow_y_00001.jpg
.
.
+---Ahmad_Burger
| +---flow_x_00001.jpg
.
.
.
All images should be put into path/to/images (e.g. gtea_images/).
The ground truth gaze image is generated from the gaze data by pointing a 2d Gaussian at the gaze position. We recommend ground truth images to have same name with rgb images. Put the ground truth gaze maps into path/to/gt/images (e.g. gtea_gts/). For 1280x720 image we use gaussian variance of 70. Processing reference can be seen in data/dataset_preprocessing.py
We also use predicted fixation/saccade in our model. Examples for GTEA Gaze+ dataset are in folder fixsac. You may use any method to predict fixation.
To run the complete experiment, after preparing the data, run
python gaze_full.py --train_sp --train_lstm --train_late --extract_lstm --extract_late --flowPath path/to/opticalflow/images --imagePath path/to/images --fixsacPath path/to/fixac/folder --gtPath path/to/gt/images
The whole modle is not trained end to end. We extract data for each module and train them separatedly. We reccomend to first train the spatial and temporal stream separatedly, and then train the full SP module using pretrained spatial and temproal models. Direct training of SP result in slightly worse final results but better SP results.
Details of args can be seen in gaze_full.py or by typing python gaze_full.py -h.
You can find pre-trained SP module here
The module is trained using leave-one-subject-out strategy, this model is trained with 'Alireza' left out.
Y. Huang, M. Cai, Z. Li and Y. Sato, "Predicting Gaze in Egocentric Video by Learning Task-dependent Attention Transition," European Conference on Computer Vision (ECCV), 2018. (oral presentation, acceptance rate: 2%)
[Arxiv preprint]
Please cite the following paper if you feel this repository useful.
@inproceedings{huang2018predicting,
title={Predicting gaze in egocentric video by learning task-dependent attention transition},
author={Huang, Yifei and Cai, Minjie and Li, Zhenqiang and Sato, Yoichi},
booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
pages={754--769},
year={2018}
}
For any question, please contact
Yifei Huang: hyf(.at.)iis.u-tokyo.ac.jp