This project aim to demonstrate key word extraction from text using tf-idf method.
The dataset used in this project is "Indonesia News Title Dataset" which contains more than 90.000 news titles gathered from an online news portal.
This notebook is following this structure:
- Text Preprocessing: text normalisation, word filtering, lemmatization
- Simple exploratory data analysis
- Keyword extraction process using tf-idf
The basic idea of this proejct is to determine the importance of each word in the title. To achieve this, we utilize tf idf scoring which the formula is shown below:
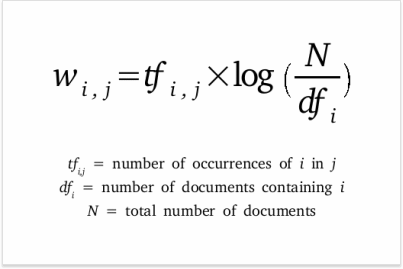
Credit: https://www.searchenginejournal.com/tf-idf-can-it-really-help-your-seo/331075/
Weight is the overall weight of a word in a text. Most important words of a text will have more weight, and vice versa.
The first term is TF or, term frequency, which determine the ratio of particular word in the current text. For example, if a word "Facebook" is appeared 10 times out of 100 words, then the TF is 0.1
The second term is Inverse Document Frequency, or IDF. Intuitively, this tells us how common a words is appeared accross all documents. Therefore, usually a stopword has a low IDF. Meanwhile, topic words, should have a large IDF because it's unique and only appeared in low portion of documents.
If you want to contact the author of this project, reach me through:
- Email: ibamibrahim0 [at] gmail