realtime event processing.0.2h
このチュートリアルはNiFi, SAM, Schema Registry, Supersetでリアルタイムプロセッシングを2時間で皆さんに体験していただく内容になっています。
環境はこちらで用意したVMを利用します。HDP、HDFがすでにインストールされ、チュートリアルに必要なNiFiやSAMの設定もある程度済んだ状態になっています。まずは講師から共有されたVMへの接続確認を行いましょう。
Webブラウザから、http://host:8080にアクセスします。
ユーザ/パスワードはadmin/adminです。
# centosユーザでSSHログインします。
$ ssh -i hwx-handson.pem centos@host本ハンズオンでは、以下の図に示すサンプルアプリケーションを皆さんに触っていただきます。
HDP (Hortonworks Data Platform), HDF (Hortonworks DataFlow)には多数のオープンソースプロダクトが同梱されており、それらを組み合わせてデータアプリケーションを開発します。本ハンズオンを通して、それぞれのプロダクトがどのような用途に利用できるのか、理解していただけると幸いです。
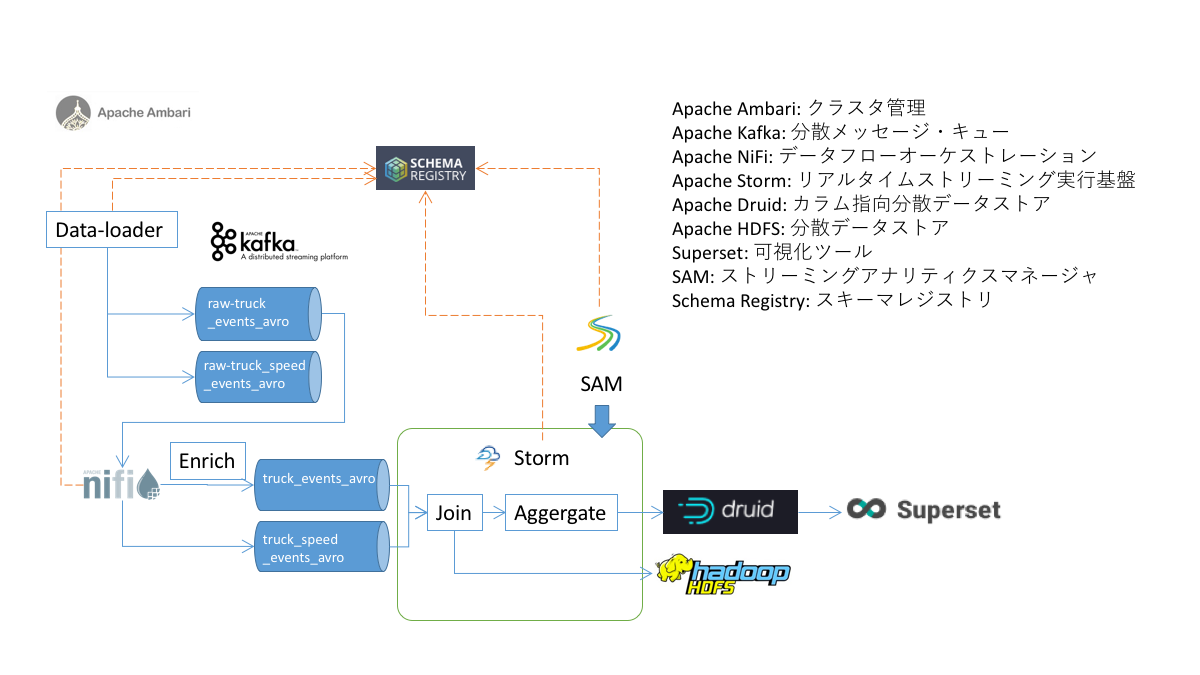
Supersetは、視覚的、直観的、対話的なデータ探索プラットフォームです。このプラットフォームは、可視化されたデータセットにて、友人やビジネスクライアントとダッシュボードを迅速に作成して共有する方法を提供します。様々な可視化オプションはデータを分析するために使用します。Semantic Layerは、データストアをUIに表示する方法を制御することをユーザに許可します。このモデルは安全であり、特定の機能だけが特定のユーザによってアクセスできる複雑なルールをユーザに与えます。Supersetは、Druidやマルチシステムと互換がある柔軟性を提供している他のデータストア(SQLAlchemy、Python ORMなど)と結合できます。
Druidは、データのビジネスインテリジェンスクエリのために開発されたオープンソースの分析データベースです。また、リアルタイムなデータ取り込みを低レイテンシで行い、柔軟なデータ探索と迅速な集約を提供します。デプロイメントは、多数のペタバイトのデータに関連して、何兆ものイベントに達することがよくあります。
Stream Analytics Managerは、ストリーム処理開発者が従来の数行のコードを記述するのに比べてわずか数分でデータトポロジを構築できるドラッグ&ロップのプログラムです。今すぐに、各コンポーネントまたはプロセッサがデータの計算を実行する方法をユーザは設定および最適化できます。また、ウィンドウ処理機能、複数のストリーム結合、その他のデータ操作を実行することができます。SAMは現在、Apache Stormと呼ばれるストリーム処理エンジンをサポートしていますが、後にSparkやFlinkなどの他のエンジンもサポートします。その際には、ユーザーが選択したいストリーム処理エンジンを選択できるようになるでしょう。
Schema Registry(SR)は、RESTfulインターフェイス経由でAvroスキーマを格納および取得します。SRには、すべてのスキーマを含むバージョン履歴が保存されます。シリアライザは、スキーマを格納するKafkaクライアントに接続するために提供され、Avro形式で送信されたKafkaメッセージを取得します。
# centosユーザでSSHログインし、rootユーザになります。
$ sudo su -
# データローダを起動します。
$ cd Data-Loader
$ ./data-loader.sh
# バックグラウンドで実行されログはnohup.outに出力されます。
$ tail -f nohup.outAmbariからNiFiサービスを選択し、Quick LinksのNiFi UIから、NiFiのUIを表示することができます。すでにKafkaからメッセージを取得し、データをエンリッチしてKafkaトピックへと出力するフローが用意されています。
ここでは、このフローが何をやっているのか、掘り下げて見てみましょう。
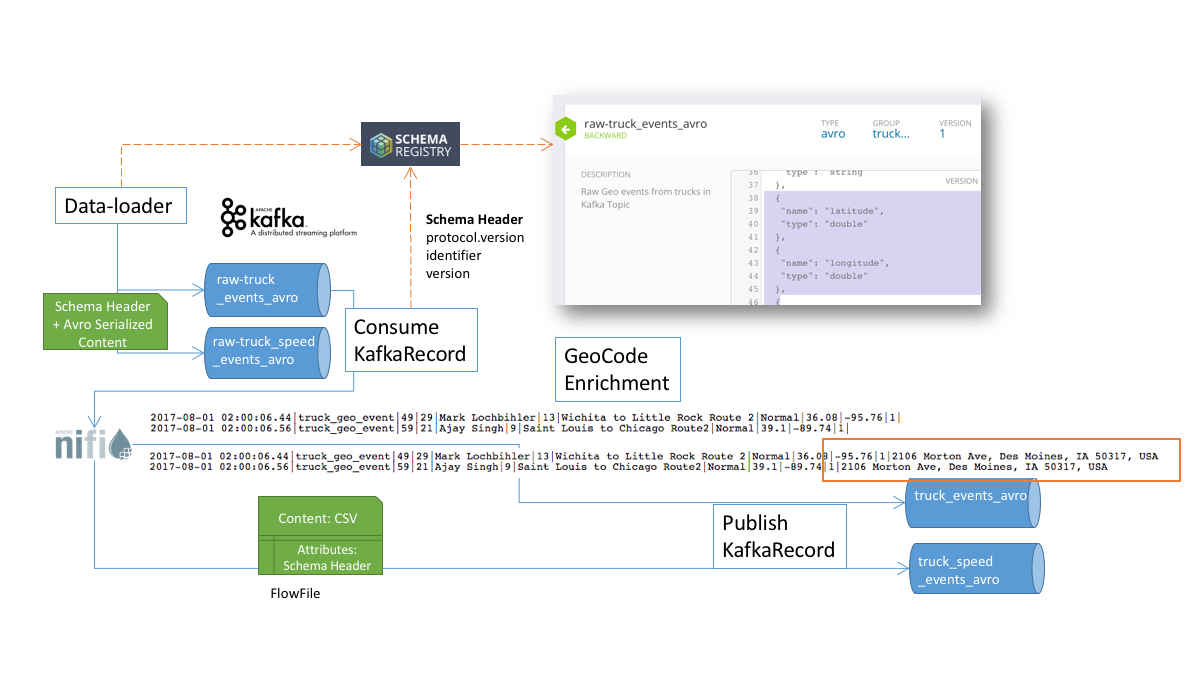
- ConsumeKafkaRecord: Kafkaからメッセージを取得します。AvroReaderでは、取得したメッセージに埋め込まれたSchemaヘッダを利用し、Schema RegistryからSchemaを取得してメッセージをパースします。CSVRecordWriterによりCSV形式のFlowFileを出力します。後のフローではCSV形式でデータを扱えるようになります。
- GeoCode Enrichment: Groovyスクリプトで、緯度経度を元に情報を付与(エンリッチ)します。
- PublishKafkaRecord: Kafkaへとメッセージを送信します。CSVReaderでCSVをパースし、AvroRecordSetWriterでAvro形式にシリアライズします。
GeoCode Enrichmentを右クリックし、Data provenanceを選択します。
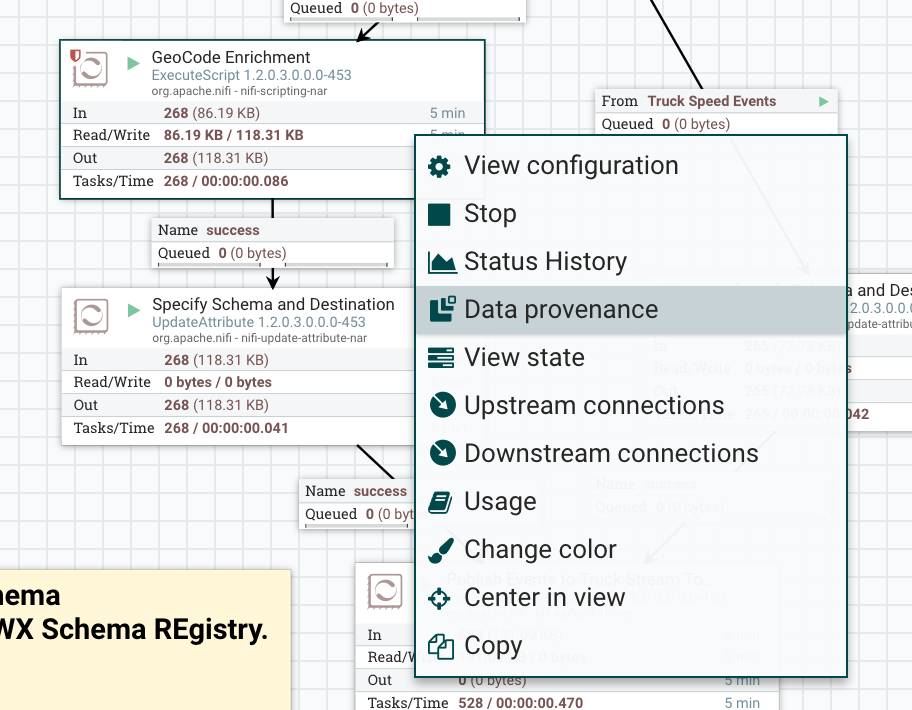
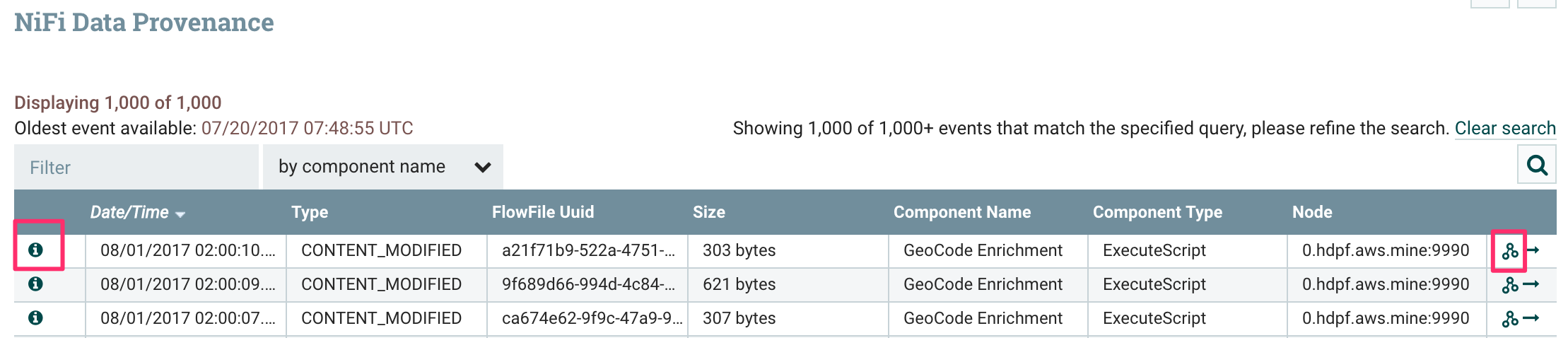
すると、このプロセッサを経由したFlowFileの一覧が確認できます。左端のインフォメーションアイコンをクリックすると、さらにこのプロセッサによる変更前後のデータが確認できます。右端のアイコンをクリックすると、このデータがどこからやってきてどのようなフローをたどったのか、データ来歴を確認することができます。
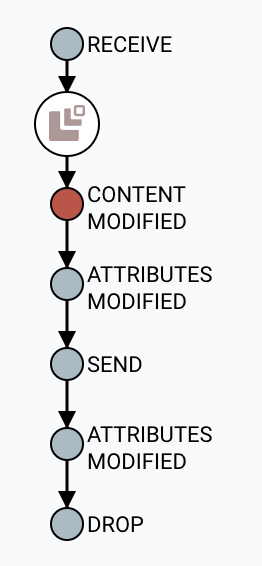
NiFiから参照していたスキーマを確認してみましょう。
Schema Registryにアクセスするために、Ambariの左サイドバーから"Registry" -> "Quick Links" -> "Registry UI"をクリックします。また、各スキーマを押下することでスキーマの内容が確認できます。

Kafkaのトピックを確認してみましょう。Kafkaトピックの作成などは、このようなコマンドを利用して行います。しかし、ストリーミングアプリケーションを作成している際にコマンドラインでトピックの有無やトピック名を確認するのも面倒なものですね。
# SSHでログインして、以下のコマンドを入力します。
# Kafkaにあるトピックの一覧が表示されます。
$ cd /usr/hdp/current/kafka-broker/bin
$ ./kafka-topics.sh --zookeeper localhost:2181 --listそこで、SAMでは、AmbariのURLを渡すと、そのクラスタの中にある各種アプリケーションのエンドポイントが一括で参照可能になる便利な機能があります。続いて、SAMを触ってみましょう。
SAMにアクセスするために、Ambariの左サイドバーから"Streaming Analytics Manager" -> "Quick Links" -> "SAM UI"をクリックします。をクリックし、右上の"Edit"をクリックします。"My Applications"から"+"ボタン -> "New Application"をクリックして、新しいアプリケーションを追加しましょう。任意の名前を着けて、Environmentに"HDF3_Handson"を指定して"Ok"をクリックします。
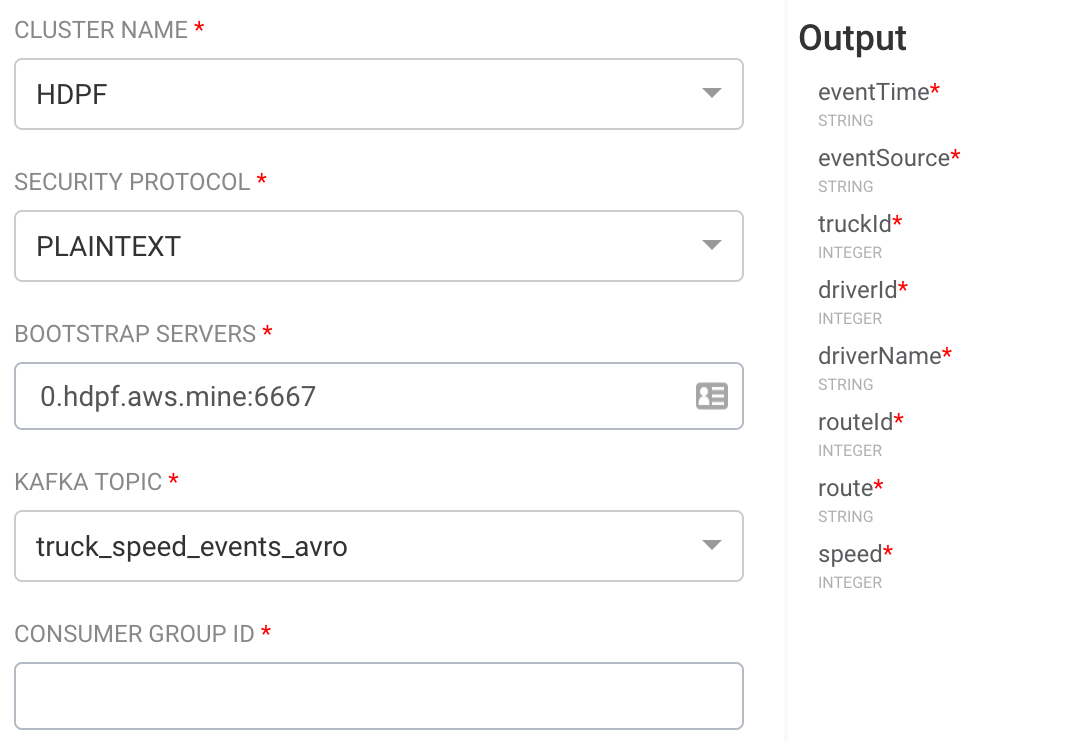
左サイドバーにある"KAFKA"アイコンをキャンバスにドラッグしましょう。 キャンバスに配置されたKAFKAアイコンをダブルクリックすると、設定画面が表示されます。SECURITY PROTOCOLを選択すると、BOOTSTRAP SERVERSにKafka brokerの接続先が自動的に設定されます。KAFKA_TOPICにも存在するトピックがリスト表示されているので、手入力する必要がありません。さらに、トピック名を選択すると、Schema Registryに登録されたスキーマが表示されるので、どのようなデータが受信できるのかすぐに分かります。
Kafkaだけでなく、HDFSやDruidなど、SAMで接続するデータソースはこのように簡単に接続先の設定が可能です。
Supersetを使用して、可視化をしてみましょう。
- Supersetにアクセスするために、Ambariの左サイドバーから"Druid" -> "Quick Links" -> "Superset"をクリックします。
- ユーザ/パスワードに
admin/passwordを入力してログインします。 - "Sources" -> "Refresh Druid Metadata"をクリックします。

- "Data Source"の
violation-events-cubeを選択すると、データの可視化を作成できる"Datasource & Chart Type"ページが表示されます。

- "Data Source & Chart Type"から、"Table View"をクリックし、Chart typeを
Sunburstに設定します。

- "Time"にて、"Time Granularity"を
one day、"Since"を7 days ago、"Until"をnowに設定します。 - "Hierarchy"を
driverName, eventTypeに設定します。 - 左上にあるQueryボタンを押下してクエリを実行し、出力を確認します。
- Save asボタンをクリックして、"Slice name"には
DriverViolationsSunburstを入力し、"dashboard name"にはTruckDriverMonitoringを入力し、Saveボタンで保存をします。

- "Table View"で
Mapboxを選択します。 - "Time"は、サンバースト図での設定をそのまま使用します。
- "Longitude"には
longitudeを、"Latitude"にはlatitudeを設定します。 - "Clustering Radius"を
20に設定します。 - "GroupBy"を
latitude, longitude, routeに設定します。 - "Label"を
routeに設定します。 - "Map Style"を
Outdoorsに設定します。 - "Viewport"にて、"Default longitude"を
-90.1、"Default latitude"を38.7に、"Zoom"を5.5に設定します。 - Queryボタンを押下して、クエリを実行します。
- Save Asボタンをクリックして、"Save as"を選択して
DriverViolationMapと入力します。その後、"Add slice to existing dashboard"を選択し、ドロップダウンからTruckDriverMonitoringを選び、"Save"を押下します。
- Dashboardsタブをクリックすると、ダッシュボードのリストが表示されます。

-
TruckDriverMonitoringのダッシュボードを選択します。
