Home
For this beta release of the impresso interface we introduce the first version of visual search. You can now filter all available images, by date and newspaper, and whether or not they appeared on a front page. Another way to explore images was added to the article viewer: just like the table of contents displays the list of article titles, the new tab “images” lets you scroll through all images in a newspaper issue.
As always, we value your feedback! You can email us at info@impresso-project.ch, use the Feedback Button on the lower right or use the impresso community Slack channel to share your thoughts and observations.
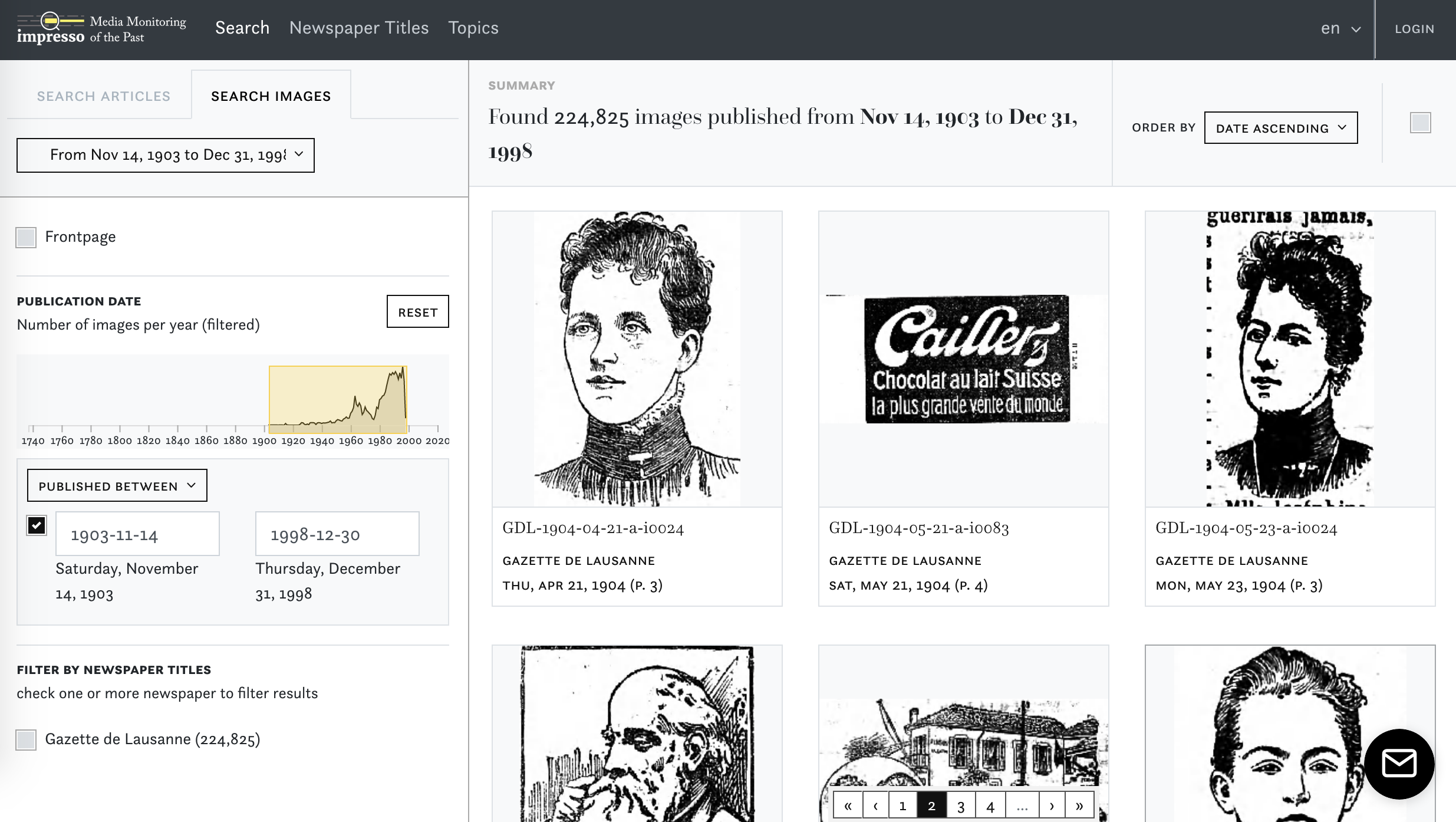
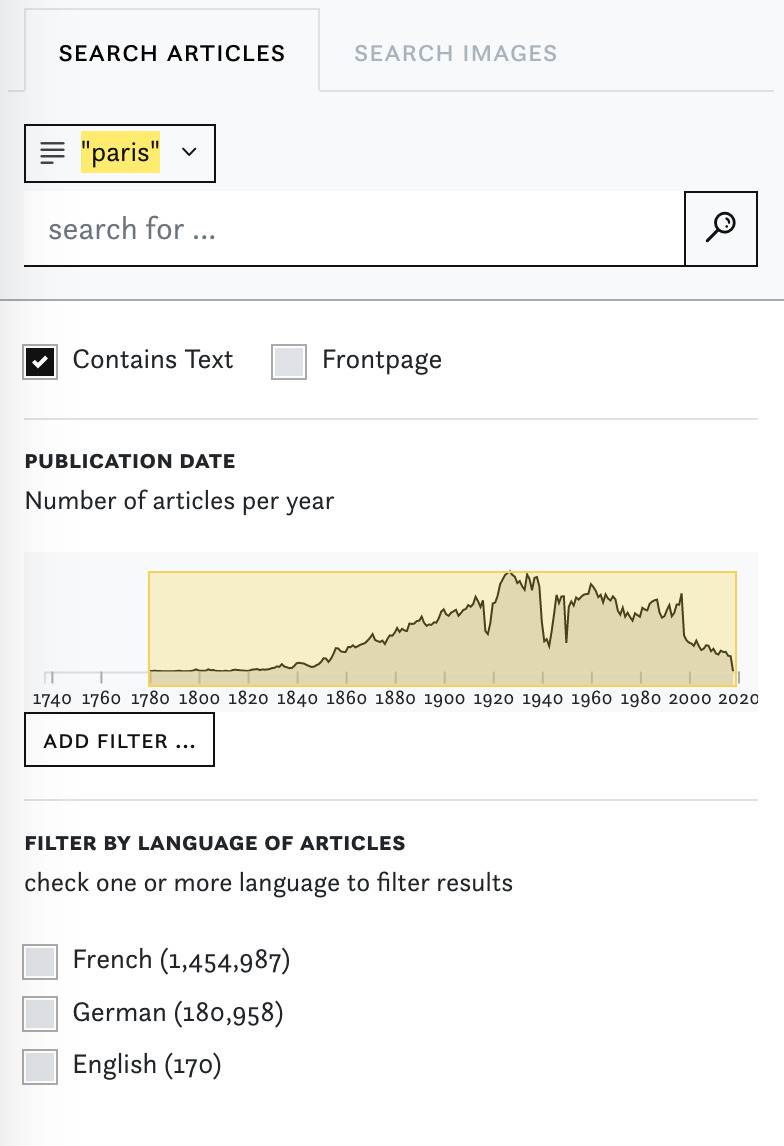
Amongst countless other small tweaks and improvements, we added the possibility to add your collections as facets and redesigned the search page including the facet filters and date ranges. Take a look and tell us what you think!
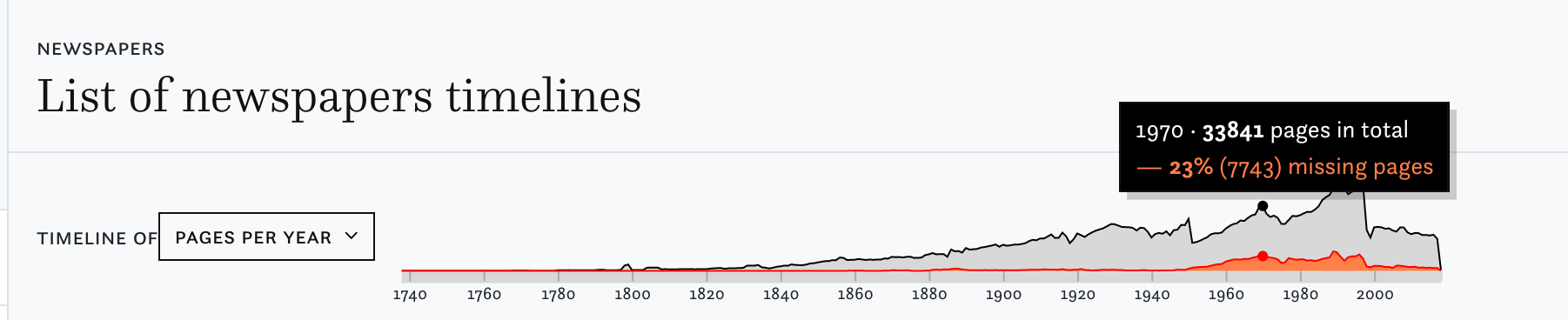
The perfect corpus does not exist and impresso is committed to helping you deal with inherent imperfections. To give you a better sense of what is or is not available in the impresso corpus, we added a newly designed timeline in the Newspapers section. But also please note that many of the now missing issues will be added within the next few weeks.
The ability to export data is among the most requested features. You can now bulk download metadata of your search result items for further processing with other analytic tools. The downloaded .csv file includes the newspaper title, issue date, language as well as the article content.

Have you noticed something wrong or irritating in the interface? Please email us at info@impresso-project.ch, use the Feedback Button on the lower right or use the impresso community Slack channel to let us know.
Here a list of things which are already under investigation:
- some articles appear to have no text associated to them
- there is a problem to retrieve images stored in collections
- blue highlights of article positions on facsimiles are sometimes off
- we display raw OCR output without any post-processing whatsoever; future releases will include, when possible, OCR post-correction
- the interface is optimised for Firefox and Chrome, Safari may cause issues
- newspaper metadata is still incomplete
- articles marked as English are an artefact caused by poor OCR
Start your query with the search box by typing a first keyword (for example Paris or for the movie Paris, Texas) and press enter. To add another keyword (France), repeat and press enter. Your keywords will appear in the search bar. Try to edit your keywords by clicking on them and change the scope of the query with the filters.
You can limit date ranges in your search in two ways by typing in the year boxes or by dragging the orange area in the chart.
You can limit the scope of the query to one newspaper title or to front pages only. Click on the title to select it. When selected it will appear in the search box. You can add several newspaper titles in this way.
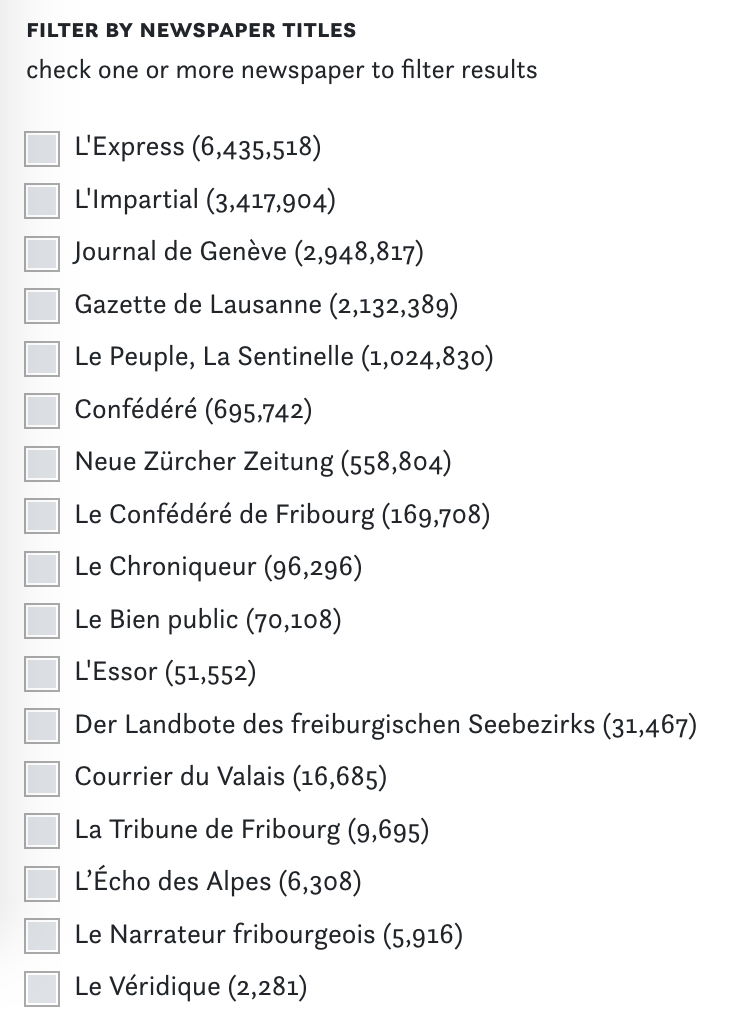
For this release we focused on adding a first set Swiss newspapers to the corpus. Check the Newspaper Titles segment in the interface to get an overview of what has been included in this release.
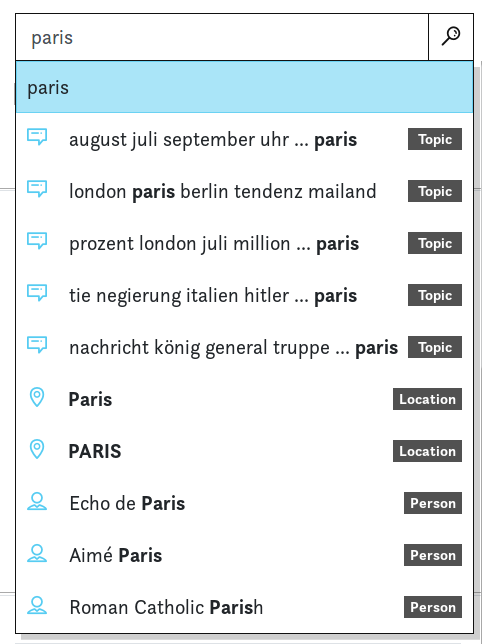
Named entities are automatically detected names of persons and locations. Future releases will also include organisations. In the search bar you can already select whether you are interested e.g. in Paris as a person or a location. You may notice wrongly assigned entities - e.g. a location miscategorised as a person - quality will improve over time. Also note that for now entities are recognised and categorised (pers/loc), but not yet disambiguated, i.e. attached to a unique referent. Consequently, the detected names Bismarck, Otto von Bismarck and Bismark (with an OCR mistake or typo) correspond to three different mentions, not yet linked all together.
To learn more about named entities, take a look at our blog post Named entity processing in a nutshell.
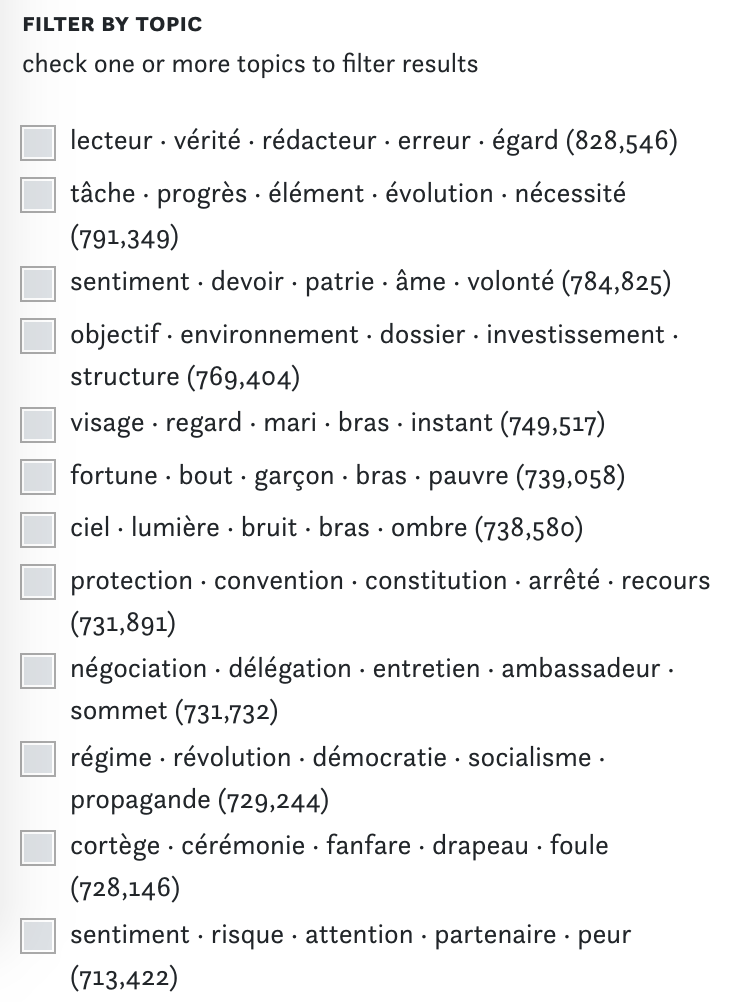
Put very simply, topic models allow us to automatically identify articles which have words in common and may therefore be related to each other. Topic models can help you to get an overview of the different contexts in which for example Europe is mentioned in the corpus. You can also use topic models as filters to narrow down search results. In the Topics section you can filter all topics for keywords of interest and use the graph to explore visually how they overlap. Click on a topic to explore the underlying articles.
To learn more about topic modeling, take a look at our blog post About Topic Modeling on historical newspapers.

Collections let you store and organise articles. You are able to add articles to your own collections. To add one article to one or more collection, use Add to Collection and here, define the name of the collection by typing it and clicking on Create New. If you have already created one or several collections, you can add the article to the collection by clicking on them. When an article has been added to a collection, the labels of these collections will appear on the article listing. To add several articles: on the side of the article list, notice the boxes that can help you select several articles at once and add them to one or several collections.
The first public release will include the following features and additions:
- the possibility to search for images which are similar to each other
- Named entity disambiguation with a page for every person, institution and location mentioned in the corpus
- keyword suggestions to improve your search queries
- a help page with additional information about the interface in place as well as recipes: examples for advanced searches that you can easily adapt for your own purposes
- the complete Luxembourgish and additional newspapers from Switzerland in the corpus.
The autumn release will include the following features and additions:
- search for recurrent text segments throughout the corpus to trace how e.g. a press release has been altered and how it spread over time and across newspapers
- sometimes dramatic improvements in the quality of character recognition depending on the newspaper font style (Gothic/Antiqua). This in turn will improve the quality of our text processing and yield for example better keyword searches, named entity recognition and finally more legible text
- information on the quality of entity recognition - the models used to extract entities will be evaluated against a ground truth which will cover several newspapers and 20 time periods. We will attempt to add confidence scores for each extracted entity mention in the interface
- a tool for the visual comparison of collections which will help you to detect where two collections overlap and differ
- a recommendation service will be available which will suggest articles with similar content
- tools which allow you to track semantic shifts of words over time by taking into account how their word-neighbours change.
After the autumn release we will begin working on custom visualisation case studies. Here we seek to support scholars with their projects by providing customised data visualisations which match their specific research interests. Do get in touch if you are interested in this.