Add unpivot functionality #2539
Comments
|
|
|
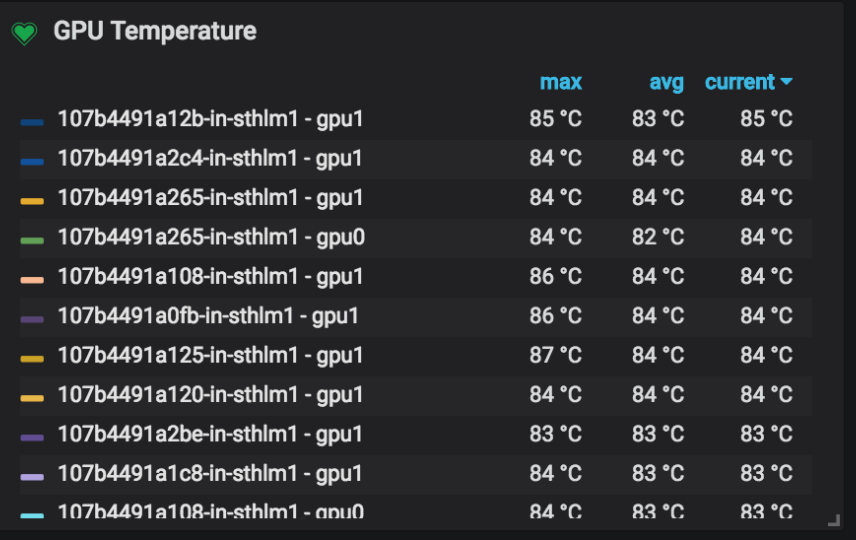
This would be great. My use case to have this is doing a but needing the output to be in long format of having columns |
|
Un-pivot is definitely something I've needed in Flux. I've used the work-around but it's far from ideal. |
|
THis will be useful for me as well! |
|
Please can we have unpivot! I've just spent hours on a workaround AGAIN where unpivot is exactly what's needed! |
|
Currently, running into the same issue. Would be great to have an unpivot. |
|
I'd like to hear a little bit more regarding times when unpivot is needed so we can make sure to design the function correctly. Some of the queries here could be rewritten slightly and avoid a need for an unpivot, but I'd like to hear feedback on them. The query at the top of the issue: This would be more efficiently written like this: I don't have the entire query, but I think that the other example is pretty similar: Could be rewritten to two map calls. But, I am not sure that these methods are very user-friendly and we want to make this very obvious for new flux developers. It seems that there might be two aggravating factors.
For 2, I think this issue captures the need. I have to take a row and split it into multiple rows that could go into different table keys. The reason why this isn't ideal is because I don't think we would be able to keep type information and I suspect it would be harder for us to parallelize the query to increase performance with this method. The above methods would allow the mean, max, and min to be processed concurrently by the engine. It also makes it easier for the planner to recognize that it could convert the above into pushdowns while the For 1, I am wondering if it would help if We're going to have a wider team discussion today so I am just brainstorming possible ideas. |
|
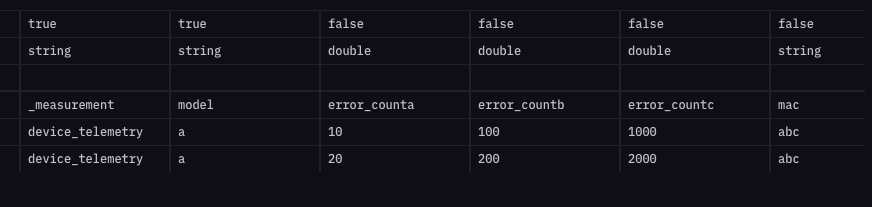
I'm looking for something similar to unpivot, but to be honest, I think I might be working around a cardinality issue (looking forward to Influx IOx). I'm collecting telemetry from devices. Its natural to use "mac address" as a tag, but we quickly hit cardinality limits in Influx cloud and moved mac address to a field. An approximation of my data in line protocol is: We're using Grafana to visualize this data both for the population and for individual devices. Which results in: I'm lazy and when we introduce error_countd, I don't want to have to update any dashboards. I made some progress using the above - which is a useful pattern for many other queries I have so thanks for that - but it doesn't quite get me to the end state I need: I have a post about this in the Influx community too: https://community.influxdata.com/t/lazy-grafana-dashboarding-using-field-vs-tag/19309 |
|
I'd also like an
The only way that I know how to parse these results is to use In this example, the array is only 6 elements long, but my actual data has 100 elements, and the code quickly gets out of hand with repeating sections. There also seems to be a performance impact, I'm guessing because I'm creating so many tables. I'm hoping this could be significantly simplified by including an |
|
@jsternberg Is there any update on this? I think you misunderstood the exmaple from @zegerhoogeboom. I have a similar situation. Then I would like to store that daily aggregate back to a new bucket. But I can't because now there is no |
|
@mjeanrichard you can use |
|
Why doesn't readding the _value column with map work as expected?? |
|
|
|
This is brilliant. A really useful function.
…On Thu, 10 Nov 2022 at 16:25, Scott Anderson ***@***.***> wrote:
unpivot()
<https://docs.influxdata.com/flux/v0.x/stdlib/experimental/unpivot/> is
available in the standard library as an experimental function. Closing this
issue.
—
Reply to this email directly, view it on GitHub
<#2539 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AQP5XM54AFXH3CSF5EUQQ7DWHUOWHANCNFSM4KYUMSQQ>
.
You are receiving this because you commented.Message ID:
***@***.***>
|
Every now and then, I run into a use case where it would be really useful to have the ability to unpivot data. For example, I defined this custom
minMaxMean()function that usesreduce()to output the min, max, and mean values for each table. The issue is that, as-is, I can't 1) visualize the results in the UI or 2) write them back to the db because the output schema doesn't meet the requirements for writing back into InfluxDB.To accomplish those things, I have to create multiple filtered streams, then union them back together:
This could be simplified with an
unpivot()function.So given the following input data:
unpivot()would output:The text was updated successfully, but these errors were encountered: