Adding file to repo with many files is slow #3545
Comments
|
Running this locally on my Macbook (to confirm it wasn't something weird with my ZFS drives), it does about 50k objects and then goes from roaring along at 0.05-0.06 seconds per file to 1-3 seconds per file Edit: correct number of objects downwards |
|
I think I've been seeing similar behaviour while adding the cdn.media.ccc.de mirror. I haven't measured it, but the repo was initially nearly empty, then the 3.8TB add got slower and slower over time, and now additional adds are just as slow. |
|
I just started another add, but this time with only-hash set ( |
|
Yeah, it’s definitely not slowing down for me with only-hash set
Edit: clarify
|
|
similar issue: ./ipfs add became very slow when handling about 45K files(~300GB), it took about 3+ seconds to wait after the process bar finished. % ./ipfs repo stat |
|
@jdgcs damn, I'd say it's the same thing...I even looked to see if there was already an issue and couldn't see anything |
|
I see that you are both using the repo stat: |
|
@mateon1 Thanks for the reminder. I did actually try 0.4.5-dev yesterday after I reported this. It did still have the problem: This is now locally on my MacbookPro on a USB3 external HD (HFS+). Interestingly, it's after the progress bar, and even the debug messages just seem to sit there. |
It took about 9h15m in the end, so it definitely is storage-related. |
|
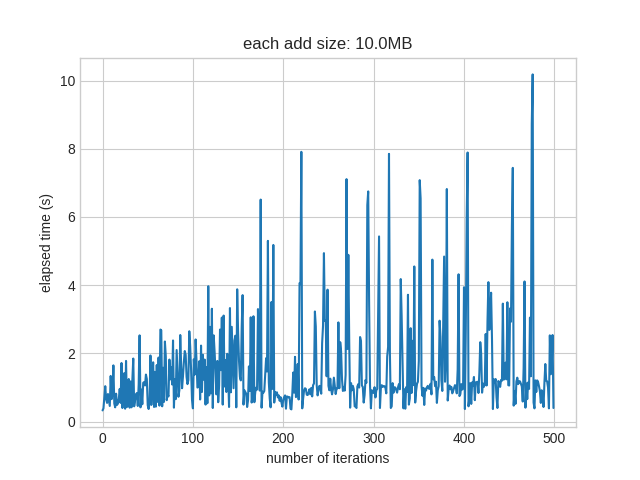
I test-benchmarked this on 0.4.5-rc1, code to reproduce: https://github.com/rht/sfpi-benchmark/tree/master/add_growing_repo ( The slowdown is >twice when the repo size hits ~5GB. I don't have enough storage space to quantify the ~TB scale though. |
|
I experience this as well. |
|
@forstmeier try using the experimental badger datastore. You can create a node configured to use it by instantiating it with I'm guessing this is due to the default datastore creating tons of tiny files (which filesystems generally don't like). Badgerds doesn't create one file per block so it should perform better (also, it'll use a hell of a lot less space). |
Version information:
go-ipfs version: 0.4.4-
Repo version: 4
System version: amd64/linux
Golang version: go1.7
Type: Bug
Priority: P1
Description:
Adding a file to an existing repo after many files have been imported is very slow.
I had originally though it might just be the time writing the file out, however this doesn't appear to be the case. Even a tiny file incurs the ~10 second penalty.
Is this expected behaviour? because it sort of rules out using it for anything large like rubygems (which is what I was trying to import).
This isn't on a particularly beefy machine, however it doesn't seem to be CPU bound or IO bound (I'm not a massive expert on the later, however
zpool iostatisn't showing high values).The text was updated successfully, but these errors were encountered: