Almost every app gets UC errors, 0.012% of all requests in 24h period #13848
Comments
|
Do you know if this is a new issue you are experiencing? |
|
Annoyingly, I'm not sure :-( Historically I've only really been looking at
|
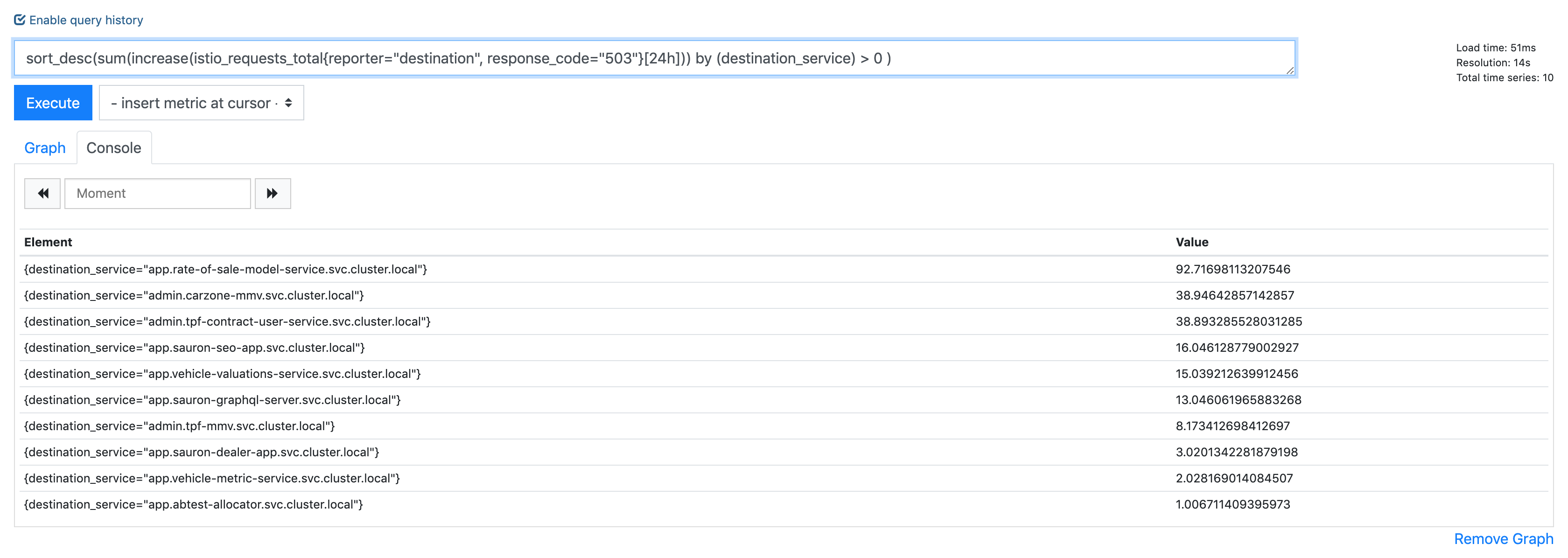
|
Hmm I have a theory that my updated timeout settings won't apply to existing connections, so the continued 503 UC i'm still seeing are old connections timing out. So will restart a bunch of the apps and leave overnight to observe. |
|
Well 10 minutes after restarting them, I saw another :'( so guess I didn't need to wait overnight!
|

|
Would you be able to post Envoy router and connection pool logs? I'm wondering if it's a case of a closed-by-upstream connection being reused that results in a 503 (recently fixed in Envoy but hasn't been released yet). Also, can you try setting |
|
The router logs in debug are difficult to capture as they're very verbose, the failure rate is quite low, say 0.02% - it becomes difficult to capture logs from all instances for a given app and catch the UC as i don't shift istio-proxy logs off to external logging (ELK). I'll try and think of something tomorrow. In the interim, I'll try adjusting the idleTimeout though and see what happens, but i'm unsure how it would help considering i've configured keep alive to be less than the timeout. |
|
15s made no difference 🤷 |
|
OK @arianmotamedi @howardjohn I persevered and managed to catch one with router and connection logs. This is from the destination envoy. |
|
I feel there is overlap with #13616, even though @jaygorrell is specifically talking about his observations during deployments. |
|
I also want to call out the messages i put on slack the other day, we have multiple app that do connection pooling having their connections terminated for no reason, all with the same error. I can't help but feel this is all related. searchone-consumer talking to search-one (in cluster -> in cluster) sauron-web talking to abtest-allocator (in cluster -> in cluster) sauron-web talking to ods (in cluster -> on prem) |
|
Wait, in the logs you posted, |
|
We do apply the outlier detection rules to inbound, not sure about the rest. I don't think this actually really does anything though, since we have the minHealthPercent |
|
TBH I don't know what the problem is. I'm just observing the failures with the code Here are sections from the config dump for that cluster: |
|
I mean, these logs don't sound particular healthy? |
They don't, it's definitely an issue, but it's not the same issue as others reported that was caused due to an existing connection being closed by upstream without downstream Envoy acknowledging it and returning it to the connection pool, which is what idleTimeout was added for. In those cases, you'd see an explicit log saying the connection is being reused:
If this isn't in your logs for |
|
Ah right so it's separate to the other issues then. @arianmotamedi those logs above are from |
|
@Stono these are The other thing you should check is cluster statistics for |
|
There is nothing in the application logs about it killing connections, no. Does envoy -> the app connection pool? Here are all the cx stats for one of the instances that's just been spawned (2 mins ago) and has had a UC already (just one): |
|
And here are the rest of the stats that are non-zero (you can see the 503): |
|
OK this issue can be exacerbated when you have more pods: Take this: And then look at the first two requests fail: This app is getting a very small amount of traffic but enough to prevent time outs: There's absolutely no pattern to the UC's, so it isn't some sort of fixed point interval drop. We've removed: Just in case for whatever reason that was interfering - but same behaviour I'm really not sure what else me and @emedina can do to help debug the problem! |
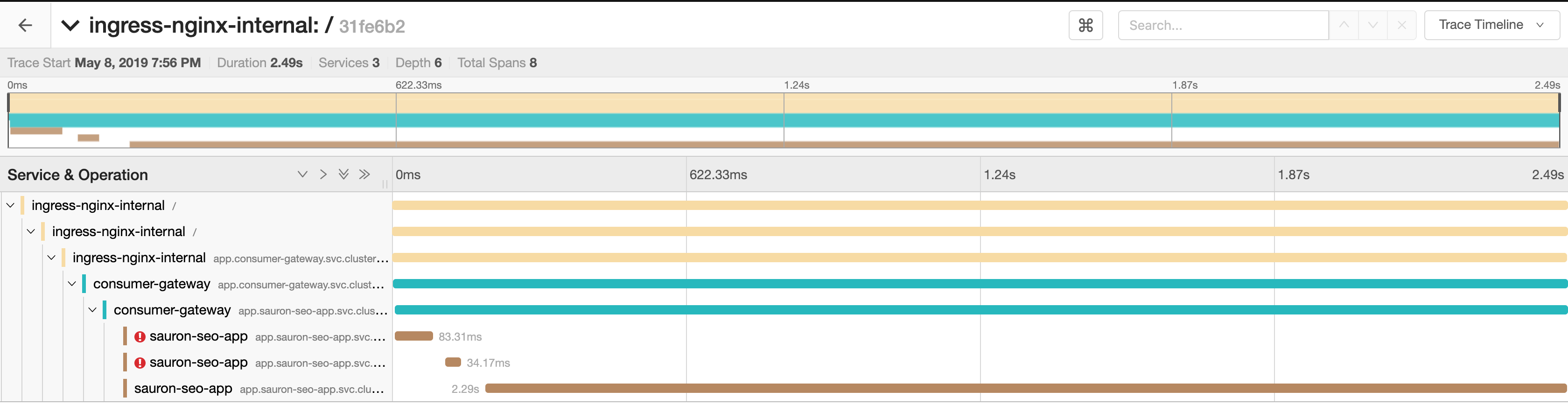
|
assigning to @duderino for triage, etc. |
@arianmotamedi Can you point me to this PR? We could potentially cherrypick |
|
@arianmotamedi that is a problem but i don't believe it is the cause of this issue |
|
@Stono we certainly have not proven it's the cause, but I'd like to keep considering it. @PiotrSikora @silentdai @jplevyak your thoughts please |
|
TBH if you had I've just unset |
|
Could you save the source envoy and dst envoy config somewhere? and the dst pod. My concern is that pilot would interpret infinite timeout as as hard-coded number instead a infinitity_max. I see this pattern a lot. |
|
idle timeout definitely works btw, you can see here where i set it to a low value (30s) and as a result get more connection churn into the destination app
|

|
I've sent you the config dumps on slack |
|
That shouldn't be good. IIUC active request should remain the same while the connection rate is higher |
|
Yes that's what you can see there; connection rate goes up active requests stay around the same, 15s sample rate. |
|
Update: Unfortunately I didn't reproduce. I have some clue in my experiment.
|
|
@Stono We should not see "remote early close" unless the service is jeopardized. That's indicating expect further data when the connection is closed. We shouldn't see this as you describe it as low rps. Is there any evidence that client(xx-gateway) or the server(seo) is overloaded at the UC 503? It might not be an overall loaded but a single request congestion. |
|
That's a shame. I've had 475 in the last 24 hours (on 112,626,354 requests, across 410 envoys):
It's nothing to do with the application being overloaded (it really isn't), in fact two of our top offenders have very little requests per second (6). I thought we had also demonstrated that the issue is between source envoy and destination envoy, not between destination envoy and destination app? I don't know if it helps debug at all, but here are some envoy graphs for the two top offenders: sauron-seo-app: sauron-graphql-server: And the another app which gets consistently quite a bit more traffic, but has had no UC's (search-one): They're all running with the same Destinationrule configuration: |

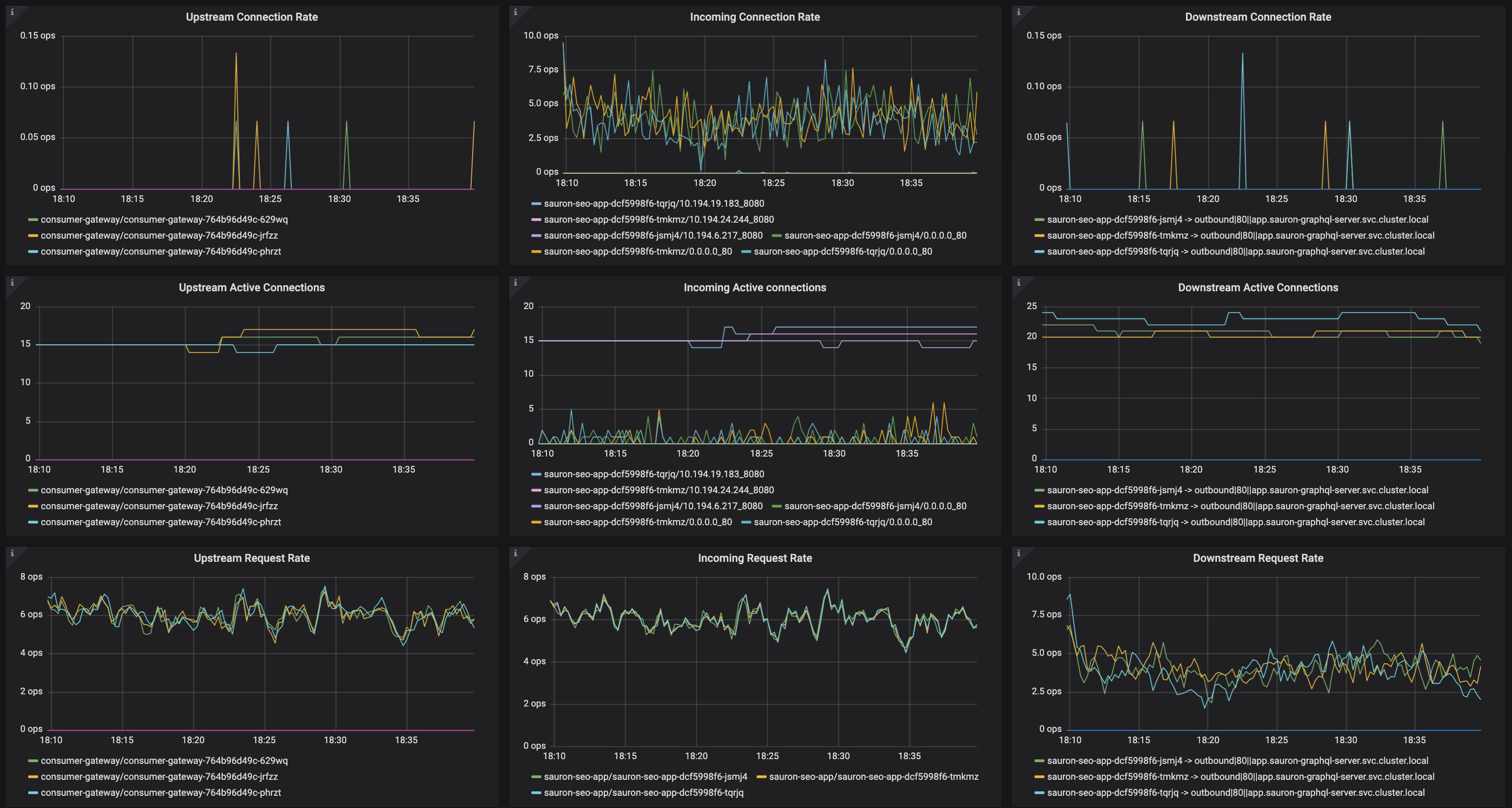

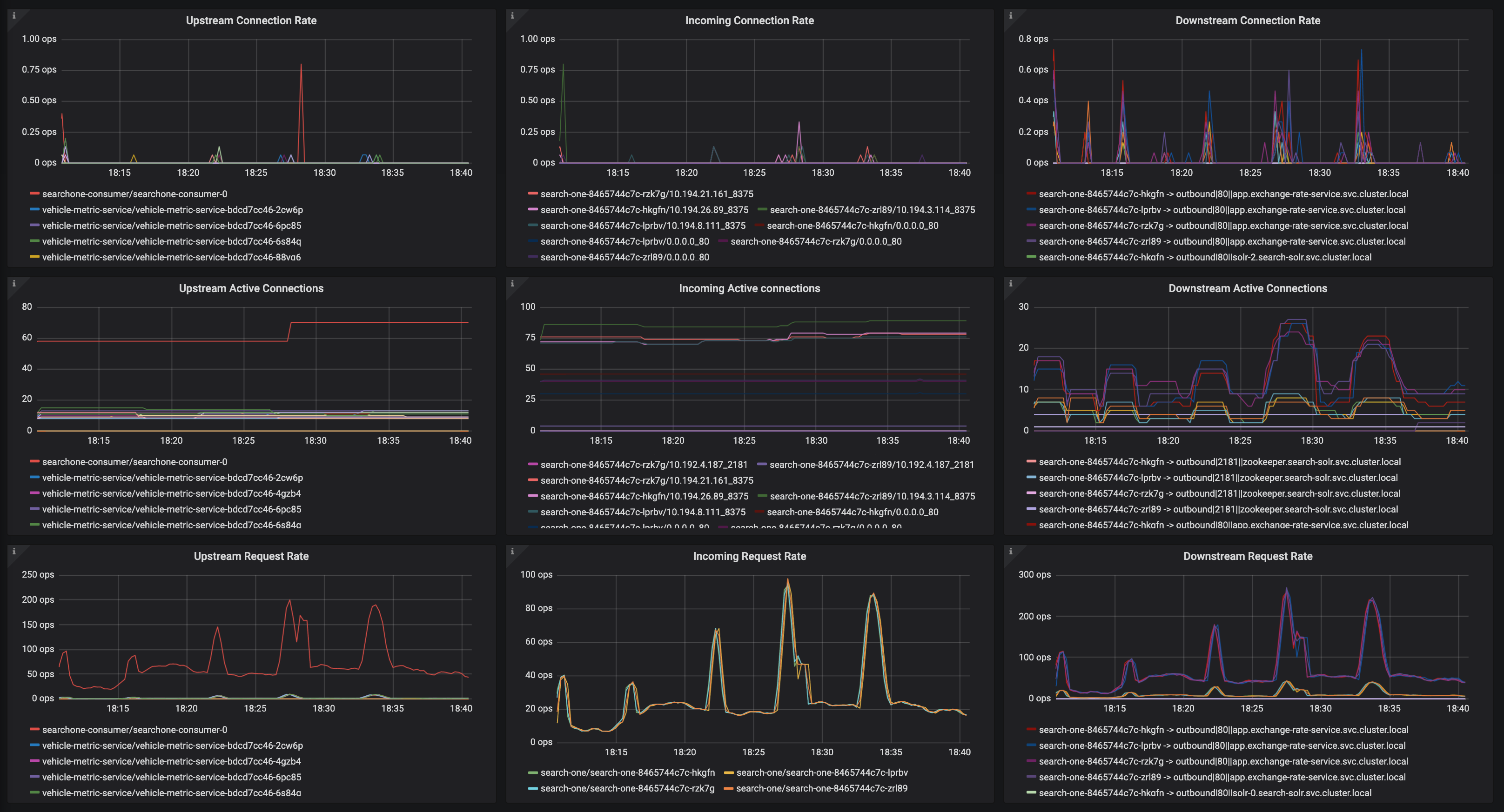
|
I think the key take away of this issue is that you're not going to be able to replicate the incredibly diverse setup of each of your customers environments, but your customers are going to experience issues. I think the focus should be around providing tooling, debugging capability, better metrics (cc @douglas-reid), improved logging and so on in order to help diagnose issues. |
|
@Stono This is a bit hard to digest, but if there are metrics that would help further, i'd love to brainstorm on their generation. |
|
We see more of these as connections ramp up. Following a deployment, here are the 503s: And here is the connections TO the envoy in front of sauron-seo-app: |
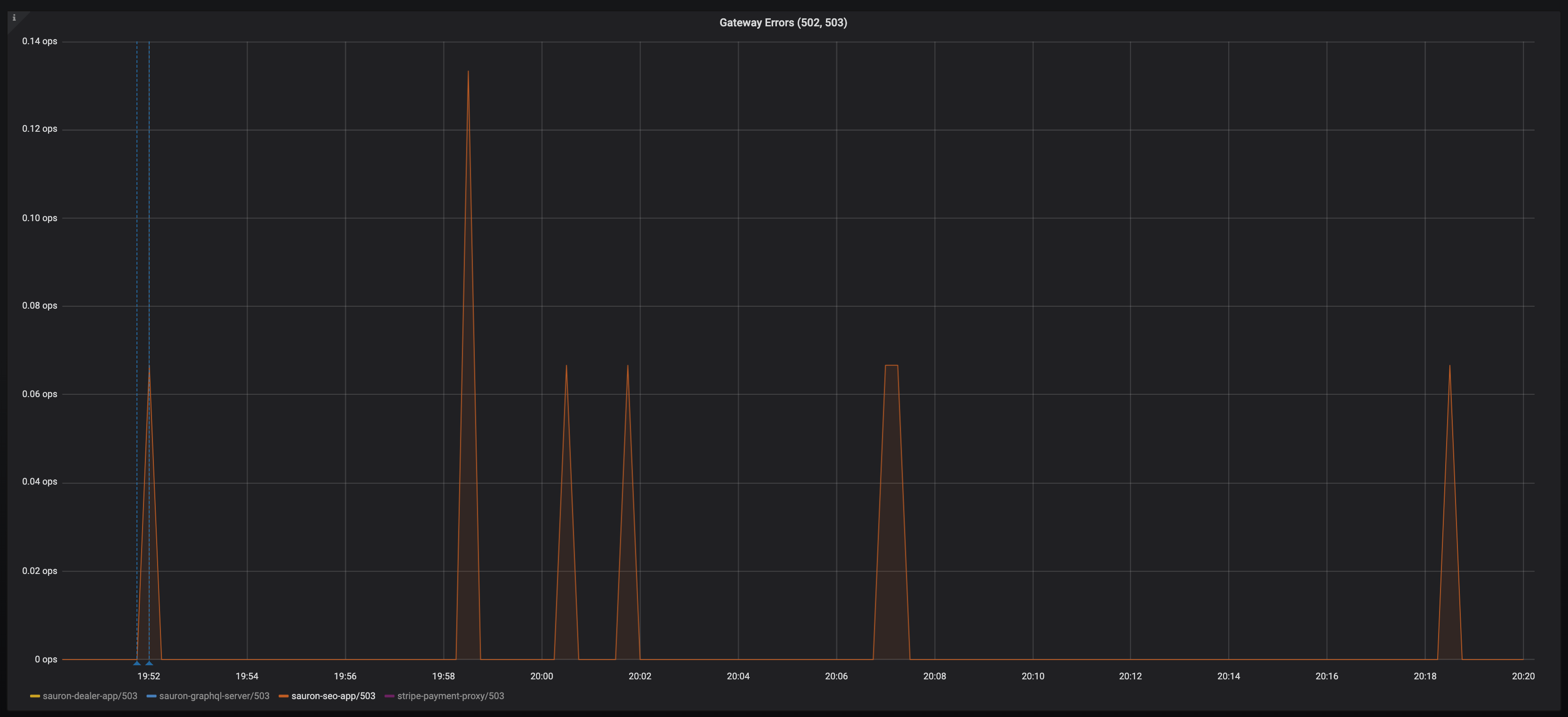
|
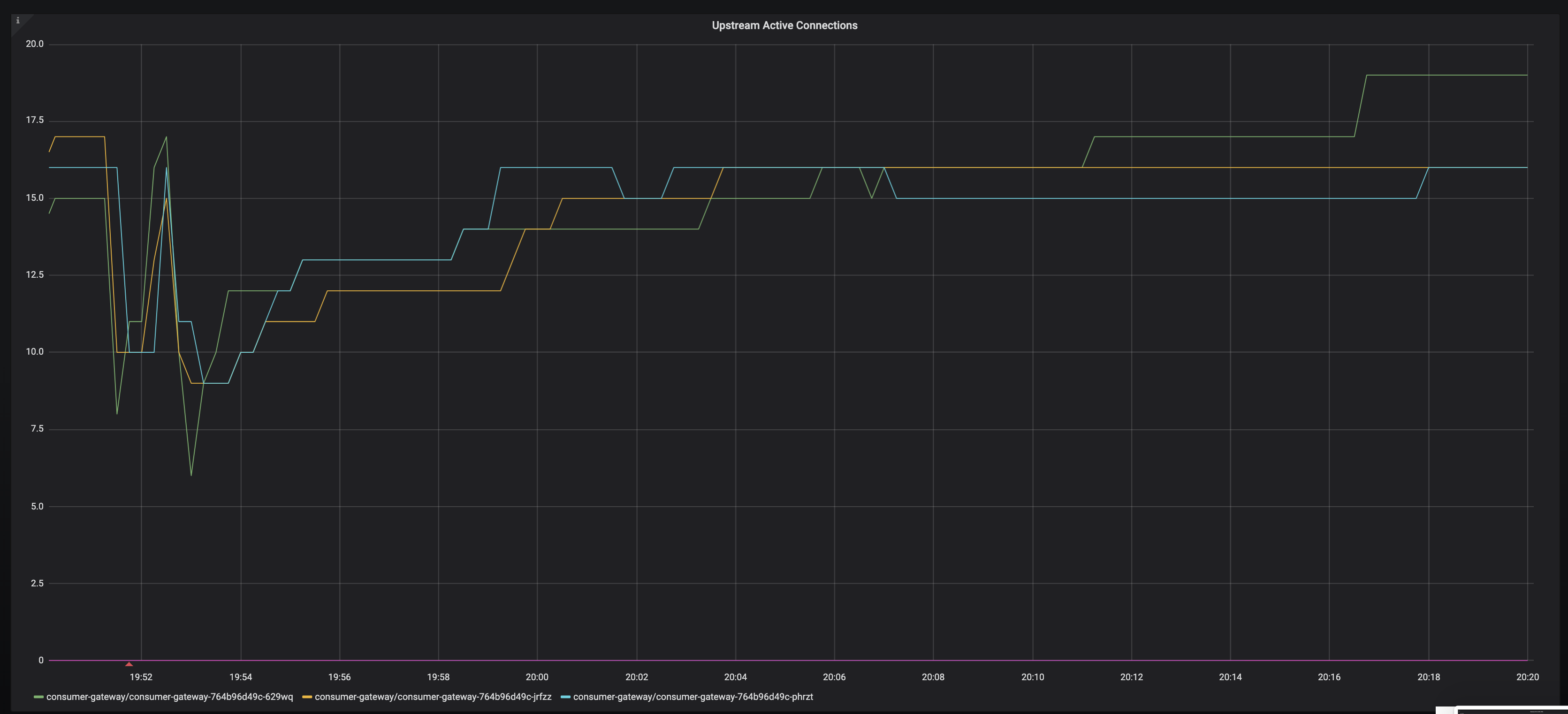
And again: |
|
@Stono could you provide logs from all involved peers (i.e. source app, source Envoy, destination Envoy, destination app) for the same 503 UC event (with a few minutes of logs before and after for context)? I'm trying to figure out which connection is terminated first and starts the chain of errors, but it's unclear from the small pieces of logs from different events, and I couldn't find any event with logs from multiple peers. You're saying that the issue is between sidecars:
But in the logs that you provided, the destination Envoy sees an upstream connection (i.e. connection to the destination app) being reset:
Similarly, the tcpdump that @chrismckean captured shows that the destination app resets connection to the destination Envoy, doesn't it? That suggests that the issue is with the connection to the destination app, and not between sidecars. |
|
@PiotrSikora i'm sorry but i'm not spending another whole day grabbing logs. Please let's just get on this call later and live debug together. You'll be able to ask questions and we can answer them real time. The really frustrating thing for me is i'm not able to replicate this in a testing environment, only on a busy cluster. Which I can show you later. |
|
Hello, logs from istio-ingressgateway:
logs from the app(verdaccio) at the same time: it happens for others services/apps as well when using istio. Istio was installed with these: If you have any questions, i'd like to fix this asap |
|
Some more logs in debug: Also noting this few lines after: |
|
istio/envoy#73 fixes the known issue. PR in testing. |
|
Along with silentdai's PR, we also discovered that applications which have a low socket timeout value will terminate connections to envoy more frequently, exacerbating the issue. I've written about it here: https://karlstoney.com/2019/05/31/istio-503s-ucs-and-tcp-fun-times The TLDR; here is that @silentdai's update (hopefully in 1.1.8) combined with an awareness and adjustment of applications with low tcp socket timeouts resolves 99.99% of our 503's. I'm going to close this issue now as it's become a bit of a novel, I'm thankful to the whole Istio team for their efforts helping get to the bottom of this one and I know there are more improvements to come from them which should make this less of a problem. |
|
I have come through both "timeout" and "upstream disconnect/reset" errors, which compose about 2% of all requests. I have no idea if we are going into the same problem. What's annoying, the "timeout" requests could be referred from the log of envoy while the "upstream disconnect" could not. |
|
Do you have node.js application behind envoy? We have resolve this with DestinationRule: |
|
Thanks for all the info @Stono; You mentioned 1.1.8 will (hopefully) have the fix for the UC 503s, I wondered if you have a link to that PR as I'm interested in the solution? The reason I ask is because we originally solved the issue by turning on envoy retries with However, we've since had a few incidents in production whereby a third party service times out and we end up creating massive cascading request chains in production (our Nodejs app also performs retries to third parties which compounds the issue 🤦♂). We therefore have no choice but to disable envoy retries but before we do this I wanted to check whether the 1.1.8 fix solved the underlying issue or if we should expect to see the UC 503s again? |
@turbotankist which version of istio are you using? The default idle timeout in Destination Rule is 1 hour after 1.4. |
|
Apologies for commenting on this long-closed issue, but I was also experiencing this problem (w/ 1.15). Because some of our traffic comes in via NodePorts directly to the service, there's no outbound rule that I can set for retries, so I ended up adding this apiVersion: networking.istio.io/v1alpha3
kind: EnvoyFilter
metadata:
name: passthrough-retries
namespace: myapp
spec:
workloadSelector:
labels:
app: myapp
configPatches:
- applyTo: HTTP_ROUTE
match:
context: SIDECAR_INBOUND
listener:
portNumber: 8080
filterChain:
filter:
name: "envoy.filters.network.http_connection_manager"
subFilter:
name: "envoy.filters.http.router"
patch:
operation: MERGE
value:
route:
retry_policy:
retry_back_off:
base_interval: 10ms
retry_on: reset
num_retries: 2After applying ☝🏻 to my service, the random 503/UC errors seem to have gone away regardless of the client or ingress method. Hopefully this is helpful to someone! |
I've noticed pretty much every application periodically gets this, a 503 with the envoy code
UC.It's retried as you can see, but it's bothering me that I cannot get to the bottom of why it is happening. My destinationrule should deal with any connection timeouts etc:
The frequency of these bothers me, because across a distributed service graph, we can get spikes in latency on client requests as a result.
The text was updated successfully, but these errors were encountered: