Jason Y. Zhang, Panna Felsen, Angjoo Kanazawa, Jitendra Malik
University of California, Berkeley
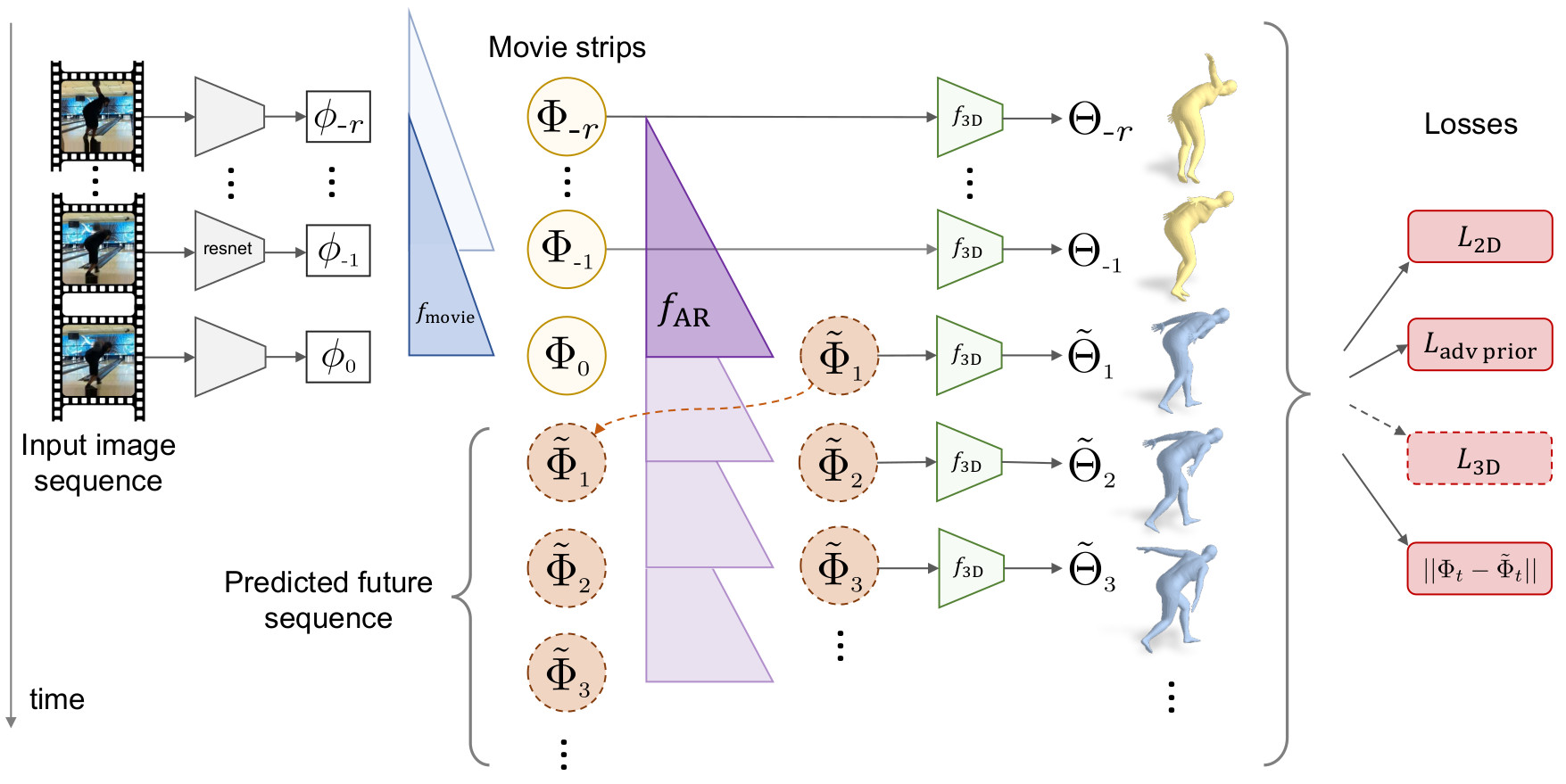
Requirements:
- Python 3 (tested on 3.6.8)
- Tensorflow (tested on 1.15)
- Pytorch for NMR (tested on 1.3.0)
- CUDA (tested on 10.0)
- ffmpeg (tested on 3.4.6)
Our code is licensed under BSD. Note that the SMPL model and any datasets still fall under their respective licenses.
virtualenv venv_phd -p python3
source venv_phd/bin/activate
pip install -U pip
pip install numpy tensorflow-gpu==1.15.0
pip install torch==1.3.0 # Make sure the wheel corresponds to your CUDA Version
pip install -r requirements.txt
cd src/external
sh install_nmr.shDownload the model weights from this Google Drive link.
You should place them in phd/models.
Download the Penn Action dataset.
You should place or symlink the dataset to phd/data/Penn_Action.
--vid_id 0104 runs the model on video 0104 in Penn Action. The public model is
conditioned on 15 images, so --start_frame 60 starts the conditioning window
at 60, and future prediction will start on frame 76. --ar_length 25 sets the
number of future predictions at 25, which is the prediction length the model
was trained on. You can also try increasing ar_length, which usually looks
reasonable until 35.
python demo.py --load_path models/phd.ckpt-199269 --vid_id 0104 --ar_length 25 --start_frame 60
For reference, this should be your output.
You can also run at multiple starting points in the same sequence.
--start_frame 0 --skip_rate 5 will run starting at frame 0, frame 5, frame 10,
etc.
python demo.py --load_path models/phd.ckpt-199269 --vid_id 0104 --ar_length 25 --start_frame 0 --skip_rate 5
For reference, this should be your output.
To run on a generic video, you will need a tracklet around the person. We extract the tracklet using PoseFlow.
Follow directions to download AlphaPose and Model Weights from https://github.com/MVIG-SJTU/AlphaPose.
Roughly, that should entail:
- Clone the repo to
src/external - Build AlphaPose using
python setup.py build develop --user - Download pre-trained weights to the specified directories. Use the ResNet50 Fast Pose from the Model Zoo.
Steps 1. and 2. can be done by running sh install_alphapose.sh in src/external
Now you should be able to run the model on any video, eg:
python demo.py --load_path models/phd.ckpt-199269 --vid_path data/0502.mp4 --start_frame 0 --ar_length 25
Coming soon