This repository is the official Pytorch implementation for CVPR2021 paper "CondenseNet V2: Sparse Feature Reactivation for Deep Networks" by Le Yang*, Haojun Jiang*, Ruojin Cai, Yulin Wang, Shiji Song, Gao Huang and Qi Tian (*Authors contributed equally).
-
Update on 2021/04/14: Release the training code on ImageNet.
-
Update on 2022/04/19: Release the visualization code.
If you find our project useful in your research, please consider citing:
@inproceedings{yang2021condensenetv2,
title={CondenseNet V2: Sparse Feature Reactivation for Deep Networks},
author={Yang, Le and Jiang, Haojun and Cai, Ruojin and Wang, Yulin and Song, Shiji and Huang, Gao and Tian, Qi},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
year={2021}
}
Reusing features in deep networks through dense connectivity is an effective way to achieve high computational efficiency. The recent proposed CondenseNet has shown that this mechanism can be further improved if redundant features are removed. In this paper, we propose an alternative approach named sparse feature reactivation (SFR), aiming at actively increasing the utility of features for reusing. In the proposed network, named CondenseNetV2, each layer can simultaneously learn to 1) selectively reuse a set of most important features from preceding layers; and 2) actively update a set of preceding features to increase their utility for later layers. Our experiments show that the proposed models achieve promising performance on image classification (ImageNet and CIFAR) and object detection (MS COCO) in terms of both theoretical efficiency and practical speed.
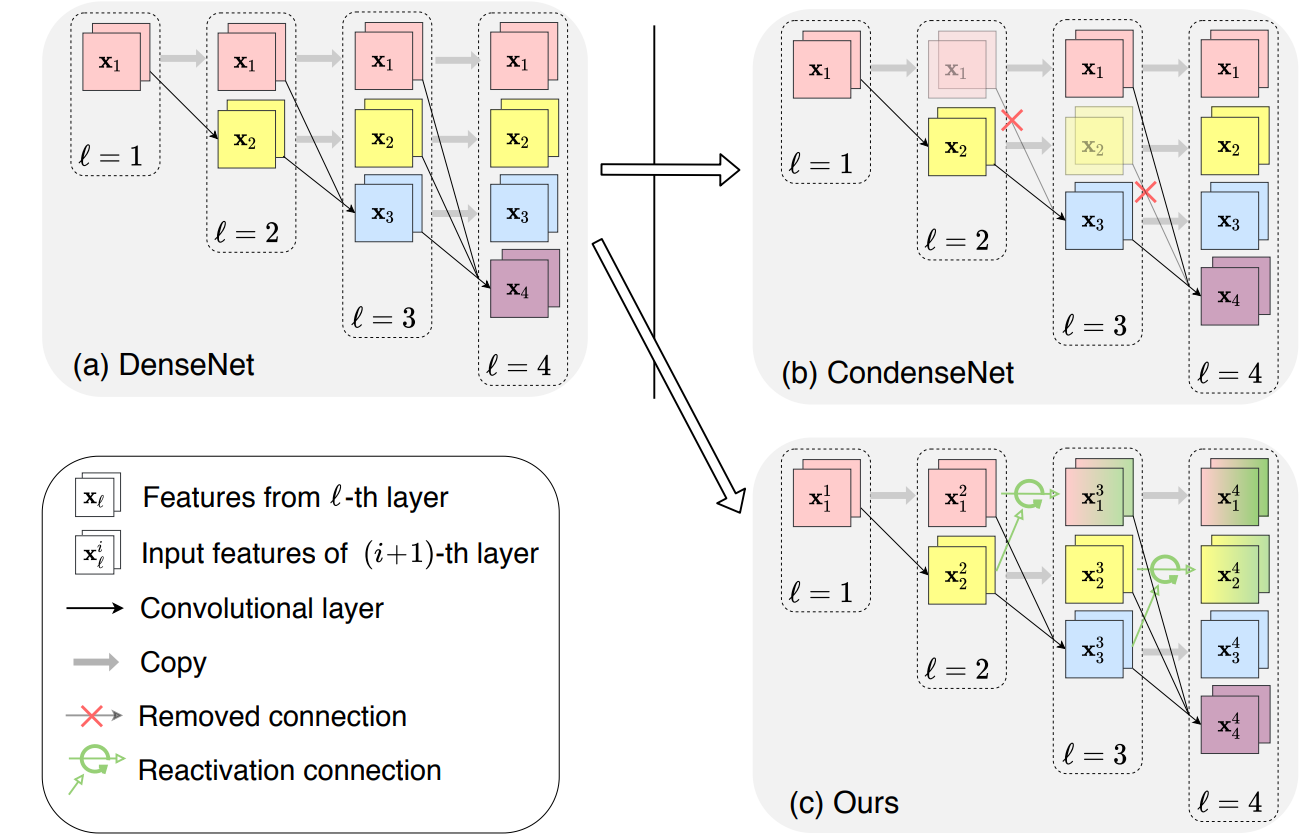
DenseNet, CondenseNet and CondenseNetV2.
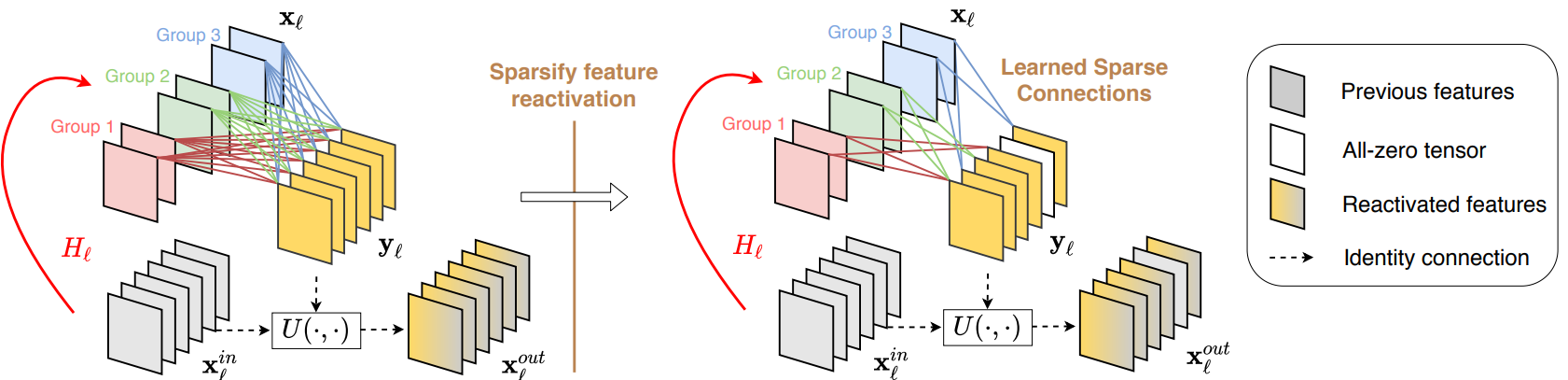
Sparse feature reactivation.
As an example, use the following command to train a CondenseNetV2-A/B/C on ImageNet
python -m torch.distributed.launch --nproc_per_node=8 train.py --model cdnv2_a/b/c
--batch-size 1024 --lr 0.4 --warmup-lr 0.1 --warmup-epochs 5 --opt sgd --sched cosine \
--epochs 350 --weight-decay 4e-5 --aa rand-m9-mstd0.5 --remode pixel --reprob 0.2 \
--data_url /PATH/TO/IMAGENET --train_url /PATH/TO/LOG_DIR
We take the ImageNet model trained above as an example.
To evaluate the non-converted trained model, use test.py to evaluate from a given checkpoint path:
python test.py --model cdnv2_a/b/c \
--data_url /PATH/TO/IMAGENET -b 32 -j 8 \
--train_url /PATH/TO/LOG_DIR \
--evaluate_from /PATH/TO/MODEL_WEIGHT
To evaluate the converted trained model, use --model converted_cdnv2_a/b/c:
python test.py --model converted_cdnv2_a/b/c \
--data_url /PATH/TO/IMAGENET -b 32 -j 8 \
--train_url /PATH/TO/LOG_DIR \
--evaluate_from /PATH/TO/MODEL_WEIGHT
Note that these models are still the large models after training. To convert the model to standard group-convolution version as described in the paper, use the convert_and_eval.py:
python convert_and_eval.py --model cdnv2_a/b/c \
--data_url /PATH/TO/IMAGENET -b 64 -j 8 \
--train_url /PATH/TO/LOG_DIR \
--convert_from /PATH/TO/MODEL_WEIGHT
| Model | FLOPs | Params | Top-1 Error | Converted Model | Unconverted Model |
|---|---|---|---|---|---|
| CondenseNetV2-A | 46M | 2.0M | 35.6 | Tsinghua Cloud / Google Drive | - |
| CondenseNetV2-B | 146M | 3.6M | 28.1 | Tsinghua Cloud / Google Drive | - |
| CondenseNetV2-C | 309M | 6.1M | 24.1 | Tsinghua Cloud / Google Drive | Tsinghua Cloud / Google Drive |
The detection experiments are conducted based on the mmdetection repository. We simply replace the backbones of FasterRCNN and RetinaNet with our CondenseNetV2s.
| Detection Framework | Backbone | Backbone FLOPs | mAP |
|---|---|---|---|
| FasterRCNN | ShuffleNetV2 0.5x | 41M | 22.1 |
| FasterRCNN | CondenseNetV2-A | 46M | 23.5 |
| FasterRCNN | ShuffleNetV2 1.0x | 146M | 27.4 |
| FasterRCNN | CondenseNetV2-B | 146M | 27.9 |
| FasterRCNN | MobileNet 1.0x | 300M | 30.6 |
| FasterRCNN | ShuffleNetV2 1.5x | 299M | 30.2 |
| FasterRCNN | CondenseNetV2-C | 309M | 31.4 |
| RetinaNet | MobileNet 1.0x | 300M | 29.7 |
| RetinaNet | ShuffleNetV2 1.5x | 299M | 29.1 |
| RetinaNet | CondenseNetV2-C | 309M | 31.7 |
| Model | FLOPs | Params | CIFAR-10 | CIFAR-100 |
|---|---|---|---|---|
| CondenseNet-50 | 28.6M | 0.22M | 6.22 | - |
| CondenseNet-74 | 51.9M | 0.41M | 5.28 | - |
| CondenseNet-86 | 65.8M | 0.52M | 5.06 | 23.64 |
| CondenseNet-98 | 81.3M | 0.65M | 4.83 | - |
| CondenseNet-110 | 98.2M | 0.79M | 4.63 | - |
| CondenseNet-122 | 116.7M | 0.95M | 4.48 | - |
| CondenseNetV2-110 | 41M | 0.48M | 4.65 | 23.94 |
| CondenseNetV2-146 | 62M | 0.78M | 4.35 | 22.52 |
yangle15 at mails.tsinghua.edu.cn
jhj20 at mails.tsinghua.edu.cn
Any discussions or concerns are welcomed!
Our work is inspired by CondenseNet: An Efficient DenseNet using Learned Group Convolutions and we use the code in the official repository of CondenseNet.
Thanks to Ross Wightman for building a powerful Pytorch Image Models repository, our training code is forked from his repository.