FP16 speed benchmark #204
Comments
|
Would love to help. I am running a Titan V on Win 10 with the following specs
I guess i just run
is that correct? Also, should the benchmark be run with the chinese language model as in |

|
Thanks a lot for your initiative! Yes, correct. Just add No, you don't need Chinese BERT at all. You can use whatever BERT you like, as the speed is measured on the sample-level not on the token-level, changing BERT language should not affect the speed. |
|
Thanks for the clarifications! The benchmark is currently running, however i had to do some additional steps, which i will shortly outline in the following, to determine whether i introduced inconsistencies. Why not just run benchmark.py as is?Since So why is this a problem for benchmark.py?The server is started from within benchmark.py, which did not work for me. I guess this is related to the previous point. https://github.com/hanxiao/bert-as-service/blob/9a5b015c1b9d925d88769d93eb17704d5ddb8691/benchmark.py#L70 Cool. How did you work around that?I commented out the server starting and closing procedures in the experimental loop in With the running server i then proceeded to run benchmark.py, which is going well thus far. Any trouble caused by this?
Thanks! Also, for clarification, i used the version of benchmark.py from commit 9a5b015 but hard coded the Edit: fixed formatting. UpdateBased on the comparison of the obtained results with the results posted in the readme i am now pretty certain that the approach i took did skew the results (now that i think about it again it makes a lot of sense, since parameters like Speed wrt.
|
client_batch_size |
seqs/s |
|---|---|
| 1 | 58 |
| 4 | 129 |
| 8 | 163 |
| 16 | 195 |
| 64 | 213 |
| 256 | 216 |
| 512 | 225 |
| 1024 | 229 |
| 2048 | 230 |
| 4096 | 232 |
Speed wrt. max_batch_size
max_batch_size |
seqs/s |
|---|---|
| 32 | 229 |
| 64 | 231 |
| 128 | 230 |
| 256 | 231 |
| 512 | 233 |
Speed wrt. max_seq_len
max_seq_len |
seqs/s |
|---|---|
| 20 | 231 |
| 40 | 231 |
| 80 | 225 |
| 160 | 232 |
| 320 | 230 |
Speed wrt. num_client
num_client |
seqs/s |
|---|---|
| 2 | 120 |
| 4 | 59 |
| 8 | 29 |
| 16 | 14 |
| 32 | 7 |
Speed wrt. pooling_layer
pooling_layer |
seqs/s |
|---|---|
| [-1] | 233 |
| [-2] | 233 |
| [-3] | 233 |
| [-4] | 233 |
| [-5] | 234 |
| [-6] | 233 |
| [-7] | 233 |
| [-8] | 233 |
| [-9] | 233 |
| [-10] | 233 |
| [-11] | 233 |
| [-12] | 233 |
|
Thanks a lot for the detailed investigation. I did improve benchmark.py in 1.7.7, now it's a part of the CLI. After btw, the broken CLI link on Windows (#194) is also fixed. |
|
Besides that benchmark script, FP32encoding 717 strs in 0.41s, speed: 1729/s
encoding 7887 strs in 3.39s, speed: 2328/s
encoding 15057 strs in 6.39s, speed: 2357/s
encoding 22227 strs in 9.59s, speed: 2318/s
encoding 29397 strs in 12.92s, speed: 2275/s
encoding 36567 strs in 16.66s, speed: 2194/s
encoding 43737 strs in 20.97s, speed: 2086/s
encoding 50907 strs in 24.30s, speed: 2094/s
encoding 58077 strs in 27.79s, speed: 2089/s
encoding 65247 strs in 31.29s, speed: 2085/s
encoding 72417 strs in 34.79s, speed: 2081/s
encoding 79587 strs in 38.11s, speed: 2088/s
encoding 86757 strs in 41.65s, speed: 2082/s
encoding 93927 strs in 44.96s, speed: 2089/s
encoding 101097 strs in 48.21s, speed: 2096/s
encoding 108267 strs in 51.68s, speed: 2094/s
encoding 115437 strs in 55.16s, speed: 2092/s
encoding 122607 strs in 58.38s, speed: 2100/s
encoding 129777 strs in 62.14s, speed: 2088/s
encoding 136947 strs in 65.44s, speed: 2092/sFP16 (
|
|
got some new result |
|
After updating to the latest release the CLI works very well, thank you! Benchmark Results with Titan V and
|
client_batch_size |
samples/s |
|---|---|
| 1 | 60 |
| 16 | 192 |
| 256 | 209 |
| 4096 | 231 |
max_batch_size |
samples/s |
|---|---|
| 8 | 194 |
| 32 | 226 |
| 128 | 232 |
| 512 | 231 |
max_seq_len |
samples/s |
|---|---|
| 32 | 250 |
| 64 | 216 |
| 128 | 178 |
| 256 | 124 |
num_client |
samples/s |
|---|---|
| 1 | 231 |
| 4 | 61 |
| 16 | 16 |
| 64 | 3 |
pooling_layer |
samples/s |
|---|---|
| [-1] | 209 |
| [-2] | 227 |
| [-3] | 250 |
| [-4] | 277 |
| [-5] | 313 |
| [-6] | 357 |
| [-7] | 417 |
| [-8] | 492 |
| [-9] | 600 |
| [-10] | 789 |
| [-11] | 1116 |
| [-12] | 1454 |
I'll update with fp32 results once available.
Benchmark Results with Titan V and fp32After reviewing the results i think i maybe need to rerun the -fp16 benchmark skript, as it seems something was going on while it has been running that slowed down the process. Any thoughts?
|
|
Hi @davidlenz thanks for your time and effort on benchmarking this. Your result suggests that your GPU/driver may not support FP16 instruction. Before running into another exhaustive benchmark, could you do a quick test by using
then copy-paste the client output here? Thanks a lot! |
|
Looks like you made the right guess. Thus, i should probably update the drivers to enable FP 16 instructions?
|
google-research/bert#378
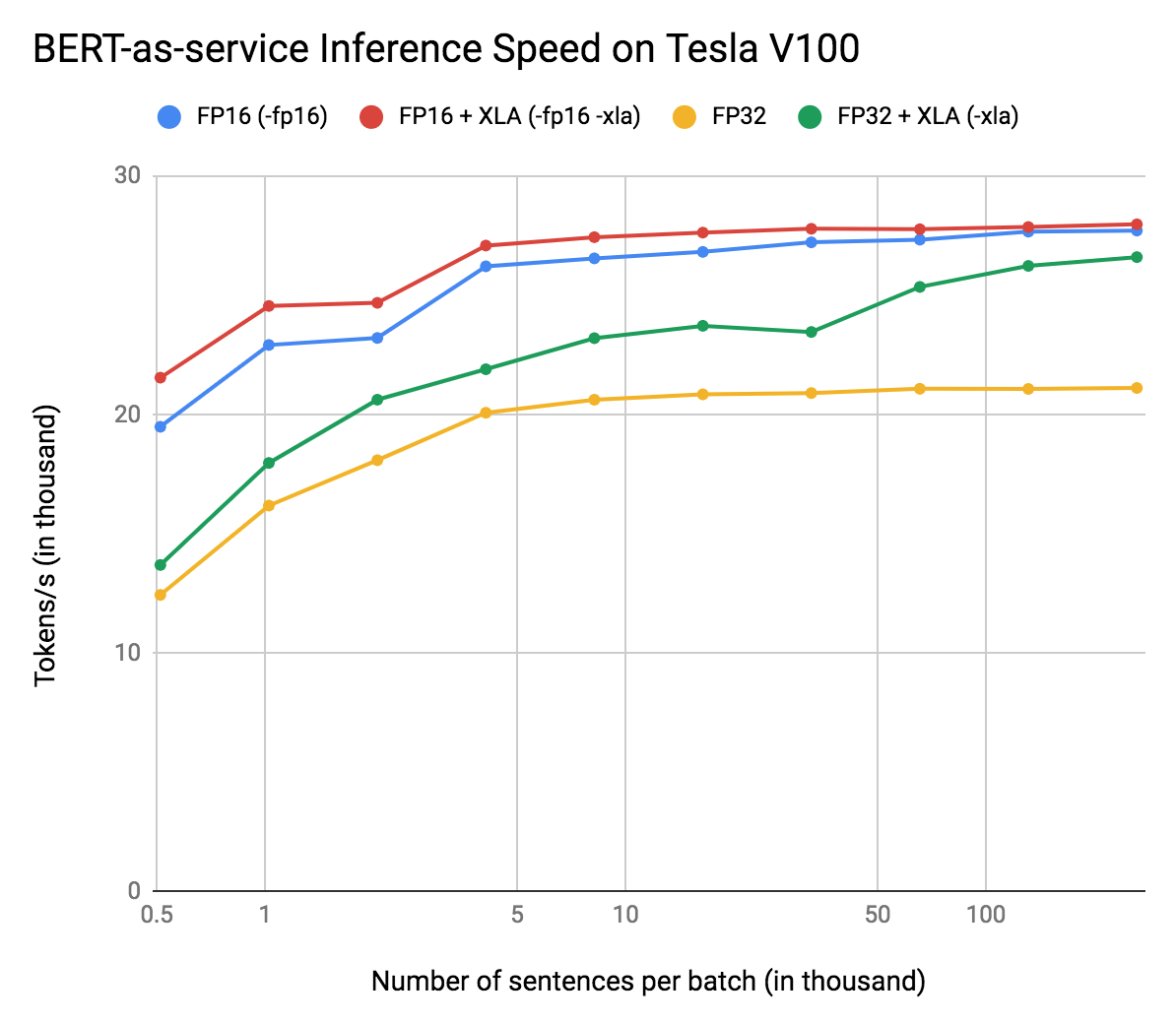
Since 1.7.5 of
bert-as-servicea new option-fp16is added to the CLI, which loads a pretrained/fine-tuned BERT model (originally in FP32) and converts it to a FP16 frozen graph. As a result the model size and the memory footprint reduces 40% comparing to the FP32 counterpart. On the other hand, the speedup highly depends on the device, GPU driver, CUDA, etc. I currently don't have such environment to measure the speedup with-fp16.If someone has a half-precision enabled device, it would be really awesome if you can test the performance and report it here or in
bert-as-serviceissues. Thanks in advance! 🙇The text was updated successfully, but these errors were encountered: