Home
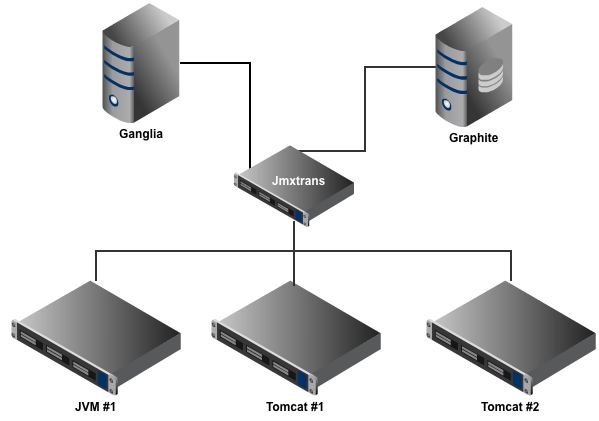
jmxtrans is a tool which allows you to connect to any number of Java Virtual Machines (JVMs) and query them for their attributes without writing a single line of Java code. The attributes are exported from the JVM via Java Management Extensions (JMX). Most Java applications have made their statistics available via this protocol and it is possible to add this to any codebase without a lot of effort. If you use the SpringFramework for your code, it can be as easy as just adding a couple of annotations to a Java class file.
The query language is based on the easy to write JSON format. This allows non-programmers access to JMX without having to know how to write Java. That makes this tool perfect for the busy Ops person.
The results of the queries are processed by Java classes called OutputWriters. These are a bit more involved to write because generally it means integrating Java code with a third party tool such as Graphite or Ganglia. Out of the box, jmxtrans supports several output writers and we are encouraging others to suggest new ideas by submitting requests to the issue tracker.
There are two primary modes for using jmxtrans. The first is to use the JmxTransformer engine included with the distribution. This engine will read a directory of .json files, process them and then create 'jobs' to execute on a cron-like schedule. Each job maps to a server that you would like to query jmx attributes on. Therefore, you can setup a complex query schedule for each server by setting the cronExpression field on the Server object (by default it is every minute).
For a given json file, there can be an unlimited number of servers defined within it. The servers are the JVMs that you want to gather stats from and are defined by a hostname, port, username and password.
Within each server, there can be an unlimited number of JMX queries executed against it. Each Query executed against a server can output its results using any number of OutputWriters. jmxtrans includes several different OutputWriters that you can use.
The [Queries] expect an object ("java.lang.type=Memory"), zero or more attributes ["HeapMemoryUsage", "NonHeapMemoryUsage"] and one or more OutputWriters to send the Results of the query to. If you don't specify any attributes, then it will get all of them. You can also specify a star within an object name to query dynamically generated object names.
The JmxTransformer engine is fully multithreaded. You specify the maximum number of threads that you want to start up for each part of the application. By default, up to 10 servers are queried at the same time. It is also possible to have multiple threads for each query against a server. Thus, you can specify that you want 10 threads to handle your 50 servers. Each one of your servers may have defined 10 queries. You can therefore, set the numQueryThreads to 2 to execute two queries against a server at the same time.
There are two sides to JmxTransformer. The input is the connection to the JMX server running in a JVM. The output is to OutputWriters. As necessary, both sides make use of connection object pools to maintain socket connections to both the input and output.
On a side note, I've heard from a few people now who are using it to monitor clusters of hundreds of machines. If you have even larger clusters, please let me know!
The second mode for jmxtrans is to act as an API to build your own application for pulling data from JMX and writing it out. The Engine was written on top of this API. The Engine is how I'd use this project, but maybe you have other ideas so that is fully supported by allowing you to write your own engine.
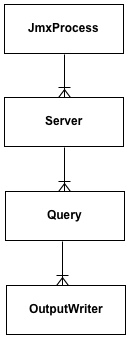
jmxtrans uses the amazing Jackson library to parse json data into a Java object model. This model is primarily represented by the JmxProcess, Server, Query, Result objects. This means that if you know a bit of java, it is possible to fully customize your own usage of jmxtrans to however you see fit.
The core of the api is implemented as mostly static methods in the JmxUtils class. You pass in a Server object with a bunch of Queries and get back a list of Results. How you process those results is up to you.
This also means that you can use Java'ish languages like Jython, Scala and Groovy to script jmxtrans to do whatever you want.
Take a look at the included example classes. They show how you can either read a json file from disk into the object model or create the object model by hand and execute it. There is also examples of using wildcards, which jmxtrans fully supports with JDK 6.