Home
![]()
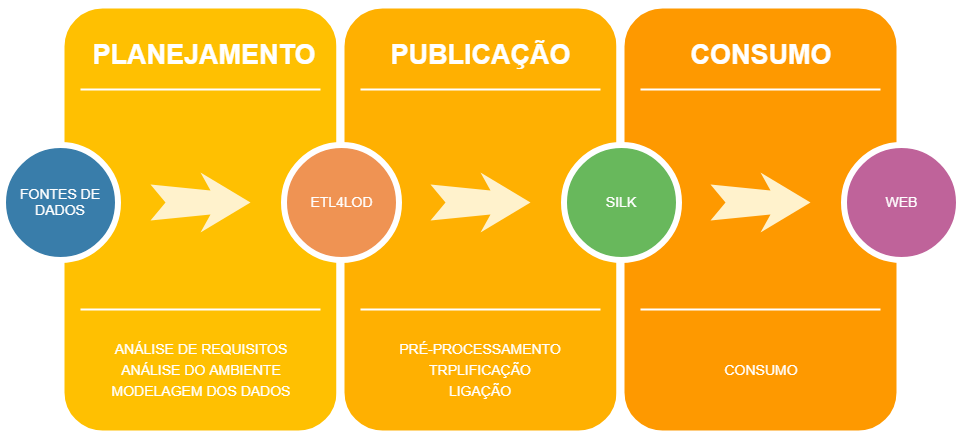
O objetivo do ETL4LOD é fornecer uma framework amigável ao usuário que permita a manutenção da etapa de publicação do ciclo de vida de dados do tipo LOD.
A figura 1 apresenta as principais etapas envolvidas nesse ciclo de vida:
Para garantir uma interface que seja amigável ao usuário e tirar proveito de funcionalidades já existentes, o ETL4LOD foi criado como uma extensão ao Pentaho Data Integration, também conhecido como Kettle.
Uma extensão do Kettle é um conjunto de plugins, ou steps, desenvolvidos em Java que são integrados a ferramenta e podem ser usados em conjunto com os outros steps já existentes. Portanto, o ELT4LOD é um conjunto de plugins voltados especificamente para o trabalho com Linked Data.
A mecânica drag&drop contida no Kettle garante uma ótima usabilidade para o usuário final, que precisa apenas selecionar entre uma lista de opções que se aplicam ao processo sendo criado, e arrastá-la para a área de trabalho do Kettle para uso. Já a existência de steps feitos especificamente para processos de ETL no Kettle permite que o processo de publicação do ciclo de vida de dados ligados seja feito todo dentro do Kettle.
Em sua versão inicial, o ETL4LOD foi criado para trabalhar com a versão 4.4.0 do Kettle. O objetivo deste trabalho é dualmente atualizar o ETL4LOD e suas dependências para trabalhar na versão mais recente do Kettle, e melhorar a usabilidade e funcionalidades já existentes na ferramenta.
Mais informações sobre o que foi atualizado podem ser encontradas em changelog.
O ciclo de vida para publicação de dados do tipo LOD na web é dividido em três etapas: pré-processamento, triplificação e ligação. Os steps criados para o ETL4LOD+ se encaixam em sua maioria na etapa de triplificação, enquanto que os steps já existentes no Kettle são usados na etapa de pré-processamento.
A etapa de pré-processamento é a que envolve o trabalho sobre um dado bruto, geralmente um arquivo csv, texto ou excel, visando tirar as inconsistências desses dados e prepará-los para o processo de triplificação.
O pré-processamento de dados no Kettle pode ser subdivido em duas etapas: entrada de dados e trabalho sobre os dados, que no kettle é traduzido em um conjunto de pastas: Input, Output, Transform, Flow, Scripting, Lookup e Joins. Essas pastas podem ser consideradas as mais importantes para todo o processo de limpeza de dados feitos no Kettle, envolvendo ou não a triplificação de dados.
A entrada de dados envolve steps que sejam usados para carregar os dados necessários para o Kettle, estejam eles em arquivos de texto, xml, csv ou em um banco de dados. Os steps mais usados para o trabalho com dados interligados são:
| Step | Descrição |
|---|---|
 |
Leitura de arquivos de quaisquer arquivos de texto |
 |
Leitura de arquivos de texto separados por vírgula |
 |
Leitura de uma tabela num banco de dados |
 |
Leitura de um arquivo xls ou xlst |
 |
Leitura de um arquivo json ou json-ld |
 |
Leitura de arquivos xml, incluindo owl ou rdf |
Os steps de entrada de dados geralmente possuem um step correspondente para a saída de dados, na pasta Output, que permite salvar os dados naquele formato. Como o processo de triplificação geralmente envolve salvar os dados num endpoint sparql ou em rdf não falaremos sobre todos esses steps de saída.
Nesta categoria se encontram os steps que servem para modificar as entradas em um fluxo já existente do Kettle. Abaixo seguem alguns dos steps mais usados desta categoria:
| Step | Descrição |
|---|---|
| Permite que operações númericas sejam feitas entre duas colunas do fluxo, como a soma entre a coluna A e a coluna B (A+B). | |
| Permite substituir uma string (ou substring) numa coluna A com um valor de outro campo ou um valor fixo dado um regex do kettle. Esse step é útil para remover, por exemplo, tudo o que não é caracter A-Za-z de uma String. | |
| Permite renomear colunas, adicionar metadados a colunas, ou remover colunas do fluxo. | |
| Ordena todo o fluxo por uma coluna | |
| Quebra uma coluna em N outras colunas dado um delimitador. Pode ser usado, por exemplo, para separar 20/10/2018 em 20 10 2018 quando quebrados pelo delimitador / | |
| Permite aplicar operações como converter para lowercase em Strings | |
| Permite extrair uma substring de uma string no fluxo |
Nesta categoria estão as condicionais do Kettle. Elas servem para separar ou para o fluxo dependendo de alguma condição específica.
| Step | Descrição |
|---|---|
| Força uma transformação a terminar quando chega nesse step. É útil para parar uma transformação caso uma condição seja verdadeira. | |
| Não faz nada. É bom para testes de preview ou para juntar fluxos diferentes. | |
| É o if-then-else do Kettle | |
| É o switch case do Kettle |
Nesta categoria estão os steps que permitem a execução de um script em alguma linguagem aceita pela Kettle, como SQL ou javascript.
| Step | Descrição |
|---|---|
| É usado para criar fórmulas com Strings ou números. É útil para adicionar "<>" as URI do fluxo. | |
| É um step que só deve ser usado como último recurso por ser lento. Permite executar um script javascript nas colunas do fluxo. |
Nesta categoria encontram-se os steps para busca de dados em bancos, fluxos ou páginas da web.
| Step | Descrição |
|---|---|
| Faz um select em uma tabela do banco de dados e retorna as colunas selecionadas para o fluxo |
Nesta categoria estão os steps para unir dois fluxos de entrada em um de saída.
| Step | Descrição |
|---|---|
| Faz literalmente um join (LEFT, FULL, RIGHT) entre duas tabelas ou fluxos do Kettle |
Nesta categoria estão todos os plugins criados para o ETL4LOD+ que servem para criação de dados conectados.
| Plugin | Manual | Descrição |
|---|---|---|
| link | Anota uma tripla com termos de vocabulários e ontologias | |
| link | Permite trabalhar com o vocabulário DataCube | |
| link | Mapeia triplas RDF, onde o objeto é um valor literal | |
| link | Analisa um Grafo RDF de entrada e anota suas triplas com um nível semântico | |
| link | Executa queries do tipo CONSTRUCT ou DESCRIBE num Endpoint SPARQL e retorna um grafo RDF | |
| link | Converte um grafo RDF em triplas no formato N-Triples | |
| link | Faz a ligação de arquivos e sparql endpoints usando o silk | |
| link | Converte sentenças RDF em NTriple | |
| link | Mapeia triplas RDF, onde o objeto de saída é uma URI | |
| link | Carrega triplas RDF em um banco de triplas como o Vituoso | |
| link | Extrai dados de um SPARQL Endpoint | |
| link | Executa uma query SPARQL | |
| link | Gerencia e busca ontologias e vocabulários | |
| link | Converte arquivos .csv para .ttl |
Na criação de fluxos no Kettle, algumas boas práticas podem ser adotadas:
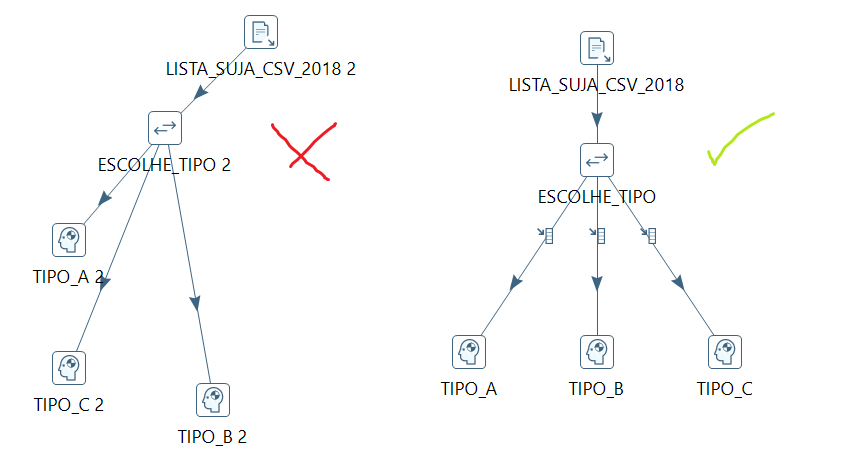
- Sempre nomeie os steps utilizados no seu fluxo. Cada step no Kettle é como uma variável num código, e um código legível precisa ter suas variáveis bem nomeadas. Portanto, é importante sempre dar um nome semântico aos steps utilizados.

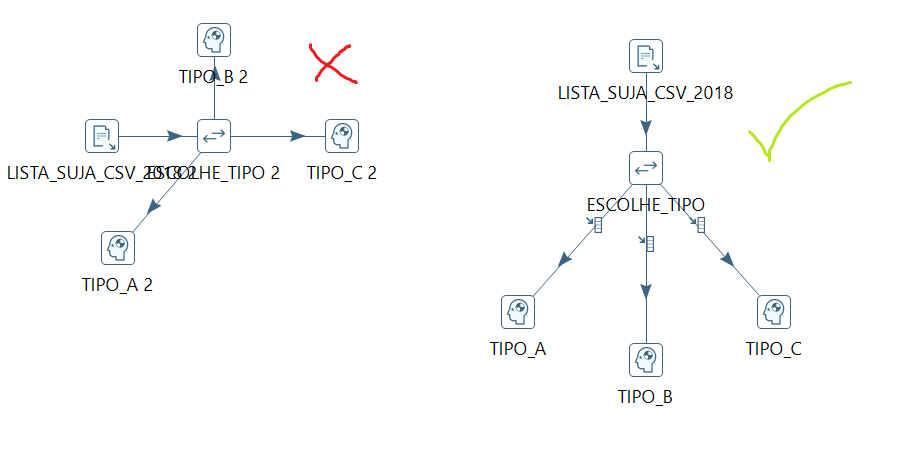
- Fluxos devem preferencialmente ir de cima para baixo. É uma boa prática do kettle que todas as setas do seu fluxo sempre apontem para baixo. Dessa forma, a leitura do .ktr fica mais fluída e fica mais simples saber de onde o fluxo vem e para onde o fluxo vai.
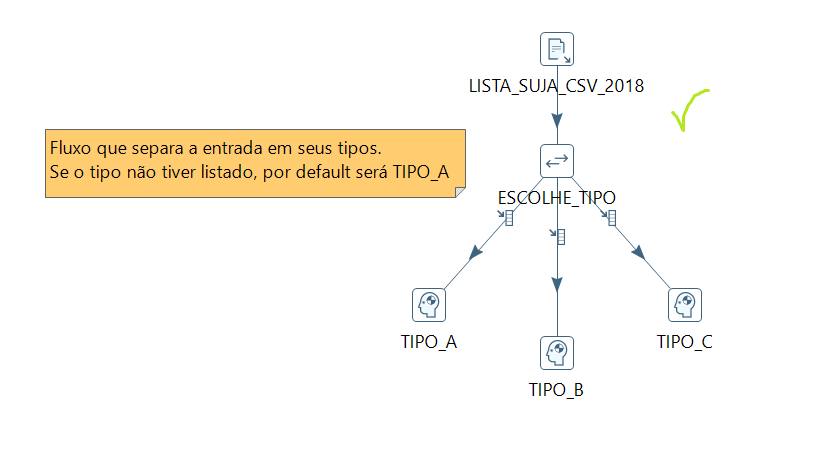
- Quando necessário, use a caixa de comentários do Kettle para explicar o seu fluxo. Alguns fluxos ficam inevitavelmente complexos. Por esse motivo, o Kettle permite que notas sejam adicionadas ao seu fluxo (só clicar com o botão direito no ktr). Essas notas podem ser usadas para explicar um pedaço complexo do seu fluxo ou organizar melhor o fluxo.
- Use variáveis do Kettle. O Kettle permite a adição de variáveis de ambiente que devem ser usadas quando o seu fluxo possuir algum input/output específico da sua máquina ou execução. Se um fluxo possui uma entrada de dados, não se deve colocar, por exemplo, o caminho /dados/rdf/ontologia.owl no step. Esse tipo de dado que precisa ser substituído dependendo de onde o ktr é executado deveria ficar em uma variável ${OWLINPUT}. Dessa forma quando outra pessoa tiver de executar o seu fluxo não será necessário alterar nenhum step, somente as variáveis do ambiente.
- Use a opção de alinhar e distribuir do Kettle. O Kettle possui a opção no botão direito do mouse de alinhar/distribuir os steps selecionados. Essa função é boa para ordenar os steps para que eles sempre fiquem na mesma posição e com a mesma quantidade de espaço entre eles.