13. Abstraction of Process
In this chapter, we will see how we actually define a user process - the basic unit of an isolated running entity. The essential idea is to virtualize the CPU and allow multiple processes to time-share the CPU.
If you study the OSTEP book, you will notice that the order is reversed here: we first build support for virtualizing the memory (paging + heap memory allocator), then implement the support for virtualizing the CPU (user processes + scheduling). This is due to practical issues: concretizing the abstraction of processes requires a functioning virtual memory system and a way to allocating chunks of memory on the kernel heap.
This chapter shows the basic data structures needed to support processes and the steps to kick off the first process in our system, named init, temporarily in kernel mode execution.
Scan through them before going forth:
- Process data structures and the context switch snippet of xv6 ✭
- Processes and Direct Execution chapters of the OSTEP book: abstraction of process, how processes run
So far, our kernel is still in its booting phase and is using the 16KiB booting stack for doing the initialization stuff. We now move towards a user-mode/kernel-mode execution pattern with the concept of processes. A process is the basic unit of a running entity in an operating system, e.g., a shell, a GUI desktop, a text dumper, a web browser, etc.
To execute a program as a process, the program gets loaded into memory from a compiled executable file (in some executable format recognizable by the OS, e.g., ELF) on some persistent storage (figure 4.1 from OSTEP by Remzi & Andrea):
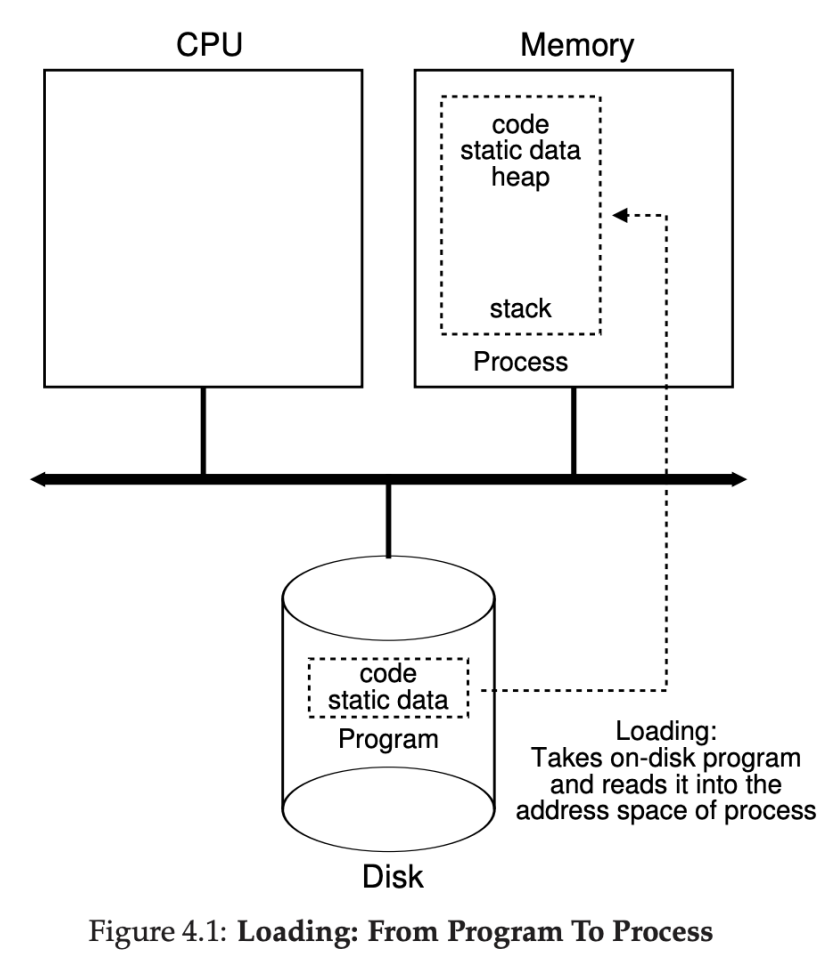
The kernel needs to maintain the following set of information for each process in its process control block (PCB) ✭:
- Address space: each process runs in its separate virtual address space (which could be very sparse and large); the kernel needs to allocate some space on kernel heap to hold the process's page directory/tables, and also take care of handling page faults and allocating frames for valid pages.
- Context registers: the saved values of CPU registers the last time the process gets de-scheduled. (Explanation of time-sharing and context switching in later chapters.)
- Kernel stack: the process normally runs in user mode, but when it wants to do something that involves shared resource (e.g., any kind of I/O such as printing to terminal, getting its process ID, allocating more memory beyond what has been mapped for it, etc.), it does a system call (software interrupt); or sometimes it gets interrupted by hardware (hardware interrupt), e.g., the timer. It changes to kernel mode execution with kernel privileges, when it uses a kernel function stack allocated somewhere on kernel heap. (Explanation of execution mode and system calls in later chapters.)
- I/O-related information in persistence chapters.
The global data structure holding all the PCBs is called the process table (ptable).
We assume that Hux only supports a single-core CPU. Running on multiple CPUs or single multiprocessors (SMPs) definitely makes it more challenging. It involves careful locking and coordination to get things right. See xv6 if interested in what a minimal SMP kernel looks like.
Let's begin by defining the PCB struct format. Code @ src/process/process.h:
/** Max number of processes at any time. */
#define MAX_PROCS 32
/** Each process has a kernel stack of one page. */
#define KSTACK_SIZE PAGE_SIZE
/**
* Process context registers defined to be saved across switches.
*
* PC is the last member (so the last value on stack not being explicitly
* popped in `context_switch()), because it will then be used as the
* return address of the snippet.
*/
struct process_context {
uint32_t edi;
uint32_t esi;
uint32_t ebx;
uint32_t ebp; /** Frame pointer. */
uint32_t eip; /** Instruction pointer (PC). */
} __attribute__((packed));
typedef struct process_context process_context_t;
/** Process state. */
enum process_state {
UNUSED, /** Indicates PCB slot unused. */
INITIAL,
READY,
RUNNING,
BLOCKED,
TERMINATED
};
typedef enum process_state process_state_t;
/** Process control block (PCB). */
struct process {
char name[16]; /** Process name. */
int8_t pid; /** Process ID. */
process_context_t *context; /** Registers context. */
process_state_t state; /** Process state */
pde_t *pgdir; /** Process page directory. */
uint32_t kstack; /** Bottom of its kernel stack. */
// ... (TODO)
};
typedef struct process process_t;
/** Extern the process table to the scheduler. */
extern process_t ptable[];
void process_init();The process table is simply an array of MAX_PROCS PCB slots @ src/process/process.c:
/** Process table - list of PCB slots. */
process_t ptable[MAX_PROCS];
/** Next available PID value, incrementing overtime. */
static int8_t next_pid = 1;
/** Fill the ptable with UNUSED entries. */
void
process_init(void)
{
for (size_t i = 0; i < MAX_PROCS; ++i)
ptable[i].state = UNUSED;
next_pid = 1;
}We also need a structure that holds the state information of the CPU. The most important CPU state is the scheduler context - a special context that runs the CPU scheduler, which is an endless loop function always picking the next process to run.
Define the CPU state struct @ src/process/scheduler.h:
/** Per-CPU state (we only have a single CPU). */
struct cpu_state {
/** No ID field because only supporting single CPU. */
process_context_t *scheduler; /** CPU scheduler context. */
process_t *running_proc; /** The process running or NULL. */
// ... (TODO)
};
typedef struct cpu_state cpu_state_t;
void cpu_init();Since we are only supporting a single CPU, there is only one instance of this struct (instead of an array). Code @ src/process/scheduler.c:
/** Global CPU state (only a single CPU). */
static cpu_state_t cpu_state;
/** Initialize CPU state. */
void
cpu_init(void)
{
cpu_state.scheduler = NULL; /** Will be set at context switch. */
cpu_state.running_proc = NULL;
}We will make a simple context_switch assembly snippet. To be precise, a context switch is the composition of the following steps ✭:
- Old context's EIP (PC) value will be implicitly put on current active stack when the current running entity calls
context_switch()function; - Save the callee-saved register values (
edi,esi,ebx,ebp) onto the current active stack (for now, we are in the booting stack - the scheduler uses this stack); - Interpret the above-mentioned five register values (
eip,edi, ...ebp) as aprocess_contextstruct, save its address (current ESP) to the current entity's PCB (the scheduler is special since it is not exactly a process - the pointer is stored in the CPU state struct); - Switch ESP to be the pointer to the new context;
- Pop out the four callee-saved register values;
- Call
ret, which implicitly uses the value at stack bottom - the new context's EIP - as the return address, so we start/resume executing the new entity.
The assembly code logic is borrowed from xv6. Code @ src/process/switch.s:
.global context_switch
.type context_switch, @function
context_switch:
movl 4(%esp), %eax /** old */
movl 8(%esp), %edx /** new */
/** Save callee-saved registers of old (notice order). */
pushl %ebp
pushl %ebx
pushl %esi
pushl %edi
/** Swtich stack to the new one. */
movl %esp, (%eax)
movl %edx, %esp
/** Load callee-saved registers of new (notice order). */
popl %edi
popl %esi
popl %ebx
popl %ebp
/** Return to new's EIP (so not being popped). */
retIn the design of Hux, any context switch is a switch from a kernel stack and to a kernel stack (with a special case of the booting stack, which is the stack used by the scheduler). Any process must be in kernel mode before performing a switch to someone else; in turn, when we switch to any process, we must be in its kernel stack.
With this context switch snippet, we can build a very simple scheduler (which we will definitely improve later). It endlessly loops through the process table, picks a process in READY state, and context switches to it. Whenever something happens that triggers a context switch back to the scheduler (the process blocks itself, or a timer interrupt forces a scheduling decision), the scheduler continues the loop.
Add these @ src/process/scheduler.c:
/** Extern our context switch routine from ASM `switch.s`. */
extern void context_switch(process_context_t **old, process_context_t *new);
/** CPU scheduler, never leaves this function. */
void
scheduler(void)
{
cpu_state.running_proc = NULL;
while (1) { /** Loop indefinitely. */
/** Look for a ready process in ptable. */
process_t *proc;
for (proc = ptable; proc < &ptable[MAX_PROCS]; ++proc) {
if (proc->state != READY)
continue;
info("scheduler: going to context switch to '%s'", proc->name);
/**
* Switch to chosen process.
*
* This is temprorary so we are not switching to user mode;
* just doing a context switch of registers.
*/
cpu_state.running_proc = proc;
context_switch(&(cpu_state.scheduler), proc->context);
/** Our demo init process never switches back... */
cpu_state.running_proc = NULL;
}
}
}
// src/process/scheduler.h
void scheduler();Most operating systems, after setting up the virtual memory system and other necessary support, will switch to an init process. The init process then creates basic user processes that provide the user interface (UI, e.g., GUI or shell) and other daemon processes. This is the time when the client gets a chance to interact with the OS, log in, and do useful stuff (forking more user processes from the shell).
Our Hux kernel does not have file system support yet. One problem thus arise: how does the kernel get the content of a piece of completely independent binary code (the compiled init program)? To achieve this, we have to do some tweaks to our compilation & linking process. See this Stackoverflow post on xv6 for more.
- Write an
init.sprogram in assembly, compile and link it to a standalone binary, separately from the kernel image; - In the kernel image linking process, use the
-b binaryflag to embed the compiledinitbinary as a whole into the kernel image; - The linker, though not well documented, exposes three symbols named
_binary_<objfile>_start,_binary_<objfile>_end, and_binary_<objfile>_size. These three symbols can beextern'ed in the kernel code, and the byte array starting at_binary_<initbinary>_startis the binary content ofinit.
Let's first make a piece of dummy init code that prints a character to VGA terminal.
Code @ src/process/init.s:
.global start
.type start, @function
start:
/**
* Prints a letter 'H' in the second to last VGA line, just to show
* that init gets executed. Please ignore the dirty numbers.
*/
movl $0xB8000, %eax
movw $0x0F48, %bx
movw %bx, 3720(%eax)
/** Infinite halt loop trick. */
cli
halt:
hlt
jmp haltEmbedding the init binary into our kernel image requires some modifications to the Makefile. Add a new target initproc for compiling and linking the init binary executable. Then, embed the result when linking the kernel.
Modifications to the Makefile:
INIT_SOURCE="./src/process/init.s"
INIT_OBJECT="./src/process/init.c.o"
INIT_LINKED="./src/process/init.bin"
INIT_BINARY="./src/process/init"
# Don't include init.s in kernel building - it is standalone.
S_SOURCES=$(filter-out $(INIT_SOURCE), $(shell find . -name "*.s"))
S_OBJECTS=$(patsubst %.s, %.o, $(S_SOURCES))
# Init process goes separately, links into an independent binary.
initproc:
@echo $(HUX_MSG) "Handling 'init' process binary..."
$(ASM) $(ASM_FLAGS) -o $(INIT_OBJECT) $(INIT_SOURCE)
$(LD) $(LD_FLAGS) -N -e start -Ttext 0 -o $(INIT_LINKED) $(INIT_OBJECT)
$(OBJCOPY) --strip-debug $(INIT_LINKED)
$(OBJCOPY) --strip-all -O binary $(INIT_LINKED) $(INIT_BINARY)
# Remember to link 'libgcc'. Embeds the init process binary.
kernel: $(S_OBJECTS) $(C_OBJECTS) initproc
@echo $(HUX_MSG) "Linking kernel image..."
$(LD) $(LD_FLAGS) -T scripts/kernel.ld -lgcc -o $(TARGET_BIN) \
-Wl,--oformat,elf32-i386 $(S_OBJECTS) $(C_OBJECTS) \
-Wl,-b,binary,$(INIT_BINARY)
$(OBJCOPY) --only-keep-debug $(TARGET_BIN) $(TARGET_SYM)
$(OBJCOPY) --strip-debug $(TARGET_BIN)
.PHONY: clean
clean:
rm -f $(S_OBJECTS) $(C_OBJECTS) $(INIT_OBJECT) $(INIT_LINKED) \
$(INIT_BINARY) $(TARGET_BIN) $(TARGET_ISO) $(TARGET_SYM)Note that the path to our init binary is named as ./src/process/init, so the symbol names will be _binary___src_process_init_start, etc. (took me quite some time to debug this one ¯\(°_°)/¯).
In our kernel, we then set up a slot in the ptable for the init process, mark it as READY, and jump into the scheduler loop.
Add these routines @ src/process.c:
/**
* Find an UNUSED slot in the ptable and put it into INITIAL state. If
* all slots are in use, return NULL.
*/
static process_t *
_alloc_new_process(void)
{
process_t *proc;
bool found = false;
for (proc = ptable; proc < &ptable[MAX_PROCS]; ++proc) {
if (proc->state == UNUSED) {
found = true;
break;
}
}
if (!found) {
warn("new_process: process table is full, no free slot");
return NULL;
}
/** Allocate kernel stack. */
proc->kstack = salloc_page();
if (proc->kstack == 0) {
warn("new_process: failed to allocate kernel stack page");
return NULL;
}
/** Make proper setups for the new process. */
proc->state = INITIAL;
proc->pid = next_pid++;
return proc;
}
/**
* Initialize the `init` process - put it in READY state in the process
* table so the scheduler can pick it up.
*/
void
initproc_init(void)
{
/** Get the embedded binary of `init.s`. */
extern char _binary___src_process_init_start[];
extern char _binary___src_process_init_size[]; // Not used for now.
/** Get a slot in the ptable. */
process_t *proc = _alloc_new_process();
assert(proc != NULL);
strncpy(proc->name, "init", sizeof(proc->name) - 1);
/**
* Set up context, set EIP to be the start of its binary code.
*
* This is temporary because we are in the process's kernel stack.
* After user mode execution has been explained, it should be changed
* to a "return-from-trap" context. User page tables must also be
* set up, and switched properly in the `scheduler()` function.
*/
uint32_t sp = proc->kstack + KSTACK_SIZE;
sp -= sizeof(process_context_t);
proc->context = (process_context_t *) sp;
memset(proc->context, 0, sizeof(process_context_t));
proc->context->eip = (uint32_t) _binary___src_process_init_start;
/** Set process state to READY so the scheduler can pick it up. */
proc->state = READY;
}
// src/process/process.h
void initproc_init();Finally, in the kernel main function, call the initializers and jump into the scheduler loop @ src/kernel.c:
/** The main function that `boot.s` jumps to. */
void
kernel_main(unsigned long magic, unsigned long addr)
{
... // All the previous initializations...
/** Initialize CPU state, process structures, and the `init` process. */
_init_message("initializing CPU state and process structures");
cpu_init();
process_init();
initproc_init();
_init_message_ok();
info("maximum number of processes: %d", MAX_PROCS);
/** Executes `sti`, CPU starts taking in interrupts. */
asm volatile ( "sti" );
/**
* Jump into the scheduler. For now, it will pick up the only ready
* process which is `init` and context switch to it, then never
* switching back.
*/
printf("\nShould see a white letter 'H' in the second to last VGA line\n");
scheduler();
while (1) // CPU idles with a `hlt` loop.
asm volatile ( "hlt" );
}Let's see what happens after our kernel jumps into the scheduler loop!
This should produce a terminal window as the following after booting up:

With the basic process framework setup, we can now work on enabling user mode execution, system calls, and time-sharing across multiple processes. Most of the process initialization function shown in this chapter will get heavily modified in the next few chapters as we turn these fancy terminology into code ✭.
Current repo structure:
hux-kernel
├── Makefile
├── scripts
│ ├── gdb_init
│ ├── grub.cfg
│ └── kernel.ld
├── src
│ ├── boot
│ │ ├── boot.s
│ │ ├── elf.h
│ │ └── multiboot.h
│ ├── common
│ │ ├── debug.c
│ │ ├── debug.h
│ │ ├── port.c
│ │ ├── port.h
│ │ ├── printf.c
│ │ ├── printf.h
│ │ ├── string.c
│ │ ├── string.h
│ │ ├── types.c
│ │ └── types.h
│ ├── device
│ │ ├── keyboard.c
│ │ ├── keyboard.h
│ │ ├── timer.c
│ │ └── timer.h
│ ├── display
│ │ ├── terminal.c
│ │ ├── terminal.h
│ │ └── vga.h
│ ├── interrupt
│ │ ├── idt-load.s
│ │ ├── idt.c
│ │ ├── idt.h
│ │ ├── isr-stub.s
│ │ ├── isr.c
│ │ └── isr.h
│ ├── memory
│ │ ├── gdt-load.s
│ │ ├── gdt.c
│ │ ├── gdt.h
│ │ ├── kheap.c
│ │ ├── kheap.h
│ │ ├── paging.c
│ │ ├── paging.h
│ │ ├── slabs.c
│ │ └── slabs.h
│ ├── process
│ │ ├── init.s
│ │ ├── process.c
│ │ ├── process.h
│ │ ├── scheduler.c
│ │ ├── scheduler.h
│ │ └── switch.s
│ └── kernel.c