High Performance MapReduce-First Cluster Computing Library

This library provides a set of utility functions and distributed data containers for high performance cluster computing. We provide a highly-optimized MapReduce function to process and convert one data container to another. This MapReduce function is usually several times faster than Aparch Spark at the time of this update. For most parallel algorithms, users only need to write a few mapper functions and they will get similar performance as hand-optimized code written with raw sockets and threads. We also provide some additional features to complement MapReduce, such as loading files to distributed data containers, thread-safe random number generators, and functions for converting distributed containers to and from C++ standard containers, etc.
For more details about the use cases and our optimizations, we refer users to our paper Blaze: Simplified High Performance Cluster Computing.
Blaze is being actively used in a quantum chemistry package (developed by the Umrigar Group at Cornell University LASSP Lab) and has successfully and efficiently processed petabytes of scientific data and saved billions of core hours of computation compared to using Spark (or hundreds of billions of core hours compared to using Hadoop MapReduce).
In this section, we present two examples to illustrate the usage of Blaze.
The complete code of these examples can be found in the example folder.
For your convenience, we also provide the corresponding Makefile.
Note that this library has two sets of dependencies:
First, the ones in the vendor directory, which you can get by either add the --recursive option when you clone the repository or use the following command later
git submodule update --init --recursive
Second, an MPI library. Blaze supports all the major MPI implementations and you can choose the most suitable one for your infrastructure.
In this example, we build a distributed hash map of word occurrences<std::string, size_t> and output the number of unique words.
// Load source file into DistVector<string> in parallel.
auto lines = blaze::util::load_file("filepath..."); // Source
const auto& mapper = [&](const size_t, const std::string& line, const auto& emit) {
// First argument is line_id, which is not needed.
std::stringstream ss(line);
std::string word;
while (getline(ss, word, ' ')) emit(word, 1); // Split line into words.
};
blaze::DistHashMap<std::string, size_t> words; // Target
blaze::mapreduce<std::string, std::string, size_t>(lines, mapper, "sum", words);
std::cout << words.size() << std::endl;In this example, we estimate π using the Monte Carlo method.
const size_t N_SAMPLES = 1000000;
blaze::DistRange<size_t> samples(0, N_SAMPLES);
const auto& mapper = [&](const size_t, const auto& emit) {
double x = blaze::random::uniform();
double y = blaze::random::uniform();
if (x * x + y * y < 1) emit(0, 1);
};
std::vector<size_t> count(1); // {0}
blaze::mapreduce<size_t, size_t>(samples, mapper, "sum", count);
std::cout << 4.0 * count[0] / N_SAMPLES << std::endl;More examples are available in the benchmark folder test/benchmark.
These are used when we generate the benchmarks for the paper mentioned above, and contains the Blaze implementation of several popular data mining algorithms.
Since the input data are huge, we don't provide it here.
We present two benchmarks here: one is with Apache Spark on AWS to show its superior performance on a multi-machine cluster; the other one is with hand-optimized parallel for loops to illustrate that Blaze can approach similar performance as hand-optimized code;
This task counts the number of occurrences of each unique word from a text file, which contains about 0.4 billion words in total. The performance of Blaze is compared to Apache Spark (from AWS EMR 5.20.0) on several AWS EC2 r5.xlarge instances.
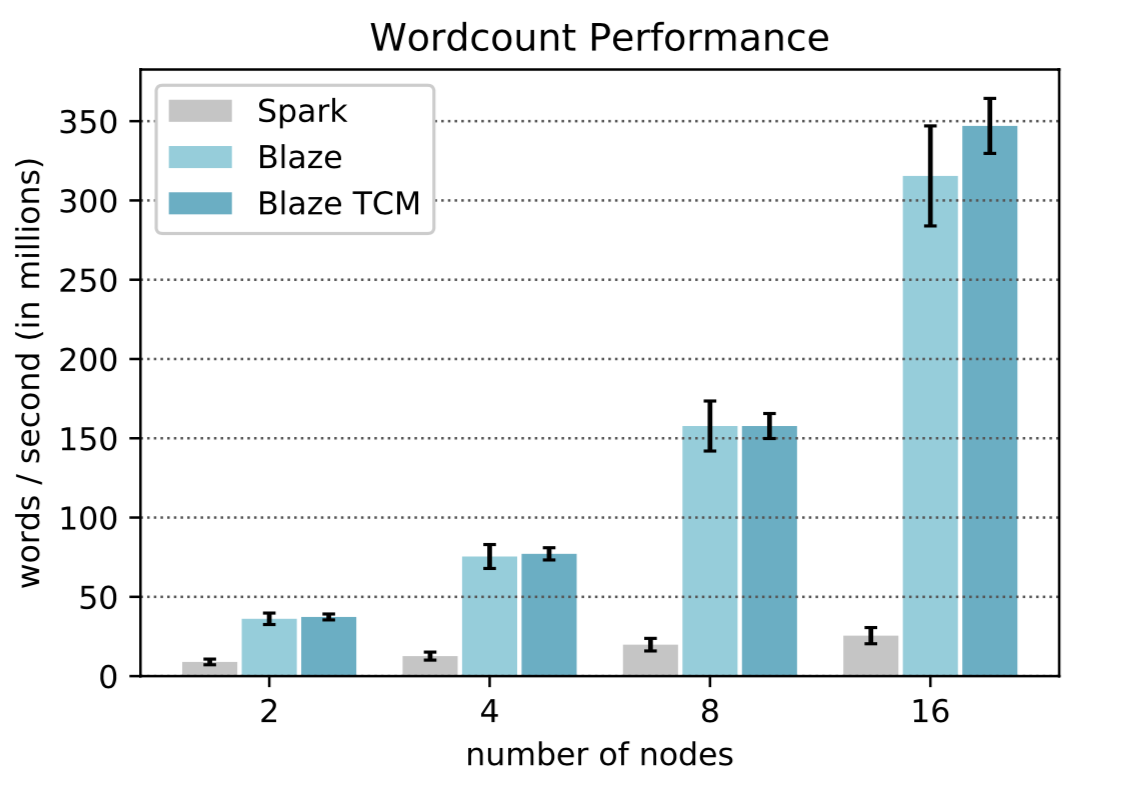
Here Blaze TCM stands for Blaze linked with the TCMalloc library from Google. We can see Blaze is about 10 times faster than Spark for this task.
This task compares the performance and source lines of code (SLOC) of the π estimation between a Blaze MapReduce implementation and a hand-optimized parallel for loops implementation.
| Blaze MapReduce | MPI+OpenMP | |
|---|---|---|
| Time for 10M Samples (s) | 0.14 | 0.14 |
| Time for 100M Samples (s) | 1.44 | 1.42 |
| Time for 1B Samples (s) | 14.2 | 14.6 |
| Source Line of Code | 8 | 24 |
We can see that Blaze MapReduce achieves similar performance as hand-optmized parallel for loops while using significantly less lines of code.
The hand-optimized code is listed in at test/example/pi_estimation.cc.