Refactor GraphQL backend #964
Conversation
Signed-off-by: Antony Milne <antony.milne@quantumblack.com>
Signed-off-by: Antony Milne <antony.milne@quantumblack.com>
Signed-off-by: Antony Milne <antony.milne@quantumblack.com>
Signed-off-by: Antony Milne <antony.milne@quantumblack.com>
Signed-off-by: Antony Milne <antony.milne@quantumblack.com>
…re/refactor-graphql Signed-off-by: Antony Milne <antony.milne@quantumblack.com>
This reverts commit 35a3d6a.
package/kedro_viz/api/graphql.py
Outdated
| @@ -49,7 +54,7 @@ class JSONObject(dict): | |||
| description="Generic scalar type representing a JSON object", | |||
| ) | |||
|
|
|||
|
|
|||
| # TODO: where should format functions go? | |||
There was a problem hiding this comment.
hey so this is what I usually call serializers in API development. A serializer takes data from one format (domain model) and serializer it into another format (GraphQL type or FastAPI Response Model) so a file called graphql_serializers might be a good idea.
There was a problem hiding this comment.
Thanks Lim! This is exactly what I was thinking.
My other idea was that it should live in the Run type itself. It seems that strawberry.scalar has a serialize option but strawberry.type doesn't, so would need to do this as a method:
@strawberry.type
class Run:
author: Optional[str]
bookmark: Optional[bool]
...
def format(self):
...
What do you think? Is this a horrible misunderstanding of the purpose of these objects (maybe there's a good reason that strawberry.type doesn't have serialize) or a good way to do it?
There was a problem hiding this comment.
Yea, one down side I can think of is unit testing. Ideally you would want to be able to test the serialization logic which is mostly standalone and stateless without having to mock out the whole API
There was a problem hiding this comment.
This is what I suspected, thank you for confirming!
Signed-off-by: Antony Milne <antony.milne@quantumblack.com>
|
Here's how I've reorganised things: My proposal for tests would be:
What do you think? Please tell me if this sounds right to you 🙏 Thank you very much! @limdauto |
Signed-off-by: Antony Milne <antony.milne@quantumblack.com>
Signed-off-by: Antony Milne <antony.milne@quantumblack.com>
Signed-off-by: Antony Milne <antony.milne@quantumblack.com>
Signed-off-by: Antony Milne <antony.milne@quantumblack.com>
Signed-off-by: Antony Milne <antony.milne@quantumblack.com>
Signed-off-by: Antony Milne <antony.milne@quantumblack.com>
Signed-off-by: Antony Milne <antony.milne@quantumblack.com>
Signed-off-by: Antony Milne <antony.milne@quantumblack.com>
Signed-off-by: Antony Milne <antony.milne@quantumblack.com>
Signed-off-by: Antony Milne <antony.milne@quantumblack.com>
Signed-off-by: Antony Milne <antony.milne@quantumblack.com>
Signed-off-by: Antony Milne <antony.milne@quantumblack.com>
…re/refactor-graphql Signed-off-by: Antony Milne <antony.milne@quantumblack.com>
Signed-off-by: Antony Milne <antony.milne@quantumblack.com>
Signed-off-by: Antony Milne <antony.milne@quantumblack.com>
Signed-off-by: Antony Milne <antony.milne@quantumblack.com>
Signed-off-by: Antony Milne <antony.milne@quantumblack.com>
| @@ -37,12 +37,22 @@ lint-check: | |||
| flake8 --config=package/.flake8 package | |||
| mypy --config-file=package/mypy.ini package | |||
|
|
|||
| schema-fix: | |||
There was a problem hiding this comment.
curious: what's the need for this?
There was a problem hiding this comment.
This is what automatically generates the graphql.schema file and png from the strawberry schema. It's called schema-fix (bit of a weird name I know) by analogy with make format-fix, which will make the make format-check CI pass. Here schema-fix will make the make schema-check CI that tests if the schema file and diagram is up to date pass.
|
@AntonyMilneQB if you are fishing for next project, I'd recommend drilling on this one:
This is related to this issue that I opened a few weeks ago: #872 -- the ideal flow in my head is:
|
This PR was created based on the backend refactor ticket. #964 The backend has now changed and for runTrackingData -- it will now get queries also based on the group (dataset type) the tracking data belongs to i.e. Metrics, JSON Data (and in future Plots) In this ticket, we have adjusted the front-end to get information from the backend for each dataset. If a particular group (Metrics, JSON Dataset) has no datasets, that group will not be shown in the front-end. Otherwise all run tracking data will now have another parent in the heirarchy/accordian i.e. type of dataset (Metrics, JSON Data, Plots)
Description
Originally I was just doing a bit of tidying to enable #958, but the deeper I got the more I decided that our current experiment tracking backend was not up to scratch. It's still not perfect, but it's a lot better and we now have some clear steps to improve it further.
The only new functionality introduced here is being able to query by group, which isn't yet used on the fronted. But following this PR it should as a result be much easier to extend now, e.g. to add plots.
Renaming and restructuring
apihas been broken into two new folders that reflect the GraphQL and REST parts of the app. All GraphQL related code was previously ingraphql.py; this has now been broken down into several separate files.Some naming has been aligned (e.g.
experiments_tracking.py➡️experiment_tracking.py,graph.py➡️flowchart.py).Separation of responsibility
To separate out responsibilities better we now have some new components on the backend:
TrackingDatasetRepositoryTrackingDatasetModelandTrackingDatasetGroup.This means that, e.g., data loading is no longer leaking out into the API as it was before.
The way that tracking data is populated and retrieved is worth documenting here:
populate_datawhen the app is first loaded,TrackingDatasetRepositoryis populated bydata_access_manager.add_catalog--pipelineargument affect only the flowchart view)kedro runthen the new dataset won't show up in experiment tracking unless--autoreloadis set, becausepopulate_datawon't be called againrun_idis only loaded (throughdataset._load) when the GraphQL queryrun_tracking_datais run with thatrun_id. Subsequentrun_tracking_dataqueries will not perform the load from disk again but instead read out of memoryQuery by group
The
runTrackingDataquery now accepts agroupargument with typeTrackingDatasetGroup:This is not used yet on the frontend but will be very useful to query without needing another layer in the tracking datasets hierarchy. e.g.
Tidying implementation
Lots of small changes to implementation just to make things tidier, e.g. using
json.JSONDataSet._loadrather than re-writing it; removing unnecessary custom strawberry typeJSONObject; putting strawberry resolvers directly as class methods rather than external functions.Documentation
The backend (specifically strawberry) defines the GraphQL schema and writes it to

schema.graphqland generates a png from it:A new CI check ensures this is always up to date.
All parts of the schema now have
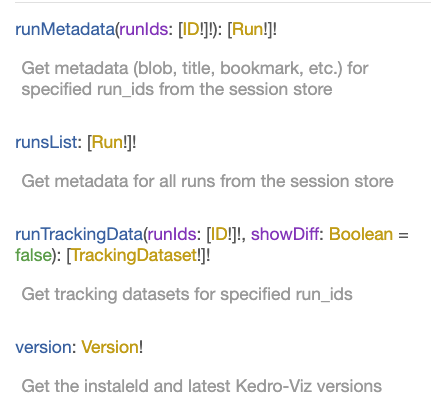
descriptions. Unlike docstrings, these are rendered in GraphiQL:Next steps
Write lots of tests. Improve the way we do GraphQL tests in general (various ideas here).
For adding plots to experiment tracking:
TrackingDatasetGroupand produce existing behaviour for metrics and JSON.TrackingDatasetModelandTrackingDatset. Consider model for run which would simplify (maybe even remove)format_run_tracking_data. How to query byrun_idcorrectly?TrackingDatasetRunin strawberry but not a dataclass model. Maybe do this as GraphQL interface with different implementations, serializers for plots, etc.Important other refactoring:
DataNodeandDataNoteMetadatamodels. There's too much duplication between these are tracking datasets.check_db_session, e.g. decorator argument that returns empty iterable (could be done automatically from type hint)? Null class?is_tracking_datasetshould useisinstanceinstead, but be careful with importsformat_runsneeded? Should formatting go into constructor or class method? Are they needed at all?TrackedDataSetsa field inRun?QA notes
Extended Python GraphQL query tests to be more e2e and accommodate new structure ✅
Manually tested ✅
Tested schema generated and CI check works ✅
Checklist
RELEASE.mdfile