{kind=link}
OPENTQA is a open framework of the textbook question answering.
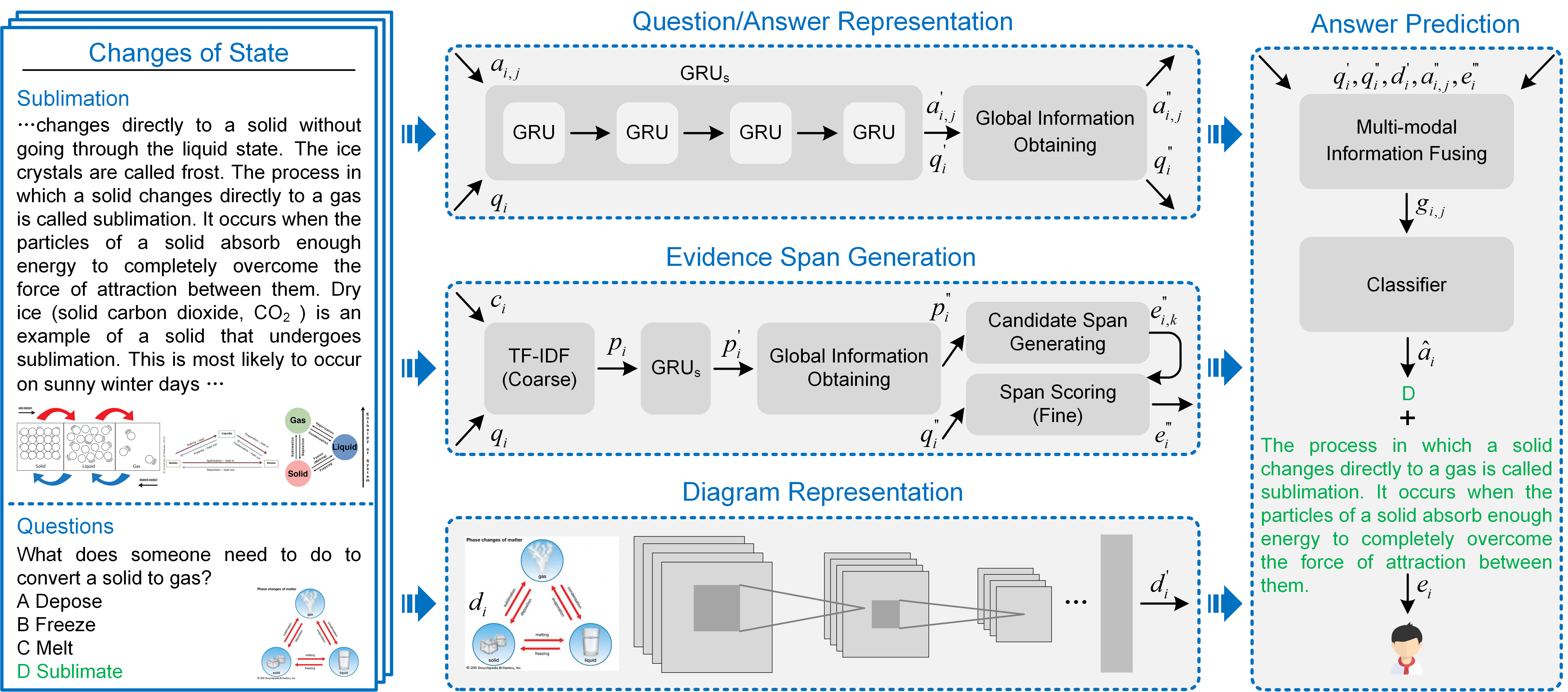
Our method can be generalized by this picture:
You can simply install the virtual environment by:
pip install -r requirements.txt
The preprocessed dataset is placed in
https://drive.google.com/drive/folders/1eFx3XGyUSs0ij12wSmv70e6MRXa2TEFL
The datasets were split to 2 parts, diagram questions (dqa) and non-diagram questions (ndqa) ;
For each model, the project provides argumentations below:
-
dqa
- que_ix: the index of questions
- opt_ix: the index of options
- dia: the diagram corresponding the above question
- ins_dia: the instructional diagram corresponding to the lesson that contains the above question
- cp_ix: the closest paragraph that is extracted by TF-IDF method
-
ndqa
- que_ix: the index of questions
- opt_ix: the index of options
- cp_ix: the closest paragraph that is extracted by TF-IDF method
OPENTQA contains several models which are listed down here.
- xtqa
- mcan
- mfb
- CMR
- mutan
Each model is composed by four parts:
- [model_name].yml This file is in configs/[dataset]/ and the other 3 files are in opentqa/models/[dataset]/.It contains the global variables of the model, such as data_path , epoch , batch_size etc.
- net.py This file describes how the model works.
- model_cfgs.py This file contains the local variables of the model.
- layers.py This file contains layers which might be called in net.py
You can also add your own model to the project by following these steps:
- Add net.py to opentqa/models/[dataset]/ , it should accept the argumentation mentioned above;
- Add model_cfgs.py and layers.py according to your need;
- Add [model_name].yml to configs/[dataset]/ , make sure it contains the global variables and the correct path of dataset.
- Add your model name to the arguments in run.py
Next we will talk about how to run the code.
Before you try to run the code, please make sure your configs are right:configs/[dataset]/[model_name].yml
You can train the model by the command:
python run.py --dataset_use=[dataset] --model=[model_name] --run_mode=train For example, if I want to train "xtqa" on dataset "dqa", the command should be:
python run.py --dataset_use=dqa --model=xtqa --run_mode=train
You can find your a model version showed on the terminal, and this number is used to test the model.
The result will be in results/log/ and the checkpoints will be placed in ckpt/
Notice: if there are two same version, the new one will cover the old one!
You can test the model by the command:
python run.py --ckpt_v=[ckpt_version] --ckpt_e=[ckpt_epoch] --dataset_use=[dataset] --model=[model_name] --run_mode=test
ckpt_version was talked above, ckpt_epoch refers to the epoch of the checkpoint.
For example, you can test the 5th epoch of "xtqa" which version is 1024 on dqa on this way:
python run.py --ckpt_v=1024 --ckpt_e=5 --dataset_use=dqa --model=xtqa --run_mode=test