
In this project we develop a Semantic Web application that automatically generates crossword puzzles based on user-specified topics in a generic way. Hence, the final application can be recognized as a learning tool focusing on topics the user is interested in. However, the application is not restricted to high-level topics but rather allows to incorporate most of the entities which can be found in corresponding RDF knowledge sources as a topic for the crossword puzzle.
Most of the traditional crossword generator tools have a fixed crossword structure and employ backtracking algorithms by exploiting manually crafted databases of clue-answer pairs. Hence, the creation of the crossword puzzle is only semi-automatic, still requiring human knowledge and expertise. Therefore, different topics can only be represented in the crossword by applying different topic clue-answer databases.
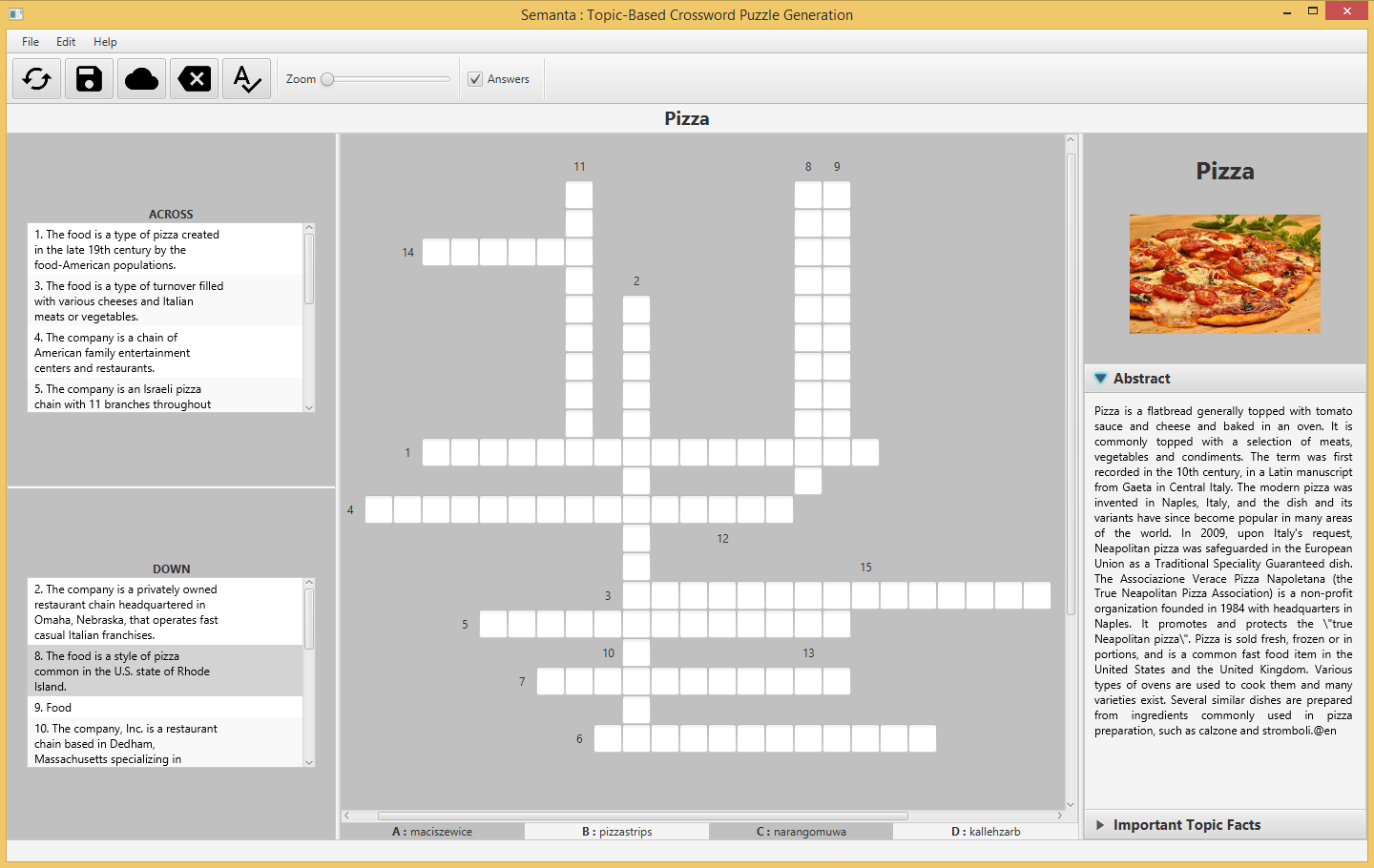
The approach of creating crosswords implemented in Semanta, however, is reversed. Instead of starting with a fixed structure and filling in words, Semanta firstly extracts the topic-related words and then dynamically creates the crossword structure. Hence, the user specifies an interesting topic, receives a list of the most probably resources that belong to the given string and selects the corresponding resource. In addition, the user can directly generate a crossword puzzle without selecting one of the search results. These options allow the user to select not only more specific topics but also provides a complete automated pipeline of the crossword generation process. Based on the selected resource and a specified difficulty level, the crossword puzzle generation algorithm queries a RDF knowledge base to obtain topic-related resources and finally establishes a new crossword puzzle based on the retrieved resources. Note that the main RDF data processing tasks are to find topic-related resources and to generate meaningful clues for the sought-after words. In addition, we integrate the option to retrieve four possible answers (distractors) to facilitate the solving of the crossword puzzle. Here, the application is required to automatically generate reasonable distractors adaptive to a difficulty level given the actual answer resource.

The figure illustrates the overall pipeline and individual steps involved in automatically creating a crossword based on user specified topic, number of words and difficulty level. First, we map the input topic string to a particular resource in our knowledge base as a starting point for the remaining process. This step is denoted as (1) Topic Resource Retrivial and exploits full text search capabilities of the Virtuoso endpoint as well as the PageRank available for DBPedia entities. Based on the topic resource, we explore the local neighbourhood to identify interesting and reasonable sought-after resources for the crossword, which is denoted by (2) Topic-Related Resource Selection. Here, we implemented two approaches based on the PageRank of the entities and based on the approximate PageRank denoted as Node Degree. Once we have selected the crossword entities, we automatically generate clues which is denoted by (3) Clue Generation. We focued on two main approaches called Abstract Sentence Extraction and Property Clue Generation, which are more precisely described in the subsequent section. In order to help the user to guess the answer, we also provide distractors as in a traditional quiz game. For each entity in the crossword, we therefore extract meaningful related entites which are similar in some way. This step is denoted by (4) Distractor Generation. FInally, once all data is generated, we generate a crossword structure denoted by (5) Crossword Generation.
In order to retrieve meaningful topic resources based on the search input, PageRank was used to sort the results, and the application shows the best ten results to the user.
To extract proper results, a language filter was applied on the rdfs:label and the dbo:abstract, to restrict them to English. All resources of type skos:Concept were ignored, which helped to ignore entities that do not represent a specific topic (e.g. categories). Since the user is capable of entering more than one word in the search field, the search query was restricted to retrieve resources that contain all the tokens of the search.
In order to have fast and robust query execution, our query used the full text search feature which is supported by the public DBpedia endpoint. Within the query, bif:contains is used with AND operator, connecting individual words. Regex approach was tried in the beginning, but yielded very slow execution time.
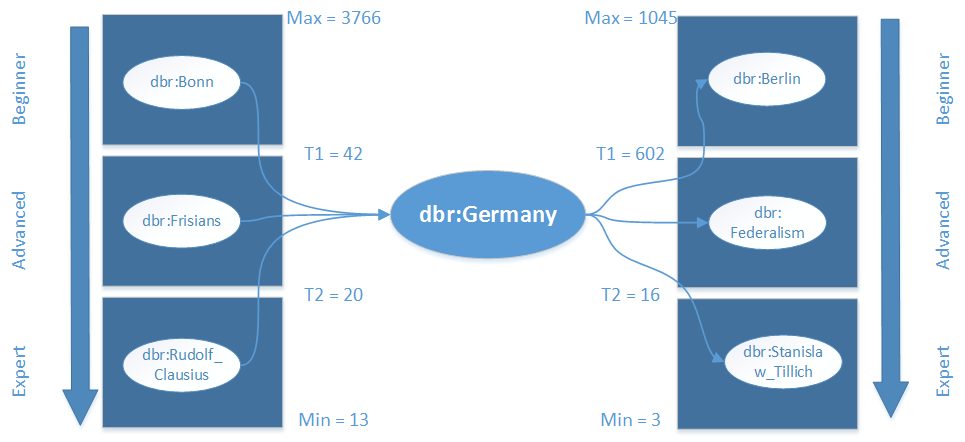
After we detected the most probable topic resource belonging to the input string, we extract multiple resources related to the topic resource, which represent the search words within the crossword puzzle. Note that the final word used in the crossword, is the sanitized rdfs:label string of the resource. Resources which exhibit a direct link to the topic resource are considered as eligible resources with semantic relatedness to the topic. Note that resources which are reachable over multiple hops by the topic resource may also yield interesting resources related to the topic, however, it is a difficult task to measure the semantic relatedness to the topic for these resources. In this project hence, we focused solely on resources located in the one-hop-reachable neighborhood of the topic resource as being interesting to the user. For terminology, we distinguish between incoming resources (?s ?p ?topic) and outgoing resources (?topic ?p ?o). Outgoing resources often exhibit strong semantic relatedness to the topic and therefore can be exploited immediately for crossword puzzle generation. On the other hand, topic resources have often vast number of incoming resources which makes more precise filtering obligatory, in order to avoid selecting arbitrary resources. Based on these findings, we incorporated metrics to measure the individual importance and rank the resources accordingly. Since these metrics measure the importance of a single resource, we additionally can exploit the ranking for difficulty level adaption of the crossword puzzle. Higher ranked resources have potentially increased degree of popularity and therefore are easier to determine as lower ranked ones.
As a first importance metric, we computed the degree of a the resource as the sum of incoming and outgoing links using SPARQL. As a second approach, we simply used the PageRank provided for Dbpedia. We evaluated both approaches and decided to use PageRank due to an improved query time, however, both produced similar results.
To obtain the resources for a specific difficulty level, we sort the resources using PageRank first and divide the ranked list into three parts representing the distinct difficulty levels. Each division can be specified by an upper and lower threshold of the rank value. With a subsequent SPARQL query, we obtain resources belonging to one difficulty level by using a filter and the previously estimated thresholds, and select a random sample. We execute these steps for both incoming and outgoing resources and combine them equally for the final result.
The previous components involved SPARQL queries and fetching RDF data. As a subsequent component of topic-related resource selection which form the words in the crossword, we perform processing of the data in order to generate clues for each word. We developed two independent approaches for clue generation. For each resource, we locally compute the most general, the most specialized and the in between ontology concept based on Dbpedia ontology. These computed ontology types are also beneficial for difficulty adaption for clue generation as well as distractor generation.
This approach for clue generation exploits the abstract provided by the resource through the dbo:abstract property. First, we employ the sentence detector of Apache OpenNLP trained on a English sentence model. This NLP tool extracts individual sentences in the abstract. Thus, it detects if a period is used to end the sentence or only as abbreviation within a sentence. After obtaining the sentences, a regular expression is created using the label of the resource under consideration in such a way, that the regular expression matches all occurrences of the label. On each sentence we apply the regular expression and if there is at least one match, we keep the sentence and replace the match with a template of the definite article followed by the ontology concept of the resource. Note that we adapt the difficulty level by inserting one of the mentioned ontology concepts. For example, inserting dbo:SoccerPlayer into a sentence extracted for dbr:Oliver Kahn makes it easier to determine the answer as inserting dbo:Person, since we add specialized information. An additional way of adapting the clue to difficulty level is to exploit the fact that sentences which occur earlier in the abstract are more important and general, than sentences occurring later in the abstract. The following example shows the original sentence and the regular expression match replaced with its ontology type for dbr:Oliver Kahn.
Oliver Rolf Kahn is a former German football goalkeeper.
The soccer player is a former German football goalkeeper.
The abstract sentence extraction approach exploits already existing descriptions of the resource, which are properly written by humans. Hence, this approach is able to create proper clues often, however, sometimes generates grammatically wrong clues and fails, if no match for the regular expression is found.
The second investigated approach for crossword clue generation is more robust in the sense that in most cases it can generate clues, however, often produces grammatically wrong sentences which are hard to understand. It is a template-based approach and combines the ontology concept with a corresponding property and its object value. For example, the following clues are generated for resource dbr:Oliver Kahn for each difficulty level using the given template.
Template : <ontology concept> with <property> <object>
Beginner : Soccer player with position Goalkeeper (association football)
Advanced : Person with team FC Bayern Munich
Expert : Agent with team Karlsruher SC II
Again the specificity of the ontology concept is adapted to achieve different difficulty levels, and in addition the selected properties of the resource are adapted. Note that the notion behind the selection of the properties is identical to the related resource selection using page rank. However, since there is no PageRank available for properties, we rank the objects they link the resource to. According to the example, the resource dbr:Goalkeeper has a higher rank than dbr:FC Bayern Munich and dbr:Karlsruher SC II. We observed that the produced hints are more concise as in a manually crafted crosswords, however, often lack grammatically correctness. As an improvement, we tested various grammar check APIs like JLanguageTool, however, these tools mostly apply only simple rules and are not sophisticated enough to correct severe grammatical errors.
All algorithmic steps discussed previously are sufficient for generating an entire topic-based crossword puzzle composed of clues and corresponding answers. However, we decided to include the facility to present four possible answer (the actual answer among three distractors) to the user, similar to a quiz game. For this component, we also developed multiple approaches for adapting to different difficulty levels. Note that the following approaches built upon each other. That is, a subsequent approach can be regarded as a specialization of the previous one. All approaches have in common that from the qualifying resources, a random sample is selected.
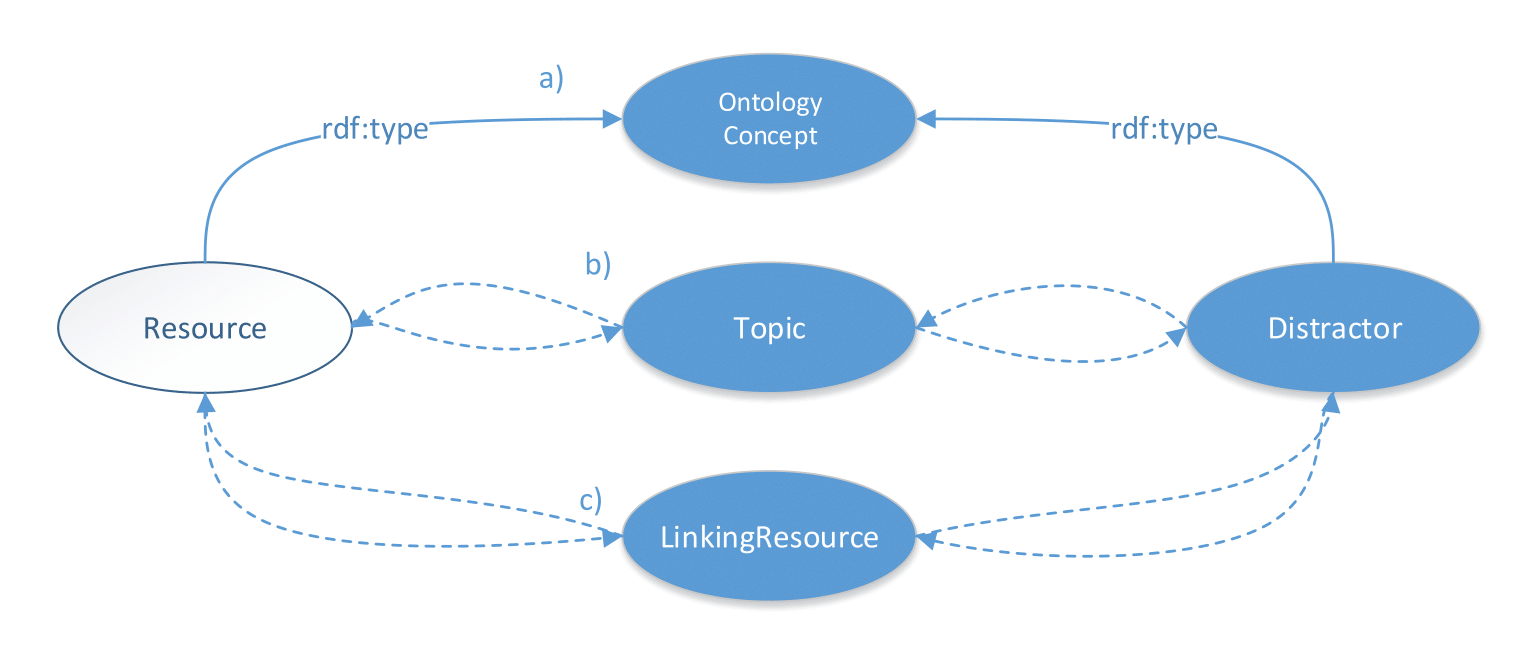
The first and simplest approach to identify meaningful distractors given a resource is to query for resources having the same rdf:type as depicted in the following Figure. We can easily adapt the difficulty level by switching the ontology concept using the previously described method. Note that for clue generation a more specialized ontology concept yields easier clues. However, distractors which are more similar (by querying for more specialized ontology concept) to the actual resource, increase the fuzziness and complicate finding the valid answer. For example, for resource dbr:Oliver_Kahn this component extracts dbr:Ronaldo.
The second approach also uses the ontology concept of the actual resource, however, additionally requires some link between the distractor and the topic resource. Note that each resource under consideration is inevitable linked to the topic resource. Hence, we increase the fuzziness through extracting only distractors which exhibit some connection to the topic. This approach is also adaptable to different difficulty levels through ontology concept switching. The additional component is depicted in Figure b.
The third approach extracts distractors with further linking resources, to which both the resource under consideration and the distractor are linked to. We sort the results by the number of linking resources and extract the top-ranked as distractors. For example, for dbr:Oliver_Kahn this approach extracts soccer players with position goalkeeper, team Bayern Munich and so on. The more the resources have in common in terms of linking resources, the higher the fuzziness for the user dealing with the distractors. These linking resources are depicted in Figure c.
Finally we combined the three approaches and use the Linking Resource Distractor Generator for expert level, Topic Distractor Generator for advanced level and Type Distractor Generator for beginner level. Note that this approach also provides a fallback strategy in case of distractor generation failure. Therefore, if a more specialized component fails, the next more general approach is used. Hence, we trade-off between meeting the difficulty level and generate distractors in any case.
So far, we only focused on generating distractors based on increasing fuzziness due to higher semantic similarity. However, distractor generation for crosswords is especially challenging due to further restrictions like a determined word length and specific characters at specific position within the word. Therefore, we filter all distractors which have a different length compared to the actual answer. However, due to increased complexity and lack of time, we neglect the fact that distractors must have specific characters at intersection cells.