Incorrect behavior on scaling up when using behaviors config on HPA #96671
Comments
|
@DmitrySemchenok: This issue is currently awaiting triage. If a SIG or subproject determines this is a relevant issue, they will accept it by applying the The Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository. |
|
/sig autoscaling |
|
/assign josephburnett |
|
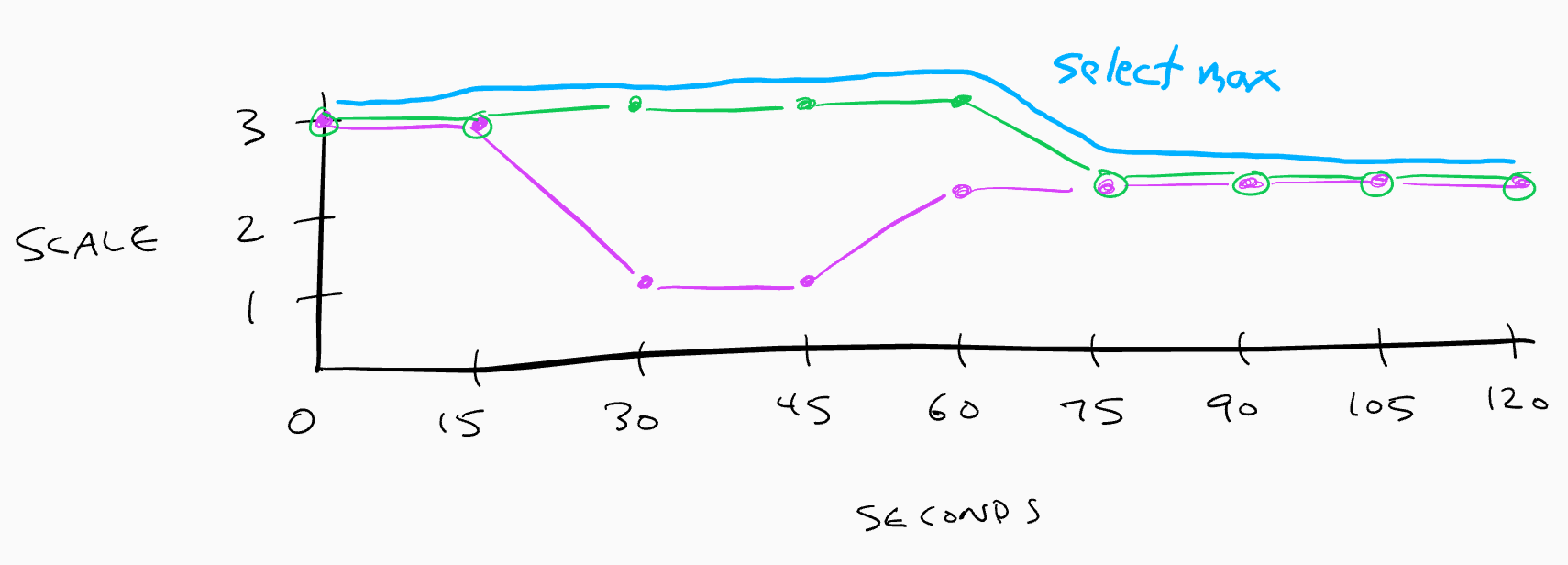
The HPA controller keeps a flat history of recommendations for stabilization. When downscale stabilizing the maximum recommendation is selected. Purple is pre-stabilized recommendation. Green is final recommendation. Blue is max recommendation within window. When upscale stabilization the minimum recommendation is selected. However when both up and down scale stabilization is configured, the interpretation of the history changes depending on the direction of movement. Red is the undesired, actuated recommendation. What we want is to keep the stabilized recommendation within the envelope of the minimum and maximum over configured stabilization windows. We should only move when the envelope forces a move. We first stabilize up and down, and check if the current value fits within it. If it does (or the range is "inverted"), we do nothing. If it does not, we emit the "nearest possible" value, which will be lower or upper bound, depending on where the current size is in relation to the range. |




The current explanation is misleading (for example: for consistently decreasing resource usage, the HPA stabilization does not impact the frequency of its actuation). This has confused users recently ( kubernetes/kubernetes#96671 )
When configuring new behaviors section in HPA I faced two scenarios that I think are incorrect.

First one:
stabilizationWindowSeconds set up to 5 minutes for both scale up and scale down
min replica count 2
Application consumes big amount of resources during warm-up
0 minute: current replica count: 2
1 minute: desired replica count: 3 - no scale up stabilization window worked
2 minute: desired replica count: 1 (!) - scale up to 3 (max number from previous recommendations during stabilization window period)
Second one
Stabilization window for scale up 0
Stabilization window for scale down 5 minutes
min replica count 2
behavior set to scale up new pod in 2 minutes
scaleUp:
policies:
- type: Pods
value: 1
periodSeconds: 120
What happens:
0 minute: 2 replicas
1 minute : performance spike scale up to 3 (desired value 4)
2 minute : no spike no scale up
3 minute: no spike scale up to 4(!) - supposedly desired value 1 and supposedly worked this way because of scale down window set to 5 minutes picking max value from that 5 minutes window that was 4 replicas
Expected behaviors
1 Scenario no scale up for 5 minutes
2 Scenario correct measurement and no scale up when there is no need for it
Environment:
kubectl version): client 1.19.3 Server 1.19.0The text was updated successfully, but these errors were encountered: