-
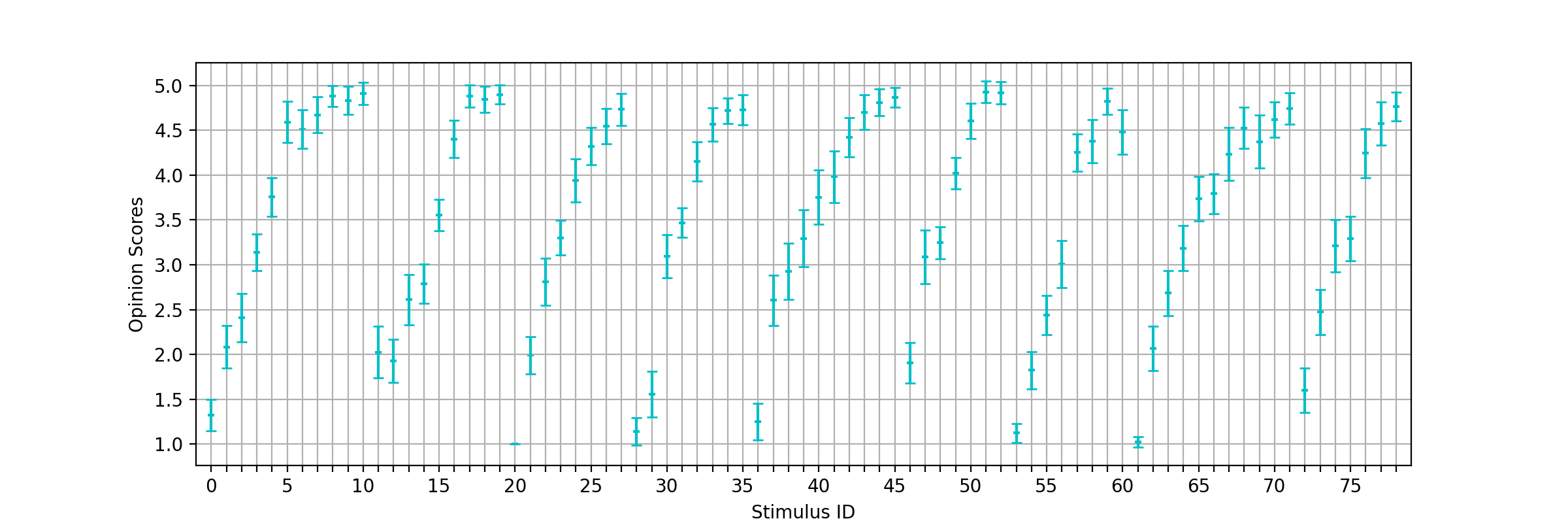
MOS recovery with corresponding CI
-
$P_{th}$ percentile recovery -
Subject bias estimation
-
Subject inconsistency estimation
-
Content ambiguity estimation
If you use this in any of your research work, please cite the following paper:
@INPROCEEDINGS{10222033,
author={Zhu, Jingwen and Ak, Ali and Le Callet, Patrick and Sethuraman, Sriram and Rahul, Kumar},
booktitle={2023 IEEE International Conference on Image Processing (ICIP)},
title={ZREC: Robust Recovery of Mean and Percentile Opinion Scores},
year={2023},
volume={},
number={},
pages={2630-2634},
doi={10.1109/ICIP49359.2023.10222033}}
numpy is the only requirement for ZREC.
In the provided scripts, pandas is used to read the dataset .csv file and convert to a numpy array, but it is optional as long as the final dataset input is a 2d numpy array.
matplotlib is used to visualize the recovered MOS, subject bias and subject inconsistencies. This is also optional as any other library can be used to acquire the same plots.
ZREC_Mos_Recovery.py file contains all the necessary functions.
The script contains 5 functions as follows:
zrec_mos_recovery: Main function to calculate recovered MOS, corresponding CIs, subject bias, subject inconsistency and content ambiguity.
zrec_percentile_recovery: Alternative function, to recover percentile opinion score as well as subject bias, subject inconsistency. Especially useful for JND dataset and SUR prediction use-cases.
weighted_avg_std: A utility function required in zrec_mos_recovery
plot_subject_inconsistency_bias: Function to plot estimated subject inconsistencies and bias.
plot_mos_ci: Function to plot recovered MOS and corresponding CI values.
NETFLIX Public dataset is given as an example in /data/NETFLIX.csv file. The dataset contains 26 subjects and 79 stimuli. CSV file contains a 26x79 tabular data where each row corresponds to a unique observer and each column corresponds to a unique stimuli.
Input datasets should follow the same format (subjects at the rows, stimuli at the columns) and should be inputted as a numpy array to the functions described in Usage.
The model is designed to work with partial data or missing/corrupted entries therefore can handle NaN entries in the input matrix. Therefore if the input dataset has any missing entries, they should be represented with NaN values.
Recovered MOS and corresponding CIs
Subject Inconsistencies and Biases
