Week 2
This week we're going to talk about faces. This page serves both as the course notes for a class in the "Appropriating New Technologies" half-semester class, and the independent "Face as Interface" workshop.

One of the most salient objects in our day-to-day life is the human face. Faces are so important that the impairment of our face-processing ability is seen as a disorder, called prosopagnosia while unconsciously seeing faces where there are none is an almost universal kind of pareidolia.
Without any effort, we maintain a massively multidimensional model that can recognize minor variations in shape and color. One theory says that color vision evolved in apes to help us empathize.

Structurally, Chernoff faces use 18 dimensions.

The Facial Action Coding System (FACS) uses 46 dimensions.
When talking about computers vision and faces, there are three major modifiers on the word "face": detection, recognition, and tracking. Each of these has a specific meaning, though they are sometimes used loosely:

- Detection is a binary classification task. That means it's only about deciding whether something is a face or not. Detection means knowing the difference between a face and a non-face.

- Recognition is about association, or naming. Recognition means knowing the difference between my face and your face.

- Tracking is about detection, and possibly recognition, over time. Tracking means knowing that the face in this frame of video is the same as the face in the last frame of video.
When you start talking about properties of the face itself, you will also hear:

- Pose describes the position and orientation of the face.

- Expression describes the gesture the face is making.
Despite the fact that other methods of identification (such as fingerprints, or iris scans) can be more accurate, face recognition has always remains a major focus of research because of its non-invasive nature and because it is people's primary method of person identification. (Tanzeem Choudhury)
As early as the 1960s, computers were aiding humans with face identification. Woodrow Bledsoe was one of the original researchers. In 1959 he worked on letter recognition using photocell mosaics at Sandia Corporation. In 1964/65 he worked with Helen Chan and Charles Bisson on the first face recognition algorithms at Panoramic Research, Inc. The algorithms were based on matching image that were manually marked up, so it worked but didn't scale well. Not very much of this work was published, "because the funding was provided by an unnamed intelligence agency that did not allow much publicity".
In 1988/89 researchers developed techniques for automatically recognizing faces if the face was already aligned and normalized. They used techniques like principal components analysis, and neural networks for classification. In 1991 this technique was extended to face detection.
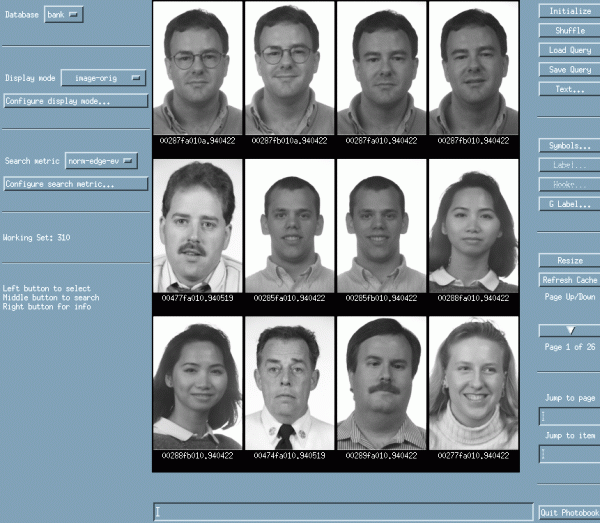
One of the first databases to offer a baseline for comparing different algorithms was called The Facial Recognition Technology (FERET) Database. It was developed from 1993-1997 and is still in use today.
The goal of the FERET program was to develop automatic face recognition capabilities that could be employed to assist security, intelligence, and law enforcement personnel in the performance of their duties. ... Total funding for the program was in excess of $6.5 million. (NIST)
To get a better idea of what these faces look like, watch this video that shows the result of some code run on the database.
Face recognition became especially controversial in 2001:
The technology first captured the public’s attention from the media reaction to a trial implementation at the January 2001 Super Bowl, which captured surveillance images and compared them to a database of digital mugshots. (US Government Subcommittee on Biometrics)


Wired has a good article with some thoughts on whether it was constitutional, and relating some of the fears at the time.
"We do not believe that the public understands or accepts that they will be subjected to a computerized police lineup as a condition of admission." (American Civil Liberties Union)
One of the developers of the system downplayed the privacy issues:
It's not automatically adding people to the database. It's simply matching faces in field-of-view against known criminals, or in the case of access control, employees who have access. So no one's privacy is at stake, except for the privacy of criminals and intruders. (Frances Zelazney)
A more complete technical overview of the system used at the Super Bowl is available from Security Solutions. Due to complaints and false positives, the system was not used in 2002. Instead, the Super Bowl was designated a National Special Security Event , for which the Secret Service provides security, frequently employing snipers and other unusual force.
The city of Tampa, where the 2001 Super Bowl was held, spent $8 million in federal grants to improve the system and now has officers regularly using it at traffic stops. While there were no arrests at the Super Bowl, the system has since aided in more than 500 arrests. In late 2001 the ACLU released an amazing anti-surveillance opinion piece called Your Face Is Not a Bar Code: Arguments Against Automatic Face Recognition in Public Places, but in 2008, they changed their opinion:
If it has a high success rate, then maybe it is an effective tool. (Bruce Howie, chair of the legal panel for the Pinellas chapter of the American Civil Liberties Union)
Since 2006, using the right kind of data, some algorithms have been able to uniquely identify identical twins.
Today, the combination of face detection with publicly available social network information can correctly predict your Facebook profile and the first five digits of your SSN for a third of the public, in under three seconds:
Our study is less about face recognition and more about privacy concerns raised by the convergence of various technologies. There is no obvious answer and solution to the privacy concerns raised by widely available face recognition and identified (or identifiable) facial images. Google's Eric Schmidt observed that, in the future, young individuals may be entitled to change their names to disown youthful improprieties. It is much harder, however, to change someone's face.
Reading more of this research there's a Catch-22: the reason they can do this kind of matching is because there's a ton of data online, but in the future it will take more time to match people because there will be too much data online. As an aside, it's worth noting that that this research is partially funded by the U.S. Army Research Office.
This kind of research is dispersing into pop culture with games like Watch Dogs.
In the early 1960s, Paul Ekman set out to discover whether facial expressions for communicating emotions are universal or cultural. He travelled the world with photographs of distinct faces, even traveling to remote locations, and found that they were interpreted consistently.
In the late 1960s, he continued his research with Wallace Friesen, and they spent a huge amount of time making faces at each other, unpacking the different muscles and labeling their combinations. This system is called the Facial Action Coding System (FACS). They discovered an interesting side effect:
"What we discovered is that that expression alone is sufficient to create marked changes in the autonomic nervous system. When this first occurred, we were stunned. We weren't expecting this at all. And it happened to both of us. We felt terrible . What we were generating was sadness, anguish. And when I lower my brows, which is four, and raise the upper eyelid, which is five, and narrow the eyelids, which is seven, and press the lips together, which is twenty-four, I' m generating anger. My heartbeat will go up ten to twelve beats. My hands will get hot. As I do it, I can't disconnect from the system. It's very unpleasant, very unpleasant." (Paul Ekman inThe Naked Face)
Some of the expressions described by FACS occur for very short bursts of time like 1/15th or 1/25th of a second. These are called microexpressions. There are apocryphal stories, and some scientific studies, about "truth wizards"; a 1 in 1000 trait that allows people to identify these microexpressions and make insightful judgements about whether someone is lying.
Ken Perlin has a great example of a randomized FACS system. I've done some experiments with randomized, unshaded FACS systems and using FFT bins to determine the action unit weights.
If an expression changes very slowly, we have difficulty keeping track of the change. This is called change blindness to gradual face changes.
If we maintain an expression for too long because our environment requires it, we can start to have emotional trauma. This is a documented problem in the service industry in Japan and Korea where employees are expected to constantly maintain smiles, creating a disorder called smile mask syndrome.

Daito Manabe is obsessed with the idea of expression transfer, and has spent a lot of time sensing and actuating expressions. He is best know for his work Electric Stimulus to Face -test3.

The Artifacial project by Dutch artist Arthur Elsenaar started in the 90s (performed as early as 1995) is an extensive artistic research into the externally controlled human face as a site for artistic expression. Some of Elsenaar's work draws on traditional formal structure such as phasing. For more insight, see Electric Body Manipulation as Performance Art: A Historical Perspective.
Consider expression transfer in the context of our natural empathic response to pain.

Though artists like Jason Salavon have made entire careers out of averaging images, there is still plenty to explore. The face of tomorrow approaches face averaging with international perspective. Luke DuBois normalizes multiple faces over time: with Britney he only uses images of the pop icon, in Play only the faces of Playboy centerfold models, and in A more perfect union he uses online dating profiles. All of Luke's faces are manually aligned using custom software where he defines the eye positions. Picasa's Face movies create a similar effect automatically.

If you have just two eye positions, you can normalize or do a basic average of multiple faces. If you have an entire mesh you can explore more advanced topics like face substitution, face morphing, and caricatures. Keith Lafuente has an excellent face substitution project called Mark and Emily that deals with sexual identity and cultural norms, and the relationship between identity and technology.
And keep in mind, you don't have to warp peoples faces using a computer. You can always ask them to pose.
The Machine Perception Toolbox (MPT) is a computer vision toolkit from UCSD. One of the unofficial releases supported smile detection, but there was no documentation. Theo Watson studied the structure of MPT and got an example compiling, eventually creating two wrappers (ofxSmile and ofxBlink) that used the undocumented features. From this wrapper came Autosmiley, then I collaborated with Theo on Happy Things.

In 2003, the researchers behind MPT worked with Christian Moeller on "Cheese", one of the best commentaries on computational face analysis yet.
Computationally distinguishing a genuine smile from a fake one is not trivial. But there is a new technique that uses video instead of images to figure it out.
Haar object detection is the de facto standard for realtime face detection. The technique was developed in 2001 by Paul Viola and Michael Jones, so it is most properly called "Viola-Jones Detection", but because it uses "Haar-like features" it is often just called "Haar detection". Indeed, the OpenCV implementation is named cvHaarDetectObjects() or CascadeClassifier::detectMultiScale(). Haar detection is relevant because it takes advantage of two techniques. One is called integral images, which speed up the feature evaluation. The other is called AdaBoost, which reduces the number of features that need to be tested.

One of the best demonstrations of how Haar detection works comes from a former ITP student, Adam Harvey: OpenCV Face Detection: Visualized. The video demonstrates how a decision tree containing thresholded classifiers can be evaluated at different scales on an image to detect an object. There's an interview with Adam where he describes how it works. Adam made this for a great project called CV Dazzle that explores techniques for fooling this algorithm with makeup. You can also avoid face recognition by keeping your head tilted.
The object that is detected depends solely on the decision tree, and this decision tree is generated by training against a collection of positive and negative examples. This means that Haar detection can be used for any two dimensional object in a scale and translation invariant way. Haar detection cannot handle significant rotation in any axis, or skew, or significant color variations. The video HP computers are racist popularized the fact that Haar detection is not robust against significant color variation. Sometimes setting thresholds properly is important too.
The process of generating a decision tree from examples is based on first creating a list of features, then evaluating those features on the different images. A feature might be something like "an image where the left is more white, and the right is more black". When you check this feature on the image, you get a single value that tells you how well the feature matches the image. You do this for all the negative examples (non-faces), and let's say you get a bunch of low numbers. Then you do it for all the positive (faces) examples and you get a bunch of high numbers. That means that when this feature returns a higher value, it's more likely to be a face.
You repeat this process for all the different features (there are thousands of them, at different sizes and positions) and you build a bunch of thresholds that help you decide whether something is a face or non-face based just on the feature values. Then, instead of evaluating all of the features whenever you want to search an image, you evaluate them in a tree-like fashion: first testing the features that are the best indicators of whether something is a face, then the ones that are less discriminatory but still give you a hint.
Haar detection will only tell you if and where a face is present, and how large it is. It doesn't know anything about orientation, the outline, or the expression.

Active Shape Models (ASM) are an advanced detection technique that tries to fit a shape to an object. It uses external information (like Haar detection) to make an initial guess, and then iteratively refines the guess. The iterative process involves two steps:
- A "procrustes alignment" step where each point is moved slightly to a better location in image space. This might be based on looking for strong edges or other features.
- A model adjustment step, where the new positions of all the points are used to make a better guess about the global properties of the shape like scale, position, and orientation.

ASM is extended by Active Appearance Models (AAM), which uses all the features of ASM but also takes into account the texture within the shape (the "appearance"). During the iterative refinement step, AAM will check the current texture against the trained texture, and use that to refine its guess.
With ASM and AAM, it is possible to recover not just the position and scale of a face, but the entire pose and expression.
The original ASM implementation was written in 1995 for Matlab, and AAM was introduced by the same authors in 1998. The authors have also posted explanations of the techniques as well as software for "research/non-commercial" use.
A number of different ASM and AAM implementations exist. Two significant open source contributions are aamlib (poor accuracy) and Stasm (not quite realtime). A leading commercial implementation is FaceAPI, which recently started offering a free non-commercial version, presumably to compete with the other available open source software.
But in my opinion, the current de facto standard in the arts for advanced face tracking is Jason Saragih's FaceTracker library, which is a beautiful implementation of ASM using OpenCV 2.0, trained on the CMU MultiPIE database. The best reference for understanding how it works in detail is his most recent article on face tracking, Deformable Model Fitting by Regularized Landmark Mean-Shift. Jason wrote FaceTracker to fill a gap in available ASM implementations:
...those directly working on face alignment and tracking often find implementing an algorithm from published work to be a daunting task, not least because baseline code against which performance claims can be assessed does not exist. As such, the goal of FaceTracker is to provide source code and pre-trained models that can be used out-of-the-box... (Jason Saragih)


{kind=link}
Both Haar detection and AAM can be "fooled" by non-faces in similar ways to humans. Greg Borenstein has a good study of FaceTracker-based pareidolia (satirized by Dan Paluska with The Holy Toaster), while Ghosts in the Machine explores the concept with Haar cascades searching through noise for faces.
If you're following along as part of a "Face as Interface" workshop, we're going to use FaceOSC and use the FaceOSC Processing sketches to get us started.
Otherwise, if you're following as part of "Appropriating New Technologies" we're going to focus on openFrameworks apps: the best place to get started with face detection in OF is the opencvHaarFinderExample that ships with the OF release. We'll take a quick look at this and talk about how it's set up.
FaceTracker is released with a command-line tool, as is commonly done with research-grade computer vision apps. We'll look at this and spend some time talking about how it turned into ofxFaceTracker.
Once we understand Haar detection and FaceTracker, we can look at FaceSubstitution and image cloning.
First, pick your technique. From least to most difficult:
- ofxCvHaarFinder
- FaceOSC and the FaceOSC-Receiver from Dan Wilcox.
- ofxFaceTracker: if you want to work with ofxFaceTracker, you need to contact Jason Saragih immediately for the FaceTracker source, and download ofxCv as well.
- Eigenfaces have been used since the 80s, but are still important for recognition. No wrapper is currently available for openFrameworks, but there is a lot of example code available for OpenCv.
Second pick one or more of the following:
- Create a system that amplifies facial gestures. What gesture do you think is most interesting, or most ignored?
- Create an inverse surveillance or personal surveillance system.
- Use facial information to create a single image or video that represents a group of people. It can't be an average face or a Picasa-style "face movie".
- Create a "mirror" that gives people a novel understanding of their own face, or challenges their sense of identity. You may create this in an installation format, or for your own personal reflection.
Third:
- Post the source code for your project in your branch on GitHub.
- Post a documentation (description, video, image, etc.) wherever you like.
- Post a link to the source and documentation under Week-2-assignment-documentation
Finally, you should find your favorite example of a face-based media art piece (interactive or not) and add it to the list on the wiki.
Computer Vision for Artists and Designers: Pedagogic Tools and Techniques for Novice Programmers is a slightly dated but excellent essay from Golan Levin. It's a quick read, and to understand face tracking in context you need to understand computer vision.
Pages Section 14.1 up to and including 14.2 (approximately 28 pages) of Szeliski's "Computer Vision: Algorithms and Applications". This is a brief summary of the things we discussed in class. It's incredibly dense and scientific/mathematical. Don't worry about understanding everything, just get a feeling for how scientists talk about these topics.