Preforming language detection on several texts using machine learning algorithms.
methodology followed in the project is represented in this map:
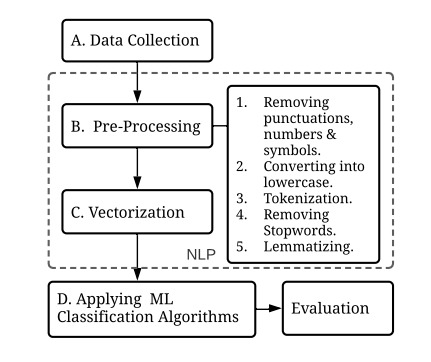
1-Data unserstanding we started by data collection, using the selenium python library we scraped data from twitter we basically foccused on scrapping data in 3 different languages: Darija, French and English. Then we explored our dataset to understand it's specifities and caracteristics.
2-Data preprocessing This is one of the most important steps in any modelisation probleme, data preprocessing plays a crucial role since the modelisation technics are not equipped to process non-structed data especially in our case, where we're dealing with textual data. well see more details further in the notebook.
3-Modeling After getting our data ready, and compatible with machine learning algorithms inputs, we're ready tobuild our model, the challenge here is that we have several types of algorithms and we will have to chose which one preforms the best in our case.
4-Evaluation After building our models we move to evaluationg them using different technics.
After succesfully cleaning our dataset, we move to building the matrix how is it done?
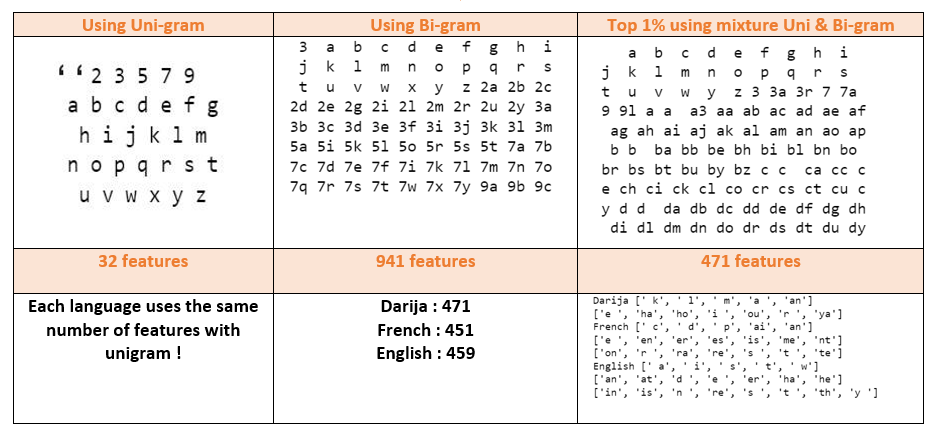
To move on to the creation of machine learning models, we must first transform the text into a data matrix that corresponds to the processing by ML algorithms, while trying to minimizing the loss of information as much as possible. each line in our dataset will represent the lines of our matrix hence we speak of a vector presentation, but in order to determine the features or the indexes we will use the countvectorizer. The countvectorizer has many parameters to do indexation we have chosen to use the N-gram of letters. Here's a schema of what we're going to do using n-gram

vector presentation of languages using uni-gram

Let's take an exemple to understand what's going on:
Here's how does the countvectorizer work:

Ps: in this exemple we're refering to the uni-gram parameter, it's pretty clear since the size of the constracted vector is equal to 32 which is the number of unique features in uni-gram!
top bigrams (>1%) for each language

Let's take an exemple to understand what's going on:
Here's how does the countvectorizer work:


Ps: in this exemple we're refering to the bi-gram parameter, the size of the constracted vector is equal to 941 which is the number of unique features in bi-grams!
top Mixture (>1%) for each language




Let's take an exemple to understand what's going on:
Here's how does the countvectorizer work:


Ps: in this exemple we're refering to the mixture parameter, the size of the constracted vector is equal to 471 .
top 60 Mixture for each language


Let's take an exemple to understand what's going on:
Here's how does the countvectorizer work:

For this problem, we used 3 classification models:
Result: After applying k-fold cross validation, we found that Logistic regression using Top 1% Mixture is the best model, because it was able to distinguish more or less between the languages.