git使用用户名密码clone的方式:
git clone http://username:password@remote
eg: username: abc@qq.com, pwd: test, git地址为git@xxx.com/test.git
git clone http://abc%40qq.com:test@git@xxx.com/test.git
最近在Linux里面使用pip安装应用的速度十分的慢,于是便上网找了一些国内的源。
清华大学:https://pypi.tuna.tsinghua.edu.cn/simple
阿里云:https://mirrors.aliyun.com/pypi/simple
中国科学技术大学 https://pypi.mirrors.ustc.edu.cn/simple
豆瓣:http://pypi.douban.com/simple
修改pip为国内源
修改家目录隐藏的配置文件
vim ~/.pip/pip.conf
一般配置文件不存在的,如果上诉方法不行这执行下面步骤
1 cd ~ && mkdir .pip
2 cd .pip && vim pip.conf
然后修改pip.conf的内容为
1 [global]
2 index-url = https://pypi.tuna.tsinghua.edu.cn/simple
大功告成。
pip install lightgbm -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
一、安装前的检查
1.0 关闭系统防火墙
关闭系统的防火墙
systemctl stop firewalld
systemctl disable firewalld
1.1 检查 linux 系统版本
[root@rabbitmq2~]# cat /etc/system-release
CentOS Linux release 7.3.1611 (Core)
1.2 检查是否安装了 mysql
[root@rabbitmq2~]# rpm -qa | grep mysql
若存在 mysql 安装文件,则会显示 mysql安装的版本信息
如:mysql-connector-odbc-5.2.5-6.el7.x86_64
卸载已安装的MySQL,卸载mysql命令,如下:
[root@rabbitmq2~]# rpm -e --nodeps mysql-connector-odbc-5.2.5-6.el7.x86_64
将/var/lib/mysql文件夹下的所有文件都删除干净。
细节注意:
检查一下系统是否存在 mariadb 数据库,如果有,一定要卸载掉,否则可能与 mysql 产生冲突。
检查是否安装了 mariadb:[root@rabbitmq2~]# rpm -qa | grep mariadb
如果有就使劲卸载干净:
systemctl stop mariadb rpm -qa | grep mariadb rpm -e --nodeps mariadb-5.5.52-1.el7.x86_64 rpm -e --nodeps mariadb-server-5.5.52-1.el7.x86_64 rpm -e --nodeps mariadb-libs-5.5.52-1.el7.x86_64
1.3 系统内存检查
检查一下 linux 系统的虚拟内存大小,如果内存不足 1G,启动 mysql 的时候可能会产生下面这个错误提示:
Starting mysqld (via systemctl): Job for mysqld.service failed because the control process exited with error code.
See "systemctl status mysqld.service" and "journalctl -xe" for details.[FAILED]
二、从 mysql 官网下载并上传 mysql安装包
2.1 下载 mysql 安装包
https://dev.mysql.com/downloads/mysql/5.7.html#downloads
2.2 上传安装文件到 linux 系统
[root@rabbitmq2~]# rz -y
mysql-5.7.26-linux-glibc2.5-x86_64.tar.gz
三、安装 mysql
3.1 解压安装包,并移动至 home 目录下
解压 mysql 的 gz 安装包:
[root@rabbitmq2pub]# mv mysql-5.7.26-linux-glibc2.5-x86_64/* /usr/lcoal/mysql/
将文件移动到 /usr/local 目录下,并重命名文件夹
[root@rabbitmq2pub]# mkdir /usr/local/msyql
/usr/local 目录下创建文件夹存 mysql:
[root@rabbitmq2pub]# tar -zvxf mysql-5.7.26-linux-glibc2.5-x86_64.tar.gz
3.2 添加系统用户
添加 mysql 组和 mysql 用户:
添加 mysql 组:[root@rabbitmq2~]# groupadd mysql
添加 mysql 用户:[root@rabbitmq2~]# useradd -r -g mysql mysql
扩展:
useradd -r -g mysql -s /bin/false mysql
-s /bin/false参数指定mysql用户仅拥有所有权,而没有登录权限
查看是否存在 mysql 组:[root@rabbitmq2~]# more /etc/group | grep mysql
查看 msyql 属于哪个组:[root@rabbitmq2~]# groups mysql
查看当前活跃的用户列表:[root@rabbitmq2~]# w
3.3 检查是否安装了 libaio
[root@rabbitmq2~]# rpm -qa | grep libaio
若没有则安装
版本检查:[root@rabbitmq2~]# yum search libaio
安装:[root@rabbitmq2~]# yum -y install libaio
3.3 安装 mysql
进入安装 mysql 软件目录:
[root@rabbitmq2~]# cd /usr/local/mysql/
安装配置文件:
[root@rabbitmq2 mysql]# cp ./support-files/my-default.cnf /etc/my.cnf
(提示是否覆盖,输入“ y ”同意)
修改被覆盖后的 my.cnf:[root@rabbitmq2mysql]# vim /etc/my.cnf
[mysqld]
port=3306
#设置安装目录
basedir=/usr/local/mysql
# 设置mysql数据库的数据的存放目录
datadir=/usr/local/mysql/data
socket=/tmp/mysql.sock
user=mysql
tmpdir=/tmp
# 开启ip绑定
bind-address = 0.0.0.0
# 允许最大连接数
max_connections=200
# # 服务端使用的字符集默认为8比特编码的latin1字符集
character-set-server=utf8mb4
collation-server=utf8mb4_general_ci
# 创建新表时将使用的默认存储引擎
default-storage-engine=INNODB
innodb_buffer_pool_size=64MB
max_allowed_packet=16M
[mysqld_safe]
log-error=/usr/local/mysql/data/error.log
pid-file=/usr/local/mysql/data/mysql.pid
[mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8mb4
[client]
#指定客户端连接mysql时的socket通信文件路径
socket=/tmp/mysql.sock
default-character-set=utf8mb4
#!includedir /etc/my.cnf.d创建 data 文件夹:
[root@rabbitmq2 mysql]# mkdir ./data
修改当前目录拥有者为 mysql 用户:
[root@rabbitmq2 mysql]# chown -R mysql:mysql ./
初始化 mysqld:
[root@rabbitmq2mysql]# ./bin/mysqld --initialize --user=mysql --basedir=/usr/local/mysql/ --datadir=/usr/local/mysql/data/
启动mysql服务: ./support-files/mysql.server start
四、配置 mysql
4.1 设置开机启动
a. 复制启动脚本到资源目录(需要新建mysqld文件夹):
[root@rabbitmq2 mysql]# cp support-files/mysql.server /etc/init.d/mysqld
b. 增加 mysqld 服务控制脚本执行权限:(不使用)
[root@rabbitmq2 mysql]# chmod +x /etc/rc.d/init.d/mysqld
c. 将 mysqld 服务加入到系统服务:(不使用)
[root@rabbitmq2 mysql]# chkconfig --add mysqld
d. 检查mysqld服务是否已经生效:(不使用)
[root@rabbitmq2 mysql]# chkconfig --list mysqld
命令输出类似下面的结果:
mysqld 0:关 1:关 2:开 3:开 4:开 5:开 6:关
表明mysqld服务已经生效,在2、3、4、5运行级别随系统启动而自动启动,以后可以使用 service 命令控制 mysql 的启动和停止。
查看启动项:chkconfig --list | grep -i mysql
删除启动项:chkconfig --del mysql(这个可以不执行)
e. 启动 mysqld:[root@rabbitmq2mysql]# service mysqld start
4.2 环境变量配置
将mysql的bin目录加入PATH环境变量,编辑 /etc/profile文件:
[root@rabbitmq2 mysql]# vim /etc/profile
export PATH=$PATH:/usr/local/mysql/bin
执行命令使其生效:
[root@rabbitmq2 mysql]# source /etc/profile
用 export 命令查看PATH值:
[root@rabbitmq2 mysql]# echo $PATH
五、登录 mysql
5.1 测试登录
登录 mysql:[root@rabbitmq2 mysql]# mysql -uroot -p(登录密码为初始化的时候显示的临时密码)
如果出错 ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: YES)
1、先停掉原来的服务
service mysqld stop
2、使用安全模式登陆,跳过密码验证
mysqld_safe --user=mysql --skip-grant-tables --skip-networking&或./mysqld_safe --skip-grant-tables(mysql/bin)
3.使用root账户,无密码登录,修改root用户密码
mysql/mysql -uroot
4.修改root密码
update user set password=PASSWORD("你的密码") where User = 'root';(最好先使用desc 表名 查看表结构后操作)
mysql5.7 没有password列
update mysql.user set authentication_string=password('123qwe') where user='root';
flush privileges;
alter user user() identified by "123456";或alter user 'root'@'localhost' identified by '123';初次登录需要设置密码才能进行后续的数据库操作:SET PASSWORD = PASSWORD('password');(密码设置根据实际提供密码设置)
设置允许远程连接数据库,命令如下:
先选择数据库:
use mysql
update user set user.Host='%' where user.User='root';
update user set authentication_string=PASSWORD('password') where User='root';
强制刷新数据库
flush privileges;
5.2 防火墙端口偶设置,便于远程访问**(防火墙关闭就不用设置了)**
开启防火墙:systemctl start firewalld
[root@rabbitmq2~]$ firewall-cmd --zone=public --add-port=3306/tcp --permanent
[root@rabbitmq2~]$ firewall-cmd --reload
开启防火墙mysql3306端口的外部访问
CentOS升级到7之后,使用firewalld代替了原来的iptables。下面记录如何使用firewalld开放Linux端口
--zone : 作用域,网络区域定义了网络连接的可信等级。
这是一个一对多的关系,这意味着一次连接可以仅仅是一个区域的一部分,而一个区域可以用于很多连接
--add-port : 添加端口与通信协议,格式为:端口/通讯协议,协议是tcp 或 udp
--permanent : 永久生效,没有此参数系统重启后端口访问失效
5.3 使用 SQLyog 、Navicat远程连接出现不允许连接问题:
首先使用 dos 窗口 ping 一下 linux,排除网络连通问题,其次使用 SQLyog 连接测试一下。
解决方法:登录 linux mysql 在用户管理表新增用户帐号
mysql> use msyql
mysql> create user 'user-name'@'ip-address' identified by 'password';(红色标记为需要修改的地方)
其他方案:
授权root用户可以进行远程连接,注意替换以下代码中的“password”为 root 用户真正的密码,
另外请注意如果你的root用户设置的是弱口令,那么非常不建议你这么干!:
mysql> grant all privileges on . to root@"%" identified by "password" with grant option;
mysql> flush privileges
(maria DB如同 MySQL 的影子版本,玛莉亚数据库是 MySQL 的一个分支版本(branch),而不是衍生版本(folk),提供的功能可和 MySQL 完全兼容)。
1.安装:
yum install -y mariadb-server
2.启动maria DB服务:
systemctl start mariadb.service
(说明:CentOS 7.x开始,CentOS开始使用systemd服务来代替daemon,原来管理系统启动和管理系统服务的相关命令全部由systemctl命令来代替。)
3.添加至开机自启动:
systemctl enable mariadb.service
初始化数据库配置
mysql_secure_installation
首先是设置密码,会提示先输入密码:
设置密码
Enter current password for root (enter for none):<–直接回车
Set root password? [Y/n] <– 是否设置root用户密码,输入y并回车或直接回车 New password: <– 设置root用户的密码 Re-enter new password: <– 再输入一次你设置的密码 其他配置
Remove anonymous users? [Y/n] <– 是否删除匿名用户,Y回车
Disallow root login remotely? [Y/n] <–是否禁止root远程登录, N回车,
Remove test database and access to it? [Y/n] <– 是否删除test数据库,Y回车
Reload privilege tables now? [Y/n] <– 是否重新加载权限表,Y回车
初始化MariaDB完成,接下来测试本地登录。
配置文件位置:vim /etc/my.cnf.d/mysql-clients.cnf
开启远程访问
首先配置允许访问的用户,采用授权的方式给用户权限GRANT ALL PRIVILEGES ON *.* TO 'root'@'%'IDENTIFIED BY '123456' WITH GRANT OPTION;最后配置好权限之后不应该忘记刷新使之生效 说明:root是登陆数据库的用户,123456是登陆数据库的密码,*就是意味着任何来源任何主机反正就是权限很大的样子。flush privileges;再次访问就可以了吧。开启centOS7的防火墙端口3306:https://www.cnblogs.com/moxiaoan/p/5683743.html
1、登陆mysql数据库
mysql -u root -p
查看user表
mysql> use mysql; Database changed mysql> select host,user,password from user; +--------------+------+-------------------------------------------+ | host | user | password | +--------------+------+-------------------------------------------+ | localhost | root | *A731AEBFB621E354CD41BAF207D884A609E81F5E | | 192.168.1.1 | root | *A731AEBFB621E354CD41BAF207D884A609E81F5E | +--------------+------+-------------------------------------------+ 2 rows in set (0.00 sec)
可以看到在user表中已创建的root用户。host字段表示登录的主机,其值可以用IP,也可用主机名,
(1)有时想用本地IP登录,那么可以将以上的Host值改为自己的Ip即可。
2、实现远程连接(授权法)
将host字段的值改为%就表示在任何客户端机器上能以root用户登录到mysql服务器,建议在开发时设为%。
update user set host = ’%’ where user = ’root’;
将权限改为ALL PRIVILEGES
mysql> use mysql; Database changed mysql> grant all privileges on . to root@'%' identified by "password"; Query OK, 0 rows affected (0.00 sec)
mysql> flush privileges; Query OK, 0 rows affected (0.00 sec)
mysql> select host,user,password from user; +--------------+------+-------------------------------------------+ | host | user | password | +--------------+------+-------------------------------------------+ | localhost | root | *A731AEBFB621E354CD41BAF207D884A609E81F5E | | 192.168.1.1 | root | *A731AEBFB621E354CD41BAF207D884A609E81F5E | | % | root | *A731AEBFB621E354CD41BAF207D884A609E81F5E | +--------------+------+-------------------------------------------+ 3 rows in set (0.00 sec)
这样机器就可以以用户名root密码root远程访问该机器上的MySql.
3、实现远程连接(改表法)
use mysql;
update user set host = '%' where user = 'root';
这样在远端就可以通过root用户访问Mysql.
环境:Centos 6.5
Linux 使用yum命令安装mysql
- 先检查系统是否装有mysql
[root@localhost ~]#yum list installed mysql* [root@localhost ~]#rpm –qa|grep mysql*
- 查看有没有安装包
[root@localhost ~]#yum list mysql*
- 安装mysql客户端
[root@localhost ~]yum install mysql
- 安装mysql服务端
[root@localhost ~]#yum install mysql-server
CentOS7下解决yum install mysql-server 异常:No package mysql-server available.问题
yum安装mysql-server没有可用包问题解决方法:
step 1: wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm
step 2: rpm -ivh mysql-community-release-el7-5.noarch.rpm
经过以上两个步骤后再次执行:yum install mysql-server 命令就可以成功安装了
[root@localhost ~]#yum install mysql-devel
- 在/etc/my.cnf 文件中加入默认字符集
[root@localhost ~]#vim /etc/my.cnf
default-character-set=utf8/ character-set-server = utf8
bind-address=0.0.0.0
- 启动或者关闭mysql服务
[root@localhost ~]#service mysqld start --启动mysql 或者 /etc/init.d/mysqld start (关闭mysql #service mysql stop)
- 设置开机启动mysql服务
[root@localhost ~]# chkconfig --add mysqld
-
创建root用户 密码为123456
mysqladmin –u root password 123456
[root@localhost ~]# mysqladmin -u root password 123456
- 连接mysql
[root@localhost ~]# mysql -u root -p --输入密码123456
- 设置远程访问权限
mysql> use mysql mysql> GRANT ALL PRIVILEGES ON . TO root@’%’IDENTIFIED BY ‘123456’ WITH GRANT OPTION; --第一个admin为用户名,第二个admin为密码,%表示所有的电脑都可以链接 mysql> flush privileges; --设置立即生效
mysql> SELECT DISTINCT CONCAT('User:''',user,'''@''',host,''';') AS query FROM mysql.user; mysql> exit; --退出mysql服务 [root@localhost ~]# vi /etc/my.cnf
[mysqld] datadir=/var/lib/mysql socket=/var/lib/mysql/mysql.sock user=mysql default-character-set=utf8
Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0 #设备地址 bind-address=0.0.0.0 #设置设备地址
[mysqld_safe] log-error=/var/log/mysqld.log pid-file=/var/run/mysqld/mysqld.pid
[root@localhost ~]# service mysqld start --重启mysql服务
[root@localhost ~]# mysql -u root -p --连接mysql输入密码
mysql> show global variables like 'port'; --查看端口号 +---------------+-------+ | Variable_name | Value | +---------------+-------+ | port | 3306 | +---------------+-------+ 1 row in set (0.00 sec)
10.使用navcat连接mysql
我下载的是64位系统的zip包:
下载地址:https://dev.mysql.com/downloads/mysql/
下载zip的包:
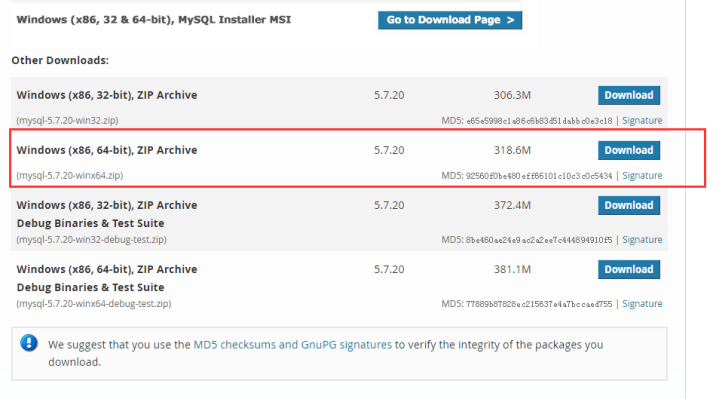
下载后解压:D:\软件安装包\mysql-5.7.20-winx64
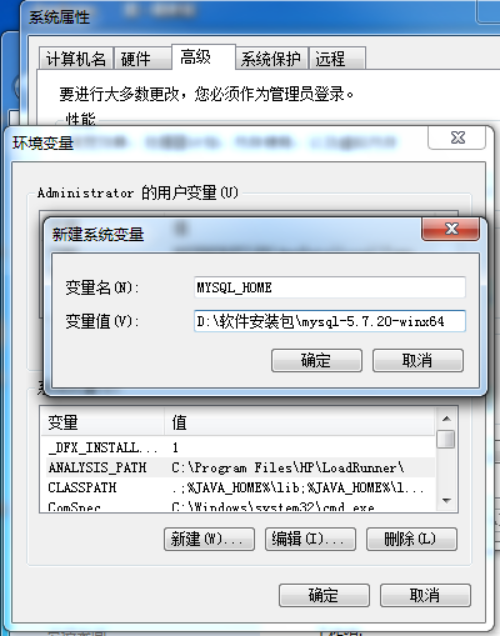
变量名:MYSQL_HOME
变量值:E:\mysql-5.7.20-winx64
path里添加:%MYSQL_HOME%\bin;
以管理员身份运行cmd
进入E:\mysql-5.7.20-winx64\bin 下
执行命令:mysqld --initialize-insecure --user=mysql 在E:\mysql-5.7.20-winx64目录下生成data目录

执行命令:net start mysql 启动mysql服务,若提示:服务名无效...(后面有解决方法==步骤:1.5);
提示:服务名无效
解决方法:
执行命令:mysqld -install 即可(不需要my.ini配置文件 注意:网上写的很多需要my.ini配置文件,其实不需要my.ini配置文件也可以,我之前放置了my.ini文件,反而提示服务无法启动,把my.ini删除后启动成功了)
若出现下图,需要去资源管理器中把mysql进程全结束了,重新启动即可。

登录mysql:(因为之前没设置密码,所以密码为空,不用输入密码,直接回车即可)
E:\mysql-5.7.20-winx64\bin>mysql -u root -p
Enter password: ******
查询用户密码命令:mysql> select host,user,authentication_string from mysql.user;
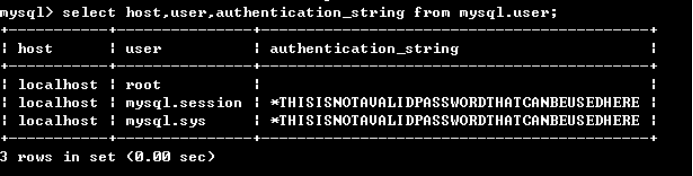
设置(或修改)root用户密码:
mysql> update mysql.user set authentication_string=password("123456") where user
="root"; #password("123456"),此处引号中的内容是密码,自己可以随便设置
Query OK, 1 row affected, 1 warning (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 1
mysql> flush privileges; #作用:相当于保存,执行此命令后,设置才生效,若不执行,还是之前的密码不变
Query OK, 0 rows affected (0.01 sec)
mysql> quit
Bye
在windows平台下使用python内置函数 open() 时发现,当不传递encoding参数时,会自动采用gbk(cp936)编码打开文件,而当下很大部分文件的编码都是UTF-8。
我们当然可以通过每次手动传参encoding='utf-8',但是略显冗余,而且有很多外国的第三方包,里面调用的内置open()函数并没有提供接口让我们指定encoding,这就会导致这些包在windows平台上使用时,常会出现如 "UnicodeDecodeError: 'gbk' codec can't decode byte 0x91 in position 209: illegal multibyte sequence" 的报错
通过查看python文档分析原因:
if encoding is not specified the encoding used is platform dependent: locale.getpreferredencoding(False) is called to get the current locale encoding. (For reading and writing raw bytes use binary mode and leave encoding unspecified.)
可以发现当open不传递encoding参数时,是默认调用locale.getpreferredencoding()方法来获取当前平台的“默认编码类型”,继续查看相关文档,发现有两种方法可以指定windows平台下Python运行时的“默认编码类型”。
通过运行脚本是添加命令行参数 -X utf8(注意是跟在python.exe后面的interpreter option,不是跟在要运行脚本后面的parameters!)
指定sys.flags.utf8_mode参数之后,Python运行时会在很多场景下自动使用utf-8编码,而不是win默认的gbk(cp936)编码。
import _locale
_locale._getdefaultlocale = (lambda *args: ['en_US', 'utf8'])
复制代码
python解释器会取_getdefaultlocale()[1]作为默认编码类型,重写后,会改变当前运行环境下的所有模块的默认编码。
总之,使用以上两种方法后,windows平台下,open()函数会默认用utf-8编码打开文件,其实不止open()方法,跨模块、全局改变python解释器的默认编码为utf-8,会带来很多使用上的便利,而不需要被gbk编码报错的噩梦所纠缠。
系统环境win7
1.下载 nodejs 32bit的,得到一个node.exe文件
\2. 设置环境变量;
3.下载 npm文件,得到一个zip文件,解压到nodejs的目录下,这个时候,nodejs目录下有:
文件node.exe 、文件夹 node_modules、文件npm.cmd 共三个文件(夹)
4.安装 python2.7,设置环境变量;
\5. 安装 visual c++ 2010;
\6. 执行 npm install jsdom [-g]全局环境
7.搞定!
安装的问题:之前 执行第6步的时候,总是提示:
“C:\Users\shawn.node-gyp\0.10.13\Release\node.lib : fatal error LNK1106: 文件无 效或磁 盘已满: 无法查找到 0x164FE [D:\node\node_modules\jsdom\node_modules\contextify\b uild\co ntextify.vcxproj] gyp ERR! build error”
回头把目录 C:\Users\shawn.node-gyp 删掉,重新执行第6步。完成!
2018年07月10日 15:32:54 Cand6oy 阅读数:4195
因为使用多次以后发现进程中出现了很多chromedriver的残留,造成卡顿,所以决定优化一下。
这个问题困扰了楼主很久,百度谷歌查来查去都只有java,后面根据java和selenium结合看找出了python如何执行完把chromedriver进程关闭
Python的话控制chromedriver的开启和关闭的包是Service
from selenium.webdriver.chrome.service import Service
创建的时候需要把chromedriver.exe的位置写在Service的XXX部分,需要调用他的命令行方法,不然报错然后启动就可以了
c_service = Service('xxx')
c_service.command_line_args()
c_service.start()
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
关闭的时候用quit而不是采用close
close只会关闭当前页面,quit会推出驱动别切关闭所关联的所有窗口
最后执行完以后就关闭
driver.quit();c_service.stop()
嫌麻烦也可以直接使用python的os模块执行下面两句话结束进程
os.system('taskkill /im chromedriver.exe /F')
os.system('taskkill /im chrome.exe /F')
用ntpdate从时间服务器更新时间
1.如果你的linux系统根本没有ntpdate这个命令
`yum install -y ntp`
2.安装完了之后,你不要做什么配置,也不需要,直接测试一下
`[root@git conf.d]# ntpdate asia.pool.ntp.org``21 Mar 10:52:01 ntpdate[9247]: step time server 209.58.185.100 offset 38761.507576 sec`
3.如果出去上面的内容说明,同步成功了。然后在crontab里面加上以下内容。
`*/10 * * * * ntpdate asia.pool.ntp.org`
4.推荐几个时间服务器
`time.nist.gov``time.nuri.net``asia.pool.ntp.org``asia.pool.ntp.org``asia.pool.ntp.org``asia.pool.ntp.org`
CentOS 7.0默认使用的是firewall作为防火墙,使用iptables必须重新设置一下
1、直接关闭防火墙
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
2、设置 iptables service
yum -y install iptables-services
如果要修改防火墙配置,如增加防火墙端口3306
vi /etc/sysconfig/iptables
增加规则
-A INPUT -m state --state NEW -m tcp -p tcp --dport 3306 -j ACCEPT
保存退出后
systemctl restart iptables.service #重启防火墙使配置生效
systemctl enable iptables.service #设置防火墙开机启动
最后重启系统使设置生效即可。
wget http://download.redis.io/releases/redis-4.0.6.tar.gz

[root@iZwz991stxdwj560bfmadtZ local]# wget http://download.redis.io/releases/redis-4.0.6.tar.gz
--2017-12-13 12:35:12-- http://download.redis.io/releases/redis-4.0.6.tar.gz
Resolving download.redis.io (download.redis.io)... 109.74.203.151
Connecting to download.redis.io (download.redis.io)|109.74.203.151|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 1723533 (1.6M) [application/x-gzip]
Saving to: ‘redis-4.0.6.tar.gz’
100%[==========================================================================================================>] 1,723,533 608KB/s in 2.8s
2017-12-13 12:35:15 (608 KB/s) - ‘redis-4.0.6.tar.gz’ saved [1723533/1723533]
tar -zxvf redis-4.0.6.tar.gz
[root@iZwz991stxdwj560bfmadtZ local]# tar -zxvf redis-4.0.6.tar.gz
yum install gcc
[root@iZwz991stxdwj560bfmadtZ local]# yum install gcc
遇到选择,输入y即可
cd redis-4.0.6
[root@iZwz991stxdwj560bfmadtZ local]# cd redis-4.0.6
make MALLOC=libc
[root@iZwz991stxdwj560bfmadtZ redis-4.0.6]# make MALLOC=libc
将/usr/local/redis-4.0.6/src目录下的文件加到/usr/local/bin目录
cd src && make install
[root@iZwz991stxdwj560bfmadtZ redis-4.0.6]# cd src && make install
CC Makefile.dep
Hint: It's a good idea to run 'make test' ;)
INSTALL install
INSTALL install
INSTALL install
INSTALL install
INSTALL install
先切换到redis src目录下
[root@iZwz991stxdwj560bfmadtZ redis-4.0.6]# cd src
./redis-server
[root@iZwz991stxdwj560bfmadtZ src]# ./redis-server
18685:C 13 Dec 12:56:12.507 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
18685:C 13 Dec 12:56:12.507 # Redis version=4.0.6, bits=64, commit=00000000, modified=0, pid=18685, just started
18685:C 13 Dec 12:56:12.507 # Warning: no config file specified, using the default config. In order to specify a config file use ./redis-server /path/to/redis.conf
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 4.0.6 (00000000/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in standalone mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 6379
| `-._ `._ / _.-' | PID: 18685
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
18685:M 13 Dec 12:56:12.508 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
18685:M 13 Dec 12:56:12.508 # Server initialized
18685:M 13 Dec 12:56:12.508 # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
18685:M 13 Dec 12:56:12.508 # WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled.
18685:M 13 Dec 12:56:12.508 * Ready to accept connections
如上图:redis启动成功,但是这种启动方式需要一直打开窗口,不能进行其他操作,不太方便。
按 ctrl + c可以关闭窗口。
第一步:修改redis.conf文件
将
daemonize no
修改为
daemonize yes
第二步:指定redis.conf文件启动
`./redis-server /usr/local/redis-4.0.6/redis.conf`
第三步:关闭redis进程
首先使用ps -aux | grep redis查看redis进程
[root@iZwz991stxdwj560bfmadtZ src]# ps -aux | grep redis
root 18714 0.0 0.1 141752 2008 ? Ssl 13:07 0:00 ./redis-server 127.0.0.1:6379
root 18719 0.0 0.0 112644 968 pts/0 R+ 13:09 0:00 grep --color=auto redis
使用kill命令杀死进程
[root@iZwz991stxdwj560bfmadtZ src]# kill -9 18714
1、在/etc目录下新建redis目录
mkdir redis
[root@iZwz991stxdwj560bfmadtZ etc]# mkdir redis
2、将/usr/local/redis-4.0.6/redis.conf 文件复制一份到/etc/redis目录下,并命名为6379.conf
[root@iZwz991stxdwj560bfmadtZ redis]# cp /usr/local/redis-4.0.6/redis.conf /etc/redis/6379.conf
3、将redis的启动脚本复制一份放到/etc/init.d目录下
[root@iZwz991stxdwj560bfmadtZ init.d]# cp /usr/local/redis-4.0.6/utils/redis_init_script /etc/init.d/redisd
4、设置redis开机自启动
先切换到/etc/init.d目录下
然后执行自启命令
[root@iZwz991stxdwj560bfmadtZ init.d]# chkconfig redisd on
service redisd does not support chkconfig
看结果是redisd不支持chkconfig
解决方法:
使用vim编辑redisd文件,在第一行加入如下两行注释,保存退出
# chkconfig: 2345 90 10
# description: Redis is a persistent key-value database
注释的意思是,redis服务必须在运行级2,3,4,5下被启动或关闭,启动的优先级是90,关闭的优先级是10。

再次执行开机自启命令,成功
[root@iZwz991stxdwj560bfmadtZ init.d]# chkconfig redisd on
现在可以直接已服务的形式启动和关闭redis了
启动:
service redisd start
[root@izwz991stxdwj560bfmadtz ~]# service redisd start
Starting Redis server...
2288:C 13 Dec 13:51:38.087 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
2288:C 13 Dec 13:51:38.087 # Redis version=4.0.6, bits=64, commit=00000000, modified=0, pid=2288, just started
2288:C 13 Dec 13:51:38.087 # Configuration loaded
关闭:
service redisd stop
[root@izwz991stxdwj560bfmadtz ~]# service redisd stop
Stopping ...
Redis stopped
pip install web.py==0.40.dev0
引言 Selenium主要用在自动化测试中,但是也可以用在爬取数据中,由于其实真实的浏览器,则可以无缝地提取数据,而无需担心各类的数据屏蔽,这里主要介绍在CentOS上安装它们的过程以及其中碰到的各类问题记录。
环境介绍 CentOS 7.4 , Selenium 3.13.0, google chrome, Gecko Driver,这里以google的chrome为例,Gecko的过程类似。 墙内的用户建议使用Gecko Driver。 自备梯子的童鞋,则可以考虑Google Chrome的driver。
安装步骤 创建google chrome.repo文件。
vi /etc/yum.repos.d/google-chrome.repo
在文件中输入如下内容:
[google-chrome] name=google-chrome baseurl=http://dl.google.com/linux/chrome/rpm/stable/x86_64 enabled=1 gpgcheck=1 gpgkey=https://dl.google.com/linux/linux_signing_key.pub 2 执行yum的更新操作
yum update
如果顺利的话,则可以提示需要更新的内容。 在执行过程中,碰到如下问题:
---> Package fontpackages-filesystem.noarch 0:1.44-8.el7 will be installed ---> Package google-chrome-stable.x86_64 0:68.0.3440.84-1 will be installed --> Processing Dependency: libappindicator3.so.1()(64bit) for package: google-chrome-stable-68.0.3440.84-1.x86_64 ---> Package graphite2.x86_64 0:1.3.10-1.el7_3 will be installed ---> Package lcms2.x86_64 0:2.6-3.el7 will be installed ---> Package libXxf86vm.x86_64 0:1.1.4-1.el7 will be installed ---> Package libgusb.x86_64 0:0.2.9-1.el7 will be installed ---> Package libsoup.x86_64 0:2.56.0-4.el7_4 will be installed --> Processing Dependency: glib-networking(x86-64) >= 2.38.0 for package: libsoup-2.56.0-4.el7_4.x86_64 ---> Package libxshmfence.x86_64 0:1.2-1.el7 will be installed ---> Package mesa-libgbm.x86_64 0:17.0.1-6.20170307.el7 will be installed ---> Package mesa-libglapi.x86_64 0:17.0.1-6.20170307.el7 will be installed ---> Package stix-fonts.noarch 0:1.1.0-5.el7 will be installed --> Running transaction check ---> Package glib-networking.x86_64 0:2.50.0-1.el7 will be installed --> Processing Dependency: gsettings-desktop-schemas for package: glib-networking-2.50.0-1.el7.x86_64 ---> Package google-chrome-stable.x86_64 0:68.0.3440.84-1 will be installed --> Processing Dependency: libappindicator3.so.1()(64bit) for package: google-chrome-stable-68.0.3440.84-1.x86_64 --> Running transaction check ---> Package google-chrome-stable.x86_64 0:68.0.3440.84-1 will be installed --> Processing Dependency: libappindicator3.so.1()(64bit) for package: google-chrome-stable-68.0.3440.84-1.x86_64 ---> Package gsettings-desktop-schemas.x86_64 0:3.22.0-1.el7 will be installed --> Finished Dependency Resolution Error: Package: google-chrome-stable-68.0.3440.84-1.x86_64 (google-chrome) Requires: libappindicator3.so.1()(64bit) You could try using --skip-broken to work around the ’ 先是执行如下命令:
yum –enablerepo=extras install epel-release 输出信息如下;
Loaded plugins: fastestmirror, langpacks Loading mirror speeds from cached hostfile Package epel-release-7-9.noarch already installed and latest version Nothing to do 表示其已经安装成功了。于是继续安装:
yum install libappindicator-gtk3
但是依然会提示上述的错误信息,于是这里我就直接将epel-release进行了卸载和重新安装,则问题解决:
yum –enablerepo=extras reinstall epel-release yum install libappindicator-gtk3
则在yum update过程中的错误信息解决。
安装Google Chrome yum install google-chrome-stable 但是非常不幸的是,问题再次出现了,问题的错误信息如下:
Total size: 52 M Installed size: 187 M Is this ok [y/d/N]: y Downloading packages: warning: /var/cache/yum/x86_64/7/google-chrome/packages/google-chrome-stable-68.0.3440.84-1.x86_64.rpm: Header V4 DSA/SHA1 Signature, key ID 7fac5991: NOKEY Retrieving key from https://dl-ssl.google.com/linux/linux_signing_key.pub
GPG key retrieval failed: [Errno 14] curl#7 - "Failed to connect to 2404:6800:4008:c00::5d: Network is unreachable" 从错误信息上,好像是网络的某些设置被阻隔了。好吧,于是直接下载安装包,本地安装好了。
wget https://dl.google.com/linux/direct/google-chrome-stable_current_x86_64.rpm yum -y localinstall google-chrome-stable_current_x86_64.rpm
然后安装完成。
安装 chormedriver 下载地址: https://chromedriver.storage.googleapis.com/index.html?path=2.41/ 这里使用的是2.41版本,下载,解压之后,放入PATH环境变量之中。懒惰的话,也可以直接放入本地Python的bin目录中去。 放好之后,打开命令行,执行如下命令,看看是否有有效的信息输出: chromedriver 输出信息如下:
Starting ChromeDriver 2.41.578700 (2f1ed5f9343c13f73144538f15c00b370eda6706) on port 9515 Only local connections are allowed. 1 2 这个表示其被正确启动了,安装成功了。 5. 安装selenium 由于Selenium是标准的python包,这里直接基于pip进行安装。
pip install selenium
6.启动本地Spider程序 在程序启动过程中,出现了如下错误信息:
File "xxx-sy.py", line 384, in browser = webdriver.Chrome(chrome_options=chrome_options) File "/export/home/anaconda3/lib/python3.6/site-packages/selenium/webdriver/chrome/webdriver.py", line 75, in init desired_capabilities=desired_capabilities) File "/export/home/anaconda3/lib/python3.6/site-packages/selenium/webdriver/remote/webdriver.py", line 156, in init self.start_session(capabilities, browser_profile) File "/export/home/anaconda3/lib/python3.6/site-packages/selenium/webdriver/remote/webdriver.py", line 251, in start_session response = self.execute(Command.NEW_SESSION, parameters) File "/export/home/anaconda3/lib/python3.6/site-packages/selenium/webdriver/remote/webdriver.py", line 320, in execute self.error_handler.check_response(response) File "/export/home/anaconda3/lib/python3.6/site-packages/selenium/webdriver/remote/errorhandler.py", line 242, in check_response raise exception_class(message, screen, stacktrace) selenium.common.exceptions.WebDriverException: Message: unknown error: Chrome failed to start: exited abnormally (unknown error: DevToolsActivePort file doesn't exist) (The process started from chrome location /usr/bin/google-chrome is no longer running, so ChromeDriver is assuming that Chrome has crashed.) (Driver info: chromedriver=2.41.578700 (2f1ed5f9343c13f73144538f15c00b370eda6706),platform=Linux 3.10.0-693.5.2.el7.x86_64 x86_64)
于是切换到命令行下,尝试测试一下google chrome的命令是否可用:
google-chrome 命令输出内容如下:
[29574:29574:0803/145908.944672:ERROR:zygote_host_impl_linux.cc(89)] Running as root without --no-sandbox is not supported. See https://crbug.com/638180.
从错误信息上可以看到,需要在启动Firefox的过程中,加入–no-sanbox的启动参数。
在启动过程中,还出现了一个新的错误信息:
Fri, 03 Aug 2018 15:04:51 xx-xx.py[line:183] INFO category, style, create dir:/export/xx/spider/xx/ Traceback (most recent call last): File "taobao-sexy.py", line 428, in total_images = spide_one_action(page_url, folder_path) File "taobao-sexy.py", line 264, in spide_one_action brw= create_brw() File "taobao-sexy.py", line 309, in create_brw brw = webdriver.Chrome(chrome_options=chrome_options) File "/export/home/anaconda3/lib/python3.6/site-packages/selenium/webdriver/chrome/webdriver.py", line 75, in init desired_capabilities=desired_capabilities) File "/export/home/anaconda3/lib/python3.6/site-packages/selenium/webdriver/remote/webdriver.py", line 156, in init self.start_session(capabilities, browser_profile) File "/export/home/anaconda3/lib/python3.6/site-packages/selenium/webdriver/remote/webdriver.py", line 251, in start_session response = self.execute(Command.NEW_SESSION, parameters) File "/export/home/anaconda3/lib/python3.6/site-packages/selenium/webdriver/remote/webdriver.py", line 320, in execute self.error_handler.check_response(response) File "/export/home/anaconda3/lib/python3.6/site-packages/selenium/webdriver/remote/errorhandler.py", line 242, in check_response raise exception_class(message, screen, stacktrace) selenium.common.exceptions.WebDriverException: Message: unknown error: Chrome failed to start: exited abnormally (unknown error: DevToolsActivePort file doesn't exist) (The process started from chrome location /usr/bin/google-chrome is no longer running, so ChromeDriver is assuming that Chrome has crashed.) (Driver info: chromedriver=2.41.578700 (2f1ed5f9343c13f73144538f15c00b370eda6706),platform=Linux 3.10.0-693.5.2.el7.x86_64 x86_64)
经过调查研究之后,发现其需要在启动过程中设置chrome的参数如下:
–disable-dev-shm-usage
7.完成的Chrome启动参数如下:
chrome_options = webdriver.ChromeOptions() chrome_options.add_argument('--headless') chrome_options.add_argument('--no-sandbox') chrome_options.add_argument('--disable-gpu') chrome_options.add_argument('--disable-dev-shm-usage')
下载Anaconda 方式一:官方网站
方式二:清华大学开源软件镜像站
可以下载到本地,然后通过xftp上传到Contos上
然后bash Anaconda3-4.4.0-Linux-x86_64.sh
该按enter按,该yes|no的yes。
然后source ~/.bashrc。然后重启终端,然后输入python
若期间遇到以下问题

请先删除 anaconda3,然后下载解压,命令为:yum -y install bzip2。然后再重新bash Anaconda3-4.4.0-Linux-x86_64.sh
若是想切换到python 2.0 版本,使用如下命令: conda create -n py27tf python=2.7 -y -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
查看anaconda维护的环境的命令:conda info -e
然后将其py27tf设置为默认版本,其命令:source activate py27tf。切换3.0则 source activate root 退出3.0用exit
然后将source activate py27tf 放入./bashrc中
然后bash激活,重启系统即可
cd /etc/sysconfig/network-scripts
vi ifcfg-ens33 onboot改成yes
ip addr 查看ip
NVM git地址: https://github.com/creationix/nvm
\1. 下载命令
curl -o- https://raw.githubusercontent.com/creationix/nvm/v0.33.8/install.sh | bash 或者 wget -qO- https://raw.githubusercontent.com/creationix/nvm/v0.33.8/install.sh | bash ---------------------
2、下载完成后加入系统环境
source ~/.bashrc
\3. 查看 NVM 版本list
nvm list-romote
4、安装需要的node版本
nvm install v8.12.0
\5. 查看当前机器已安装版本号
nvm list
\6. 切换node版本
nvm use v8.12.0
7、设置默认的node版本
nvm alias default v9.5.0
pip install lightgbm -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
在Linux添加PYTHONPATH方法以及修改环境变量方法
Linux下设置环境变量有三种方法,一种用于当前终端,一种用于当前用户,一种用于所有用户:
一:用于当前终端:
在当前终端中输入:
export PATH=$PATH:<你的要加入的路径>
不过上面的方法只适用于当前终端,一旦当前终端关闭或在另一个终端中,则无效。
`export NDK_ROOT``=``/``home``/``jiang``/``soft``/``Android``-``ndk``-``r8e ``#只能在当前终端使用。`
二:用于当前用户:
在用户主目录下有一个 .bashrc 隐藏文件,可以在此文件中加入 PATH 的设置如下:
`gedit ~``/``.bashrc`
加入:
`export PATH``=``<你的要加入的路径>:$PATH`
如果要加入多个路径,只要:
`export PATH``=``<你要加入的路径``1``>:<你要加入的路径``2``>: ...... :$PATH`
当中每个路径要以冒号分隔。
这样每次登录都会生效
添加PYTHONPATH的方法也是这样,在.bashrc中添加
`export PYTHONPATH``=``/``home``/``zhao``/``setup``/``caffe``-``master``/``python:``/``home``/``zhao``/``setup``/``mypy:$PYTHONPATH`
保存后在终端输入 $ source ~/.bashrc 使环境变量立即生效
三:用于所有用户:
`sudo gedit ``/``etc``/``profile`
加入:
`export PATH``=``<你要加入的路径>:$PATH`
就可以了。
终端输入:echo $PATH 可以查看环境变量
protoc --go_out=plugins=grpc:. helloworld.protogit clone https://github.com/grpc/grpc-go.git $GOPATH/src/google.golang.org/grpc
git clone https://github.com/golang/net.git $GOPATH/src/golang.org/x/net
git clone https://github.com/golang/text.git $GOPATH/src/golang.org/x/text
go get -u github.com/golang/protobuf/{proto,protoc-gen-go}
git clone https://github.com/google/go-genproto.git $GOPATH/src/google.golang.org/genproto
cd $GOPATH/src/
go install google.golang.org/grpc
1、安装Protobuf
在 https://github.com/google/protobuf/releases
下载
protoc-3.5.1-win32.zip
把解压后的 protoc.exe 放入到 GOPATH\BIN 中
2、安装grpc
Git clone https://github.com/grpc/grpc-go
将grpc-go更名为grpc放入到google.golang.org中,完整路径如下
D:\gopath\src\google.golang.org\grpc
3、安装Genproto
Git clone https://github.com/google/go-genproto
将clone下来的文件夹更名为genproto,放到google.golang.org下,完整路径如下
D:\gopath\src\google.golang.org\genproto
4、下载text包
git clone https://github.com/golang/text.git
5、下载net包
git clone https://github.com/golang/net.git
6、安装proto
go get -u github.com/golang/protobuf/proto
7、安装protoc-gen-go
go get -ugithub.com/golang/protobuf/protoc-gen-go
8、验证
进入下列目录
src\google.golang.org\grpc\examples\helloworld>
执行命令生成代码helloworld.pb.go
protoc -I ./helloworld--go_out=plugins=grpc:./helloworld ./helloworld\helloworld.proto
进入greeter_server下执行
go run main.go
进入greeter_client下执行
go run main.go
2018/06/19 11:29:25 Greeting: Hello world
Process finished with exit code 0
ZYNGA INC. 50 User License EA7E-811825 927BA117 84C9300F 4A0CCBC4 34A56B44 985E4562 59F2B63B CCCFF92F 0E646B83 0FD6487D 1507AE29 9CC4F9F5 0A6F32E3 0343D868 C18E2CD5 27641A71 25475648 309705B3 E468DDC4 1B766A18 7952D28C E627DDBA 960A2153 69A2D98A C87C0607 45DC6049 8C04EC29 D18DFA40 442C680B
1342224D 44D90641 33A3B9F2 46AADB8F
对于Ubuntu发行版本可以通过PPA安装,命令如下:
snap install --classic notepadqq
sudo add-apt-repository ppa:notepadqq-team/notepadqq sudo apt-get update sudo apt-get install notepadqq
pycharm 是一款非常好用的软件,如果资金允许的话,还是建议大家购买版权哦。最近编程,需要用到专业版本的pycharm,我就在网上看了好多相关文章,发现网上文章质量稂莠不齐,甚至很多都是骗经验,根本不能用,浪费了大家很多宝贵的时间,实在是让人气愤。欢迎留言和纠正哦。
先选择自己需要的pycharm版本安装好,不要着急打开,先做一下破解准备工作才能破解成功。
网上流传的破解方法是3种:
1,授权服务器激活,亲测这个方法Linux (Ubantu)和window都不能用啦,还是直接放弃吧。
选择License server激活,然后填入: idea.qmanga.com或http://xidea.online,然后点Activate激活即可。
2,激活码激活,亲测Linux (Ubantu)可以用修改成功,这个方法的难点在于修改hosts文件没有权限。
优点:效果稳定有效,关键是这种激活方式不会产生其他影响。
修改后请再次打开检查hosts文件是否修改,激活码无法激活的原因99.99%是因为hosts没有修改成功。 Mac和Ubantu(Linux)系统hosts文件路径为:/etc
安装过程:
下载好Linux版本安装包。
找到安装包的文件夹:下载。右键,提取到此处(就是解压到下载这个文件夹)
先不要着急安装,这里可以先破解一下
右键打开终端
在终端下输入:sudo gedit /etc/hosts
输入自己的虚拟机账户密码
然后就能打开hosts文件了,这时候hosts文件是可以修改和保存的,将这行代码 0.0.0.0 account.jetbrains.com 随便加 入到hosts文件中点击保存就可以啦,这样就解决了hosts文件没有权限无法修改的问题啦。
回到刚才的下载目录,打开刚才解压好pycharm的文件夹,然后再打开bin目录,右键在终端打开,输入以下命令:
sh ./pycharm.sh 回车。
这个时候pycharm 就会启动,选择第二个注册码激活,输入下面一段注册码后点击激活,就成功破解安装了哦:
激活码:
K71U8DBPNE-eyJsaWNlbnNlSWQiOiJLNzFVOERCUE5FIiwibGljZW5zZWVOYW1lIjoibGFuIHl1IiwiYXNzaWduZWVOYW1lIjoiIiwiYXNzaWduZWVFbWFpbCI6IiIsImxpY2Vuc2VSZXN0cmljdGlvbiI6IkZvciBlZHVjYXRpb25hbCB1c2Ugb25seSIsImNoZWNrQ29uY3VycmVudFVzZSI6ZmFsc2UsInByb2R1Y3RzIjpbeyJjb2RlIjoiSUkiLCJwYWlkVXBUbyI6IjIwMTktMDUtMDQifSx7ImNvZGUiOiJSUzAiLCJwYWlkVXBUbyI6IjIwMTktMDUtMDQifSx7ImNvZGUiOiJXUyIsInBhaWRVcFRvIjoiMjAxOS0wNS0wNCJ9LHsiY29kZSI6IlJEIiwicGFpZFVwVG8iOiIyMDE5LTA1LTA0In0seyJjb2RlIjoiUkMiLCJwYWlkVXBUbyI6IjIwMTktMDUtMDQifSx7ImNvZGUiOiJEQyIsInBhaWRVcFRvIjoiMjAxOS0wNS0wNCJ9LHsiY29kZSI6IkRCIiwicGFpZFVwVG8iOiIyMDE5LTA1LTA0In0seyJjb2RlIjoiUk0iLCJwYWlkVXBUbyI6IjIwMTktMDUtMDQifSx7ImNvZGUiOiJETSIsInBhaWRVcFRvIjoiMjAxOS0wNS0wNCJ9LHsiY29kZSI6IkFDIiwicGFpZFVwVG8iOiIyMDE5LTA1LTA0In0seyJjb2RlIjoiRFBOIiwicGFpZFVwVG8iOiIyMDE5LTA1LTA0In0seyJjb2RlIjoiR08iLCJwYWlkVXBUbyI6IjIwMTktMDUtMDQifSx7ImNvZGUiOiJQUyIsInBhaWRVcFRvIjoiMjAxOS0wNS0wNCJ9LHsiY29kZSI6IkNMIiwicGFpZFVwVG8iOiIyMDE5LTA1LTA0In0seyJjb2RlIjoiUEMiLCJwYWlkVXBUbyI6IjIwMTktMDUtMDQifSx7ImNvZGUiOiJSU1UiLCJwYWlkVXBUbyI6IjIwMTktMDUtMDQifV0sImhhc2giOiI4OTA4Mjg5LzAiLCJncmFjZVBlcmlvZERheXMiOjAsImF1dG9Qcm9sb25nYXRlZCI6ZmFsc2UsImlzQXV0b1Byb2xvbmdhdGVkIjpmYWxzZX0=-Owt3/+LdCpedvF0eQ8635yYt0+ZLtCfIHOKzSrx5hBtbKGYRPFDrdgQAK6lJjexl2emLBcUq729K1+ukY9Js0nx1NH09l9Rw4c7k9wUksLl6RWx7Hcdcma1AHolfSp79NynSMZzQQLFohNyjD+dXfXM5GYd2OTHya0zYjTNMmAJuuRsapJMP9F1z7UTpMpLMxS/JaCWdyX6qIs+funJdPF7bjzYAQBvtbz+6SANBgN36gG1B2xHhccTn6WE8vagwwSNuM70egpahcTktoHxI7uS1JGN9gKAr6nbp+8DbFz3a2wd+XoF3nSJb/d2f/6zJR8yJF8AOyb30kwg3zf5cWw==-MIIEPjCCAiagAwIBAgIBBTANBgkqhkiG9w0BAQsFADAYMRYwFAYDVQQDDA1KZXRQcm9maWxlIENBMB4XDTE1MTEwMjA4MjE0OFoXDTE4MTEwMTA4MjE0OFowETEPMA0GA1UEAwwGcHJvZDN5MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAxcQkq+zdxlR2mmRYBPzGbUNdMN6OaXiXzxIWtMEkrJMO/5oUfQJbLLuMSMK0QHFmaI37WShyxZcfRCidwXjot4zmNBKnlyHodDij/78TmVqFl8nOeD5+07B8VEaIu7c3E1N+e1doC6wht4I4+IEmtsPAdoaj5WCQVQbrI8KeT8M9VcBIWX7fD0fhexfg3ZRt0xqwMcXGNp3DdJHiO0rCdU+Itv7EmtnSVq9jBG1usMSFvMowR25mju2JcPFp1+I4ZI+FqgR8gyG8oiNDyNEoAbsR3lOpI7grUYSvkB/xVy/VoklPCK2h0f0GJxFjnye8NT1PAywoyl7RmiAVRE/EKwIDAQABo4GZMIGWMAkGA1UdEwQCMAAwHQYDVR0OBBYEFGEpG9oZGcfLMGNBkY7SgHiMGgTcMEgGA1UdIwRBMD+AFKOetkhnQhI2Qb1t4Lm0oFKLl/GzoRykGjAYMRYwFAYDVQQDDA1KZXRQcm9maWxlIENBggkA0myxg7KDeeEwEwYDVR0lBAwwCgYIKwYBBQUHAwEwCwYDVR0PBAQDAgWgMA0GCSqGSIb3DQEBCwUAA4ICAQC9WZuYgQedSuOc5TOUSrRigMw4/+wuC5EtZBfvdl4HT/8vzMW/oUlIP4YCvA0XKyBaCJ2iX+ZCDKoPfiYXiaSiH+HxAPV6J79vvouxKrWg2XV6ShFtPLP+0gPdGq3x9R3+kJbmAm8w+FOdlWqAfJrLvpzMGNeDU14YGXiZ9bVzmIQbwrBA+c/F4tlK/DV07dsNExihqFoibnqDiVNTGombaU2dDup2gwKdL81ua8EIcGNExHe82kjF4zwfadHk3bQVvbfdAwxcDy4xBjs3L4raPLU3yenSzr/OEur1+jfOxnQSmEcMXKXgrAQ9U55gwjcOFKrgOxEdek/Sk1VfOjvS+nuM4eyEruFMfaZHzoQiuw4IqgGc45ohFH0UUyjYcuFxxDSU9lMCv8qdHKm+wnPRb0l9l5vXsCBDuhAGYD6ss+Ga+aDY6f/qXZuUCEUOH3QUNbbCUlviSz6+GiRnt1kA9N2Qachl+2yBfaqUqr8h7Z2gsx5LcIf5kYNsqJ0GavXTVyWh7PYiKX4bs354ZQLUwwa/cG++2+wNWP+HtBhVxMRNTdVhSm38AknZlD+PTAsWGu9GyLmhti2EnVwGybSD2Dxmhxk3IPCkhKAK+pl0eWYGZWG3tJ9mZ7SowcXLWDFAk0lRJnKGFMTggrWjV8GYpw5bq23VmIqqDLgkNzuoog==
安装破解成功。
3 ,破解补丁激活,亲测window下修改成功。Linux就不要浪费时间尝试了,应该不可能成功的,反正我尝试多次没有成功。
下面说一下这个方法在window 下破解pycharm。时间可以到2100年,基本就是永久啦
先下载一下破解补丁包: https://pan.baidu.com/s/119UO4SGIEW_cxf0LmZzx3w
安装好pycharm,先不要打开,找到自己的pycharm安装目录下的bin文件夹, 把下载的JetbrainsCrack-3.1-release-enc.jar 压缩包放置到 pycharm安装目录的\bin目录下,注意不要解压。我把这个包放在bin的同级目录下了,效果一样的。
然后打开bin这个文件夹,找到下面两个文件 pycharm.exe.vmoptions 和 pycharm64.exe.vmoptions
打开这两个文件,在里面追加 -javaagent:D:\PyCharm 2018.2\bin\JetbrainsCrack-3.1-release-enc.jar ,然后保存即可。红色的部分是你自己的pycharm安装目录,记得修改哦。
然后你就可以打开pycharm了,选择激活码激活安装。复制上面那一段的激活码,点击激活,然后就破解成功了。
对于经常使用Linux系统的人员来说,少不了将本地的文件上传到服务器或者从服务器上下载文件到本地,rz / sz命令很方便的帮我们实现了这个功能,但是很多Linux系统初始并没有这两个命令。今天,我们就简单的讲解一下如何安装和使用rz、sz命令。
root 账号登陆后,依次执行以下命令:
1 |
cd /tmp |
|---|---|
2 |
wget http:``//www.ohse.de/uwe/releases/lrzsz-0.12.20.tar.gz |
|---|---|
3 |
tar zxvf lrzsz-0.12.20.tar.gz && cd lrzsz-0.12.20 |
|---|---|
4 |
./configure && make && make install |
|---|---|
上面安装过程默认把lsz和lrz安装到了/usr/local/bin/目录下,现在我们并不能直接使用,下面创建软链接,并命名为rz/sz:
1 |
cd /usr/bin |
|---|---|
2 |
ln -s /usr/local/bin/lrz rz |
|---|---|
3 |
ln -s /usr/local/bin/lsz sz |
|---|---|
root 账号登陆后执行以下命令:
1 |
yum ``install -y lrzsz apt-get install lrzsz |
|---|---|
sz命令发送文件到本地:
1 |
# sz filename |
|---|---|
rz命令本地上传文件到服务器:
1 |
# rz |
|---|---|
执行该命令后,在弹出框中选择要上传的文件即可。 说明:打开SecureCRT软件 -> Options -> session options -> X/Y/Zmodem 下可以设置上传和下载的目录。
python -m pip install --upgrade --force pip
Ubuntu pip升级后无法使用pip:
将当前使用的pip或pip3文件按其所写如下修改,位置是 /usr/bin/pip 或 /usr/bin/pip3,此操作需要管理员权限。
前:
from pip import main if name == 'main': sys.exit(main()) 后:
from pip import main if name == 'main':
sys.exit(main._main())
# 1
import traceback
print(traceback.format_exc())
import sys
logger.exception(sys.exc_info())笔者在使用linux时(虚拟机),经常会发现使用一段时间后,linux时间和我的宿主机(真实机)的时间不一致,而宿主机的时间确实是internet时间,安装linux时选择的时区也是Asia/Shanghai,那么今天我分享的即为如何让linux时间与internet时间同步
在解决问题之前,我们首先来了解下面几个知识点:
\1. date命令:
#date
显示系统时间
2.hwclock命令 (即hardwareclock系统硬件时间)
#hwclock
显示硬件时间
#hwclock -w
将系统时间写入到系统硬件当中
3.ntpdate
ntpdate 是一个linux时间同步服务软件,具体的详细资料请参考下百度,有很多详细的资料
第二、查看本机是否安装ntpdate服务,如果没有安装,请 yum install -y ntpdate
第三、同步时间
\1. 输入ntpdate time.nist.gov同步网络时间
结果:3 Jun 15:42:39 ntpdate[4721]: adjust time server 211.115.194.21 offset -0.005885 sec
出现上述结果代表时间同步成功,上面的大致意思为调整时间为服务器211.115.194.21的时间,相差-0.005885秒的时间
如果上面time.nist.gov服务器同步不了,可以换下面几个时间服务器试试: time.nist.gov time.nuri.net 0.asia.pool.ntp.org 1.asia.pool.ntp.org 2.asia.pool.ntp.org 3.asia.pool.ntp.org
2.同步时间成功后调整硬件时间
#hwclock -w
执行成功后, 查看系统硬件时间(不出意外的话,现在date和hwclock现实的时间均为internet时间)
#date
#hwclock
执行上述命令,显示的时间应该一样的
四、定时执行时间同步任务,所以我们利用crontab -e 来添加定时任务
#* */1 * * * root ntpdatetime.nuri.net;hwclock -w
即:每隔一个小时同步一下internet时间。
目标是想让代码中的日志按照不同的级别保存到不同的文件,即不管是框架本身的debug日志还是我们自己写的debug日志都保存到debug.log,info日志都保存在info.log,以此类推。
如果是为不同级别设置不同的logger,每个logger对应不同的文件handler,然后封装自己的日志函数调用对应的logger来记录日志确实是可以记录到不同的文件,但是这样只能记录自己代码中打的log而不会记录flask框架打印的log,因为框架使用的logger名称和我们使用的logger不一样,要达到我们的目标不能在logger上做处理,应该对和框架同一个logger上的handler做处理。
这里主要说的方式是使用logging的setLoggerClass方法为logging设置自己的logger对handler的处理逻辑。
默认的在python的logging库中会使用默认的Logger,在默认的Logger中有一个 callHandlers 的方法,里面会遍历该logger上添加的所有handler,只要调用的日志record的级别大于或等于设置的handler的级别就会执行handler中的handle函数。那么如果重写logger这里的逻辑,只当record的级别等于handler设置的级别时才会触发实际的handle函数这样就可以通过设置handler的级别就能让这个handler只记录对应级别的日志。
因此可以继承默认的Logger后重写callHandlers逻辑实现新的自定义Logger,通过setLoggerClass方法为logging模块设置新的Logger,然后为所有想要的级别加上文件handler,handler对应不同的日志文件,这样logger在记录对应级别的日志的时候就自动记录到对应的文件了。
由于我们需要同时保存自己的log和flask框架的log,所以必须将logger的名字设置为flask的logger名称:werkzeug,才能同时保存两者的日志到同一文件中即大家都使用werkzeug这个logger。
log.py:
::: python
import os
import logging
import logging.handlers
import sys
from logging import raiseExceptions
from logging import Logger
LOG_PATH = '/tmp/'
class AppLogger(Logger):
'''自定义logger
如果handler名称为console表示在终端打印所有大于等于设置级别的日志
其他handler则只记录等于设置级别的日志'''
def __init__(self, name, level=logging.NOTSET):
super(AppLogger, self).__init__(name, level)
def callHandlers(self, record):
"""
Pass a record to all relevant handlers.
Loop through all handlers for this logger and its parents in the
logger hierarchy. If no handler was found, output a one-off error
message to sys.stderr. Stop searching up the hierarchy whenever a
logger with the "propagate" attribute set to zero is found - that
will be the last logger whose handlers are called.
"""
c = self
found = 0
while c:
for hdlr in c.handlers:
found = found + 1
if hdlr.name == 'console':
if record.levelno >= hdlr.level:
hdlr.handle(record)
else:
if record.levelno == hdlr.level:
hdlr.handle(record)
if not c.propagate:
c = None # break out
else:
c = c.parent
if (found == 0) and raiseExceptions and not self.manager.emittedNoHandlerWarning: # noqa
sys.stderr.write("No handlers could be found for logger"
" \"%s\"\n" % self.name)
self.manager.emittedNoHandlerWarning = 1
def get_logger(logfile_name=__name__, log_path=LOG_PATH):
'''save log to diffrent file by deffirent log level into the log path
and print all log in console'''
logging.setLoggerClass(AppLogger)
formatter = logging.Formatter(
'%(asctime)s %(name)s %(levelname)s %(message)s', '%Y-%m-%d %H:%M:%S')
log_files = {
logging.DEBUG: os.path.join(log_path, logfile_name + '-debug.log'),
logging.INFO: os.path.join(log_path, logfile_name + '-info.log'),
logging.WARNING: os.path.join(log_path, logfile_name + '-warning.log'),
logging.ERROR: os.path.join(log_path, logfile_name + '-error.log'),
logging.CRITICAL:
os.path.join(log_path, logfile_name + '-critical.log')
}
# 和flask默认使用同一个logger
logger = logging.getLogger('werkzeug')
logger.setLevel(logging.DEBUG)
for log_level, log_file in log_files.items():
file_handler = logging.handlers.TimedRotatingFileHandler(log_file,
'midnight')
file_handler.setLevel(log_level)
file_handler.setFormatter(formatter)
logger.addHandler(file_handler)
console_handler = logging.StreamHandler()
console_handler.name = "console"
console_handler.setLevel(logging.DEBUG)
console_handler.setFormatter(formatter)
logger.addHandler(console_handler)
return logger
logger = get_logger()
通过以上代码为logging设置自定义Logger并添加对应的handler后即可在终端打印所有日志,在文件中则是将日志内容按日志级别分开保存。
server.py
::: python
from log import logger
from flask import Flask
app = Flask(__name__)
app.debug = True
@app.route("/")
def hello():
return "Hello World!"
logger.debug('----')
logger.info('----')
logger.error('----')
logger.warning('----')
app.run()
运行以上的flask示例,可以在终端看到全部日志:
::: text
2017-11-12 14:54:36 werkzeug DEBUG ----
2017-11-12 14:54:36 werkzeug INFO ----
2017-11-12 14:54:36 werkzeug ERROR ----
2017-11-12 14:54:36 werkzeug WARNING ----
2017-11-12 14:54:36 werkzeug INFO * Restarting with stat
2017-11-12 14:54:36 werkzeug DEBUG ----
2017-11-12 14:54:36 werkzeug INFO ----
2017-11-12 14:54:36 werkzeug ERROR ----
2017-11-12 14:54:36 werkzeug WARNING ----
2017-11-12 14:54:36 werkzeug WARNING * Debugger is active!
2017-11-12 14:54:36 werkzeug INFO * Debugger PIN: 971-444-041
2017-11-12 14:54:36 werkzeug INFO * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
同时在tmp目录下生产了对应级别的日志文件,终端中出现的所有log都按级别全部保存在对应的文件中了。
import flask, os, logging
from flask import Flask
app = Flask(__name__)
# log配置,实现日志自动按日期生成日志文件
def make_dir(make_dir_path):
"""
检查目录是否存在,如不存在则创建
:param make_dir_path: 目录路径
:return: path 目录路径
"""
path = make_dir_path.strip()
if not os.path.exists(path):
os.makedirs(path)
return path
# 目录名字
log_dir_name = "logs"
# 日志文件命名规则,按日期命名
log_file_name = 'logger-' + time.strftime('%Y-%m-%d', time.localtime(time.time())) + '.log'
# 检索文件路径,拼接绝对路径
# log_file_folder = os.path.abspath(os.path.join(os.path.dirname(__file__), os.pardir, os.pardir)) + os.sep + log_dir_name
log_file_folder = os.path.abspath(os.path.join(os.path.dirname(__file__))) + os.sep + log_dir_name
# 检查并创建目录
make_dir(log_file_folder)
log_file_str = log_file_folder + os.sep + log_file_name
# 设置日志级别
log_level = logging.WARNING
# 添加文件处理
handler = logging.FileHandler(log_file_str, encoding='utf-8')
# 设定文件处理级别
handler.setLevel(log_level)
# 设定日志格式
logging_format = logging.Formatter(
'%(asctime)s - %(levelname)s - %(filename)s - %(funcName)s - %(lineno)s - %(message)s')
# 添加日志格式
handler.setFormatter(logging_format)
# 为app的日志对象添加处理器
app.logger.addHandler(handler)打开网络连接
cd /etc/sysconfig/network-scripts/
vi ifcfg-eno16
修改ONBOOT为yes,并保存退出
service network restart
查看 ip addr
查找安装包
yum search ifconfig或其他
yum安装源:
/etc/yum.repo.d/ 内四个文件
安装pip:
sudo yum install epel-release
sudo yum install python-pip
主机名ip映射
/etc/hostname 本地主机名设置
/etc/hosts 主机名与ip映射
SSH密钥生成
ssh-keygen 在/root/下生成.ssh文件夹,包含私钥公钥
sudo apt install python-pip
- 命令行切换到root用户 备注:ubuntu默认root用户没有设置密码,切换需要首先设置密码 sudo passwd root 按照提示输入当前用户密码 按照提示输入要设置的root用户密码 按照提示再次输入root用户密码 修改成功 切换到root用户 su – root 按照提示输入root用户密码
- 安装openssh-server apt-get install openserver-ssh 修改配置文件 命令行[终端]进入目录:/etc/ssh 修改文件 sshd_config 注释掉 PermitRootlogin .. 添加一行 PermitRootLogin yes 保存文件退出
- 重启ssh服务 命令行(终端)执行命令:service ssh restart 查看ip地址:ifconfig
- 打开SecureCRT软件,根据提示输入IP地址和账号,点击连接,在弹出的对话框中输入root账号和密码,尽情享用吧!
1.先打开SecureCRT,标题标--工具---创建公钥,如图:
2.点击创建公钥,弹出选项点下一步
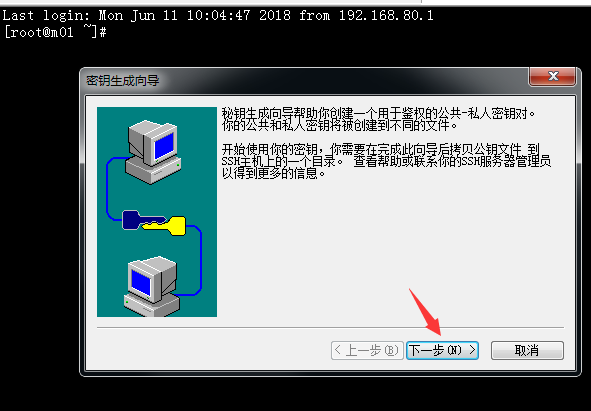
3.继续点下一步:
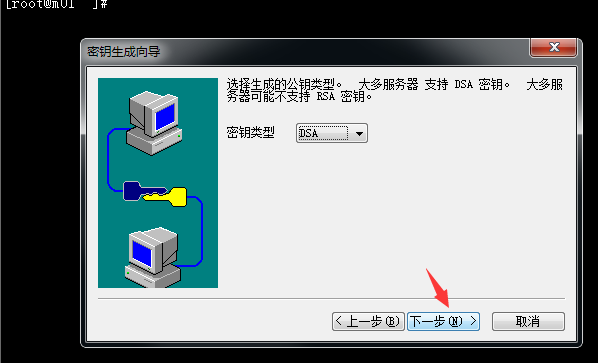
4.继续点下一步:
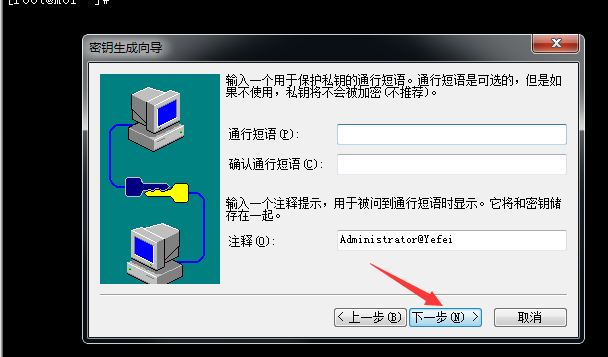
5.继续点下一步(密钥长度默认1024即可),生成密钥需一点点时间,请等待:
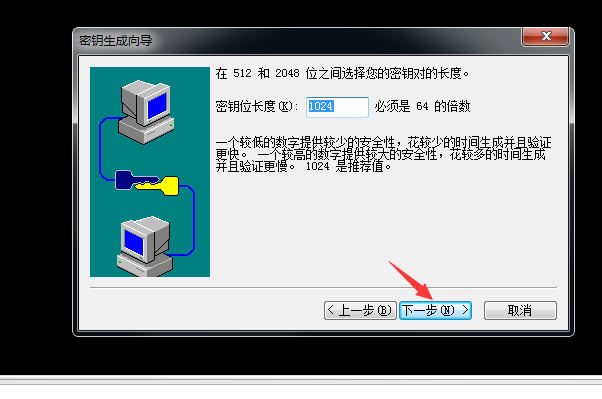
6.密钥生成完成后继续点下一步:
7.继续点下一步,选择密钥保存的位置:
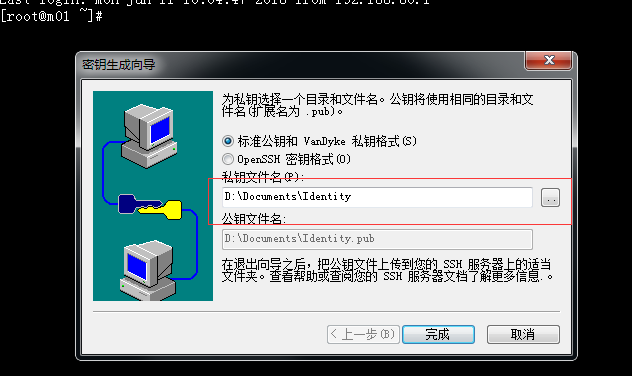
备注:Identity是私钥
Identity.pub是公钥
8.点完成,密钥创建成功
9.将公钥使用共享工具或者Linux命令rz上传到/root/.ssh下,然后将Identity.pub改名
cd /root/.ssh
chmod 700 .ssh
mv Identity.pub authorized_keys
chmod 644 authorized_keys
10.修改/etc/ssh/sshd_config配置文件:
RSAAuthentication yes
PubkeyAuthentication yes
另外,请留意 root 用户能否通过 SSH 登录,默认为yes:
PermitRootLogin yes
当我们完成全部设置并以密钥方式登录成功后,可以禁用密码登录。这里我们先不禁用,先允许密码登陆
PasswordAuthentication yes
UerDNS no #注释取消掉,这样解决连接使用ssh连接服务器慢的问题
AuthorizedKeysFile .ssh/authorized_keys 密钥存放的路径建议注释取消掉
修改完成后需要重启sshd服务(此处我被吭过,没有重启服务,死活都连接不上)
service sshd restart(重启sshd服务的方法有很多,不一一例举)
11.windows下SecureCRT配置,添加连接:
14.取消密码勾选,选择公钥,属性(选择之前创建密钥存放的路径,点确定即可,然后就可以使用密钥连接Linux了)
假设有机器A(192.168.100.0)和机器B(192.168.100.1)。若期望在A机器上免密登陆到B机器,则需要A机器有公钥和私钥,B机器上有A机器的公钥。
以Ubuntu为例,操作步骤如下:
1)在A机器上生成公钥/私钥对
A:~$ ssh-keygen -t rsa
根据提示,回车即可,提示输入密码时回车即表示空密码。在用户根目录下生成.ssh文件夹,里面包括id_rsa(私钥)和id_rsa.pub(公钥)。
2)将A机器的id_rsa.pub复制到B机器下
A:$ scp .ssh/id_rsa.pub B@192.168.100.1:/
这一步还需要输入B机器的密码。
3)在B机器上将A机器的id_rsa.pub添加到B机器的.ssh/authorized_keys,并将authorized_keys的权限改成600
B:~$ cat id_rsa.pub >> .ssh/authorized_keys
B:~$ chmod 600 .ssh/authorized_keys
现在A机器可免密登陆到B机器上了。
若A机器提示“Agent admitted failure to sign using the key.”,则需要将私钥id_rsa添加到ssh-agent的高速缓存中。
A:~$ ssh-add .ssh/id_rsa
操作环境:VMwareWorkstation10.0 + Ubuntu 16.10
出现的问题 用secureCRT连接Ubuntu提示远程系统拒绝访问和提示登录账户和密码错误。
解决办法 (1)开启ubuntu上的ssh功能,先安装,安装后就自动开启了。 命令apt install openssh-server (2)查看ubuntu 的ip, 用命令ifconfig。 (3)连接:secureCRT => Quick Connect,正确输入ubuntu的ip地址。

输入用户名和密码,点击ok。但是会出现登录账户和密码错误:
在端口号,IP地址,防火墙都确认没有问题的情况下修改ssh的配置文件。
方法: cd /etc/ssh/ vim sshd_config 找到PermitRootLogin prohibit-pasdword 改为PermitRootLogin yes ,然后重启ssh服务 (service ssh restart)。

再用secureCRT就能成功登录。
另外,可以通过options =>Session options 中设置背景颜色和字体大小等
如何配置nohub命令
用途:
LINUX命令用法,不挂断地运行命令。 语法:nohup Command [ Arg ... ] [ & ]
描述:nohup 命令运行由 Command 参数和任何相关的 Arg 参数指定的命令,忽略所有挂断(SIGHUP)信号。在注销后,使用nohup 命令运行后台中的程序。
要运行后台中的nohup 命令,添加& ( 表示“and”的符号)到命令的尾部。
例子:nohup ./startWeblogic.sh &
即使退出ssh界面,命令仍然在后台执行,并且打印过程日志到nohup.out。
当然也可以将nohup.out的输出转向到其他文件,高级应用请参考扩展阅读。
安装:
yum install coreutils
找路径:
which nohup
/usr/bin/nohup
将路径加入文件
vim ~/.bash_profile
添加:
PATH=$PATH:/usr/bin/nohup
终端执行:
source ~/.bash_profile
例子:
nohup gunicorn mysite.wsgi:application --bind 0.0.0.0:5678&
在想要输入命令的开头和结尾
一、/etc 配置文件 /etc/passwd 用户数据库,其中的域给出了用户名、真实姓名、家目录、加密口令和用户的其他信息
/etc/group 类似/etc/passwd ,但说明的不是用户而是组。
/etc/inittab init 的配置文件
/etc/issue 在登录提示符前的输出信息。通常包括系统的一段短说明或欢迎信息。内容由系统管理员确定。
/etc/motd 成功登录后自动输出,内容由系统管理员确定,经常用于通告信息,如计划关时间的警告。
/etc/mtab 当前安装的文件系统列表。由scripts 初始化,并由mount 命令自动更新。需要一个当前
安装的文件系统的列表时使用,例如df 命令,当df –a 时,查看到的信息应和其一致。
/etc/shadow 在安装了影子口令软件的系统上的影子口令文件。影子口令文件将/etc/passwd 文件中的
加密口令移动到/etc/shadow 中,而后者只对root 可读。这使破译口令更困难。
/etc/login.defs login 命令的配置文件
/etc/profile , /etc/csh.login , /etc/csh.cshrc 登录或启动时Bourne 或C
shells时执行的文件。这允许系统管理员为所有用户建立全局缺省环境 /etc/printcap 类似/etc/termcap ,但针对打印机。语法不同。
/etc/securetty 确认安全终端,即哪个终端允许root 登录。一般只列出虚拟控制台,这样就不可能
(至少很困难)通过modem 或网络闯入系统并得到超级用户特权。
/etc/shells 列出可信任的shell。chsh 命令允许用户在本文件指定范围内改变登录shell。提供一
台机器FTP 服务的服务进程ftpd 检查用户shell 是否列在 /etc/shells
文件中,如果不是将不允许该用户登录。
/etc/termcap终端性能数据库。说明不同的终端用什么"转义序列"控制。写程序时不直接输出转义序列(这样
只能工作于特定品牌的终端),而是从/etc/termcap中查找要做的工作的正确序列。这样,多数的
程序可以在多数终端上运行。
/etc/inputrc 输入设备配置文件
/etc/default/useradd 添加用户的默认信息的文件
/etc/login.defs 是用户密码信息的默认属性
/etc/skel 用户信息的骨架
/sbin/nologin 不能登陆的用户
/var/log/message 系统的日志文件
/etc/profile全局配置文件可以在添加一行PATH=$PATH:/usr/local/mysql/bin即可以软件的命令可以使用
/root/bashrc 命令的别名
/etc/yum.repos.d 配置本地YUM源
/etc/httpd/conf/httpd.conf 配置http服务的配置文件
/etc/fstab 系统启动时自动加载的设备,(用于配置自动挂载设备)
/etc/selinux 安全Linux设定
/etc/sysconfig/network 可以更改hostname(主机名)以及网卡工作状态
/etc/hosts 更改主机名和IP 地址的对应关系,请注意其格式为hostname.domain hostname localhost
localhost.domian,当修改主机名后必须修改该文件
/etc/resolv.conf 可配置DNS 地址,即第一DNS,第二DNS 以及DNS 的默认搜索路径
/etc/sysconfig/networking/profiles/default 内含数个文件,可配置hosts、网卡、DNS 地址及
DNS 搜索路径等
/etc/sysconfig/network-scripts/ifcfg-eth0 配置网卡eth0
/etc/rc.d/init.d/network restart 重启网络
/etc/rc.d/init.d 用于放置几乎所有服务的启动脚本
/etc/sysctl.conf 内核参数配置文件
/etc/sysconfig/i18n 设置系统语言和字符类型
/etc/crontab 系统定义的任务计划
/etc/anacrontab 实现检查过期和未完成的crontab的任务的配置文件
/etc/rc.d/init.d/functions 定义功能的配置文件
/etc/rc.d/rc.sysinit 系统启动设置配置文件
/etc/sysconfig/system-config-firewall配置防火墙的信任端口,以及防火墙的工作状态。图形化配置防火
墙的存档文件,具体讲只保存图形界面的otherport里面设置的项目,如果主配置
文件存在相应的配置条目,那么它里面的配置条目存在与否并不重要。
/etc/sysconfig/iptables 防火墙主配置文件
/etc/sysconfig/system-config-securitylevel 系统安全等级文件,在防火墙配置中不会涉及
/etc/xinetd.conf xinetd 的主配置文件
/etc/hosts.allow TCP的一个许可表
/etc/host.deny TCP的一个拒绝表
/etc/squid/squid.conf 代理服务器(SQUID)配置文件
/etc/sysconfig/vncservers VNC服务配置文件
/etc/vsftpd/ftpusers 用于保存不允许进行FTP 登录的本地用户账号(黑名单)
/etc/vsftpd/user_list 更灵活的用户访问控制,但需要在主配置文件中进行声明
/etc/inetd.conf swat 配置
/etc/dhcpd.conf DHCP 的配置文件
/etc/rc.d/init.d/dhcpd stop 停止DHCP
/etc/access 可以对sendmail 的邮件流进行控制
/etc/udev/rules.d 系统初始化时将硬件探测信息输出成设备配置文件,是一个程序。
让用户定义udev的规则,从而实现在创建设备文件使用不同的设备文件名
注:/etc/passwd 存放用户的账号
slaceware:x:5000:5000:Test User:/home/slackware:/bin/bash
Name:passwd位置:UID:GID:CECOS(注释):diectory(家目录):shell
注:/etc/shadow 存放用户的密码
slaceware:$1$12345678$0ME5N6oDyoEAwUp7b5UDM/:15355:0:99999:7:::
Name:加密后的密码:时间1:时间2:时间3:时间4:时间5:时间6:预留段
加密后的密码:以$分开,第一个$后是1,说明加密算法是md5,第二个$后是加的sail,第三个$后是加
的密码
时间1:从1970年1月1日起到最近的修改的天数
时间2:密码的最短使用期限
时间3:密码最长使用期限
时间4:在密码过期之前多少天开始警告
时间5:在密码过期多少天用户禁用
时间6:自1970年1月1日起多长时间用户被禁用
注:/etc/group 存放组的账号
slackware:x:5000:
Name:passwd位置:GID:附加组的用户列表
注: 交互式登陆的用户:
/etc/profile -->/etc/profile.d/* -->/.bash_profile -->/.bashrc -->/etc/bashrc
非交互式登录:
~/.bashrc -->/etc/bashrc -->.etc/profile.d/*
二、/proc 配置文件
/proc/dma 显示当前使用的DMA 通道。
/proc/filesystems 核心配置的文件系统。
/proc/interrupts 显示使用的中断,and how many of each there have been.
/proc/ioports 当前使用的I/O 端口。
/proc/kcore 系统物理内存映象。与物理内存大小完全一样,但不实际占用这么多内存;
it is generated on the fly as programs access it.
(记住:除非你把它拷贝到什么地方,/proc 下没有任何东西占用任何磁盘空间。)
/proc/kmsg 核心输出的消息。也被送到syslog
/proc/ksyms 核心符号表
/proc/loadavg 系统"平均负载";3 个指示器指出系统当前的工作量。
/proc/meminfo 存储器使用信息,包括物理内存和swap。
/proc/modules 当前加载了哪些核心模块。
/proc/net 网络协议状态信息。
/proc/self 到查看/proc 的程序的进程目录的符号连接。当2 个进程查看/proc
时,是不同的连接。这主要便于程序得到它自己的进程目录。
/proc/stat 系统的不同状态,such as the number of page faults since the system was booted.
/proc/uptime 系统启动的时间长度。
/proc/cpuinfo 处理器信息,如类型、制造商、型号和性能。
/proc/devices 当前运行的核心配置的设备驱动的列表。
/proc/version 核心版本。
/proc/mdstat RAID设备的信息
/proc/cmdline ro root=/dev/vol0/root rhgb quiet grub信息
/proc/cpuinfo 显示CPU的相关信息
/proc/cpuset cpu集合 用于显示当前进程可以应用到哪些cpu上
/proc/filesystem当前系统支持的文件系统种类
/etc/245/vm 系统进程ID号为245的进程的虚拟内存信息
/etc/245/kernel 系统进程ID号为245的进程的内核信息
/proc/mounts 挂载的所有文件系统
/proc/swaps 交换分区信息
/proc/uptime 启动系统运行时长
/proc/sys (具有写权限)定义内核参数的值来定义内核的功能
/proc/sys/kernel/hostname 主机名的设定
三、/usr 配置文件
/usr/bin 众多的应用程序
/usr/doc linux 文档
/usr/include linux 下C 开发和编译应用程序所需要的头文件
/usr/include/g++ C++编译器的头文
/usr/lib 常用的动态链接库和软件包的配置文件
/usr/src 系统软件的源代码
/usr/src/linux linux 内核的源代码
/usr/local/bin 本地增加的命令
/usr/local/lib 本地增加的库
/usr/sbin 为系统管理员保留的程序
/usr/share/fonts 字体文件
/usr/share/doc 各种文档文件
/usr/share/man 系统手册页
/usr/local/apache/man 定义man目录文集
四、其它目录配置文件
/dev/null 没有用的文件所放的位置,相当于回收站,吞噬设备
/dev/zero 初始化磁盘(吐零)
/dev/random 随机数生成器,熵池
/dev/urandom 伪随机数生成器,熵池。(当熵池耗尽时,用软件生成随机数)
/var/spool/mail/root 定义mail设置发送用户为root
/bin/bash 系统内置脚本
/home/USERNAME 用户配额文件
/var/spool/cron/USERNAME 用户定义的任务计划
五、目录结构: /boot 用于自举加载程序(LILO 或GRUB)的文件。当计算机启动时(如果有多个操作系统,
有可能允许你选择启动哪一个操作系统),这些文件首先被装载。这个目录也会包含LINUX 核(压缩文件
vmlinuz),但LINUX 核也可以存在别处,只要配置LILO 并且LILO 知道LINUX 核在哪儿。
/bin 系统启动时需要的引导程序(二进制执行文件),这些文件可以被普通用户使用
/dev 代表硬件组件的设备文件目录。LINUX 下设备被当成文件,这样一来硬件被抽象化,便
于读写、网络共享以及需要临时装载到文件系统中。正常情况下,设备会有一个独立的子目录。这些设备
的内容会出现在独立的子目录下。LINUX 没有所谓的驱动符。
/etc 存放各种配置文件
/etc/rc.d 启动的配置文件和脚本
/home 用户主目录,包含参数设置文件、个性化文件、文档、数据、EMAIL、缓存数据等
/lib 标准程序设计库,又叫动态链接共享库,作用类似windows 里的.dll 文件
/sbin 为系统管理员保留的用于系统启动时的引导程序(二进制执行文件),这些文件不打算被
普通用户使用(普通用户仍然可以使用它们,但要指定目录)
/tmp 公用的临时文件存储点,该目录会被自动清理干净
/root 系统管理员的主目录
/mnt 系统提供这个目录是让用户临时挂载其他的文件系统。
/lost+found这个目录平时是空的,系统非正常关机而留下“无家可归”的文件(windows下叫什么.chk)就在这里
/proc 虚拟的目录,是系统内存的映射,可直接访问这个目录来获取系统信息。目录整个包含
虚幻的文件。它们实际上并不存在磁盘上,也不占用任何空间。(用ls –l 可以显示它们的大小)当查看
这些文件时,实际上是在访问存在内存中的信息,这些信息用于访问系统
/proc/1 关于进程1 的信息目录。每个进程在/proc 下有一个名为其进程号的目录。
/var 某些大文件的溢出区,比方说各种服务的日志文件,包含在正常操作中被改变的文件:
假脱机文件、记录文件、加锁文件、临时文件和页格式化文件等
/var/spool mail, news, 打印队列和其他队列工作的目录。每个不同的spool 在/var/spool 下有自己的
子目录,例如,用户的邮箱在/var/spool/mail 中。
/opt 可选的应用程序,譬如,REDHAT 5.2 下的KDE (REDHAT 6.0 下,KDE 放在其它的
XWINDOWS 应用程序中,主执行程序在/usr/bin 目录下)
/usr 最庞大的目录,要用到的应用程序和文件几乎都在这个目录。
/home /var /usr/local 经常是单独分区,因为经常会操作,容易产生碎片
/srv 该目录存放一些服务启动之后需要提取的数据
一、目的需求
根据业务需要,目前负责维护的产品形式基本是属于分布式的,有多个web服务部署在不同项目现场,针对这些web服务的维护就成了比较麻烦的事情。为了保障系统服务,之前已经采用LNMP+zabbix的方案搭建了一套web服务监控系统,可以方便的查看各项目的web服务状态,方便及时发现问题并解决。
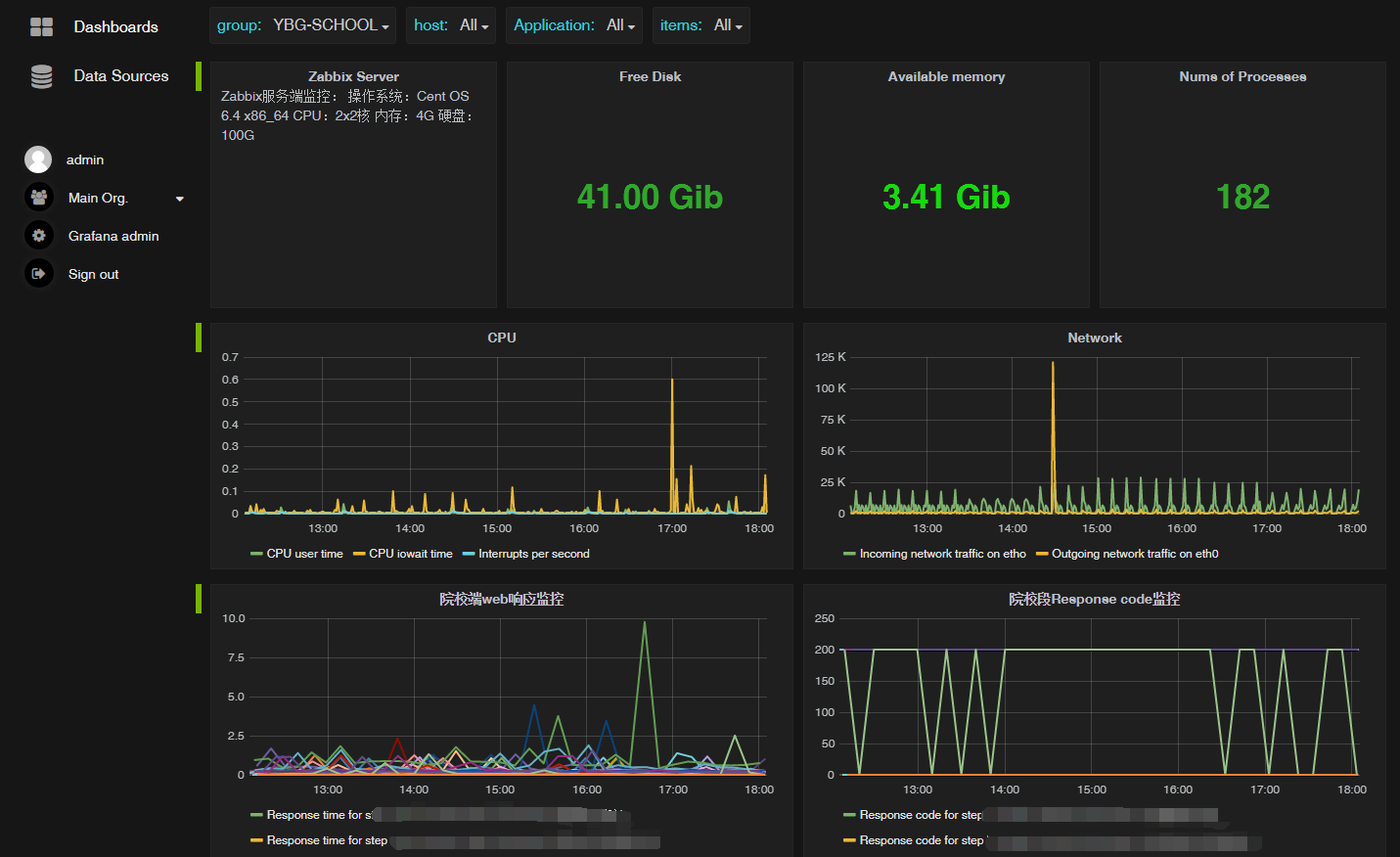
采用Grafana的前端监控界面(比zabbix自带的图表好看点 - -):
不过虽然有zabbix贴心的监控和提醒(实际上由于网络不稳定或等等玄学因素,冗余警告非常多,多了就烦了。。。),但是解决具体问题还是需要远程到项目现场进行,特别是一些进程运行时间久了之后的异常,或者数据库连接断开等,简单重启一下web服务即可解决。但是,多了频繁了之后就很浪费时间了,于是打算通过shell来监控各项目地的web服务并实现异常自动重启,作为程序猿,当然要用代码来偷懒啦~(懒惰是三大生产力之一)
二、分析过程
思路如下:
1.定时执行monitor监控脚本,获取服务状态;
2.monitor功能:
if:web服务异常
restart web服务
else:皆大欢喜
逻辑很简单清楚,貌似很容易,不过这里有一个问题,如何判定web服务异常?
根据实际经验,异常常见原因共如下几种:
1.web服务进程莫名挂掉;
2.web服务数据库连接失败,多次尝试后挂起;
3.项目地网络出现波动;(不用吐槽,教育网还有偏远地区是这样的,指不定哪天光纤被挖断或者交换机故障(╯▽╰))
对应解决方案:
1.判断进程是否存在,不存在则重启web服务;
2.这个直接通过shell不好判断,借鉴了之前在zabbix做http监控时的方法,通过模拟登录的方式,登录一个测试页面,获取http_code,若200则正常,非200则属于异常。
3.这个可以通过判断本地服务,如果本地访问无问题则正常。
三、代码实现
monitor逻辑分析清楚了,可以开始进行了,其中模拟登录使用curl来获取http_code。
#! /bin/sh
host_dir="/opt/ybg/" # 当前用户根目录
proc_name="java" # 进程名
file_name="monitor.log" # 日志文件
pid=0
proc_num() # 计算进程数
{
num=`ps -ef | grep $proc_name | grep -v grep | wc -l`
return $num
}
proc_id() # 进程号
{
pid=`ps -ef | grep $proc_name | grep -v grep | awk '{print $2}'`
}
# 通过curl模拟登录获取http_code,模拟登录参数仅供参考
# 如果只需要判断某页面的状态可使用curl -I -s -w "%{http_code}" -o /dev/null http://www.baidu.com/ 直接获取即可
http_code=`curl -I -s -w "%{http_code}" -o -d "userKey=admin&pass=c9127e832b41a" /dev/null http://portal.ly-sky.com/login.do?login= | head -n 1 | cut -d$' ' -f2`
proc_num
number=$?
if [[ $number -eq 0 ]]||[[ $http_code -ne 200 ]] # 判断进程是否存在
then
cd /opt/ybg/URP/bin/
nohup ./run.sh>../logs/urp.log 2>&1 & # 重启进程的命令,请相应修改
sleep 3 #延迟3秒是为了确保进程已正常启动并方便获取pid,否则有可能获取不到pid
proc_id # 获取新进程号
echo $pid, `date` >> $host_dir$file_name # 将新进程号和重启时间记录
fi
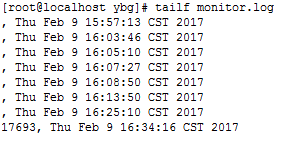
执行成功的日志记录:
记录了PID和启动时间,前面几条就是因为未加入sleep获取Pid失败,显示为空了
部署到服务器后只需要在crontab添加任务,定时执行就行了:
[root@localhost ybg]# crontab -e
#添加web服务监控,每5分钟一次,可根据实际要求修改监控频率 */5 * * * * /opt/ybg/monitor.sh
添加完毕后,可以手动kill -9 pid来测试监控是否正常运行。提示:测试时注意生产环境哦,如果服务宕了被老板请去喝茶就不好啦~✧(≖ ◡ ≖✿)
curl命令是一个利用URL规则在命令行下工作的文件传输工具。它支持文件的上传和下载,所以是综合传输工具,但按传统,习惯称curl为下载工具。作为一款强力工具,curl支持包括HTTP、HTTPS、ftp等众多协议,还支持POST、cookies、认证、从指定偏移处下载部分文件、用户代理字符串、限速、文件大小、进度条等特征。做网页处理流程和数据检索自动化,curl可以祝一臂之力。
curl(选项)(参数)
| -a/--append | 上传文件时,附加到目标文件 |
|---|---|
| -A/--user-agent | 设置用户代理发送给服务器 |
| -anyauth | 可以使用“任何”身份验证方法 |
| -b/--cookie <name=string/file> | cookie字符串或文件读取位置 |
| --basic | 使用HTTP基本验证 |
| -B/--use-ascii | 使用ASCII /文本传输 |
| -c/--cookie-jar | 操作结束后把cookie写入到这个文件中 |
| -C/--continue-at | 断点续转 |
| -d/--data | HTTP POST方式传送数据 |
| --data-ascii | 以ascii的方式post数据 |
| --data-binary | 以二进制的方式post数据 |
| --negotiate | 使用HTTP身份验证 |
| --digest | 使用数字身份验证 |
| --disable-eprt | 禁止使用EPRT或LPRT |
| --disable-epsv | 禁止使用EPSV |
| -D/--dump-header | 把header信息写入到该文件中 |
| --egd-file | 为随机数据(SSL)设置EGD socket路径 |
| --tcp-nodelay | 使用TCP_NODELAY选项 |
| -e/--referer | 来源网址 |
| -E/--cert <cert[:passwd]> | 客户端证书文件和密码 (SSL) |
| --cert-type | 证书文件类型 (DER/PEM/ENG) (SSL) |
| --key | 私钥文件名 (SSL) |
| --key-type | 私钥文件类型 (DER/PEM/ENG) (SSL) |
| --pass | 私钥密码 (SSL) |
| --engine | 加密引擎使用 (SSL). "--engine list" for list |
| --cacert | CA证书 (SSL) |
| --capath | CA目录 (made using c_rehash) to verify peer against (SSL) |
| --ciphers | SSL密码 |
| --compressed | 要求返回是压缩的形势 (using deflate or gzip) |
| --connect-timeout | 设置最大请求时间 |
| --create-dirs | 建立本地目录的目录层次结构 |
| --crlf | 上传是把LF转变成CRLF |
| -f/--fail | 连接失败时不显示http错误 |
| --ftp-create-dirs | 如果远程目录不存在,创建远程目录 |
| --ftp-method [multicwd/nocwd/singlecwd] | 控制CWD的使用 |
| --ftp-pasv | 使用 PASV/EPSV 代替端口 |
| --ftp-skip-pasv-ip | 使用PASV的时候,忽略该IP地址 |
| --ftp-ssl | 尝试用 SSL/TLS 来进行ftp数据传输 |
| --ftp-ssl-reqd | 要求用 SSL/TLS 来进行ftp数据传输 |
| -F/--form <name=content> | 模拟http表单提交数据 |
| --form-string <name=string> | 模拟http表单提交数据 |
| -g/--globoff | 禁用网址序列和范围使用{}和[] |
| -G/--get | 以get的方式来发送数据 |
| -H/--header | 自定义头信息传递给服务器 |
| --ignore-content-length | 忽略的HTTP头信息的长度 |
| -i/--include | 输出时包括protocol头信息 |
| -I/--head | 只显示请求头信息 |
| -j/--junk-session-cookies | 读取文件进忽略session cookie |
| --interface | 使用指定网络接口/地址 |
| --krb4 | 使用指定安全级别的krb4 |
| -k/--insecure | 允许不使用证书到SSL站点 |
| -K/--config | 指定的配置文件读取 |
| -l/--list-only | 列出ftp目录下的文件名称 |
| --limit-rate | 设置传输速度 |
| --local-port | 强制使用本地端口号 |
| -m/--max-time | 设置最大传输时间 |
| --max-redirs | 设置最大读取的目录数 |
| --max-filesize | 设置最大下载的文件总量 |
| -M/--manual | 显示全手动 |
| -n/--netrc | 从netrc文件中读取用户名和密码 |
| --netrc-optional | 使用 .netrc 或者 URL来覆盖-n |
| --ntlm | 使用 HTTP NTLM 身份验证 |
| -N/--no-buffer | 禁用缓冲输出 |
| -o/--output | 把输出写到该文件中 |
| -O/--remote-name | 把输出写到该文件中,保留远程文件的文件名 |
| -p/--proxytunnel | 使用HTTP代理 |
| --proxy-anyauth | 选择任一代理身份验证方法 |
| --proxy-basic | 在代理上使用基本身份验证 |
| --proxy-digest | 在代理上使用数字身份验证 |
| --proxy-ntlm | 在代理上使用ntlm身份验证 |
| -P/--ftp-port | 使用端口地址,而不是使用PASV |
| -q | 作为第一个参数,关闭 .curlrc |
| -Q/--quote | 文件传输前,发送命令到服务器 |
| -r/--range | 检索来自HTTP/1.1或FTP服务器字节范围 |
| --range-file | 读取(SSL)的随机文件 |
| -R/--remote-time | 在本地生成文件时,保留远程文件时间 |
| --retry | 传输出现问题时,重试的次数 |
| --retry-delay | 传输出现问题时,设置重试间隔时间 |
| --retry-max-time | 传输出现问题时,设置最大重试时间 |
| -s/--silent | 静默模式。不输出任何东西 |
| -S/--show-error | 显示错误 |
| --socks4 <host[:port]> | 用socks4代理给定主机和端口 |
| --socks5 <host[:port]> | 用socks5代理给定主机和端口 |
| --stderr | |
| -t/--telnet-option <OPT=val> | Telnet选项设置 |
| --trace | 对指定文件进行debug |
| --trace-ascii | Like --跟踪但没有hex输出 |
| --trace-time | 跟踪/详细输出时,添加时间戳 |
| -T/--upload-file | 上传文件 |
| --url | Spet URL to work with |
| -u/--user <user[:password]> | 设置服务器的用户和密码 |
| -U/--proxy-user <user[:password]> | 设置代理用户名和密码 |
| -w/--write-out [format] | 什么输出完成后 |
| -x/--proxy <host[:port]> | 在给定的端口上使用HTTP代理 |
| -X/--request <command> | 指定什么命令 |
| -y/--speed-time | 放弃限速所要的时间,默认为30 |
| -Y/--speed-limit | 停止传输速度的限制,速度时间 |
文件下载
curl命令可以用来执行下载、发送各种HTTP请求,指定HTTP头部等操作。如果系统没有curl可以使用yum install curl安装,也可以下载安装。curl是将下载文件输出到stdout,将进度信息输出到stderr,不显示进度信息使用--silent选项。
curl URL --silent
这条命令是将下载文件输出到终端,所有下载的数据都被写入到stdout。
使用选项-O将下载的数据写入到文件,必须使用文件的绝对地址:
curl http://man.linuxde.net/text.iso --silent -O
选项-o将下载数据写入到指定名称的文件中,并使用--progress显示进度条:
curl http://man.linuxde.net/test.iso -o filename.iso --progress
######################################### 100.0%
断点续传
curl能够从特定的文件偏移处继续下载,它可以通过指定一个便宜量来下载部分文件:
curl URL/File -C 偏移量
#偏移量是以字节为单位的整数,如果让curl自动推断出正确的续传位置使用-C -:
curl -C -URL
使用curl设置参照页字符串
参照页是位于HTTP头部中的一个字符串,用来表示用户是从哪个页面到达当前页面的,如果用户点击网页A中的某个连接,那么用户就会跳转到B网页,网页B头部的参照页字符串就包含网页A的URL。
使用--referer选项指定参照页字符串:
curl --referer http://www.google.com http://man.linuxde.net
用curl设置cookies
使用--cookie "COKKIES"选项来指定cookie,多个cookie使用分号分隔:
curl http://man.linuxde.net --cookie "user=root;pass=123456"
将cookie另存为一个文件,使用--cookie-jar选项:
curl URL --cookie-jar cookie_file
用curl设置用户代理字符串
有些网站访问会提示只能使用IE浏览器来访问,这是因为这些网站设置了检查用户代理,可以使用curl把用户代理设置为IE,这样就可以访问了。使用--user-agent或者-A选项:
curl URL --user-agent "Mozilla/5.0"
curl URL -A "Mozilla/5.0"
其他HTTP头部信息也可以使用curl来发送,使用-H"头部信息" 传递多个头部信息,例如:
curl -H "Host:man.linuxde.net" -H "accept-language:zh-cn" URL
curl的带宽控制和下载配额
使用--limit-rate限制curl的下载速度:
curl URL --limit-rate 50k
命令中用k(千字节)和m(兆字节)指定下载速度限制。
使用--max-filesize指定可下载的最大文件大小:
curl URL --max-filesize bytes
如果文件大小超出限制,命令则返回一个非0退出码,如果命令正常则返回0。
用curl进行认证
使用curl选项 -u 可以完成HTTP或者FTP的认证,可以指定密码,也可以不指定密码在后续操作中输入密码:
curl -u user:pwd http://man.linuxde.net
curl -u user http://man.linuxde.net
只打印响应头部信息
通过-I或者-head可以只打印出HTTP头部信息:
[root@localhost text]# curl -I http://man.linuxde.net
HTTP/1.1 200 OK
Server: nginx/1.2.5
date: Mon, 10 Dec 2012 09:24:34 GMT
Content-Type: text/html; charset=UTF-8
Connection: keep-alive
Vary: Accept-Encoding
X-Pingback: http://man.linuxde.net/xmlrpc.php
linux 系统则是由 cron (crond) 这个系统服务来控制的。Linux 系统上面原本就有非常多的计划性工作,因此这个系统服务是默认启动的。另 外, 由于使用者自己也可以设置计划任务,所以, Linux 系统也提供了使用者控制计划任务的命令 :crontab 命令。
一、crond简介
crond 是linux下用来周期性的执行某种任务或等待处理某些事件的一个守护进程,与windows下的计划任务类似,当安装完成操作系统后,默认会安装此服务 工具,并且会自动启动crond进程,crond进程每分钟会定期检查是否有要执行的任务,如果有要执行的任务,则自动执行该任务。
Linux下的任务调度分为两类,系统任务调度和用户任务调度。
系统任务调度:系统周期性所要执行的工作,比如写缓存数据到硬盘、日志清理等。在/etc目录下有一个crontab文件,这个就是系统任务调度的配置文件。
/etc/crontab文件包括下面几行:
cat /etc/crontab
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=HOME=/
# run-parts
51 * * * * root run-parts /etc/cron.hourly
24 7 * * * root run-parts /etc/cron.daily
22 4 * * 0 root run-parts /etc/cron.weekly
42 4 1 * * root run-parts /etc/cron.monthly
前 四行是用来配置crond任务运行的环境变量,第一行SHELL变量指定了系统要使用哪个shell,这里是bash,第二行PATH变量指定了系统执行 命令的路径,第三行MAILTO变量指定了crond的任务执行信息将通过电子邮件发送给root用户,如果MAILTO变量的值为空,则表示不发送任务 执行信息给用户,第四行的HOME变量指定了在执行命令或者脚本时使用的主目录。第六至九行表示的含义将在下个小节详细讲述。这里不在多说。
用户任务调度:用户定期要执行的工作,比如用户数据备份、定时邮件提醒等。用户可以使用 crontab 工具来定制自己的计划任务。所有用户定义的crontab 文件都被保存在 /var/spool/cron目录中。其文件名与用户名一致。
使用者权限文件:
文件:
/etc/cron.deny
说明:
该文件中所列用户不允许使用crontab命令
文件:
/etc/cron.allow
说明:
该文件中所列用户允许使用crontab命令
文件:
/var/spool/cron/
说明:
所有用户crontab文件存放的目录,以用户名命名
crontab文件的含义:
用户所建立的crontab文件中,每一行都代表一项任务,每行的每个字段代表一项设置,它的格式共分为六个字段,前五段是时间设定段,第六段是要执行的命令段,格式如下:
minute hour day month week command
其中:
minute: 表示分钟,可以是从0到59之间的任何整数。
hour:表示小时,可以是从0到23之间的任何整数。
day:表示日期,可以是从1到31之间的任何整数。
month:表示月份,可以是从1到12之间的任何整数。
week:表示星期几,可以是从0到7之间的任何整数,这里的0或7代表星期日。
command:要执行的命令,可以是系统命令,也可以是自己编写的脚本文件。

在以上各个字段中,还可以使用以下特殊字符:
星号(*):代表所有可能的值,例如month字段如果是星号,则表示在满足其它字段的制约条件后每月都执行该命令操作。
逗号(,):可以用逗号隔开的值指定一个列表范围,例如,“1,2,5,7,8,9”
中杠(-):可以用整数之间的中杠表示一个整数范围,例如“2-6”表示“2,3,4,5,6”
正斜线(/):可以用正斜线指定时间的间隔频率,例如“0-23/2”表示每两小时执行一次。同时正斜线可以和星号一起使用,例如*/10,如果用在minute字段,表示每十分钟执行一次。
二、crond服务
安装crontab:
yum install crontabs
服务操作说明:
/sbin/service crond start //启动服务
/sbin/service crond stop //关闭服务
/sbin/service crond restart //重启服务
/sbin/service crond reload //重新载入配置
/sbin/service crond status //启动服务
查看crontab服务是否已设置为开机启动,执行命令:
ntsysv
加入开机自动启动:
chkconfig –level 35 crond on
三、crontab命令详解
1.命令格式:
crontab [-u user] file
crontab [-u user] [ -e | -l | -r ]
2.命令功能:
通过crontab 命令,我们可以在固定的间隔时间执行指定的系统指令或 shell script脚本。时间间隔的单位可以是分钟、小时、日、月、周及以上的任意组合。这个命令非常设合周期性的日志分析或数据备份等工作。
3.命令参数:
-u user:用来设定某个用户的crontab服务,例如,“-u ixdba”表示设定ixdba用户的crontab服务,此参数一般有root用户来运行。
file:file是命令文件的名字,表示将file做为crontab的任务列表文件并载入crontab。如果在命令行中没有指定这个文件,crontab命令将接受标准输入(键盘)上键入的命令,并将它们载入crontab。
-e:编辑某个用户的crontab文件内容。如果不指定用户,则表示编辑当前用户的crontab文件。
-l:显示某个用户的crontab文件内容,如果不指定用户,则表示显示当前用户的crontab文件内容。
-r:从/var/spool/cron目录中删除某个用户的crontab文件,如果不指定用户,则默认删除当前用户的crontab文件。
-i:在删除用户的crontab文件时给确认提示。
4.常用方法:
1). 创建一个新的crontab文件
在 考虑向cron进程提交一个crontab文件之前,首先要做的一件事情就是设置环境变量EDITOR。cron进程根据它来确定使用哪个编辑器编辑 crontab文件。9 9 %的UNIX和LINUX用户都使用vi,如果你也是这样,那么你就编辑$ HOME目录下的. profile文件,在其 中加入这样一行:
EDITOR=vi; export EDITOR
然后保存并退出。不妨创建一个名为 cron的文件,其中是用户名,例如, davecron。在该文件中加入如下的内容。
# (put your own initials here)echo the date to the console every
# 15minutes between 6pm and 6am
0,15,30,45 18-06 * * * /bin/echo ‘date’ > /dev/console
保存并退出。确信前面5个域用空格分隔。
在 上面的例子中,系统将每隔1 5分钟向控制台输出一次当前时间。如果系统崩溃或挂起,从最后所显示的时间就可以一眼看出系统是什么时间停止工作的。在有些 系统中,用tty1来表示控制台,可以根据实际情况对上面的例子进行相应的修改。为了提交你刚刚创建的crontab文件,可以把这个新创建的文件作为 cron命令的参数:
$ crontab davecron
现在该文件已经提交给cron进程,它将每隔1 5分钟运行一次。
同时,新创建文件的一个副本已经被放在/var/spool/cron目录中,文件名就是用户名(即dave)。
2). 列出crontab文件
为了列出crontab文件,可以用:
$ crontab -l
0,15,30,45,18-06 * * * /bin/echo date > dev/tty1
你将会看到和上面类似的内容。可以使用这种方法在$ H O M E目录中对crontab文件做一备份:
$ crontab -l > $HOME/mycron
这样,一旦不小心误删了crontab文件,可以用上一节所讲述的方法迅速恢复。
3). 编辑crontab文件
如果希望添加、删除或编辑crontab文件中的条目,而E D I TO R环境变量又设置为v i,那么就可以用v i来编辑crontab文件,相应的命令为:
$ crontab -e
可以像使用v i编辑其他任何文件那样修改crontab文件并退出。如果修改了某些条目或添加了新的条目,那么在保存该文件时, c r o n会对其进行必要的完整性检查。如果其中的某个域出现了超出允许范围的值,它会提示你。
我们在编辑crontab文件时,没准会加入新的条目。例如,加入下面的一条:
# DT:delete core files,at 3.30am on 1,7,14,21,26,26 days of each month
30 3 1,7,14,21,26 * * /bin/find -name “core’ -exec rm {} ;
现在保存并退出。最好在crontab文件的每一个条目之上加入一条注释,这样就可以知道它的功能、运行时间,更为重要的是,知道这是哪位用户的作业。
现在让我们使用前面讲过的crontab -l命令列出它的全部信息:
$ crontab -l
# (crondave installed on Tue May 4 13:07:43 1999)
# DT:ech the date to the console every 30 minites
0,15,30,45 18-06 * * * /bin/echo date > /dev/tty1
# DT:delete core files,at 3.30am on 1,7,14,21,26,26 days of each month
30 3 1,7,14,21,26 * * /bin/find -name “core’ -exec rm {} ;
4). 删除crontab文件
要删除crontab文件,可以用:
$ crontab -r
5). 恢复丢失的crontab文件
如果不小心误删了crontab文件,假设你在自己的$ H O M E目录下还有一个备份,那么可以将其拷贝到/var/spool/cron/,其中是用户名。如果由于权限问题无法完成拷贝,可以用:
$ crontab
其中,是你在$ H O M E目录中副本的文件名。
我建议你在自己的$ H O M E目录中保存一个该文件的副本。我就有过类似的经历,有数次误删了crontab文件(因为r键紧挨在e键的右边)。这就是为什么有些系统文档建议不要直接编辑crontab文件,而是编辑该文件的一个副本,然后重新提交新的文件。
有些crontab的变体有些怪异,所以在使用crontab命令时要格外小心。如果遗漏了任何选项,crontab可能会打开一个空文件,或者看起来像是个空文件。这时敲delete键退出,不要按,否则你将丢失crontab文件。
5.使用实例
实例1:每1分钟执行一次command 命令: * * * * * command
实例2:每小时的第3和第15分钟执行 命令: 3,15 * * * * command
实例3:在上午8点到11点的第3和第15分钟执行 命令: 3,15 8-11 * * * command
实例4:每隔两天的上午8点到11点的第3和第15分钟执行 命令: 3,15 8-11 */2 * * command
实例5:每个星期一的上午8点到11点的第3和第15分钟执行 命令: 3,15 8-11 * * 1 command
实例6:每晚的21:30重启smb 命令: 30 21 * * * /etc/init.d/smb restart
实例7:每月1、10、22日的4 : 45重启smb 命令: 45 4 1,10,22 * * /etc/init.d/smb restart
实例8:每周六、周日的1 : 10重启smb 命令: 10 1 * * 6,0 /etc/init.d/smb restart
实例9:每天18 : 00至23 : 00之间每隔30分钟重启smb 命令: 0,30 18-23 * * * /etc/init.d/smb restart
实例10:每星期六的晚上11 : 00 pm重启smb 命令: 0 23 * * 6 /etc/init.d/smb restart
实例11:每一小时重启smb 命令: * */1 * * * /etc/init.d/smb restart
实例12:晚上11点到早上7点之间,每隔一小时重启smb 命令: * 23-7/1 * * * /etc/init.d/smb restart
实例13:每月的4号与每周一到周三的11点重启smb 命令: 0 11 4 * mon-wed /etc/init.d/smb restart
实例14:一月一号的4点重启smb 命令: 0 4 1 jan * /etc/init.d/smb restart
实例15:每小时执行/etc/cron.hourly目录内的脚本 命令: 01 * * * * root run-parts /etc/cron.hourly 说明: run-parts这个参数了,如果去掉这个参数的话,后面就可以写要运行的某个脚本名,而不是目录名了
四、使用注意事项
注意环境变量问题 有时我们创建了一个crontab,但是这个任务却无法自动执行,而手动执行这个任务却没有问题,这种情况一般是由于在crontab文件中没有配置环境变量引起的。
在 crontab文件中定义多个调度任务时,需要特别注意的一个问题就是环境变量的设置,因为我们手动执行某个任务时,是在当前shell环境下进行的,程 序当然能找到环境变量,而系统自动执行任务调度时,是不会加载任何环境变量的,因此,就需要在crontab文件中指定任务运行所需的所有环境变量,这 样,系统执行任务调度时就没有问题了。
不要假定cron知道所需要的特殊环境,它其实并不知道。所以你要保证在shelll脚本中提供所有必要的路径和环境变量,除了一些自动设置的全局变量。所以注意如下3点:
1)脚本中涉及文件路径时写全局路径;
2)脚本执行要用到java或其他环境变量时,通过source命令引入环境变量,如:
cat start_cbp.sh
#!/bin/sh
source /etc/profile
export RUN_CONF=/home/d139/conf/platform/cbp/cbp_jboss.conf
/usr/local/jboss-4.0.5/bin/run.sh -c mev &
3)当手动执行脚本OK,但是crontab死活不执行时。这时必须大胆怀疑是环境变量惹的祸,并可以尝试在crontab中直接引入环境变量解决问题。如:
0 * * * * . /etc/profile;/bin/sh /var/www/java/audit_no_count/bin/restart_audit.sh
注意清理系统用户的邮件日志 每条任务调度执行完毕,系统都会将任务输出信息通过电子邮件的形式发送给当前系统用户,这样日积月累,日志信息会非常大,可能会影响系统的正常运行,因此,将每条任务进行重定向处理非常重要。
例如,可以在crontab文件中设置如下形式,忽略日志输出:
0 */3 * * * /usr/local/apache2/apachectl restart >/dev/null 2>&1
“/dev/null 2>&1”表示先将标准输出重定向到/dev/null,然后将标准错误重定向到标准输出,由于标准输出已经重定向到了/dev/null,因此标准错误也会重定向到/dev/null,这样日志输出问题就解决了。
系统级任务调度与用户级任务调度 系 统级任务调度主要完成系统的一些维护操作,用户级任务调度主要完成用户自定义的一些任务,可以将用户级任务调度放到系统级任务调度来完成(不建议这么 做),但是反过来却不行,root用户的任务调度操作可以通过“crontab –uroot –e”来设置,也可以将调度任务直接写入/etc /crontab文件,需要注意的是,如果要定义一个定时重启系统的任务,就必须将任务放到/etc/crontab文件,即使在root用户下创建一个 定时重启系统的任务也是无效的。
其他注意事项 新创建的cron job,不会马上执行,至少要过2分钟才执行。如果重启cron则马上执行。
当crontab突然失效时,可以尝试/etc/init.d/crond restart解决问题。或者查看日志看某个job有没有执行/报错tail -f /var/log/cron。
千万别乱运行crontab -r。它从Crontab目录(/var/spool/cron)中删除用户的Crontab文件。删除了该用户的所有crontab都没了。
在crontab中%是有特殊含义的,表示换行的意思。如果要用的话必须进行转义%,如经常用的date ‘+%Y%m%d’在crontab里是不会执行的,应该换成date ‘+%Y%m%d’。
# connect("用户名/密码@IP:PORT/SERVER_NAME")
# SERVER_NAME不是SID 可以通过
# select value from v$parameter where name like '%service_name%'; 查询得到
conn = Oracle.connect("sport/sport2012@192.168.7.244:1521/oracle244.xyo.com")
cur = conn.cursor() # 创建游标第一步:下载安装cx_Oracle
下载地址:http://sourceforge.net/projects/cx-oracle/files/5.1.2/,下载cx_Oracle的rmp安装文件,注意下载版本最好和Oracle、Python环境保持一致,我当前的环境是Oracle 11g和Python2.7,因此下载的是cx_Oracle-5.1.2-11g-py27-1.x86_64.rpm。
不需按RPM方式去安装,直接解压从中取出cx_Oracle.so文件(只需要这个),复制到Python环境的dist-packages目录,我的机器是/usr/local/lib/python2.7/dist-packages/。
解压命令:
rpm2cpio file.rpm | cpio -div
第二步:下载安装Oracle instant client
下载地址:http://www.oracle.com/technetwork/indexes/downloads/index.html,从Database栏目的Instant Client链接进入,按当前系统选择对应的下载,我选择的是Instant Client for Linux x86-64
解压下载文件oracle-instantclient11.2-basic-11.2.0.3.0-1.x86_64.rpm ,实际上只需要其中的so共享库文件,将所有so文件复制到一个单独路径即可,我将他们复制到/opt/oracle-instantclient11.2/lib。
应该有5个文件:
pwd
/opt/oracle-instantclient11.2/lib
ls
libclntsh.so.11.1 libnnz11.so libocci.so.11.1 libociei.so libocijdbc11.so
第三步:检查并安装libaio1
sudo apt-get update
sudo apt-cache search libaio
sudo apt-get install libaio1
或
yum install libaio 不能用pip
第四步:配置环境变量
cd ~
sudo vim .bashrc
把 export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/lib/oracle/18.3/client64/lib 这行放在里面,保存退出。
最后:测试一下
$ python
import cx_Oracle
conn = cx_Oracle.connect(’username/pwd@ip:port/servicename’)
cursor = conn.cursor()
Ubuntu Linux系统包含两类环境变量:系统环境变量和用户环境变量。系统环境变量对所有系统用户都有效,用户环境变量仅仅对当前的用户有效。
用户环境变量通常被存储在下面的文件中:
- ~/.profile
- ~/.bash_profile 或者 ~./bash_login
- ~/.bashrc
上述文件在Ubuntu 10.0以前版本不推荐使用。
系统环境变量一般保存在下面的文件中:
- /etc/environment
- /etc/profile
- /etc/bash.bashrc
/etc/profile和 /etc/bash.bashrc在Ubuntu 10.0版本中不推荐使用。
如想将一个路径加入到$PATH中,可以像下面这样做(修改/etc/profile):
sudo nano /etc/profile
在里面加入:
JAVA_HOME=/usr/jdk1.6.0_25
export JAVA_HOME
PATH=$PATH:$JAVA_HOME/bin
export PATH
CLASSPATH=.:$JAVA_HOME/lib
export CLASSPATH
你可以自己加上指定的多个路径,中间用冒号隔开。环境变量更改后,在用户下次登陆时生效,如果想立刻生效,则可执行下面的语句:
$source /etc/profile
需要注意的是,最好不要把当前路径”./”放到PATH里,这样可能会受到意想不到的攻击。
其他文件的修改方式与此类似,需要注意的是**/etc/environment不需要使用export**设置环境变量,其他profile文件需要。
更详细的说明可以参考这里。
当然如果想使用文本编辑工具修改环境变量,可以使用root权限登录后,直接用文本编辑器打开修改保存
也可以普通用户权限下把文件复制到桌面等修改后用root权限覆盖回去
# /etc/profile: system-wide .profile file for the Bourne shell (sh(1))
# and Bourne compatible shells (bash(1), ksh(1), ash(1), ...).
if [ -d /etc/profile.d ]; then
for i in /etc/profile.d/*.sh; do
if [ -r $i ]; then
. $i
fi
done
JAVA_HOME=/usr/hadoop/jdk1.6.0_25
export JAVA_HOME
PATH=$PATH:$JAVA_HOME/bin
export PATH
CLASSPATH=.:$JAVA_HOME/lib
export CLASSPATH
unset i
fi
if [ "$PS1" ]; then
if [ "$BASH" ]; then
# The file bash.bashrc already sets the default PS1.
# PS1='\h:\w\$ '
if [ -f /etc/bash.bashrc ]; then
. /etc/bash.bashrc
fi
else
if [ "`id -u`" -eq 0 ]; then
PS1='# '
else
PS1='$ '
fi
fi
fi
Ubuntu的软件包格式是deb,如果要安装rpm的包,则要先用alien把rpm转换成deb
-
1
先安装 alien 和 fakeroot 这两个工具,其中前者可以将 rpm 包转换为 deb 包。
安装命令为: sudo apt-get install alien fakeroot
-
2
将需要安装的 rpm 包下载备用,假设为 package.rpm
-
3
使用 alien 将 rpm 包转换为 deb 包: fakeroot alien package.rpm
-
4
一旦转换成功,我们可以即刻使用以下指令来安装: sudo dpkg -i package.deb
END
-
1
安装alien和rpm: sudo apt-get install rpm alien
-
2
转化为deb格式: alien -d package.rpm
-
3
安装:sudo dpkg -i package.deb
END
- 如果提示Unable to locate package则需先执行:sudo apt-get update命令
一、apt-get 安装
deb是debian linus的安装格式,跟red hat的rpm非常相似,最基本的安装命令是:dpkg -i file.deb或者直接双击此文件
dpkg 是Debian Package的简写,是为Debian 专门开发的套件管理系统,方便软件的安装、更新及移除。所有源自Debian的Linux发行版都使用dpkg,例如Ubuntu、Knoppix 等。 以下是一些 Dpkg 的普通用法:
1、dpkg -i 安装一个 Debian 软件包,如你手动下载的文件。
2、dpkg -c 列出 的内容。
3、dpkg -I 从 中提取包裹信息。
4、dpkg -r 移除一个已安装的包裹。
5、dpkg -P 完全清除一个已安装的包裹。和 remove 不同的是,remove 只是删掉数据和可执行文件,purge 另外还删除所有的配制文件。
6、dpkg -L 列出 安装的所有文件清单。同时请看 dpkg -c 来检查一个 .deb 文件的内容。
7、dpkg -s 显示已安装包裹的信息。同时请看 apt-cache 显示 Debian 存档中的包裹信息,以及 dpkg -I 来显示从一个 .deb 文件中提取的包裹信息。
8、dpkg-reconfigure 重新配制一个已经安装的包裹,如果它使用的是 debconf (debconf 为包裹安装提供了一个统一的配制界面)。
二、软件安装后相关文件位置
1.下载的软件存放位置
/var/cache/apt/archives
2.安装后软件默认位置
/usr/share
3.可执行文件位置
/usr/bin
4.配置文件位置
/etc
5.lib文件位置
/usr/lib
dpkg 安装选择路径
选择安装.deb软件到其他目录
sudo dpkg -i --instdir=/opt/apache apache2
然后可以建立一个软链接
ln -s /opt/gsopcast/usr/local/bin/gsopcast /usr/local/bin
from flask_cors import CORS
from flask import Flask
app = Flask(__name__)
CORS(app)# 查看
show variables like 'collation_%';sudo apt install libmysqlclient-dev
pip install mysqlclient -i 在开始正式讲解之前,我们将首先进行环境准备。
Step1:安装Python,pip以及nginx:
sudo apt-get updatesudo apt-get install python-pip python-dev nginx
Step2:安装Python库:uwsgi和flask
pip install uwsgi flask
下面,我们以一个简单的单文件Flask项目为例:
假设项目目录为/home/nianshi/flask_project。
编辑/home/nianshi/flask_project/main.py:
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello():
return "<h1 style="color:blue">Hello There!</h1>"
if __name__ == "__main__":
app.run(host='0.0.0.0')
编辑/home/nianshi/flask_project/run.py:
from main import app
if __name__ == "__main__":
app.run()
运行 python run.py ,然后本地访问 http://127.0.0.1:5000 将会看到:
当然直接使用python run.py运行服务的方式只适合本地开发。线上运行时要保证更高的性能和稳定性,我们需要使用uwsgi进行部署。
使用uwsgi部署Flask项目只需要换一种命令来启动服务即可:
uwsgi --socket 0.0.0.0:5000 --protocol=http -p 3 -w run:app --enable-threads(允许app内部线程)
我们来对uwsgi的参数进行分别讲解:
--socket 0.0.0.0:5000:指定暴露端口号为5000。--protocol=http:说明使用 http 协议,即端口5000可以直接使用HTTP请求进行访问。-p 3表示启动的服务占用3个进程。-w run:app:-w 指明了要启动的模块,run 就是项目启动文件 run.py 去掉扩展名,app 是 run.py 文件中的变量 app,即 Flask 实例。
启动完成后,我们可以在任意网络连通的机器上打开浏览器,并访问如下地址: http://server_domain_or_IP:5000
可以看到结果同样如下:

既然我们已经可以好似用uwsgi来部署Flask项目了,那么我们为什么还要使用Nginx + uwsgi来部署呢? 使用Nginx有如下一些优点:
- 安全:不管什么请求都要经过代理服务器,这样就避免了外部程序直接攻击web服务器
- 负载均衡:根据请求情况和服务器负载情况,将请求分配给不同的web服务器,保证服务器性能
- 提高web服务器的IO性能:对于一些静态文件,可以直接由反向代理处理,不经过web服务器
那么,应该如何将Nginx与uwsgi结合来部署Flask项目呢?
在开始讲解Nginx之前,我们首先讲解如何将复杂的uwsgi命令参数保存在配置文件中,从而每次启动uwsgi时,无需添加繁琐的参数,只需要指定配置文件即可。
编辑/home/nianshi/flask_project/uwsgi.ini:
[uwsgi]
module = run:app
master = true
processes = 3
chdir = /home/nianshi/flask_project
socket = /home/nianshi/flask_project/myproject.sock
socket = 127.0.0.1:8000
logto = /home/nianshi/flask_project/myproject.log
chmod-socket = 660
vacuum = true
其中,文件参数说明如下:
- module相当于之前命令行中的-w参数;
- processes相当于之前的-p参数;
- socket此处包含两个,一个是指定了暴露的端口,另外指定了一个myproject.sock文件保存socker信息。
- chdir是项目路径地址。
- logto是日志输出地址。
可以看到,此处我们没有添加--protocol=http对应的配置信息。
即此时我们暴露的端口不能使用HTTP请求直接访问,当时需要经过Nginx进行反向代理。
此时,我们可以执行如下命令来通过配置文件启动uwsgi:
uwsgi --ini /home/nianshi/flask_project/uwsgi.ini
此时,我们已经正常启动了uWsgi服务,但是无法直接访问,需要继续部署Nginx服务。
下面,我们来编辑Nginx的配置文件/home/nianshi/flask_project/nginx.conf:
worker_processes 4;
events { worker_connections 1024; }
http {
include mime.types;
default_type application/octet-stream;
server {
listen 80;
location / {
include uwsgi_params;
uwsgi_pass 127.0.0.1:8000;
}
}
}
其中,如下两行指定反向代理的信息:
include uwsgi_params;
uwsgi_pass 127.0.0.1:8000;
两个分别指明了代理的解析方式是通过uwsgi解析以及uWsgi暴露的端口地址为127.0.0.1:8000。
下面,我们启动Nginx服务:
nginx -c /home/nianshi/flask_project/nginx.conf
启动完成后,由于nginx本身监听的端口是80端口,因此我们可以直接访问机器地址进行访问:
错误:fatal: refusing to merge unrelated histories
$git pull origin master –allow-unrelated-historiesimport smtplib
from email.mime.text import MIMEText
from email.header import Header
import traceback # 跟踪错误信息
def auto_email():
sender = "laoji_168@163.com"
receiver = "jihw@ssports.com"
subject = "keywords.py 异常通知"
smtpserver = "smtp.163.com"
username = "laoji_168@163.com"
password = "jhwij1314"
msg = MIMEText(traceback.format_exc(), 'plain', 'utf-8') # 中文需参数‘utf-8',单字节字符不需要
msg['Subject'] = Header(subject, 'utf-8')
msg['From'] = "laoji<laoji_168@163.com>"
msg['To'] = receiver
smtp = smtplib.SMTP()
smtp.connect(smtpserver)
smtp.login(username, password)
smtp.sendmail(sender, receiver, msg.as_string())
smtp.quit()smtplib.SMTP():实例化SMTP()
connect(host,port):
host:指定连接的邮箱服务器。常用邮箱的smtp服务器地址如下:
新浪邮箱:smtp.sina.com,新浪VIP:smtp.vip.sina.com,搜狐邮箱:smtp.sohu.com,126邮箱:smtp.126.com,139邮箱:smtp.139.com,163网易邮箱:smtp.163.com。
port:指定连接服务器的端口号,默认为25.
login(user,password):
user:登录邮箱的用户名。
password:登录邮箱的密码,像笔者用的是网易邮箱,网易邮箱一般是网页版,需要用到客户端密码,需要在网页版的网易邮箱中设置授权码,该授权码即为客户端密码。
sendmail(from_addr,to_addrs,msg,...):
from_addr:邮件发送者地址
to_addrs:邮件接收者地址。字符串列表['接收地址1','接收地址2','接收地址3',...]或'接收地址'
msg:发送消息:邮件内容。一般是msg.as_string():as_string()是将msg(MIMEText对象或者MIMEMultipart对象)变为str。
quit():用于结束SMTP会话。
2.email模块
email模块下有mime包,mime英文全称为“Multipurpose Internet Mail Extensions”,即多用途互联网邮件扩展,是目前互联网电子邮件普遍遵循的邮件技术规范。
该mime包下常用的有三个模块:text,image,multpart。
导入方法如下:
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
from email.mime.image import MIMEImage
构造一个邮件对象就是一个Message对象,如果构造一个MIMEText对象,就表示一个文本邮件对象,如果构造一个MIMEImage对象,就表示一个作为附件的图片,要把多个对象组合起来,就用MIMEMultipart对象,而MIMEBase可以表示任何对象。它们的继承关系如下:
Message
+- MIMEBase
+- MIMEMultipart
+- MIMENonMultipart
+- MIMEMessage
+- MIMEText
+- MIMEImage
2.1 text说明
邮件发送程序为了防止有些邮件阅读软件不能显示处理HTML格式的数据,通常都会用两类型分别为"text/plain"和"text/html"
构造MIMEText对象时,第一个参数是邮件正文,第二个参数是MIME的subtype,最后一定要用utf-8编码保证多语言兼容性。
2.1.1添加普通文本
text = "Hi!\nHow are you?\nHere is the link you wanted:\nhttp://www.baidu.com"
text_plain = MIMEText(text,'plain', 'utf-8')
查看MIMEText属性:可以观察到MIMEText,MIMEImage和MIMEMultipart的属性都一样。
print dir(text_plain)
['contains', 'delitem', 'doc', 'getitem', 'init', 'len', 'module', 'setitem', 'str', '_charset', '_default_type', '_get_params_preserve', '_headers', '_payload', '_unixfrom', 'add_header', 'as_string', 'attach', 'defects', 'del_param', 'epilogue', 'get', 'get_all', 'get_boundary', 'get_charset', 'get_charsets', 'get_content_charset', 'get_content_maintype', 'get_content_subtype', 'get_content_type', 'get_default_type', 'get_filename', 'get_param', 'get_params', 'get_payload', 'get_unixfrom', 'has_key', 'is_multipart', 'items', 'keys', 'preamble', 'replace_header', 'set_boundary', 'set_charset', 'set_default_type', 'set_param', 'set_payload', 'set_type', 'set_unixfrom', 'values', 'walk']
2.1.2添加超文本
html = """
<html>
<body>
<p>
Here is the <a href="http://www.baidu.com">link</a> you wanted.
</p>
</body>
</html>
"""
text_html = MIMEText(html,'html', 'utf-8')
2.1.3添加附件
sendfile=open(r'D:\pythontest\1111.txt','rb').read()
text_att = MIMEText(sendfile, 'base64', 'utf-8')
text_att["Content-Type"] = 'application/octet-stream'
text_att["Content-Disposition"] = 'attachment; filename="显示的名字.txt"'
2.2 image说明
添加图片:
sendimagefile=open(r'D:\pythontest\testimage.png','rb').read()
image = MIMEImage(sendimagefile)
image.add_header('Content-ID','<image1>')
查看MIMEImage属性:
print dir(image)
['contains', 'delitem', 'doc', 'getitem', 'init', 'len', 'module', 'setitem', 'str', '_charset', '_default_type', '_get_params_preserve', '_headers', '_payload', '_unixfrom', 'add_header', 'as_string', 'attach', 'defects', 'del_param', 'epilogue', 'get', 'get_all', 'get_boundary', 'get_charset', 'get_charsets', 'get_content_charset', 'get_content_maintype', 'get_content_subtype', 'get_content_type', 'get_default_type', 'get_filename', 'get_param', 'get_params', 'get_payload', 'get_unixfrom', 'has_key', 'is_multipart', 'items', 'keys', 'preamble', 'replace_header', 'set_boundary', 'set_charset', 'set_default_type', 'set_param', 'set_payload', 'set_type', 'set_unixfrom', 'values', 'walk']
2.3 multpart说明
常见的multipart类型有三种:multipart/alternative, multipart/related和multipart/mixed。
邮件类型为"multipart/alternative"的邮件包括纯文本正文(text/plain)和超文本正文(text/html)。
邮件类型为"multipart/related"的邮件正文中包括图片,声音等内嵌资源。
邮件类型为"multipart/mixed"的邮件包含附件。向上兼容,如果一个邮件有纯文本正文,超文本正文,内嵌资源,附件,则选择mixed类型。
msg = MIMEMultipart('mixed')
我们必须把Subject,From,To,Date添加到MIMEText对象或者MIMEMultipart对象中,邮件中才会显示主题,发件人,收件人,时间(若无时间,就默认一般为当前时间,该值一般不设置)。
msg = MIMEMultipart('mixed')
msg['Subject'] = 'Python email test'
msg['From'] = 'XXX@163.com <XXX@163.com>'
msg['To'] = 'XXX@126.com'
msg['Date']='2012-3-16'
查看MIMEMultipart属性:
msg = MIMEMultipart('mixed')
print dir(msg)
结果:
['contains', 'delitem', 'doc', 'getitem', 'init', 'len', 'module', 'setitem', 'str', '_charset', '_default_type', '_get_params_preserve', '_headers', '_payload', '_unixfrom', 'add_header', 'as_string', 'attach', 'defects', 'del_param', 'epilogue', 'get', 'get_all', 'get_boundary', 'get_charset', 'get_charsets', 'get_content_charset', 'get_content_maintype', 'get_content_subtype', 'get_content_type', 'get_default_type', 'get_filename', 'get_param', 'get_params', 'get_payload', 'get_unixfrom', 'has_key', 'is_multipart', 'items', 'keys', 'preamble', 'replace_header', 'set_boundary', 'set_charset', 'set_default_type', 'set_param', 'set_payload', 'set_type', 'set_unixfrom', 'values', 'walk']
说明:
msg.add_header(_name,_value,**_params):添加邮件头字段。
msg.as_string():是将msg(MIMEText对象或者MIMEMultipart对象)变为str,如果只有一个html超文本正文或者plain普通文本正文的话,一般msg的类型可以是MIMEText;如果是多个的话,就都添加到MIMEMultipart,msg类型就变为MIMEMultipart。
msg.attach(MIMEText对象或MIMEImage对象):将MIMEText对象或MIMEImage对象添加到MIMEMultipart对象中。MIMEMultipart对象代表邮件本身,MIMEText对象或MIMEImage对象代表邮件正文。
以上的构造的文本,超文本,附件,图片都何以添加到MIMEMultipart('mixed')中:
msg.attach(text_plain)
msg.attach(text_html)
msg.attach(text_att)
msg.attach(image)
3.文字,html,图片,附件实现实例
#coding: utf-8
import smtplib
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
from email.mime.image import MIMEImage
from email.header import Header
#设置smtplib所需的参数
#下面的发件人,收件人是用于邮件传输的。
smtpserver = 'smtp.163.com'
username = 'XXX@163.com'
password='XXX'
sender='XXX@163.com'
#receiver='XXX@126.com'
#收件人为多个收件人
receiver=['XXX@126.com','XXX@126.com']
subject = 'Python email test'
#通过Header对象编码的文本,包含utf-8编码信息和Base64编码信息。以下中文名测试ok
#subject = '中文标题'
#subject=Header(subject, 'utf-8').encode()
#构造邮件对象MIMEMultipart对象
#下面的主题,发件人,收件人,日期是显示在邮件页面上的。
msg = MIMEMultipart('mixed')
msg['Subject'] = subject
msg['From'] = 'XXX@163.com <XXX@163.com>'
#msg['To'] = 'XXX@126.com'
#收件人为多个收件人,通过join将列表转换为以;为间隔的字符串
msg['To'] = ";".join(receiver)
#msg['Date']='2012-3-16'
#构造文字内容
text = "Hi!\nHow are you?\nHere is the link you wanted:\nhttp://www.baidu.com"
text_plain = MIMEText(text,'plain', 'utf-8')
msg.attach(text_plain)
#构造图片链接
sendimagefile=open(r'D:\pythontest\testimage.png','rb').read()
image = MIMEImage(sendimagefile)
image.add_header('Content-ID','<image1>')
image["Content-Disposition"] = 'attachment; filename="testimage.png"'
msg.attach(image)
#构造html
#发送正文中的图片:由于包含未被许可的信息,网易邮箱定义为垃圾邮件,报554 DT:SPM :<p><img src="cid:image1"></p>
html = """
<html>
<head></head>
<body>
<p>Hi!<br>
How are you?<br>
Here is the <a href="http://www.baidu.com">link</a> you wanted.<br>
</p>
</body>
</html>
"""
text_html = MIMEText(html,'html', 'utf-8')
text_html["Content-Disposition"] = 'attachment; filename="texthtml.html"'
msg.attach(text_html)
#构造附件
sendfile=open(r'D:\pythontest\1111.txt','rb').read()
text_att = MIMEText(sendfile, 'base64', 'utf-8')
text_att["Content-Type"] = 'application/octet-stream'
#以下附件可以重命名成aaa.txt
#text_att["Content-Disposition"] = 'attachment; filename="aaa.txt"'
#另一种实现方式
text_att.add_header('Content-Disposition', 'attachment', filename='aaa.txt')
#以下中文测试不ok
#text_att["Content-Disposition"] = u'attachment; filename="中文附件.txt"'.decode('utf-8')
msg.attach(text_att)
#发送邮件
smtp = smtplib.SMTP()
smtp.connect('smtp.163.com')
#我们用set_debuglevel(1)就可以打印出和SMTP服务器交互的所有信息。
#smtp.set_debuglevel(1)
smtp.login(username, password)
smtp.sendmail(sender, receiver, msg.as_string())
smtp.quit()
示例 ==> 并发请求指定URL http://download.joedog.org/
siege -c 5 -r 2 http://download.joedog.org/
参数说明: -c 是并发量,并发数为5, -r 是重复次数, 重复2次
某次运行的结果~
Transactions: 30 hits ## 完成处理数30
Availability: 100.00 % ## 可用,成功率100%
Elapsed time: 4.67 secs ## 耗时4.67秒
Data transferred: 0.07 MB ## 数据传输0.07MB
Response time: 0.50 secs ## 响应时间0.50秒
Transaction rate: 6.42 trans/sec ## 每秒完成6.42个处理
Throughput: 0.01 MB/sec ## 吞吐量,每秒传输0.01MB
Concurrency: 3.21 ## 实际最高并发连接数
Successful transactions: 30 ## 成功完成处理30次
Failed transactions: 0 ## 失败0次
Longest transaction: 2.25 ## 每次传输所花最长时间
Shortest transaction: 0.37 ## 每次传输所花最短时间
在本篇博文中,我们将对Siege使用方法和参数,结合示例进行说明~
Siege使用方法
可以先通过siege -h 或者siege --help 命令,查看一下siege的帮助信息,如:
[root@test03 siege-4.0.2]# siege -h
[alert] Zip encoding disabled; siege requires zlib support to enable it
SIEGE 4.0.2
Usage: siege [options]
siege [options] URL
siege -g URL
Options:
-V, --version VERSION, prints the version number.
-h, --help HELP, prints this section.
-C, --config CONFIGURATION, show the current config.
-v, --verbose VERBOSE, prints notification to screen.
-q, --quiet QUIET turns verbose off and suppresses output.
-g, --get GET, pull down HTTP headers and display the
transaction. Great for application debugging.
-c, --concurrent=NUM CONCURRENT users, default is 10
-r, --reps=NUM REPS, number of times to run the test.
-t, --time=NUMm TIMED testing where "m" is modifier S, M, or H
ex: --time=1H, one hour test.
-d, --delay=NUM Time DELAY, random delay before each requst
-b, --benchmark BENCHMARK: no delays between requests.
-i, --internet INTERNET user simulation, hits URLs randomly.
-f, --file=FILE FILE, select a specific URLS FILE.
-R, --rc=FILE RC, specify an siegerc file
-l, --log[=FILE] LOG to FILE. If FILE is not specified, the
default is used: PREFIX/var/siege.log
-m, --mark="text" MARK, mark the log file with a string.
between .001 and NUM. (NOT COUNTED IN STATS)
-H, --header="text" Add a header to request (can be many)
-A, --user-agent="text" Sets User-Agent in request
-T, --content-type="text" Sets Content-Type in request
Copyright (C) 2016 by Jeffrey Fulmer, et al.
This is free software; see the source for copying conditions.
There is NO warranty; not even for MERCHANTABILITY or FITNESS
FOR A PARTICULAR PURPOSE.
[root@test03 siege-4.0.2]#
从上述帮助信息中,可以看出siege的使用方法有如下三种方法
Usage:
- siege [options]
- siege [options] URL
- siege -g URL
其中option的可选项有如下这些:
Options:
-V, --version VERSION, prints the version number.
-h, --help HELP, prints this section.
-C, --config CONFIGURATION, show the current config.
-v, --verbose VERBOSE, prints notification to screen.
-q, --quiet QUIET turns verbose off and suppresses output.
-g, --get GET, pull down HTTP headers and display the
transaction. Great for application debugging.
-c, --concurrent=NUM CONCURRENT users, default is 10
-r, --reps=NUM REPS, number of times to run the test.
-t, --time=NUMm TIMED testing where "m" is modifier S, M, or H
ex: --time=1H, one hour test.
-d, --delay=NUM Time DELAY, random delay before each requst
-b, --benchmark BENCHMARK: no delays between requests.
-i, --internet INTERNET user simulation, hits URLs randomly.
-f, --file=FILE FILE, select a specific URLS FILE.
-R, --rc=FILE RC, specify an siegerc file
-l, --log[=FILE] LOG to FILE. If FILE is not specified, the
default is used: PREFIX/var/siege.log
-m, --mark="text" MARK, mark the log file with a string.
between .001 and NUM. (NOT COUNTED IN STATS)
-H, --header="text" Add a header to request (can be many)
-A, --user-agent="text" Sets User-Agent in request
-T, --content-type="text" Sets Content-Type in request
siege [options]
该使用方法主要用于:
- 查看版本信息
- 查看帮助信息
- 查看当前配置信息
- 使用siege -V 或者 siege --version 查看siege版本信息
[root@test03 siege-4.0.2]# siege -V
[alert] Zip encoding disabled; siege requires zlib support to enable it
SIEGE 4.0.2
Copyright (C) 2016 by Jeffrey Fulmer, et al.
This is free software; see the source for copying conditions.
There is NO warranty; not even for MERCHANTABILITY or FITNESS
FOR A PARTICULAR PURPOSE.
[root@test03 siege-4.0.2]#
- 使用siege -h 或者 siege --help 查看帮助信息
[root@test03 siege-4.0.2]# siege -h
[alert] Zip encoding disabled; siege requires zlib support to enable it
SIEGE 4.0.2
Usage: siege [options]
siege [options] URL
siege -g URL
Options:
-V, --version VERSION, prints the version number.
-h, --help HELP, prints this section.
-C, --config CONFIGURATION, show the current config.
-v, --verbose VERBOSE, prints notification to screen.
-q, --quiet QUIET turns verbose off and suppresses output.
-g, --get GET, pull down HTTP headers and display the
transaction. Great for application debugging.
-c, --concurrent=NUM CONCURRENT users, default is 10
-r, --reps=NUM REPS, number of times to run the test.
-t, --time=NUMm TIMED testing where "m" is modifier S, M, or H
ex: --time=1H, one hour test.
-d, --delay=NUM Time DELAY, random delay before each requst
-b, --benchmark BENCHMARK: no delays between requests.
-i, --internet INTERNET user simulation, hits URLs randomly.
-f, --file=FILE FILE, select a specific URLS FILE.
-R, --rc=FILE RC, specify an siegerc file
-l, --log[=FILE] LOG to FILE. If FILE is not specified, the
default is used: PREFIX/var/siege.log
-m, --mark="text" MARK, mark the log file with a string.
between .001 and NUM. (NOT COUNTED IN STATS)
-H, --header="text" Add a header to request (can be many)
-A, --user-agent="text" Sets User-Agent in request
-T, --content-type="text" Sets Content-Type in request
Copyright (C) 2016 by Jeffrey Fulmer, et al.
This is free software; see the source for copying conditions.
There is NO warranty; not even for MERCHANTABILITY or FITNESS
FOR A PARTICULAR PURPOSE.
[root@test03 siege-4.0.2]#
- 使用siege -C 或者 siege --config 查看当前Siege的配置信息
[root@test03 siege-4.0.2]# siege -C
[alert] Zip encoding disabled; siege requires zlib support to enable it
CURRENT SIEGE CONFIGURATION
Mozilla/5.0 (unknown-x86_64-linux-gnu) Siege/4.0.2
Edit the resource file to change the settings.
----------------------------------------------
version: 4.0.2
verbose: true
color: true
quiet: false
debug: false
protocol: HTTP/1.1
HTML parser: enabled
get method: HEAD
connection: close
concurrent users: 25
time to run: n/a
repetitions: n/a
socket timeout: 30
accept-encoding: *
delay: 0.500 sec
internet simulation: false
benchmark mode: false
failures until abort: 1024
named URL: none
URLs file: /usr/local/etc/urls.txt
thread limit: 255
logging: false
log file: /usr/local/var/log/siege.log
resource file: /root/.siege/siege.conf
timestamped output: false
comma separated output: false
allow redirects: true
allow zero byte data: true
allow chunked encoding: true
upload unique files: true
no-follow:
- ad.doubleclick.net
- pagead2.googlesyndication.com
- ads.pubsqrd.com
- ib.adnxs.com
[root@test03 siege-4.0.2]#
siege -g URL
获取指定URL的Header信息,并显示HTTP处理信息~
siege -g http://www.baidu.com
[root@test03 siege-4.0.2]# siege -g http://www.baidu.com
[alert] Zip encoding disabled; siege requires zlib support to enable it
HEAD / HTTP/1.0
Host: www.baidu.com
Accept: */*
User-Agent: Mozilla/5.0 (unknown-x86_64-linux-gnu) Siege/4.0.2
Connection: close
HTTP/1.1 200 OK
Server: bfe/1.0.8.18
Date: Sat, 03 Jun 2017 03:02:23 GMT
Content-Type: text/html
Content-Length: 277
Last-Modified: Mon, 13 Jun 2016 02:50:23 GMT
Connection: Close
ETag: "575e1f6f-115"
Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform
Pragma: no-cache
Accept-Ranges: bytes
Transactions: 1 hits
Availability: 100.00 %
Elapsed time: 0.45 secs
Data transferred: 0.00 MB
Response time: 0.10 secs
Transaction rate: 2.22 trans/sec
Throughput: 0.00 MB/sec
Concurrency: 0.22
Successful transactions: 1
Failed transactions: 0
Longest transaction: 0.10
Shortest transaction: 0.10
[root@test03 siege-4.0.2]#
siege [options] URL
这种使用方法是最主要的,接下来,结合示例对参数的使用进行说明~
Siege参数说明&示例
Siege常用参数
Siege常用的参数有如下几个:
-c 或者 --concurrent=NUM : 用于指定并发人数
-r 或者 --reps=NUM : 用于指定重复次数
-d 或者 --delay=NUM : 用于指定延迟时间
-f 或者 --file=FILE : 用于指定URL列表的文件,可以一次对多个路径进行测试
-t 或者 --time=NUMm : 用于指定测试持续时间。例如: -t10S (10秒) -t5M(5分钟) -t1H(1小时)
-l 或者 --log[=FILE] : 用于记录结果日志
一般测试基本上多个参数组合在一起来完成的,下面,我们就一起来玩几个测试示例~
并发请求URL
siege -c5 -r2 http://www.bing.com
[root@test03 siege-4.0.2]# siege -c5 -r2 http://www.bing.com
[alert] Zip encoding disabled; siege requires zlib support to enable it
** SIEGE 4.0.2
** Preparing 5 concurrent users for battle.
The server is now under siege...
HTTP/1.1 301 0.13 secs: 0 bytes ==> GET /
HTTP/1.1 301 0.14 secs: 0 bytes ==> GET /
HTTP/1.1 301 0.14 secs: 0 bytes ==> GET /
HTTP/1.1 301 0.14 secs: 0 bytes ==> GET /
HTTP/1.1 301 0.14 secs: 0 bytes ==> GET /
HTTP/1.1 200 0.27 secs: 126193 bytes ==> GET /
HTTP/1.1 200 0.32 secs: 126193 bytes ==> GET /
HTTP/1.1 200 0.37 secs: 126193 bytes ==> GET /
HTTP/1.1 200 0.43 secs: 126193 bytes ==> GET /
HTTP/1.1 200 0.50 secs: 126193 bytes ==> GET /
HTTP/1.1 200 0.22 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.17 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.12 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.07 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.07 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 301 0.06 secs: 0 bytes ==> GET /
HTTP/1.1 301 0.07 secs: 0 bytes ==> GET /
HTTP/1.1 301 0.07 secs: 0 bytes ==> GET /
HTTP/1.1 301 0.06 secs: 0 bytes ==> GET /
HTTP/1.1 301 0.05 secs: 0 bytes ==> GET /
HTTP/1.1 200 0.24 secs: 126124 bytes ==> GET /
HTTP/1.1 200 0.28 secs: 126124 bytes ==> GET /
HTTP/1.1 200 0.30 secs: 126124 bytes ==> GET /
HTTP/1.1 200 0.34 secs: 126124 bytes ==> GET /
HTTP/1.1 200 0.22 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.16 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.11 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.34 secs: 126124 bytes ==> GET /
HTTP/1.1 200 0.07 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.06 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
Transactions: 30 hits
Availability: 100.00 %
Elapsed time: 1.73 secs
Data transferred: 1.27 MB
Response time: 0.19 secs
Transaction rate: 17.34 trans/sec
Throughput: 0.73 MB/sec
Concurrency: 3.27
Successful transactions: 30
Failed transactions: 0
Longest transaction: 0.50
Shortest transaction: 0.05
[root@test03 siege-4.0.2]#
在此基础上增加持续时间,设置为5秒
siege -c5 -r2 -t5S http://www.bing.com
[root@test03 siege-4.0.2]# siege -c5 -r2 -t5S http://www.bing.com
[alert] Zip encoding disabled; siege requires zlib support to enable it
[error] CONFIG conflict: selected time and repetition based testing
defaulting to time-based testing: 5 seconds
** SIEGE 4.0.2
** Preparing 5 concurrent users for battle.
The server is now under siege...
HTTP/1.1 301 0.13 secs: 0 bytes ==> GET /
HTTP/1.1 301 0.14 secs: 0 bytes ==> GET /
HTTP/1.1 301 0.14 secs: 0 bytes ==> GET /
HTTP/1.1 301 0.14 secs: 0 bytes ==> GET /
HTTP/1.1 301 0.14 secs: 0 bytes ==> GET /
HTTP/1.1 200 0.19 secs: 126193 bytes ==> GET /
HTTP/1.1 200 0.25 secs: 126193 bytes ==> GET /
HTTP/1.1 200 0.32 secs: 126193 bytes ==> GET /
HTTP/1.1 200 0.36 secs: 126193 bytes ==> GET /
HTTP/1.1 200 0.42 secs: 126193 bytes ==> GET /
HTTP/1.1 200 0.23 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.17 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.11 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.07 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.07 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 301 0.07 secs: 0 bytes ==> GET /
HTTP/1.1 301 0.06 secs: 0 bytes ==> GET /
HTTP/1.1 200 0.22 secs: 126124 bytes ==> GET /
HTTP/1.1 301 0.07 secs: 0 bytes ==> GET /
HTTP/1.1 301 0.06 secs: 0 bytes ==> GET /
HTTP/1.1 200 0.05 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 301 0.05 secs: 0 bytes ==> GET /
HTTP/1.1 200 0.28 secs: 126124 bytes ==> GET /
HTTP/1.1 301 0.06 secs: 0 bytes ==> GET /
HTTP/1.1 200 0.45 secs: 126124 bytes ==> GET /
HTTP/1.1 200 0.49 secs: 126124 bytes ==> GET /
HTTP/1.1 200 0.35 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.52 secs: 126124 bytes ==> GET /
HTTP/1.1 200 0.15 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.10 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.28 secs: 126124 bytes ==> GET /
HTTP/1.1 200 0.06 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.07 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 301 0.06 secs: 0 bytes ==> GET /
HTTP/1.1 301 0.07 secs: 0 bytes ==> GET /
HTTP/1.1 301 0.07 secs: 0 bytes ==> GET /
HTTP/1.1 301 0.06 secs: 0 bytes ==> GET /
HTTP/1.1 301 0.06 secs: 0 bytes ==> GET /
HTTP/1.1 200 0.25 secs: 126124 bytes ==> GET /
HTTP/1.1 200 0.25 secs: 126124 bytes ==> GET /
HTTP/1.1 200 0.08 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.23 secs: 126124 bytes ==> GET /
HTTP/1.1 200 0.25 secs: 126124 bytes ==> GET /
HTTP/1.1 200 0.18 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.13 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.29 secs: 126124 bytes ==> GET /
HTTP/1.1 200 0.06 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.06 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 301 0.05 secs: 0 bytes ==> GET /
HTTP/1.1 301 0.05 secs: 0 bytes ==> GET /
HTTP/1.1 301 0.07 secs: 0 bytes ==> GET /
HTTP/1.1 301 0.06 secs: 0 bytes ==> GET /
HTTP/1.1 301 0.07 secs: 0 bytes ==> GET /
HTTP/1.1 200 0.28 secs: 126124 bytes ==> GET /
HTTP/1.1 200 0.31 secs: 126124 bytes ==> GET /
HTTP/1.1 200 0.31 secs: 126124 bytes ==> GET /
HTTP/1.1 200 0.34 secs: 126124 bytes ==> GET /
HTTP/1.1 200 0.38 secs: 126124 bytes ==> GET /
HTTP/1.1 200 0.24 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.18 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.13 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.06 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.06 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 301 0.05 secs: 0 bytes ==> GET /
HTTP/1.1 200 0.24 secs: 126124 bytes ==> GET /
HTTP/1.1 301 0.06 secs: 0 bytes ==> GET /
HTTP/1.1 200 0.05 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 301 0.06 secs: 0 bytes ==> GET /
HTTP/1.1 301 0.07 secs: 0 bytes ==> GET /
HTTP/1.1 301 0.07 secs: 0 bytes ==> GET /
HTTP/1.1 301 0.06 secs: 0 bytes ==> GET /
HTTP/1.1 200 0.25 secs: 126124 bytes ==> GET /
HTTP/1.1 200 0.24 secs: 126124 bytes ==> GET /
HTTP/1.1 200 0.29 secs: 126124 bytes ==> GET /
HTTP/1.1 200 0.30 secs: 126124 bytes ==> GET /
HTTP/1.1 200 0.22 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.11 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.18 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.35 secs: 126124 bytes ==> GET /
HTTP/1.1 200 0.06 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.05 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 301 0.05 secs: 0 bytes ==> GET /
HTTP/1.1 301 0.07 secs: 0 bytes ==> GET /
HTTP/1.1 200 0.27 secs: 126124 bytes ==> GET /
HTTP/1.1 301 0.07 secs: 0 bytes ==> GET /
HTTP/1.1 200 0.25 secs: 126124 bytes ==> GET /
HTTP/1.1 200 0.06 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 301 0.07 secs: 0 bytes ==> GET /
HTTP/1.1 200 0.07 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 301 0.06 secs: 0 bytes ==> GET /
HTTP/1.1 200 0.23 secs: 126124 bytes ==> GET /
HTTP/1.1 301 0.06 secs: 0 bytes ==> GET /
HTTP/1.1 200 0.24 secs: 126124 bytes ==> GET /
Lifting the server siege...
Transactions: 91 hits
Availability: 100.00 %
Elapsed time: 4.51 secs
Data transferred: 3.92 MB
Response time: 0.17 secs
Transaction rate: 20.18 trans/sec
Throughput: 0.87 MB/sec
Concurrency: 3.36
Successful transactions: 93
Failed transactions: 0
Longest transaction: 0.52
Shortest transaction: 0.05
[root@test03 siege-4.0.2]#
多个URL场景测试
问题: 如果想测试多个URL怎么办呢?
我们只要将多个URL存放到一个文件中即可~
通过siege -C我们可以看到如下信息,
[root@test03 siege-4.0.2]# siege -C
[alert] Zip encoding disabled; siege requires zlib support to enable it
CURRENT SIEGE CONFIGURATION
Mozilla/5.0 (unknown-x86_64-linux-gnu) Siege/4.0.2
Edit the resource file to change the settings.
----------------------------------------------
version: 4.0.2
verbose: true
color: true
quiet: false
debug: false
protocol: HTTP/1.1
HTML parser: enabled
get method: HEAD
connection: close
concurrent users: 25
time to run: n/a
repetitions: n/a
socket timeout: 30
accept-encoding: *
delay: 0.500 sec
internet simulation: false
benchmark mode: false
failures until abort: 1024
named URL: none
URLs file: /usr/local/etc/urls.txt
thread limit: 255
logging: false
log file: /usr/local/var/log/siege.log
resource file: /root/.siege/siege.conf
timestamped output: false
comma separated output: false
allow redirects: true
allow zero byte data: true
allow chunked encoding: true
upload unique files: true
no-follow:
- ad.doubleclick.net
- pagead2.googlesyndication.com
- ads.pubsqrd.com
- ib.adnxs.com
[root@test03 siege-4.0.2]#
从上述信息中可以看出,Siege默认情况下URLS FILE的路径为**/usr/local/etc/urls.txt**
urls.txt的内容如下:
# URLS file for siege
# --
# Format the url entries in any of the following formats:
# http://www.whoohoo.com/index.html
# http://www/index.html
# www/index.html
# http://www.whoohoo.com/cgi-bin/howto/display.cgi?1013
# Use the POST directive for pages that require it:
# http://www.whoohoo.com/cgi-bin/haha.cgi POST ha=1&ho=2
# or POST content from a file:
# http://www.whoohoo.com/melvin.jsp POST </home/jeff/haha
# http://www.whoohoo.com/melvin.jsp POST <./haha
# You may also set and reference variables inside this file,
# for more information, man urls_txt
# -------------------------------------------------------
我们可以通过 -f参数来指定一个文件,如/srv/myurls.txt, 里面存放指定网址
http://www.baidu.com
http://cn.bing.com/
注,上述URL很简单,并不在Header或者其他地方设置参数~
使用如下命令即可~
siege -c5 -r2 -f /srv/myurls.txt
[root@test03 siege-4.0.2]# siege -c5 -r2 -f /srv/myurls.txt
[alert] Zip encoding disabled; siege requires zlib support to enable it
** SIEGE 4.0.2
** Preparing 5 concurrent users for battle.
The server is now under siege...
HTTP/1.1 200 0.14 secs: 102074 bytes ==> GET /
HTTP/1.1 200 0.16 secs: 102202 bytes ==> GET /
HTTP/1.1 200 0.19 secs: 102123 bytes ==> GET /
HTTP/1.1 200 0.25 secs: 102238 bytes ==> GET /
HTTP/1.1 200 0.14 secs: 2947 bytes ==> GET /baidu.html?from=noscript
HTTP/1.1 200 0.12 secs: 2947 bytes ==> GET /baidu.html?from=noscript
HTTP/1.1 200 0.09 secs: 2947 bytes ==> GET /baidu.html?from=noscript
HTTP/1.1 200 0.28 secs: 102168 bytes ==> GET /
HTTP/1.1 200 0.06 secs: 2947 bytes ==> GET /baidu.html?from=noscript
HTTP/1.1 200 0.06 secs: 91 bytes ==> GET /img/gs.gif
HTTP/1.1 200 0.06 secs: 91 bytes ==> GET /img/gs.gif
HTTP/1.1 200 0.06 secs: 91 bytes ==> GET /img/gs.gif
HTTP/1.1 200 0.06 secs: 2947 bytes ==> GET /baidu.html?from=noscript
HTTP/1.1 200 0.06 secs: 91 bytes ==> GET /img/gs.gif
HTTP/1.1 200 0.05 secs: 91 bytes ==> GET /img/gs.gif
[error] HTTPS requires libssl: Unable to reach ss1.bdstatic.com with this protocol: Transport endpoint is already connected
[error] HTTPS requires libssl: Unable to reach ss1.bdstatic.com with this protocol: Transport endpoint is already connected
[error] HTTPS requires libssl: Unable to reach ss1.bdstatic.com with this protocol: Transport endpoint is already connected
[error] HTTPS requires libssl: Unable to reach ss1.bdstatic.com with this protocol: Transport endpoint is already connected
[error] HTTPS requires libssl: Unable to reach ss1.bdstatic.com with this protocol: Transport endpoint is already connected
HTTP/1.1 200 0.05 secs: 93750 bytes ==> GET /r/www/cache/static/jquery/jquery-1.10.2.min_65682a2.js
HTTP/1.1 200 0.05 secs: 93750 bytes ==> GET /r/www/cache/static/jquery/jquery-1.10.2.min_65682a2.js
HTTP/1.1 200 0.05 secs: 93750 bytes ==> GET /r/www/cache/static/jquery/jquery-1.10.2.min_65682a2.js
HTTP/1.1 200 0.06 secs: 93750 bytes ==> GET /r/www/cache/static/jquery/jquery-1.10.2.min_65682a2.js
HTTP/1.1 200 0.07 secs: 93750 bytes ==> GET /r/www/cache/static/jquery/jquery-1.10.2.min_65682a2.js
HTTP/1.1 200 0.06 secs: 705 bytes ==> GET /img/baidu_jgylogo3.gif
HTTP/1.1 200 0.06 secs: 705 bytes ==> GET /img/baidu_jgylogo3.gif
HTTP/1.1 200 0.06 secs: 705 bytes ==> GET /img/baidu_jgylogo3.gif
HTTP/1.1 200 0.07 secs: 705 bytes ==> GET /img/baidu_jgylogo3.gif
HTTP/1.1 200 0.06 secs: 705 bytes ==> GET /img/baidu_jgylogo3.gif
HTTP/1.1 200 0.06 secs: 7877 bytes ==> GET /img/bd_logo1.png
HTTP/1.1 200 0.06 secs: 7877 bytes ==> GET /img/bd_logo1.png
HTTP/1.1 200 0.06 secs: 7877 bytes ==> GET /img/bd_logo1.png
HTTP/1.1 200 0.06 secs: 7877 bytes ==> GET /img/bd_logo1.png
HTTP/1.1 200 0.06 secs: 7877 bytes ==> GET /img/bd_logo1.png
HTTP/1.1 200 0.28 secs: 126193 bytes ==> GET /
HTTP/1.1 200 0.28 secs: 126193 bytes ==> GET /
HTTP/1.1 200 0.30 secs: 126193 bytes ==> GET /
HTTP/1.1 200 0.17 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.10 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.32 secs: 126193 bytes ==> GET /
HTTP/1.1 200 0.06 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.07 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.23 secs: 126193 bytes ==> GET /
HTTP/1.1 200 0.07 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
Transactions: 40 hits
Availability: 88.89 %
Elapsed time: 1.62 secs
Data transferred: 1.62 MB
Response time: 0.11 secs
Transaction rate: 24.69 trans/sec
Throughput: 1.00 MB/sec
Concurrency: 2.81
Successful transactions: 40
Failed transactions: 5
Longest transaction: 0.32
Shortest transaction: 0.05
[root@test03 siege-4.0.2]#
记录结果到日志
如果想把测试结果存放到日志文件中去,可以使用**--log参数**,如:
siege -c5 -r2 --log=/srv/siege_result.log -f /srv/myurls.txt
[root@test03 srv]# siege -c5 -r2 --log=/srv/siege_result.log -f /srv/myurls.txt
[alert] Zip encoding disabled; siege requires zlib support to enable it
** SIEGE 4.0.2
** Preparing 5 concurrent users for battle.
The server is now under siege...
HTTP/1.1 200 0.15 secs: 102110 bytes ==> GET /
HTTP/1.1 200 0.20 secs: 102087 bytes ==> GET /
HTTP/1.1 200 0.24 secs: 101920 bytes ==> GET /
HTTP/1.1 200 0.27 secs: 102186 bytes ==> GET /
HTTP/1.1 200 0.15 secs: 2947 bytes ==> GET /baidu.html?from=noscript
HTTP/1.1 200 0.09 secs: 2947 bytes ==> GET /baidu.html?from=noscript
HTTP/1.1 200 0.30 secs: 101935 bytes ==> GET /
HTTP/1.1 200 0.06 secs: 2947 bytes ==> GET /baidu.html?from=noscript
HTTP/1.1 200 0.06 secs: 2947 bytes ==> GET /baidu.html?from=noscript
HTTP/1.1 200 0.06 secs: 91 bytes ==> GET /img/gs.gif
HTTP/1.1 200 0.06 secs: 91 bytes ==> GET /img/gs.gif
HTTP/1.1 200 0.06 secs: 2947 bytes ==> GET /baidu.html?from=noscript
HTTP/1.1 200 0.06 secs: 91 bytes ==> GET /img/gs.gif
HTTP/1.1 200 0.07 secs: 91 bytes ==> GET /img/gs.gif
HTTP/1.1 200 0.06 secs: 91 bytes ==> GET /img/gs.gif
[error] HTTPS requires libssl: Unable to reach ss1.bdstatic.com with this protocol: Transport endpoint is already connected
[error] HTTPS requires libssl: Unable to reach ss1.bdstatic.com with this protocol: Transport endpoint is already connected
[error] HTTPS requires libssl: Unable to reach ss1.bdstatic.com with this protocol: Transport endpoint is already connected
[error] HTTPS requires libssl: Unable to reach ss1.bdstatic.com with this protocol: Transport endpoint is already connected
[error] HTTPS requires libssl: Unable to reach ss1.bdstatic.com with this protocol: Transport endpoint is already connected
HTTP/1.1 200 0.05 secs: 93750 bytes ==> GET /r/www/cache/static/jquery/jquery-1.10.2.min_65682a2.js
HTTP/1.1 200 0.06 secs: 93750 bytes ==> GET /r/www/cache/static/jquery/jquery-1.10.2.min_65682a2.js
HTTP/1.1 200 0.06 secs: 93750 bytes ==> GET /r/www/cache/static/jquery/jquery-1.10.2.min_65682a2.js
HTTP/1.1 200 0.06 secs: 93750 bytes ==> GET /r/www/cache/static/jquery/jquery-1.10.2.min_65682a2.js
HTTP/1.1 200 0.07 secs: 93750 bytes ==> GET /r/www/cache/static/jquery/jquery-1.10.2.min_65682a2.js
HTTP/1.1 200 0.06 secs: 705 bytes ==> GET /img/baidu_jgylogo3.gif
HTTP/1.1 200 0.06 secs: 705 bytes ==> GET /img/baidu_jgylogo3.gif
HTTP/1.1 200 0.06 secs: 705 bytes ==> GET /img/baidu_jgylogo3.gif
HTTP/1.1 200 0.07 secs: 705 bytes ==> GET /img/baidu_jgylogo3.gif
HTTP/1.1 200 0.06 secs: 705 bytes ==> GET /img/baidu_jgylogo3.gif
HTTP/1.1 200 0.06 secs: 7877 bytes ==> GET /img/bd_logo1.png
HTTP/1.1 200 0.06 secs: 7877 bytes ==> GET /img/bd_logo1.png
HTTP/1.1 200 0.07 secs: 7877 bytes ==> GET /img/bd_logo1.png
HTTP/1.1 200 0.06 secs: 7877 bytes ==> GET /img/bd_logo1.png
HTTP/1.1 200 0.06 secs: 7877 bytes ==> GET /img/bd_logo1.png
HTTP/1.1 200 0.26 secs: 126193 bytes ==> GET /
HTTP/1.1 200 0.29 secs: 126193 bytes ==> GET /
HTTP/1.1 200 0.12 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.30 secs: 126193 bytes ==> GET /
HTTP/1.1 200 0.06 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.06 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.25 secs: 126193 bytes ==> GET /
HTTP/1.1 200 0.25 secs: 126193 bytes ==> GET /
HTTP/1.1 200 0.06 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
HTTP/1.1 200 0.06 secs: 6752 bytes ==> GET /rms/rms%20answers%20Homepage%20ZhCn$BingAppQR/ic/0d08e928/0f482622.png
Transactions: 40 hits
Availability: 88.89 %
Elapsed time: 1.70 secs
Data transferred: 1.62 MB
Response time: 0.11 secs
Transaction rate: 23.53 trans/sec
Throughput: 0.95 MB/sec
Concurrency: 2.66
Successful transactions: 40
Failed transactions: 5
Longest transaction: 0.30
Shortest transaction: 0.05
LOG FILE: /srv/siege_result.log
You can disable this log file notification by editing
/root/.siege/siege.conf and changing 'show-logfile' to false.
[root@test03 srv]#
其中,
Transactions: 40 hits
Availability: 88.89 %
Elapsed time: 1.70 secs
Data transferred: 1.62 MB
Response time: 0.11 secs
Transaction rate: 23.53 trans/sec
Throughput: 0.95 MB/sec
Concurrency: 2.66
Successful transactions: 40
Failed transactions: 5
Longest transaction: 0.30
Shortest transaction: 0.05
这些结果信息会记录到指定的siege_result.log文件中,
Date & Time, Trans, Elap Time, Data Trans, Resp Time, Trans Rate, Throughput, Concurrent, OKAY, Failed
2017-06-03 14:37:03, 40, 1.70, 1, 0.11, 23.53, 0.59, 2.66, 40, 5
Header参数传值
在平时写接口的时候,可能需要先通过一个key获得相应的token,在这种时候,获取token的接口,需要在Header中设置key的参数和值。
在这种情况下,可以通过**--header "key:abcdefg123456789"** 这样的方法来进行测试~
如:
siege -c5 -r2 --header "key:WJPRVEZEPMGX4RYESQ4ZPYPQLP2G0HCA" http://127.0.0.1:8080/accessToken
测试示例:
[root@test03 srv]# siege -c5 -r2 --header "key:WJPRVEZEPMGX4RYESQ4ZPYPQLP2G0HCA" http://127.0.0.1:8080/accessToken
[alert] Zip encoding disabled; siege requires zlib support to enable it
** SIEGE 4.0.2
** Preparing 5 concurrent users for battle.
The server is now under siege...
HTTP/1.1 200 0.06 secs: 99 bytes ==> GET /accessToken
HTTP/1.1 200 0.06 secs: 99 bytes ==> GET /accessToken
HTTP/1.1 200 0.08 secs: 99 bytes ==> GET /accessToken
HTTP/1.1 200 0.09 secs: 99 bytes ==> GET /accessToken
HTTP/1.1 200 0.09 secs: 99 bytes ==> GET /accessToken
HTTP/1.1 200 0.02 secs: 99 bytes ==> GET /accessToken
HTTP/1.1 200 0.02 secs: 99 bytes ==> GET /accessToken
HTTP/1.1 200 0.02 secs: 99 bytes ==> GET /accessToken
HTTP/1.1 200 0.02 secs: 99 bytes ==> GET /accessToken
HTTP/1.1 200 0.02 secs: 99 bytes ==> GET /accessToken
Transactions: 10 hits
Availability: 100.00 %
Elapsed time: 0.77 secs
Data transferred: 0.00 MB
Response time: 0.05 secs
Transaction rate: 12.99 trans/sec
Throughput: 0.00 MB/sec
Concurrency: 0.62
Successful transactions: 10
Failed transactions: 0
Longest transaction: 0.09
Shortest transaction: 0.02
[root@test03 srv]#
POST + JSON测试
假设我们需要测试一个接口方法,POST请求,请求内容为JSON, 并且需要在Header中使用AccessToken。
问题:
这样的情况,我们如何进行传值和测试呢?
Header中的传值可以使用**--header "accessToken:c6fe5634d629497ba1bb9e89c2e2fb59"**来完成。
至于提交的JSON内容,可以将其放到一个文件中( 如myjson.txt ), 本示例文件中的内容如下:
{
"actions":[{
"actionId":"set_room_temp",
"value":28
}]
}
然后指定URL路径 和 json体的文件路径
'http://127.0.0.1/v1/control/3WIMLT4P3FZvirtualsn0000000 POST < /srv/myjson.txt'
注意:
上述内容需要用单引号括起来,否则会产生错误~
本文使用的示例如下:
siege -c5 -r1 --header "accessToken:c6fe5634d629497ba1bb9e89c2e2fb59" 'http://127.0.0.1/v1/control/3WIMLT4P3FZvirtualsn0000000 POST < /srv/myjson.txt'
[root@test03 srv]# siege -c5 -r1 --header "accessToken:c6fe5634d629497ba1bb9e89c2e2fb59" 'http://127.0.0.1/v1/control/3WIMLT4P3FZvirtualsn0000000 POST < /srv/myjson.txt'
[alert] Zip encoding disabled; siege requires zlib support to enable it
** SIEGE 4.0.2
** Preparing 5 concurrent users for battle.
The server is now under siege...
HTTP/1.1 200 0.13 secs: 57 bytes ==> POST http://127.0.0.1/v1/control/3WIMLT4P3FZvirtualsn0000000
HTTP/1.1 200 0.13 secs: 57 bytes ==> POST http://127.0.0.1/v1/control/3WIMLT4P3FZvirtualsn0000000
HTTP/1.1 200 0.14 secs: 57 bytes ==> POST http://127.0.0.1/v1/control/3WIMLT4P3FZvirtualsn0000000
HTTP/1.1 200 0.15 secs: 57 bytes ==> POST http://127.0.0.1/v1/control/3WIMLT4P3FZvirtualsn0000000
HTTP/1.1 200 0.16 secs: 57 bytes ==> POST http://127.0.0.1/v1/control/3WIMLT4P3FZvirtualsn0000000
Transactions: 5 hits
Availability: 100.00 %
Elapsed time: 0.54 secs
Data transferred: 0.00 MB
Response time: 0.14 secs
Transaction rate: 9.26 trans/sec
Throughput: 0.00 MB/sec
Concurrency: 1.31
Successful transactions: 5
Failed transactions: 0
Longest transaction: 0.16
Shortest transaction: 0.13
[root@test03 srv]#
redis是业界主流的key-value nosql 数据库之一。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
Redis从它的许多竞争继承来的三个主要特点:
- Redis数据库完全在内存中,使用磁盘仅用于持久性。
- 相比许多键值数据存储,Redis拥有一套较为丰富的数据类型。
- Redis可以将数据复制到任意数量的从服务器。
Redis 优势:
- 异常快速:Redis的速度非常快,每秒能执行约11万集合,每秒约81000+条记录。
- 支持丰富的数据类型:Redis支持最大多数开发人员已经知道像列表,集合,有序集合,散列数据类型。这使得它非常容易解决各种各样的问题,因为我们知道哪些问题是可以处理通过它的数据类型更好。
- 操作都是原子性:所有Redis操作是原子的,这保证了如果两个客户端同时访问的Redis服务器将获得更新后的值。
- 多功能实用工具:Redis是一个多实用的工具,可以在多个用例如缓存,消息,队列使用(Redis原生支持发布/订阅),任何短暂的数据,应用程序,如Web应用程序会话,网页命中计数等。
- MultiUtility工具:Redis是一个多功能实用工具,可以在很多如:缓存,消息传递队列中使用(Redis原生支持发布/订阅),在应用程序中,如:Web应用程序会话,网站页面点击数等任何短暂的数据;
centos7安装Redis
yum install epel-release
yum install redis
要在 Ubuntu 上安装 Redis,打开终端,然后输入以下命令:
$sudo apt-get update
$sudo apt-get install redis-server
这将在您的计算机上安装Redis
启动 Redis
$redis-server
查看 redis 是否还在运行
$redis-cli
这将打开一个 Redis 提示符,如下图所示:
redis 127.0.0.1:6379>
在上面的提示信息中:127.0.0.1 是本机的IP地址,6379是 Redis 服务器运行的端口。现在输入 PING 命令,如下图所示:
redis 127.0.0.1:6379> ping
PONG
这说明现在你已经成功地在计算机上安装了 Redis。
Redis 的配置文件位于 Redis 安装目录下,文件名为 redis.conf。
你可以通过 CONFIG 命令查看或设置配置项。
语法
Redis CONFIG 命令格式如下:
redis 127.0.0.1:6379> CONFIG GET CONFIG_SETTING_NAME
实例
redis 127.0.0.1:6379> CONFIG GET loglevel
1) "loglevel"
2) "notice"
使用 * 号获取所有配置项:
实例
redis 127.0.0.1:6379> CONFIG GET *
1) "dbfilename"
2) "dump.rdb"
3) "requirepass"
4) ""
5) "masterauth"
6) ""
7) "unixsocket"
8) ""
9) "logfile"
10) ""
11) "pidfile"
12) "/var/run/redis.pid"
13) "maxmemory"
14) "0"
15) "maxmemory-samples"
16) "3"
17) "timeout"
18) "0"
19) "tcp-keepalive"
20) "0"
21) "auto-aof-rewrite-percentage"
22) "100"
23) "auto-aof-rewrite-min-size"
24) "67108864"
25) "hash-max-ziplist-entries"
26) "512"
27) "hash-max-ziplist-value"
28) "64"
29) "list-max-ziplist-entries"
30) "512"
31) "list-max-ziplist-value"
32) "64"
33) "set-max-intset-entries"
34) "512"
35) "zset-max-ziplist-entries"
36) "128"
37) "zset-max-ziplist-value"
38) "64"
39) "hll-sparse-max-bytes"
40) "3000"
41) "lua-time-limit"
42) "5000"
43) "slowlog-log-slower-than"
44) "10000"
45) "latency-monitor-threshold"
46) "0"
47) "slowlog-max-len"
48) "128"
49) "port"
50) "6379"
51) "tcp-backlog"
52) "511"
53) "databases"
54) "16"
55) "repl-ping-slave-period"
56) "10"
57) "repl-timeout"
58) "60"
59) "repl-backlog-size"
60) "1048576"
61) "repl-backlog-ttl"
62) "3600"
63) "maxclients"
64) "4064"
65) "watchdog-period"
66) "0"
67) "slave-priority"
68) "100"
69) "min-slaves-to-write"
70) "0"
71) "min-slaves-max-lag"
72) "10"
73) "hz"
74) "10"
75) "no-appendfsync-on-rewrite"
76) "no"
77) "slave-serve-stale-data"
78) "yes"
79) "slave-read-only"
80) "yes"
81) "stop-writes-on-bgsave-error"
82) "yes"
83) "daemonize"
84) "no"
85) "rdbcompression"
86) "yes"
87) "rdbchecksum"
88) "yes"
89) "activerehashing"
90) "yes"
91) "repl-disable-tcp-nodelay"
92) "no"
93) "aof-rewrite-incremental-fsync"
94) "yes"
95) "appendonly"
96) "no"
97) "dir"
98) "/usr/local/redis-3.0/src" #这是redis的安装路径
99) "maxmemory-policy"
100) "volatile-lru"
101) "appendfsync"
102) "everysec"
103) "save"
104) "3600 1 300 100 60 10000"
105) "loglevel"
106) "notice"
107) "client-output-buffer-limit"
108) "normal 0 0 0 slave 268435456 67108864 60 pubsub 33554432 8388608 60"
109) "unixsocketperm"
110) "0"
111) "slaveof"
112) ""
113) "notify-keyspace-events"
114) ""
115) "bind"
116) ""
编辑配置
你可以通过修改 redis.conf 文件或使用 CONFIG set 命令来修改配置。
语法
CONFIG SET 命令基本语法:
redis 127.0.0.1:6379> CONFIG SET CONFIG_SETTING_NAME NEW_CONFIG_VALUE
实例
redis 127.0.0.1:6379> CONFIG SET loglevel "notice"
OK
redis 127.0.0.1:6379> CONFIG GET loglevel
1) "loglevel"
2) "notice"
参数说明
redis.conf 配置项说明如下:
1. Redis默认不是以守护进程的方式运行,可以通过该配置项修改,使用yes启用守护进程
daemonize no
2. 当Redis以守护进程方式运行时,Redis默认会把pid写入/var/run/redis.pid文件,可以通过pidfile指定
pidfile /var/run/redis.pid
3. 指定Redis监听端口,默认端口为6379,为什么选用6379作为默认端口,因为6379在手机按键上MERZ对应的号码,而MERZ取自意大利歌女Alessia Merz的名字
port 6379
4. 绑定的主机地址
bind 127.0.0.1
5.当 客户端闲置多长时间后关闭连接,如果指定为0,表示关闭该功能
timeout 300
6. 指定日志记录级别,Redis总共支持四个级别:debug、verbose、notice、warning,默认为verbose
loglevel verbose
7. 日志记录方式,默认为标准输出,如果配置Redis为守护进程方式运行,而这里又配置为日志记录方式为标准输出,则日志将会发送给/dev/null
logfile stdout
8. 设置数据库的数量,默认数据库为0,可以使用SELECT <dbid>命令在连接上指定数据库id
databases 16
9. 指定在多长时间内,有多少次更新操作,就将数据同步到数据文件,可以多个条件配合
save <seconds> <changes>
Redis默认配置文件中提供了三个条件:
save 900 1
save 300 10
save 60 10000
分别表示900秒(15分钟)内有1个更改,300秒(5分钟)内有10个更改以及60秒内有10000个更改。
10. 指定存储至本地数据库时是否压缩数据,默认为yes,Redis采用LZF压缩,如果为了节省CPU时间,可以关闭该选项,但会导致数据库文件变的巨大
rdbcompression yes
11. 指定本地数据库文件名,默认值为dump.rdb
dbfilename dump.rdb
12. 指定本地数据库存放目录
dir ./
13. 设置当本机为slav服务时,设置master服务的IP地址及端口,在Redis启动时,它会自动从master进行数据同步
slaveof <masterip> <masterport>
14. 当master服务设置了密码保护时,slav服务连接master的密码
masterauth <master-password>
15. 设置Redis连接密码,如果配置了连接密码,客户端在连接Redis时需要通过AUTH <password>命令提供密码,默认关闭
requirepass foobared
16. 设置同一时间最大客户端连接数,默认无限制,Redis可以同时打开的客户端连接数为Redis进程可以打开的最大文件描述符数,如果设置 maxclients 0,表示不作限制。当客户端连接数到达限制时,Redis会关闭新的连接并向客户端返回max number of clients reached错误信息
maxclients 128
17. 指定Redis最大内存限制,Redis在启动时会把数据加载到内存中,达到最大内存后,Redis会先尝试清除已到期或即将到期的Key,当此方法处理 后,仍然到达最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作。Redis新的vm机制,会把Key存放内存,Value会存放在swap区
maxmemory <bytes>
18. 指定是否在每次更新操作后进行日志记录,Redis在默认情况下是异步的把数据写入磁盘,如果不开启,可能会在断电时导致一段时间内的数据丢失。因为 redis本身同步数据文件是按上面save条件来同步的,所以有的数据会在一段时间内只存在于内存中。默认为no
appendonly no
19. 指定更新日志文件名,默认为appendonly.aof
appendfilename appendonly.aof
20. 指定更新日志条件,共有3个可选值: no:表示等操作系统进行数据缓存同步到磁盘(快) always:表示每次更新操作后手动调用fsync()将数据写到磁盘(慢,安全) everysec:表示每秒同步一次(折衷,默认值)
appendfsync everysec
21. 指定是否启用虚拟内存机制,默认值为no,简单的介绍一下,VM机制将数据分页存放,由Redis将访问量较少的页即冷数据swap到磁盘上,访问多的页面由磁盘自动换出到内存中(在后面的文章我会仔细分析Redis的VM机制)
vm-enabled no
22. 虚拟内存文件路径,默认值为/tmp/redis.swap,不可多个Redis实例共享
vm-swap-file /tmp/redis.swap
23. 将所有大于vm-max-memory的数据存入虚拟内存,无论vm-max-memory设置多小,所有索引数据都是内存存储的(Redis的索引数据 就是keys),也就是说,当vm-max-memory设置为0的时候,其实是所有value都存在于磁盘。默认值为0
vm-max-memory 0
24. Redis swap文件分成了很多的page,一个对象可以保存在多个page上面,但一个page上不能被多个对象共享,vm-page-size是要根据存储的 数据大小来设定的,作者建议如果存储很多小对象,page大小最好设置为32或者64bytes;如果存储很大大对象,则可以使用更大的page,如果不 确定,就使用默认值
vm-page-size 32
25. 设置swap文件中的page数量,由于页表(一种表示页面空闲或使用的bitmap)是在放在内存中的,,在磁盘上每8个pages将消耗1byte的内存。
vm-pages 134217728
26. 设置访问swap文件的线程数,最好不要超过机器的核数,如果设置为0,那么所有对swap文件的操作都是串行的,可能会造成比较长时间的延迟。默认值为4
vm-max-threads 4
27. 设置在向客户端应答时,是否把较小的包合并为一个包发送,默认为开启
glueoutputbuf yes
28. 指定在超过一定的数量或者最大的元素超过某一临界值时,采用一种特殊的哈希算法
hash-max-zipmap-entries 64
hash-max-zipmap-value 512
29. 指定是否激活重置哈希,默认为开启(后面在介绍Redis的哈希算法时具体介绍)
activerehashing yes
30. 指定包含其它的配置文件,可以在同一主机上多个Redis实例之间使用同一份配置文件,而同时各个实例又拥有自己的特定配置文件
include /path/to/local.conf
Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。
string是redis最基本的类型,你可以理解成与Memcached一模一样的类型,一个key对应一个value。
string类型是二进制安全的。意思是redis的string可以包含任何数据。比如jpg图片或者序列化的对象 。
string类型是Redis最基本的数据类型,一个键最大能存储512MB。
-
1 redis 127.0.0.1:6379> SET name "redis.net.cn" 2 OK 3 redis 127.0.0.1:6379> GET name 4 "redis.net.cn"
在以上实例中我们使用了 Redis 的 SET 和 GET 命令。键为 name,对应的值为redis.net.cn。
**注意:**一个键最大能存储512MB。
Redis hash 是一个键值对集合。
Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
-
1 redis 127.0.0.1:6379> HMSET user:1 username redis.net.cn password redis.net.cn points 200 2 OK 3 redis 127.0.0.1:6379> HGETALL user:1 4 1)"username" 5 2)"redis.net.cn" 6 3)"password" 7 4)"redis.net.cn" 8 5)"points" 9 6)"200" 10 redis 127.0.0.1:6379>
以上实例中 hash 数据类型存储了包含用户脚本信息的用户对象。 实例中我们使用了 Redis HMSET, HEGTALL 命令,user:1 为键值。
每个 hash 可以存储 232 - 1 键值对(40多亿)。
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素导列表的头部(左边)或者尾部(右边)。
-
1 redis 127.0.0.1:6379> lpush redis.net.cn redis 2 (integer)1 3 redis 127.0.0.1:6379> lpush redis.net.cn mongodb 4 (integer)2 5 redis 127.0.0.1:6379> lpush redis.net.cn rabitmq 6 (integer)3 7 redis 127.0.0.1:6379> lrange redis.net.cn 010 8 1)"rabitmq" 9 2)"mongodb" 10 3)"redis" 11 redis 127.0.0.1:6379>
列表最多可存储 232 - 1 元素 (4294967295, 每个列表可存储40多亿)。
Redis的Set是string类型的无序集合。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。
添加一个string元素到,key对应的set集合中,成功返回1,如果元素以及在集合中返回0,key对应的set不存在返回错误。
sadd key member
1 redis 127.0.0.1:6379> sadd redis.net.cn redis
2 (integer)1
3 redis 127.0.0.1:6379> sadd redis.net.cn mongodb
4 (integer)1
5 redis 127.0.0.1:6379> sadd redis.net.cn rabitmq
6 (integer)1
7 redis 127.0.0.1:6379> sadd redis.net.cn rabitmq
8 (integer)0
9 redis 127.0.0.1:6379> smembers redis.net.cn
10
11 1)"rabitmq"
12 2)"mongodb"
13 3)"redis"
**注意:**以上实例中 rabitmq 添加了两次,但根据集合内元素的唯一性,第二次插入的元素将被忽略。
集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)。
Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
zset的成员是唯一的,但分数(score)却可以重复。
添加元素到集合,元素在集合中存在则更新对应score
1 zadd key score member
1 redis 127.0.0.1:6379> zadd redis.net.cn 0 redis
2 (integer)1
3 redis 127.0.0.1:6379> zadd redis.net.cn 0 mongodb
4 (integer)1
5 redis 127.0.0.1:6379> zadd redis.net.cn 0 rabitmq
6 (integer)1
7 redis 127.0.0.1:6379> zadd redis.net.cn 0 rabitmq
8 (integer)0
9 redis 127.0.0.1:6379> ZRANGEBYSCORE redis.net.cn 01000
10
11 1)"redis"
12 2)"mongodb"
13 3)"rabitmq"
Redis 的配置文件位于 Redis 安装目录下,文件名为 redis.conf。
你可以通过 CONFIG 命令查看或设置配置项。
Redis CONFIG 命令格式如下:
-
1 redis 127.0.0.1:6379> CONFIG GET CONFIG_SETTING_NAME
-
1 redis 127.0.0.1:6379> CONFIG GET loglevel 2 3 1)"loglevel" 4 2)"notice"
使用 ***** 号获取所有配置项:
-
1 redis 127.0.0.1:6379> CONFIG GET * 2 3 1)"dbfilename" 4 2)"dump.rdb" 5 3)"requirepass" 6 4)"" 7 5)"masterauth" 8 6)"" 9 7)"unixsocket" 10 8)"" 11 9)"logfile" 12 10)"" 13 11)"pidfile" 14 12)"/var/run/redis.pid" 15 13)"maxmemory" 16 14)"0" 17 15)"maxmemory-samples" 18 16)"3" 19 17)"timeout" 20 18)"0" 21 19)"tcp-keepalive" 22 20)"0" 23 21)"auto-aof-rewrite-percentage" 24 22)"100" 25 23)"auto-aof-rewrite-min-size" 26 24)"67108864" 27 25)"hash-max-ziplist-entries" 28 26)"512" 29 27)"hash-max-ziplist-value" 30 28)"64" 31 29)"list-max-ziplist-entries" 32 30)"512" 33 31)"list-max-ziplist-value" 34 32)"64" 35 33)"set-max-intset-entries" 36 34)"512" 37 35)"zset-max-ziplist-entries" 38 36)"128" 39 37)"zset-max-ziplist-value" 40 38)"64" 41 39)"hll-sparse-max-bytes" 42 40)"3000" 43 41)"lua-time-limit" 44 42)"5000" 45 43)"slowlog-log-slower-than" 46 44)"10000" 47 45)"latency-monitor-threshold" 48 46)"0" 49 47)"slowlog-max-len" 50 48)"128" 51 49)"port" 52 50)"6379" 53 51)"tcp-backlog" 54 52)"511" 55 53)"databases" 56 54)"16" 57 55)"repl-ping-slave-period" 58 56)"10" 59 57)"repl-timeout" 60 58)"60" 61 59)"repl-backlog-size" 62 60)"1048576" 63 61)"repl-backlog-ttl" 64 62)"3600" 65 63)"maxclients" 66 64)"4064" 67 65)"watchdog-period" 68 66)"0" 69 67)"slave-priority" 70 68)"100" 71 69)"min-slaves-to-write" 72 70)"0" 73 71)"min-slaves-max-lag" 74 72)"10" 75 73)"hz" 76 74)"10" 77 75)"no-appendfsync-on-rewrite" 78 76)"no" 79 77)"slave-serve-stale-data" 80 78)"yes" 81 79)"slave-read-only" 82 80)"yes" 83 81)"stop-writes-on-bgsave-error" 84 82)"yes" 85 83)"daemonize" 86 84)"no" 87 85)"rdbcompression" 88 86)"yes" 89 87)"rdbchecksum" 90 88)"yes" 91 89)"activerehashing" 92 90)"yes" 93 91)"repl-disable-tcp-nodelay" 94 92)"no" 95 93)"aof-rewrite-incremental-fsync" 96 94)"yes" 97 95)"appendonly" 98 96)"no" 99 97)"dir" 100 98)"/home/deepak/Downloads/redis-2.8.13/src" 101 99)"maxmemory-policy" 102 100)"volatile-lru" 103 101)"appendfsync" 104 102)"everysec" 105 103)"save" 106 104)"3600 1 300 100 60 10000" 107 105)"loglevel" 108 106)"notice" 109 107)"client-output-buffer-limit" 110 108)"normal 0 0 0 slave 268435456 67108864 60 pubsub 33554432 8388608 60" 111 109)"unixsocketperm" 112 110)"0" 113 111)"slaveof" 114 112)"" 115 113)"notify-keyspace-events" 116 114)"" 117 115)"bind" 118 116)""
你可以通过修改 redis.conf 文件或使用 CONFIG set 命令来修改配置。
CONFIG SET 命令基本语法:
-
1 redis 127.0.0.1:6379> CONFIG SET CONFIG_SETTING_NAME NEW_CONFIG_VALUE
-
1 redis 127.0.0.1:6379> CONFIG SET loglevel "notice" 2 OK 3 redis 127.0.0.1:6379> CONFIG GET loglevel 4 5 1)"loglevel" 6 2)"notice"
redis.conf 配置项说明如下:
\1. Redis默认不是以守护进程的方式运行,可以通过该配置项修改,使用yes启用守护进程
daemonize no
\2. 当Redis以守护进程方式运行时,Redis默认会把pid写入/var/run/redis.pid文件,可以通过pidfile指定
pidfile /var/run/redis.pid
\3. 指定Redis监听端口,默认端口为6379,作者在自己的一篇博文中解释了为什么选用6379作为默认端口,因为6379在手机按键上MERZ对应的号码,而MERZ取自意大利歌女Alessia Merz的名字
port 6379
\4. 绑定的主机地址
bind 127.0.0.1
5.当 客户端闲置多长时间后关闭连接,如果指定为0,表示关闭该功能
timeout 300
\6. 指定日志记录级别,Redis总共支持四个级别:debug、verbose、notice、warning,默认为verbose
loglevel verbose
\7. 日志记录方式,默认为标准输出,如果配置Redis为守护进程方式运行,而这里又配置为日志记录方式为标准输出,则日志将会发送给/dev/null
logfile stdout
\8. 设置数据库的数量,默认数据库为0,可以使用SELECT <dbid>命令在连接上指定数据库id
databases 16
\9. 指定在多长时间内,有多少次更新操作,就将数据同步到数据文件,可以多个条件配合
save
Redis默认配置文件中提供了三个条件:
save 900 1
save 300 10
save 60 10000
分别表示900秒(15分钟)内有1个更改,300秒(5分钟)内有10个更改以及60秒内有10000个更改。
\10. 指定存储至本地数据库时是否压缩数据,默认为yes,Redis采用LZF压缩,如果为了节省CPU时间,可以关闭该选项,但会导致数据库文件变的巨大
rdbcompression yes
\11. 指定本地数据库文件名,默认值为dump.rdb
dbfilename dump.rdb
\12. 指定本地数据库存放目录
dir ./
\13. 设置当本机为slav服务时,设置master服务的IP地址及端口,在Redis启动时,它会自动从master进行数据同步
slaveof
\14. 当master服务设置了密码保护时,slav服务连接master的密码
masterauth
\15. 设置Redis连接密码,如果配置了连接密码,客户端在连接Redis时需要通过AUTH <password>命令提供密码,默认关闭
requirepass foobared
\16. 设置同一时间最大客户端连接数,默认无限制,Redis可以同时打开的客户端连接数为Redis进程可以打开的最大文件描述符数,如果设置 maxclients 0,表示不作限制。当客户端连接数到达限制时,Redis会关闭新的连接并向客户端返回max number of clients reached错误信息
maxclients 128
\17. 指定Redis最大内存限制,Redis在启动时会把数据加载到内存中,达到最大内存后,Redis会先尝试清除已到期或即将到期的Key,当此方法处理 后,仍然到达最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作。Redis新的vm机制,会把Key存放内存,Value会存放在swap区
maxmemory
\18. 指定是否在每次更新操作后进行日志记录,Redis在默认情况下是异步的把数据写入磁盘,如果不开启,可能会在断电时导致一段时间内的数据丢失。因为 redis本身同步数据文件是按上面save条件来同步的,所以有的数据会在一段时间内只存在于内存中。默认为no
appendonly no
\19. 指定更新日志文件名,默认为appendonly.aof
appendfilename appendonly.aof
\20. 指定更新日志条件,共有3个可选值: no:表示等操作系统进行数据缓存同步到磁盘(快) always:表示每次更新操作后手动调用fsync()将数据写到磁盘(慢,安全) everysec:表示每秒同步一次(折衷,默认值)
appendfsync everysec
\21. 指定是否启用虚拟内存机制,默认值为no,简单的介绍一下,VM机制将数据分页存放,由Redis将访问量较少的页即冷数据swap到磁盘上,访问多的页面由磁盘自动换出到内存中(在后面的文章我会仔细分析Redis的VM机制)
vm-enabled no
\22. 虚拟内存文件路径,默认值为/tmp/redis.swap,不可多个Redis实例共享
vm-swap-file /tmp/redis.swap
\23. 将所有大于vm-max-memory的数据存入虚拟内存,无论vm-max-memory设置多小,所有索引数据都是内存存储的(Redis的索引数据 就是keys),也就是说,当vm-max-memory设置为0的时候,其实是所有value都存在于磁盘。默认值为0
vm-max-memory 0
\24. Redis swap文件分成了很多的page,一个对象可以保存在多个page上面,但一个page上不能被多个对象共享,vm-page-size是要根据存储的 数据大小来设定的,作者建议如果存储很多小对象,page大小最好设置为32或者64bytes;如果存储很大大对象,则可以使用更大的page,如果不 确定,就使用默认值
vm-page-size 32
\25. 设置swap文件中的page数量,由于页表(一种表示页面空闲或使用的bitmap)是在放在内存中的,,在磁盘上每8个pages将消耗1byte的内存。
vm-pages 134217728
\26. 设置访问swap文件的线程数,最好不要超过机器的核数,如果设置为0,那么所有对swap文件的操作都是串行的,可能会造成比较长时间的延迟。默认值为4
vm-max-threads 4
\27. 设置在向客户端应答时,是否把较小的包合并为一个包发送,默认为开启
glueoutputbuf yes
\28. 指定在超过一定的数量或者最大的元素超过某一临界值时,采用一种特殊的哈希算法
hash-max-zipmap-entries 64
hash-max-zipmap-value 512
\29. 指定是否激活重置哈希,默认为开启(后面在介绍Redis的哈希算法时具体介绍)
activerehashing yes
\30. 指定包含其它的配置文件,可以在同一主机上多个Redis实例之间使用同一份配置文件,而同时各个实例又拥有自己的特定配置文件
include /path/to/local.conf
Redis 命令用于在 redis 服务上执行操作。
要在 redis 服务上执行命令需要一个 redis 客户端。Redis 客户端在我们之前下载的的 redis 的安装包中。
Redis 客户端的基本语法为:
- $ redis-cli
以下实例讲解了如何启动 redis 客户端:
启动 redis 客户端,打开终端并输入命令 redis-cli。该命令会连接本地的 redis 服务。
-
1 $redis-cli 2 redis 127.0.0.1:6379> 3 redis 127.0.0.1:6379> PING 4 5 PONG
在以上实例中我们连接到本地的 redis 服务并执行 PING 命令,该命令用于检测 redis 服务是否启动。
如果需要在远程 redis 服务上执行命令,同样我们使用的也是 redis-cli 命令。
-
1 $ redis-cli -h host -p port -a password
以下实例演示了如何连接到主机为 127.0.0.1,端口为 6379 ,密码为 mypass 的 redis 服务上。
-
1 $redis-cli -h 127.0.0.1 -p 6379 -a "mypass" 2 redis 127.0.0.1:6379> 3 redis 127.0.0.1:6379> PING 4 5 PONG
Redis 键命令用于管理 redis 的键。
Redis 键命令的基本语法如下:
-
1 redis 127.0.0.1:6379> COMMAND KEY_NAME
-
1 redis 127.0.0.1:6379> SET w3ckey redis 2 OK 3 redis 127.0.0.1:6379> DEL w3ckey 4 (integer) 1
在以上实例中 DEL 是一个命令, w3ckey 是一个键。 如果键被删除成功,命令执行后输出 (integer) 1,否则将输出 (integer) 0
下表给出了与 Redis 键相关的基本命令:
| 序号 | 命令及描述 |
|---|---|
| 1 | DEL key 该命令用于在 key 存在是删除 key。 |
| 2 | DUMP key 序列化给定 key ,并返回被序列化的值。 |
| 3 | EXISTS key 检查给定 key 是否存在。 |
| 4 | EXPIRE key seconds 为给定 key 设置过期时间。 |
| 5 | EXPIREAT key timestamp EXPIREAT 的作用和 EXPIRE 类似,都用于为 key 设置过期时间。 不同在于 EXPIREAT 命令接受的时间参数是 UNIX 时间戳(unix timestamp)。 |
| 6 | PEXPIRE key milliseconds 设置 key 的过期时间亿以毫秒计。 |
| 7 | PEXPIREAT key milliseconds-timestamp 设置 key 过期时间的时间戳(unix timestamp) 以毫秒计 |
| 8 | KEYS pattern 查找所有符合给定模式( pattern)的 key 。 |
| 9 | MOVE key db 将当前数据库的 key 移动到给定的数据库 db 当中。 |
| 10 | PERSIST key 移除 key 的过期时间,key 将持久保持。 |
| 11 | PTTL key 以毫秒为单位返回 key 的剩余的过期时间。 |
| 12 | TTL key 以秒为单位,返回给定 key 的剩余生存时间(TTL, time to live)。 |
| 13 | RANDOMKEY 从当前数据库中随机返回一个 key 。 |
| 14 | RENAME key newkey 修改 key 的名称 |
| 15 | RENAMENX key newkey 仅当 newkey 不存在时,将 key 改名为 newkey 。 |
| 16 | TYPE key 返回 key 所储存的值的类型。 |
Redis 字符串数据类型的相关命令用于管理 redis 字符串值,基本语法如下:
1 redis 127.0.0.1:6379> COMMAND KEY_NAME
1 redis 127.0.0.1:6379> SET w3ckey redis OK redis 127.0.0.1:6379> GET w3ckey "redis"
在以上实例中我们使用了 SET 和 GET 命令,键为 w3ckey。
下表列出了常用的 redis 字符串命令:
| 序号 | 命令及描述 |
|---|---|
| 1 | SET key value 设置指定 key 的值 |
| 2 | GET key 获取指定 key 的值。 |
| 3 | GETRANGE key start end 返回 key 中字符串值的子字符 |
| 4 | GETSET key value 将给定 key 的值设为 value ,并返回 key 的旧值(old value)。 |
| 5 | GETBIT key offset 对 key 所储存的字符串值,获取指定偏移量上的位(bit)。 |
| 6 | [MGET key1 key2..] 获取所有(一个或多个)给定 key 的值。 |
| 7 | SETBIT key offset value 对 key 所储存的字符串值,设置或清除指定偏移量上的位(bit)。 |
| 8 | SETEX key seconds value 将值 value 关联到 key ,并将 key 的过期时间设为 seconds (以秒为单位)。 |
| 9 | SETNX key value 只有在 key 不存在时设置 key 的值。 |
| 10 | SETRANGE key offset value 用 value 参数覆写给定 key 所储存的字符串值,从偏移量 offset 开始。 |
| 11 | STRLEN key 返回 key 所储存的字符串值的长度。 |
| 12 | [MSET key value key value ...] 同时设置一个或多个 key-value 对。 |
| 13 | [MSETNX key value key value ...] 同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在。 |
| 14 | PSETEX key milliseconds value 这个命令和 SETEX 命令相似,但它以毫秒为单位设置 key 的生存时间,而不是像 SETEX 命令那样,以秒为单位。 |
| 15 | INCR key 将 key 中储存的数字值增一。 |
| 16 | INCRBY key increment 将 key 所储存的值加上给定的增量值(increment) 。 |
| 17 | INCRBYFLOAT key increment 将 key 所储存的值加上给定的浮点增量值(increment) 。 |
| 18 | DECR key 将 key 中储存的数字值减一。 |
| 19 | DECRBY key decrement key 所储存的值减去给定的减量值(decrement) 。 |
| 20 | APPEND key value 如果 key 已经存在并且是一个字符串, APPEND 命令将 value 追加到 key 原来的值的末尾。 |
Redis hash 是一个string类型的field和value的映射表,hash特别适合用于存储对象。
Redis 中每个 hash 可以存储 232 - 1 键值对(40多亿)。
-
1 redis 127.0.0.1:6379> HMSET w3ckey name "redis tutorial" description "redis basic commands for caching" likes 20 visitors 23000 2 OK 3 redis 127.0.0.1:6379> HGETALL w3ckey 4 5 1) "name" 6 2) "redis tutorial" 7 3) "description" 8 4) "redis basic commands for caching" 9 5) "likes" 10 6) "20" 11 7) "visitors" 12 8) "23000"
在以上实例中,我们设置了 redis 的一些描述信息(name, description, likes, visitors) 到哈希表的 w3ckey 中。
下表列出了 redis hash 基本的相关命令:
| 序号 | 命令及描述 |
|---|---|
| 1 | [HDEL key field2 field2] 删除一个或多个哈希表字段 |
| 2 | HEXISTS key field 查看哈希表 key 中,指定的字段是否存在。 |
| 3 | HGET key field 获取存储在哈希表中指定字段的值/td> |
| 4 | HGETALL key 获取在哈希表中指定 key 的所有字段和值 |
| 5 | HINCRBY key field increment 为哈希表 key 中的指定字段的整数值加上增量 increment 。 |
| 6 | HINCRBYFLOAT key field increment 为哈希表 key 中的指定字段的浮点数值加上增量 increment 。 |
| 7 | HKEYS key 获取所有哈希表中的字段 |
| 8 | HLEN key 获取哈希表中字段的数量 |
| 9 | [HMGET key field1 field2] 获取所有给定字段的值 |
| 10 | [HMSET key field1 value1 field2 value2 ] 同时将多个 field-value (域-值)对设置到哈希表 key 中。 |
| 11 | HSET key field value 将哈希表 key 中的字段 field 的值设为 value 。 |
| 12 | HSETNX key field value 只有在字段 field 不存在时,设置哈希表字段的值。 |
| 13 | HVALS key 获取哈希表中所有值 |
| 14 | HSCAN key cursor [MATCH pattern] [COUNT count] 迭代哈希表中的键值对。 |
Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素导列表的头部(左边)或者尾部(右边)
一个列表最多可以包含 232 - 1 个元素 (4294967295, 每个列表超过40亿个元素)。
1 redis 127.0.0.1:6379> LPUSH w3ckey redis
2 (integer) 1
3 redis 127.0.0.1:6379> LPUSH w3ckey mongodb
4 (integer) 2
5 redis 127.0.0.1:6379> LPUSH w3ckey mysql
6 (integer) 3
7 redis 127.0.0.1:6379> LRANGE w3ckey 0 10
8
9 1) "mysql"
10 2) "mongodb"
11 3) "redis"
在以上实例中我们使用了 LPUSH 将三个值插入了名为 w3ckey 的列表当中。
下表列出了列表相关的基本命令:
| 序号 | 命令及描述 |
|---|---|
| 1 | [BLPOP key1 key2 ] timeout 移出并获取列表的第一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。 |
| 2 | [BRPOP key1 key2 ] timeout 移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。 |
| 3 | BRPOPLPUSH source destination timeout 从列表中弹出一个值,将弹出的元素插入到另外一个列表中并返回它; 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。 |
| 4 | LINDEX key index 通过索引获取列表中的元素 |
| 5 | LINSERT key BEFORE|AFTER pivot value 在列表的元素前或者后插入元素 |
| 6 | LLEN key 获取列表长度 |
| 7 | LPOP key 移出并获取列表的第一个元素 |
| 8 | [LPUSH key value1 value2] 将一个或多个值插入到列表头部 |
| 9 | LPUSHX key value 将一个或多个值插入到已存在的列表头部 |
| 10 | LRANGE key start stop 获取列表指定范围内的元素 |
| 11 | LREM key count value 移除列表元素 |
| 12 | LSET key index value 通过索引设置列表元素的值 |
| 13 | LTRIM key start stop 对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除。 |
| 14 | RPOP key 移除并获取列表最后一个元素 |
| 15 | RPOPLPUSH source destination 移除列表的最后一个元素,并将该元素添加到另一个列表并返回 |
| 16 | [RPUSH key value1 value2] 在列表中添加一个或多个值 |
| 17 | RPUSHX key value 为已存在的列表添加值 |
Redis的Set是string类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。
Redis 中 集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。
集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)。
1 redis 127.0.0.1:6379> SADD w3ckey redis
2 (integer) 1
3 redis 127.0.0.1:6379> SADD w3ckey mongodb
4 (integer) 1
5 redis 127.0.0.1:6379> SADD w3ckey mysql
6 (integer) 1
7 redis 127.0.0.1:6379> SADD w3ckey mysql
8 (integer) 0
9 redis 127.0.0.1:6379> SMEMBERS w3ckey
10
11 1) "mysql"
12 2) "mongodb"
13 3) "redis"
在以上实例中我们通过 SADD 命令向名为 w3ckey 的集合插入的三个元素。
下表列出了 Redis 集合基本命令:
| 序号 | 命令及描述 |
|---|---|
| 1 | [SADD key member1 member2] 向集合添加一个或多个成员 |
| 2 | SCARD key 获取集合的成员数 |
| 3 | [SDIFF key1 key2] 返回给定所有集合的差集 |
| 4 | [SDIFFSTORE destination key1 key2] 返回给定所有集合的差集并存储在 destination 中 |
| 5 | [SINTER key1 key2] 返回给定所有集合的交集 |
| 6 | [SINTERSTORE destination key1 key2] 返回给定所有集合的交集并存储在 destination 中 |
| 7 | SISMEMBER key member 判断 member 元素是否是集合 key 的成员 |
| 8 | SMEMBERS key 返回集合中的所有成员 |
| 9 | SMOVE source destination member 将 member 元素从 source 集合移动到 destination 集合 |
| 10 | SPOP key 移除并返回集合中的一个随机元素 |
| 11 | [SRANDMEMBER key count] 返回集合中一个或多个随机数 |
| 12 | [SREM key member1 member2] 移除集合中一个或多个成员 |
| 13 | [SUNION key1 key2] 返回所有给定集合的并集 |
| 14 | [SUNIONSTORE destination key1 key2] 所有给定集合的并集存储在 destination 集合中 |
| 15 | [SSCAN key cursor MATCH pattern] [COUNT count] 迭代集合中的元素 |
Redis 有序集合和集合一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
有序集合的成员是唯一的,但分数(score)却可以重复。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。 集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)。
-
1 redis 127.0.0.1:6379> ZADD w3ckey 1 redis 2 (integer) 1 3 redis 127.0.0.1:6379> ZADD w3ckey 2 mongodb 4 (integer) 1 5 redis 127.0.0.1:6379> ZADD w3ckey 3 mysql 6 (integer) 1 7 redis 127.0.0.1:6379> ZADD w3ckey 3 mysql 8 (integer) 0 9 redis 127.0.0.1:6379> ZADD w3ckey 4 mysql 10 (integer) 0 11 redis 127.0.0.1:6379> ZRANGE w3ckey 0 10 WITHSCORES 12 13 1) "redis" 14 2) "1" 15 3) "mongodb" 16 4) "2" 17 5) "mysql" 18 6) "4"
在以上实例中我们通过命令 ZADD 向 redis 的有序集合中添加了三个值并关联上分数。
下表列出了 redis 有序集合的基本命令:
| 序号 | 命令及描述 |
|---|---|
| 1 | [ZADD key score1 member1 score2 member2] 向有序集合添加一个或多个成员,或者更新已存在成员的分数 |
| 2 | ZCARD key 获取有序集合的成员数 |
| 3 | ZCOUNT key min max 计算在有序集合中指定区间分数的成员数 |
| 4 | ZINCRBY key increment member 有序集合中对指定成员的分数加上增量 increment |
| 5 | [ZINTERSTORE destination numkeys key key ...] 计算给定的一个或多个有序集的交集并将结果集存储在新的有序集合 key 中 |
| 6 | ZLEXCOUNT key min max 在有序集合中计算指定字典区间内成员数量 |
| 7 | [ZRANGE key start stop WITHSCORES] 通过索引区间返回有序集合成指定区间内的成员 |
| 8 | [ZRANGEBYLEX key min max LIMIT offset count] 通过字典区间返回有序集合的成员 |
| 9 | [ZRANGEBYSCORE key min max WITHSCORES] [LIMIT] 通过分数返回有序集合指定区间内的成员 |
| 10 | ZRANK key member 返回有序集合中指定成员的索引 |
| 11 | [ZREM key member member ...] 移除有序集合中的一个或多个成员 |
| 12 | ZREMRANGEBYLEX key min max 移除有序集合中给定的字典区间的所有成员 |
| 13 | ZREMRANGEBYRANK key start stop 移除有序集合中给定的排名区间的所有成员 |
| 14 | ZREMRANGEBYSCORE key min max 移除有序集合中给定的分数区间的所有成员 |
| 15 | [ZREVRANGE key start stop WITHSCORES] 返回有序集中指定区间内的成员,通过索引,分数从高到底 |
| 16 | [ZREVRANGEBYSCORE key max min WITHSCORES] 返回有序集中指定分数区间内的成员,分数从高到低排序 |
| 17 | ZREVRANK key member 返回有序集合中指定成员的排名,有序集成员按分数值递减(从大到小)排序 |
| 18 | ZSCORE key member 返回有序集中,成员的分数值 |
| 19 | [ZUNIONSTORE destination numkeys key key ...] 计算给定的一个或多个有序集的并集,并存储在新的 key 中 |
| 20 | [ZSCAN key cursor MATCH pattern] [COUNT count] 迭代有序集合中的元素(包括元素成员和元素分值) |
Redis 在 2.8.9 版本添加了 HyperLogLog 结构。
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
以下实例演示了 HyperLogLog 的工作过程:
-
1 redis 127.0.0.1:6379> PFADD w3ckey "redis" 2 3 1) (integer) 1 4 5 redis 127.0.0.1:6379> PFADD w3ckey "mongodb" 6 7 1) (integer) 1 8 9 redis 127.0.0.1:6379> PFADD w3ckey "mysql" 10 11 1) (integer) 1 12 13 redis 127.0.0.1:6379> PFCOUNT w3ckey 14 15 (integer) 3
下表列出了 redis HyperLogLog 的基本命令:
| 序号 | 命令及描述 |
|---|---|
| 1 | [PFADD key element element ...] 添加指定元素到 HyperLogLog 中。 |
| 2 | [PFCOUNT key key ...] 返回给定 HyperLogLog 的基数估算值。 |
| 3 | [PFMERGE destkey sourcekey sourcekey ...] 将多个 HyperLogLog 合并为一个 HyperLogLog |
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
Redis 客户端可以订阅任意数量的频道。
下图展示了频道 channel1 , 以及订阅这个频道的三个客户端 —— client2 、 client5 和 client1 之间的关系:

当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:

以下实例演示了发布订阅是如何工作的。在我们实例中我们创建了订阅频道名为 redisChat:
1 redis 127.0.0.1:6379> SUBSCRIBE redisChat
2
3 Reading messages... (press Ctrl-C to quit)
4 1) "subscribe"
5 2) "redisChat"
6 3) (integer) 1
现在,我们先重新开启个 redis 客户端,然后在同一个频道 redisChat 发布两次消息,订阅者就能接收到消息。
1 redis 127.0.0.1:6379> PUBLISH redisChat "Redis is a great caching technique"
2
3 (integer) 1
4
5 redis 127.0.0.1:6379> PUBLISH redisChat "Learn redis by w3cschool.cc"
6
7 (integer) 1
8
9 # 订阅者的客户端会显示如下消息
10 1) "message"
11 2) "redisChat"
12 3) "Redis is a great caching technique"
13 1) "message"
14 2) "redisChat"
15 3) "Learn redis by w3cschool.cc"
下表列出了 redis 发布订阅常用命令:
| 序号 | 命令及描述 |
|---|---|
| 1 | [PSUBSCRIBE pattern pattern ...] 订阅一个或多个符合给定模式的频道。 |
| 2 | [PUBSUB subcommand argument [argument ...]] 查看订阅与发布系统状态。 |
| 3 | PUBLISH channel message 将信息发送到指定的频道。 |
| 4 | [PUNSUBSCRIBE pattern [pattern ...]] 退订所有给定模式的频道。 |
| 5 | [SUBSCRIBE channel channel ...] 订阅给定的一个或多个频道的信息。 |
| 6 | [UNSUBSCRIBE channel [channel ...]] 指退订给定的频道。 |
Redis 事务可以一次执行多个命令, 并且带有以下两个重要的保证:
- 事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
- 事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。
一个事务从开始到执行会经历以下三个阶段:
- 开始事务。
- 命令入队。
- 执行事务。
以下是一个事务的例子, 它先以 MULTI 开始一个事务, 然后将多个命令入队到事务中, 最后由 EXEC 命令触发事务, 一并执行事务中的所有命令:
-
1 redis 127.0.0.1:6379> MULTI 2 OK 3 4 redis 127.0.0.1:6379> SET book-name "Mastering C++ in 21 days" 5 QUEUED 6 7 redis 127.0.0.1:6379> GET book-name 8 QUEUED 9 10 redis 127.0.0.1:6379> SADD tag "C++" "Programming" "Mastering Series" 11 QUEUED 12 13 redis 127.0.0.1:6379> SMEMBERS tag 14 QUEUED 15 16 redis 127.0.0.1:6379> EXEC 17 1) OK 18 2) "Mastering C++ in 21 days" 19 3) (integer) 3 20 4) 1) "Mastering Series" 21 2) "C++" 22 3) "Programming"
下表列出了 redis 事务的相关命令:
| 序号 | 命令及描述 |
|---|---|
| 1 | DISCARD 取消事务,放弃执行事务块内的所有命令。 |
| 2 | EXEC 执行所有事务块内的命令。 |
| 3 | MULTI 标记一个事务块的开始。 |
| 4 | UNWATCH 取消 WATCH 命令对所有 key 的监视。 |
| 5 | [WATCH key key ...] 监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断。 |
一、python连接redis
在python中,要操作redis,目前主要是通过一个python-redis模块来实现
1、在python中安装redis模块
1 pip3 install redis
2、在python中使用redis
跟其他模块一样,在安装好redis模块后,要使用redis模块就要先导入。
python连接redis数据库:
1 #!/usr/bin/env python
2 # -*- coding:utf8 -*-
3
4 import redis
5
6 '''
7 这种连接是连接一次就断了,耗资源.端口默认6379,就不用写
8 r = redis.Redis(host='127.0.0.1',port=6379,password='tianxuroot')
9 r.set('name','root')
10
11 print(r.get('name').decode('utf8'))
12 '''
13 '''
14 连接池:
15 当程序创建数据源实例时,系统会一次性创建多个数据库连接,并把这些数据库连接保存在连接池中,当程序需要进行数据库访问时,
16 无需重新新建数据库连接,而是从连接池中取出一个空闲的数据库连接
17 '''
18 pool = redis.ConnectionPool(host='127.0.0.1',password='helloworld') #实现一个连接池
19
20 r = redis.Redis(connection_pool=pool)
21 r.set('foo','bar')
22 print(r.get('foo').decode('utf8'))
二、Redis API使用
redis-py 的API的使用可以分类为:
- 连接方式
- 连接池
- 操作
- String 操作
- Hash 操作
- List 操作
- Set 操作
- Sort Set 操作
- 管道
- 发布订阅
前面通过一个连接实例来简述了python用过redis模块连接redis数据库的连接方式和连接池。
接下来主要看如何通过python来操作redis数据库:
1. String操作
redis中的String在在内存中按照一个name对应一个value来存储。如图:

set(name, value, ex=None, px=None, nx=False, xx=False)
在Redis中设置值,默认,不存在则创建,存在则修改
参数:
ex,过期时间(秒)
px,过期时间(毫秒)
nx,如果设置为True,则只有name不存在时,当前set操作才执行
xx,如果设置为True,则只有name存在时,岗前set操作才执行
setnx(name, value)
#设置值,只有name不存在时,执行设置操作(添加)
setex(name, value, time)
# 设置值
# 参数:
# time,过期时间(数字秒 或 timedelta对象)
psetex(name, time_ms, value)
# 设置值
# 参数:
# time_ms,过期时间(数字毫秒 或 timedelta对象)
mset(*args, **kwargs)
批量设置值
如:
mset(k1='v1', k2='v2')
或
mget({'k1': 'v1', 'k2': 'v2'})
get(name)
获取值
mget(keys, *args)
批量获取
如:
mget('name', 'root')
或
r.mget(['name', 'root'])
getset(name, value)
设置新值并获取原来的值
getrange(key, start, end)
# 获取子序列(根据字节获取,非字符)
# 参数:
#name,Redis 的 name
# start,起始位置(字节)
# end,结束位置(字节)
# 如: "你好" ,0-3表示 "你" (utf8中一个中文字符占三个字节)
setrange(name, offset, value)
# 修改字符串内容,从指定字符串索引开始向后替换(新值太长时,则向后添加)
# 参数:
# offset,字符串的索引,字节(一个汉字三个字节)
# value,要设置的值
setbit(name, offset, value)
# 对name对应值的二进制表示的位进行操作
# 参数:
# name,redis的name
# offset,位的索引(将值变换成二进制后再进行索引)
# value,值只能是 1 或 0
# 注:如果在Redis中有一个对应: n1 = "foo",
那么字符串foo的二进制表示为:01100110 01101111 01101111
所以,如果执行 setbit('n1', 7, 1),则就会将第7位设置为1,
那么最终二进制则变成 01100111 01101111 01101111,即:"goo"
# 扩展,转换二进制表示:
# source = "你好啊"
source = "foo"
for i in source:
num = ord(i)
print bin(num).replace('b','')
特别的,如果source是汉字 "你好啊"怎么办?
答:对于utf-8,每一个汉字占 3 个字节,那么 "人生苦短" 则有 12个字节
对于汉字,for循环时候会按照 字节 迭代,那么在迭代时,将每一个字节转换 十进制数,然后再将十进制数转换成二进制
11100110 10101101 10100110 11100110 10110010 10011011 11101001 10111101 10010000
-------------------------- ----------------------------- -----------------------------
你 好 啊
*用途举例,用最省空间的方式,存储在线用户数及分别是哪些用户在线
getbit(name, offset)
# 获取name对应的值的二进制表示中的某位的值 (0或1)
bitcount(key, start=None, end=None)
# 获取name对应的值的二进制表示中 1 的个数
# 参数:
# key,Redis的name
# start,位起始位置
# end,位结束位置
strlen(name)
# 返回name对应值的字节长度(一个汉字3个字节)
incr(self, name, amount=1)
# 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。
# 参数:
# name,Redis的name
# amount,自增数(必须是整数)
# 注:同incrby
incrbyfloat(self, name, amount=1.0)
# 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。
# 参数:
# name,Redis的name
# amount,自增数(浮点型)
decr(self, name, amount=1)
# 自减 name对应的值,当name不存在时,则创建name=amount,否则,则自减。
# 参数:
# name,Redis的name
# amount,自减数(整数)
append(key, value)
# 在redis name对应的值后面追加内容
# 参数:
key, redis的name
value, 要追加的字符串
2. Hash****操作
hash表现形式上有些像pyhton中的dict,可以存储一组关联性较强的数据 , redis中Hash在内存中的存储格式如下图:

hset(name, key, value)
# name对应的hash中设置一个键值对(不存在,则创建;否则,修改), 注意: 在python中,键值对是dict, 这里的name必须是dict格式。eg:xxx[]、 xxx[k]...
# 参数:
# name,redis的name
#key,name对应的hash中的key
# value,name对应的hash中的value
# 注:
# hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)
hmset(name, mapping)
# 在name对应的hash中批量设置键值对
# 参数:
# name,redis的name
# mapping,字典,如:{'k1':'v1', 'k2': 'v2'}
# 如:
# r.hmset('xx', {'k1':'v1', 'k2': 'v2'})
hget(name,key)
# 在name对应的hash中获取根据key获取value
hmget(name, keys, *args)
# 在name对应的hash中获取多个key的值
# 参数:
# name,reids对应的name
# keys,要获取key集合,如:['k1', 'k2', 'k3']
# *args,要获取的key,如:k1,k2,k3
# 如:
# r.mget('xx', ['k1', 'k2'])
# 或
# print r.hmget('xx', 'k1', 'k2')
hgetall(name)
#获取name对应hash的所有键值
hlen(name)
# 获取name对应的hash中键值对的个数
hkeys(name)
# 获取name对应的hash中所有的key的值
hvals(name)
# 获取name对应的hash中所有的value的值
hexists(name, key)
# 检查name对应的hash是否存在当前传入的key
hdel(name,*keys)
# 将name对应的hash中指定key的键值对删除
hincrby(name, key, amount=1)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
# 参数:
# name,redis中的name
# key, hash对应的key
# amount,自增数(整数)
hincrbyfloat(name, key, amount=1.0)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
# 参数:
# name,redis中的name
# key, hash对应的key
# amount,自增数(浮点数)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
hscan(name, cursor=0, match=None, count=None)
Start a full hash scan with:
HSCAN myhash 0
Start a hash scan with fields matching a pattern with:
HSCAN myhash 0 MATCH order_*
Start a hash scan with fields matching a pattern and forcing the scan command to do more scanning with:
HSCAN myhash 0 MATCH order_* COUNT 1000
# 增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而放置内存被撑爆
# 参数:
# name,redis的name
# cursor,游标(基于游标分批取获取数据)
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
# 如:
# 第一次:cursor1, data1 = r.hscan('xx', cursor=0, match=None, count=None)
# 第二次:cursor2, data1 = r.hscan('xx', cursor=cursor1, match=None, count=None)
# ...
# 直到返回值cursor的值为0时,表示数据已经通过分片获取完毕
hscan_iter(name, match=None, count=None)
# 利用yield封装hscan创建生成器,实现分批去redis中获取数据
# 参数:
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
# 如:
# for item in r.hscan_iter('xx'):
# print item
3. list
List操作,redis中的List在在内存中按照一个name对应一个List来存储。如图:

lpush(name,values)
# 在name对应的list中添加元素,每个新的元素都添加到列表的最左边
# 如:
# r.lpush('oo', 11,22,33)
# 保存顺序为: 33,22,11
# 扩展:
# rpush(name, values) 表示从右向左操作
lpushx(name,value)
# 在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边
# 更多:
# rpushx(name, value) 表示从右向左操作
llen(name)
# name对应的list元素的个数
linsert(name, where, refvalue, value))
# 在name对应的列表的某一个值前或后插入一个新值
# 参数:
# name,redis的name
# where,BEFORE或AFTER
# refvalue,标杆值,即:在它前后插入数据
# value,要插入的数据
r.lset(name, index, value)
# 对name对应的list中的某一个索引位置重新赋值
# 参数:
# name,redis的name
# index,list的索引位置
# value,要设置的值
r.lrem(name, value, num)
# 在name对应的list中删除指定的值
# 参数:
# name,redis的name
# value,要删除的值
# num,num=0,删除列表中所有的指定值;
# num=2,从前到后,删除2个;
# num=-2,从后向前,删除2个
lpop(name)
# 在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素
# 更多:
# rpop(name) 表示从右向左操作
lindex(name, index)
#在name对应的列表中根据索引获取列表元素
lrange(name, start, end)
# 在name对应的列表分片获取数据
# 参数:
# name,redis的name
# start,索引的起始位置
# end,索引结束位置
ltrim(name, start, end)
# 在name对应的列表中移除没有在start-end索引之间的值
# 参数:
# name,redis的name
# start,索引的起始位置
# end,索引结束位置
rpoplpush(src, dst)
# 从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边
# 参数:
# src,要取数据的列表的name
# dst,要添加数据的列表的name
blpop(keys, timeout)
# 将多个列表排列,按照从左到右去pop对应列表的元素
# 参数:
# keys,redis的name的集合
# timeout,超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞
# 更多:
# r.brpop(keys, timeout),从右向左获取数据
brpoplpush(src, dst, timeout=0)
# 从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧
# 参数:
# src,取出并要移除元素的列表对应的name
# dst,要插入元素的列表对应的name
# timeout,当src对应的列表中没有数据时,阻塞等待其有数据的超时时间(秒),0 表示永远阻塞
4.set集合操作
Set操作,Set集合就是不允许重复的列表。这里包括了一般的集合和有序集合。
sadd(name,values)
# name对应的集合中添加元素
scard(name)
#获取name对应的集合中元素个数
sdiff(keys, *args)
#在第一个name对应的集合中且不在其他name对应的集合的元素集合
sdiffstore(dest, keys, *args)
# 获取第一个name对应的集合中且不在其他name对应的集合,再将其新加入到dest对应的集合中
sinter(keys, *args)
# 获取多一个name对应集合的并集
sinterstore(dest, keys, *args)
# 获取多一个name对应集合的并集,再讲其加入到dest对应的集合中
sismember(name, value)
# 检查value是否是name对应的集合的成员
smembers(name)
# 获取name对应的集合的所有成员
smove(src, dst, value)
# 将某个成员从一个集合中移动到另外一个集合
spop(name)
# 从集合的右侧(尾部)移除一个成员,并将其返回
srandmember(name, numbers)
# 从name对应的集合中随机获取 numbers 个元素
srem(name, values)
# 在name对应的集合中删除某些值
sunion(keys, *args)
# 获取多一个name对应的集合的并集
sunionstore(dest,keys, *args)
# 获取多一个name对应的集合的并集,并将结果保存到dest对应的集合中
sscan(name, cursor=0, match=None, count=None)
sscan_iter(name, match=None, count=None)
# 同字符串的操作,用于增量迭代分批获取元素,避免内存消耗太大
有序集合,在集合的基础上,为每元素排序;元素的排序需要根据另外一个值来进行比较,所以,对于有序集合,每一个元素有两个值,即:值和分数,分数专门用来做排序。
zadd(name, *args, **kwargs)
# 在name对应的有序集合中添加元素
# 如:
# zadd('zz', 'n1', 1, 'n2', 2)
# 或
# zadd('zz', n1=11, n2=22)
zcard(name)
# 获取name对应的有序集合元素的数量
zcount(name, min, max)
# 获取name对应的有序集合中分数 在 [min,max] 之间的个数
zincrby(name, value, amount)
# 自增name对应的有序集合的 name 对应的分数
r.zrange( name, start, end, desc=False, withscores=False, score_cast_func=float)
# 按照索引范围获取name对应的有序集合的元素
# 参数:
# name,redis的name
# start,有序集合索引起始位置(非分数)
# end,有序集合索引结束位置(非分数)
# desc,排序规则,默认按照分数从小到大排序
# withscores,是否获取元素的分数,默认只获取元素的值
# score_cast_func,对分数进行数据转换的函数
# 更多:
# 从大到小排序
# zrevrange(name, start, end, withscores=False, score_cast_func=float)
# 按照分数范围获取name对应的有序集合的元素
# zrangebyscore(name, min, max, start=None, num=None, withscores=False, score_cast_func=float)
# 从大到小排序
# zrevrangebyscore(name, max, min, start=None, num=None, withscores=False, score_cast_func=float)
zrank(name, value)
# 获取某个值在 name对应的有序集合中的排行(从 0 开始)
# 更多:
# zrevrank(name, value),从大到小排序
zrem(name, values)
# 删除name对应的有序集合中值是values的成员
# 如:zrem('zz', ['s1', 's2'])
zremrangebyrank(name, min, max)
# 根据排行范围删除
zremrangebyscore(name, min, max)
# 根据分数范围删除
zscore(name, value)
# 获取name对应有序集合中 value 对应的分数
zinterstore(dest, keys, aggregate=None)
# 获取两个有序集合的交集,如果遇到相同值不同分数,则按照aggregate进行操作
# aggregate的值为: SUM MIN MAX
zunionstore(dest, keys, aggregate=None)
# 获取两个有序集合的并集,如果遇到相同值不同分数,则按照aggregate进行操作
# aggregate的值为: SUM MIN MAX
zscan(name, cursor=0, match=None, count=None, score_cast_func=float)
zscan_iter(name, match=None, count=None,score_cast_func=float)
# 同字符串相似,相较于字符串新增score_cast_func,用来对分数进行操作
5**、其他常用操作**
delete(*names)
# 根据删除redis中的任意数据类型
exists(name)
# 检测redis的name是否存在
keys(pattern='*')
# 根据模型获取redis的name
# 更多:
# KEYS * 匹配数据库中所有 key 。
# KEYS h?llo 匹配 hello , hallo 和 hxllo 等。
# KEYS h*llo 匹配 hllo 和 heeeeello 等。
# KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo
expire(name ,time)
# 为某个redis的某个name设置超时时间
rename(src, dst)
# 对redis中src的name重命名为dst
move(name, db))
# 将redis的某个值移动到指定的db下
randomkey()
# 随机获取一个redis的name(不删除)
type(name)
# 获取name对应值的类型
scan(cursor=0, match=None, count=None)
scan_iter(match=None, count=None)
# 同字符串操作,用于增量迭代获取key
三、管道
redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下一次pipline 是原子性操作。
1 #!/usr/bin/env python
2 # -*- coding:utf-8 -*-
3
4 import redis
5
6 pool = redis.ConnectionPool(host='192.168.22.132', port=6379)
7 r = redis.Redis(connection_pool=pool)
8
9 # pipe = r.pipeline(transaction=False)
10 pipe = r.pipeline(transaction=True)
11
12 pipe.set('name', 'root')
13 pipe.set('role', 'root')
14
15 pipe.execute()
四、发布与订阅

发布者:服务器
订阅者:Dashboad和数据处理
redis_helper:
1 #!/usr/bin/env python
2 # -*- coding:utf8 -*-
3
4 import redis
5
6 class RedisHelper(object):
7
8 def __init__(self):
9 self.__conn = redis.Redis(host='localhost') #连接本机,ip不用写
10 self.chan_sub = 'fm104.5'
11 self.chan_pub = 'fm86' #这个频道没用到啊...
12
13 def public(self,msg):
14 self.__conn.publish(self.chan_sub,msg)
15 return True
16
17 def subscribe(self):
18 pub = self.__conn.pubsub()
19 pub.subscribe(self.chan_sub) #订阅的频道
20 pub.parse_response() #准备好监听(再调用一次就是开始监听)
21 return pub
redis订阅:
1 #!/usr/bin/env python
2 # -*- coding:utf8 -*-
3
4 from redis_helper import RedisHelper
5
6 obj = RedisHelper()
7 redis_sub = obj.subscribe()
8
9 while True:
10 msg = redis_sub.parse_response()
11 print(msg) #[b'message', b'fm104.5', b'who are you?']
12 # print(msg[2].decode('utf8'))
redis发布:
1 #!/usr/bin/env python
2 # -*- coding:utf8 -*-
3
4 '''
5 发布与订阅是不同于存值取值,存值取值不需要同步,发布与订阅是需要同步的
6 '''
7 '''
8 #这样是可以的,为了配套,使用下面的
9 import redis
10
11 obj = redis.Redis(password='helloworld')
12 obj.publish('fm104.5','hello')
13
14 '''
15
16 from redis_helper import RedisHelper
17
18 obj = RedisHelper()
19 obj.public('hello')
对象-关系映射(Object/Relation Mapping,简称ORM),是随着面向对象的软件开发方法发展而产生的。面向对象的开发方法是当今企业级应用开发环境中的主流开发方法,关系数据库是企业级应用环境中永久存放数据的主流数据存储系统。对象和关系数据是业务实体的两种表现形式,业务实体在内存中表现为对象,在数据库中表现为关系数据。内存中的对象之间存在关联和继承关系,而在数据库中,关系数据无法直接表达多对多关联和继承关系。因此,对象-关系映射(ORM)系统一般以中间件的形式存在,主要实现程序对象到关系数据库数据的映射。
- 简单性:以最基本的形式建模数据。
- 传达性:数据库结构被任何人都能理解的语言文档化。
- 精确性:基于数据模型创建正确标准化了的结构。
面向对象是从软件工程基本原则(如耦合、聚合、封装)的基础上发展起来的,而关系数据库则是从数学理论发展而来的,两套理论存在显著的区别。为了解决这个不匹配的现象,对象关系映射技术应运而生。O/R中字母O起源于"对象"(Object),而R则来自于"关系"(Relational)。几乎所有的程序里面,都存在对象和关系数据库。在业务逻辑层和用户界面层中,我们是面向对象的。当对象信息发生变化的时候,我们需要把对象的信息保存在关系数据库中。
当开发一个应用程序的时候(不使用O/R Mapping),可能会写不少数据访问层的代码,用来从数据库保存,删除,读取对象信息,等等。在DAL中写了很多的方法来读取对象数据,改变状态对象等等任务。而这些代码写起来总是重复的。
如果开你最近的程序,看看DAL代码,肯定会看到很多近似的通用的模式。我们以保存对象的方法为例,传入一个对象,为SqlCommand对象添加SqlParameter,把所有属性和对象对应,设置SqlCommand的CommandText属性为存储过程,然后运行SqlCommand。对于每个对象都要重复的写这些代码。 除此之外,还有更好的办法吗?有,引入一个O/R Mapping。实质上,一个O/R Mapping会为你生成DAL。与其自己写DAL代码,不如用O/R Mapping。用O/R Mapping保存,删除,读取对象,O/R Mapping负责生成SQL,你只需要关心对象就好。对象关系映射成功运用在不同的面向对象持久层产品中,
- 一个对持久类对象进行CRUD操作的API;
- 一个语言或API用来规定与类和类属性相关的查询;
- 一个规定mapping metadata的工具;
- 一种技术可以让ORM的实现同事务对象一起进行dirty checking, lazy association fetching以及其他的优化操作。
•ORM:及Object-Relational Mapping,把关系数据库的表结构映射到对象上
•我们先来可能一个例子:
•如果我们从数据库查出来几条数据,需要你在python中表示出来,如果你没有接触过ORM技术,你或许会使用下面的形式来存储这个数据:
[
(1, ‘feng’),
(2, ‘shang’),
(3, ‘huo’),
]
如果你想知道表结构是什么样的,是不是就费劲了,如果你想快速的取出其中的元素,就需要听听ORM的思想了。
数据库中每次查出来的数据都用一个类表示,这个类的属性和数据库中表的字段一一对应。多条数据,就是一个list,每一行数据都是一个类来表示,如下所示:
class User(object):
def __init__(self, id, name):
self.id = id
self.name = name
[
User(1, “feng”),
User(2, “shang”),
User(3, “huo”),
]
当我们需要获得id,或者name的时候,只需要通过循环获取到对象,直接通过user1.id或者user1.name就可以获取到id和name的属性。并且使得数据的存取非常的规范,这样ORM架构应用而生。
Python中最有名的ORM架构就是SQLAlchemy,我们主要就是来学习SQLAlchemy的使用
pip install SQLAlchemy
yum install mysql-server mysql
service mysqld restart
sysctmctl restart mysql.service
create database sqlalchemy;
GRANT ALL PRIVILEGES ON *.* TO 'fxq'@'%' IDENTIFIED BY ‘123456’;
from sqlalchemy import create_engine
engine = create_engine('mysql://fxq:123456@192.168.100.101/sqlalchemy', echo=True)
echo参数为True时,会显示每条执行的SQL语句,可以关闭, create_engine()返回一个Engine的实例,并且它表示通过数据库语法处理细节的核心接口,在这种情况下,数据库语法将会被解释成python的类方法。 解释说明: mysql://fxq:123456@192.168.100.101/sqlalchemy mysql: 指定是哪种数据库连接 第一个fxq: 用户名 123456: fxq用户对应的密码 192.168.100.101: 数据库的ip sqlalchemy: 数据库需要连接库的名字
- 主要是通过sql语句来创建表格:
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
sql = '''create table student(
id int not null primary key,
name varchar(50),
age int,
address varchar(100));
'''
engine = create_engine('mysql+pymysql://fxq:123456@192.168.100.101/sqlalchemy')
conn = engine.connect()
conn.execute(sql)
engine.connect() #表示获取到数据库连接。类似我们在MySQLdb中游标course的作用。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/5/10 21:58
# @Author : Feng Xiaoqing
# @File : demo2.py
# @Function: -----------
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('mysql+pymysql://fxq:123456@192.168.100.101/sqlalchemy')
metadata = MetaData(engine)
student = Table('student', metadata,
Column('id', Integer, primary_key=True),
Column('name', String(50), ),
Column('age', Integer),
Column('address', String(10)),
)
metadata.create_all(engine)
以上方式都可以创建数据库表 MetaData类主要用于保存表结构,连接字符串等数据,是一个多表共享的对象 metadata = MetaData(engine) #绑定一个数据源的metadata metadata.create_all(engine) #是来创建表,这个操作是安全的操作,会先判断表是否存在。
构造函数:
Table.__init__(self, name, metadata,*args, **kwargs)
name 表名 metadata 共享的元数据 *args Column 是列定义,详见下一节 下面是可变参数 **kwargs 定义 schema 此表的结构名称,默认None autoload 自动从现有表中读入表结构,默认False autoload_with 从其他engine读取结构,默认None
include_columns 如果autoload设置为True,则此项数组中的列明将被引用,没有写的列明将被忽略,None表示所有都列明都引用,默认None mustexist 如果为True,表示这个表必须在其他的python应用中定义,必须是metadata的一部分,默认False useexisting 如果为True,表示这个表必须被其他应用定义过,将忽略结构定义,默认False owner 表所有者,用于Orcal,默认None quote 设置为True,如果表明是SQL关键字,将强制转义,默认False quote_schema 设置为True,如果列明是SQL关键字,将强制转义,默认False mysql_engine mysql专用,可以设置'InnoDB'或'MyISAM'
构造函数:
Column.__init__(self, name, type_, *args, **kwargs)
1、name 列名 2、type_ 类型,更多类型 sqlalchemy.types 3、*args Constraint(约束), ForeignKey(外键), ColumnDefault(默认), Sequenceobjects(序列)定义 4、key 列名的别名,默认None 下面是可变参数 **kwargs 5、primary_key 如果为True,则是主键 6、nullable 是否可为Null,默认是True 7、default 默认值,默认是None 8、index 是否是索引,默认是True 9、unique 是否唯一键,默认是False 10、onupdate 指定一个更新时候的值,这个操作是定义在SQLAlchemy中,不是在数据库里的,当更新一条数据时设置,大部分用于updateTime这类字段 11、autoincrement 设置为整型自动增长,只有没有默认值,并且是Integer类型,默认是True 12、quote 如果列明是关键字,则强制转义,默认False
说到数据库,就离不开Session。Session的主要目的是建立与数据库的会话,它维护你加载和关联的所有数据库对象。它是数据库查询(Query)的一个入口。 在Sqlalchemy中,数据库的查询操作是通过Query对象来实现的。而Session提供了创建Query对象的接口。 Query对象返回的结果是一组同一映射(Identity Map)对象组成的集合。事实上,集合中的一个对象,对应于数据库表中的一行(即一条记录)。所谓同一映射,是指每个对象有一个唯一的ID。如果两个对象(的引用)ID相同,则认为它们对应的是相同的对象。 要完成数据库查询,就需要建立与数据库的连接。这就需要用到Engine对象。一个Engine可能是关联一个Session对象,也可能关联一个数据库表。 当然Session最重要的功能还是实现原子操作。 ORM通过session与数据库建立连接进行通信,如下所示:
from sqlalchemy.orm import sessionmaker
DBSession = sessionmaker(bind=engine)
session = DBSession()
通过sessionmake方法创建一个Session工厂,然后在调用工厂的方法来实例化一个Session对象。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/5/10 20:58
# @Author : Feng Xiaoqing
# @File : demo1.py
# @Function: -----------
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
engine = create_engine('mysql+pymysql://fxq:123456@192.168.100.101/sqlalchemy')
DBsession = sessionmaker(bind=engine)
session = DBsession()
Base = declarative_base()
class Student(Base):
__tablename__ = 'student'
id = Column(Integer, primary_key=True)
name = Column(String(100))
age = Column(Integer)
address = Column(String(100))
student1 = Student(id=1001, name='ling', age=25, address="beijing")
student2 = Student(id=1002, name='molin', age=18, address="jiangxi")
student3 = Student(id=1003, name='karl', age=16, address="suzhou")
session.add_all([student1, student2, student3])
session.commit()
session.close()
查询是这个里面最为复杂,最为繁琐的一个步骤。 通过Session的query()方法创建一个查询对象。这个函数的参数数量是可变的,参数可以是任何类或者是类的描述的集合。下面来看一个例子:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/5/11 21:49
# @Author : Feng Xiaoqing
# @File : search.py
# @Function: -----------
from sqlalchemy import Column
from sqlalchemy import Integer
from sqlalchemy import String
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
Base = declarative_base()
class Student(Base):
__tablename__ = 'student'
id = Column(Integer, primary_key=True)
name = Column(String(50))
age = Column(Integer)
address = Column(String(100))
engine = create_engine('mysql+pymysql://fxq:123456@192.168.100.101/sqlalchemy')
DBSession = sessionmaker(bind=engine)
session = DBSession()
my_stdent = session.query(Student).filter_by(name="fengxiaoqing2").first()
print(my_stdent)
此时我们看到的输出结果是这样的:
<__main__.Student object at 0x032745F0>
前面我们在赋值的时候,我们可以通过实例化一个对象,然后直接映射到数据库中,那我们在查询出来的数据sqlalchemy直接给映射成一个对象了(或者是每个元素为这种对象的列表),对象和我们创建表时候的class是一致的,我们就也可以直接通过对象的属性就可以直接调用就可以了。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/5/11 21:49
# @Author : Feng Xiaoqing
# @File : search.py
# @Function: -----------
from sqlalchemy import Column
from sqlalchemy import Integer
from sqlalchemy import String
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
Base = declarative_base()
class Student(Base):
__tablename__ = 'student'
id = Column(Integer, primary_key=True)
name = Column(String(50))
age = Column(Integer)
address = Column(String(100))
engine = create_engine('mysql+pymysql://fxq:123456@192.168.100.101/sqlalchemy')
DBSession = sessionmaker(bind=engine)
session = DBSession()
my_stdent = session.query(Student).filter_by(name="fengxiaoqing2").first()
print(my_stdent.id,my_stdent.name,my_stdent.age,my_stdent.address)
结果:
1000311 fengxiaoqing2 182 chengde
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/5/11 21:49
# @Author : Feng Xiaoqing
# @File : search.py
# @Function: -----------
from sqlalchemy import Column
from sqlalchemy import Integer
from sqlalchemy import String
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
Base = declarative_base()
class Student(Base):
__tablename__ = 'student'
id = Column(Integer, primary_key=True)
name = Column(String(50))
age = Column(Integer)
address = Column(String(100))
engine = create_engine('mysql+pymysql://fxq:123456@192.168.100.101/sqlalchemy')
DBSession = sessionmaker(bind=engine)
session = DBSession()
my_stdent = session.query(Student).filter(Student.name.like("%feng%"))
print(my_stdent)
结果:
SELECT student.id AS student_id, student.name AS student_name, student.age AS student_age, student.address AS student_address
FROM student
WHERE student.name LIKE %s
根据结果,我们可以看出来 filter_by最后的结果就是一个sql语句,我们排错的时候就可以通过这个来排查我们sql是否正确。 以下的这些过滤操作都可以在filter函数中使用:
equals:
query(Student).filter(Student.id == 10001)
not equals:
query(Student).filter(Student.id != 100)
LIKE:
query(Student).filter(Student.name.like(“%feng%”))
IN:
query(Student).filter(Student.name.in_(['feng', 'xiao', 'qing']))
not in
query(Student).filter(~Student.name.in_(['feng', 'xiao', 'qing']))
AND:
from sqlalchemy import and_
query(Student).filter(and_(Student.name == 'fengxiaoqing', Student.id ==10001))
或者
query(Student).filter(Student.name == 'fengxiaoqing').filter(Student.address == 'chengde')
OR:
from sqlalchemy import or_
query.filter(or_(Student.name == 'fengxiaoqing', Student.age ==18))
all() 返回一个列表
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/5/11 21:49
# @Author : Feng Xiaoqing
# @File : search.py
# @Function: -----------
from sqlalchemy import Column
from sqlalchemy import Integer
from sqlalchemy import String
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
Base = declarative_base()
class Student(Base):
__tablename__ = 'student'
id = Column(Integer, primary_key=True)
name = Column(String(50))
age = Column(Integer)
address = Column(String(100))
engine = create_engine('mysql+pymysql://fxq:123456@192.168.100.101/sqlalchemy')
DBSession = sessionmaker(bind=engine)
session = DBSession()
my_stdent = session.query(Student).filter(Student.name.like("%feng%")).all()
print(my_stdent)
结果:
[<__main__.Student object at 0x031405B0>, <__main__.Student object at 0x030FCA70>, <__main__.Student object at 0x031405F0>]
可以通过遍历列表来获取每个对象。 one() 返回且仅返回一个查询结果。当结果的数量不足一个或者多于一个时会报错。 把上面的all改成one就报错了。 first() 返回至多一个结果,而且以单项形式,而不是只有一个元素的tuple形式返回这个结果.
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/5/11 21:49
# @Author : Feng Xiaoqing
# @File : search.py
# @Function: -----------
from sqlalchemy import Column
from sqlalchemy import Integer
from sqlalchemy import String
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
Base = declarative_base()
class Student(Base):
__tablename__ = 'student'
id = Column(Integer, primary_key=True)
name = Column(String(50))
age = Column(Integer)
address = Column(String(100))
engine = create_engine('mysql+pymysql://fxq:123456@192.168.100.101/sqlalchemy')
DBSession = sessionmaker(bind=engine)
session = DBSession()
my_stdent = session.query(Student).filter(Student.name.like("%feng%")).first()
print(my_stdent)
结果:
<__main__.Student object at 0x030A3610>
Filter: 可以像写 sql 的 where 条件那样写 > < 等条件,但引用列名时,需要通过 类名.属性名 的方式。 filter_by: 可以使用 python 的正常参数传递方法传递条件,指定列名时,不需要额外指定类名。,参数名对应名类中的属性名,但似乎不能使用 > < 等条件。
当使用filter的时候条件之间是使用“==",fitler_by使用的是"="。
user1 = session.query(User).filter_by(id=1).first()
user1 = session.query(User).filter(User.id==1).first()
filter不支持组合查询,只能连续调用filter来变相实现。 而filter_by的参数是**kwargs,直接支持组合查询。 比如:
q = sess.query(IS).filter(IS.node == node and IS.password == password).all()
更新就是查出来,直接更改就可以了
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/5/11 22:27
# @Author : Feng Xiaoqing
# @File : update.py
# @Function: -----------
from sqlalchemy import Column
from sqlalchemy import Integer
from sqlalchemy import String
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
Base = declarative_base()
class Student(Base):
__tablename__ = 'student'
id = Column(Integer, primary_key=True)
name = Column(String(50))
age = Column(Integer)
address = Column(String(100))
engine = create_engine('mysql+pymysql://fxq:123456@192.168.100.101/sqlalchemy')
DBSession = sessionmaker(bind=engine)
session = DBSession()
my_stdent = session.query(Student).filter(Student.id == 1002).first()
my_stdent.name = "fengxiaoqing"
my_stdent.address = "chengde"
session.commit()
student1 = session.query(Student).filter(Student.id == 1002).first()
print(student1.name, student1.address)
结果:
MariaDB [sqlalchemy]> select * from student;
+---------+---------------+------+---------+
| id | name | age | address |
+---------+---------------+------+---------+
| 1002 | molin | 18 | jiangxi |
| 1003 | karl | 16 | suzhou |
| 100011 | fengxiaoqing | 18 | chengde |
| 100021 | fengxiaqing1 | 181 | chengde |
| 1000111 | fengxiaoqing | 18 | chengde |
| 1000211 | fengxiaqing1 | 181 | chengde |
| 1000311 | fengxiaoqing2 | 182 | chengde |
+---------+---------------+------+---------+
7 rows in set (0.00 sec)
MariaDB [sqlalchemy]> select * from student;
+---------+---------------+------+---------+
| id | name | age | address |
+---------+---------------+------+---------+
| 1002 | fengxiaoqing | 18 | chengde |
| 1003 | karl | 16 | suzhou |
| 100011 | fengxiaoqing | 18 | chengde |
| 100021 | fengxiaqing1 | 181 | chengde |
| 1000111 | fengxiaoqing | 18 | chengde |
| 1000211 | fengxiaqing1 | 181 | chengde |
| 1000311 | fengxiaoqing2 | 182 | chengde |
+---------+---------------+------+---------+
7 rows in set (0.00 sec)
MariaDB [sqlalchemy]>
删除其实也是跟查询相关的,直接查出来,调用delete()方法直接就可以删除掉。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/5/11 22:27
# @Author : Feng Xiaoqing
# @File : update.py
# @Function: -----------
from sqlalchemy import Column
from sqlalchemy import Integer
from sqlalchemy import String
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
Base = declarative_base()
class Student(Base):
__tablename__ = 'student'
id = Column(Integer, primary_key=True)
name = Column(String(50))
age = Column(Integer)
address = Column(String(100))
engine = create_engine('mysql+pymysql://fxq:123456@192.168.100.101/sqlalchemy')
DBSession = sessionmaker(bind=engine)
session = DBSession()
session.query(Student).filter(Student.id == 1001).delete()
session.commit()
session.close()
#######统计count()
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/5/11 22:27
# @Author : Feng Xiaoqing
# @File : update.py
# @Function: -----------
from sqlalchemy import Column
from sqlalchemy import Integer
from sqlalchemy import String
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
Base = declarative_base()
class Student(Base):
__tablename__ = 'student'
id = Column(Integer, primary_key=True)
name = Column(String(50))
age = Column(Integer)
address = Column(String(100))
engine = create_engine('mysql+pymysql://fxq:123456@192.168.100.101/sqlalchemy')
DBSession = sessionmaker(bind=engine)
session = DBSession()
print(session.query(Student).filter(Student.name.like("%feng%")).count())
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/5/11 22:27
# @Author : Feng Xiaoqing
# @File : update.py
# @Function: -----------
from sqlalchemy import Column
from sqlalchemy import Integer
from sqlalchemy import String
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
Base = declarative_base()
class Student(Base):
__tablename__ = 'student'
id = Column(Integer, primary_key=True)
name = Column(String(50))
age = Column(Integer)
address = Column(String(100))
engine = create_engine('mysql+pymysql://fxq:123456@192.168.100.101/sqlalchemy')
DBSession = sessionmaker(bind=engine)
session = DBSession()
std_group_by = session.query(Student).group_by(Student.age)
print(std_group_by)
结果的sql语句如下:
SELECT student.id AS student_id, student.name AS student_name, student.age AS student_age, student.address AS student_address
FROM student GROUP BY student.age
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/5/11 22:27
# @Author : Feng Xiaoqing
# @File : update.py
# @Function: -----------
from sqlalchemy import Column
from sqlalchemy import Integer
from sqlalchemy import String
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
Base = declarative_base()
class Student(Base):
__tablename__ = 'student'
id = Column(Integer, primary_key=True)
name = Column(String(50))
age = Column(Integer)
address = Column(String(100))
engine = create_engine('mysql+pymysql://fxq:123456@192.168.100.101/sqlalchemy')
DBSession = sessionmaker(bind=engine)
session = DBSession()
std_ord_desc = session.query(Student).filter(Student.name.like("%feng%")).order_by(Student.id.desc()).all()
for i in std_ord_desc:
print(i.id)
1000311
1000211
1000111
100021
100011
1002
#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""
MongoDB存储
在这里我们来看一下Python3下MongoDB的存储操作,在本节开始之前请确保你已经安装好了MongoDB并启动了其服务,另外安装好了Python
的PyMongo库。
连接MongoDB
连接MongoDB我们需要使用PyMongo库里面的MongoClient,一般来说传入MongoDB的IP及端口即可,第一个参数为地址host,
第二个参数为端口port,端口如果不传默认是27017。
"""
import pymongo
client = pymongo.MongoClient(host='localhost', port=27017)
"""
这样我们就可以创建一个MongoDB的连接对象了。另外MongoClient的第一个参数host还可以直接传MongoDB的连接字符串,以mongodb开头,
例如:client = MongoClient('mongodb://localhost:27017/')可以达到同样的连接效果。
"""
# 指定数据库
# MongoDB中还分为一个个数据库,我们接下来的一步就是指定要操作哪个数据库,在这里我以test数据库为例进行说明,所以下一步我们
# 需要在程序中指定要使用的数据库。
db = client.test
# 调用client的test属性即可返回test数据库,当然也可以这样来指定:
# db = client['test']
# 两种方式是等价的。
# 指定集合
# MongoDB的每个数据库又包含了许多集合Collection,也就类似与关系型数据库中的表,下一步我们需要指定要操作的集合,
# 在这里我们指定一个集合名称为students,学生集合。还是和指定数据库类似,指定集合也有两种方式。
collection = db.students
# collection = db['students']
# 插入数据,接下来我们便可以进行数据插入了,对于students这个Collection,我们新建一条学生数据,以字典的形式表示:
student = {
'id': '20170101',
'name': 'Jordan',
'age': 20,
'gender': 'male'
}
# 在这里我们指定了学生的学号、姓名、年龄和性别,然后接下来直接调用collection的insert()方法即可插入数据。
result = collection.insert(student)
print(result)
# 在MongoDB中,每条数据其实都有一个_id属性来唯一标识,如果没有显式指明_id,MongoDB会自动产生一个ObjectId类型的_id属性。
# insert()方法会在执行后返回的_id值。
# 运行结果:
# 5932a68615c2606814c91f3d
# 当然我们也可以同时插入多条数据,只需要以列表形式传递即可,示例如下:
student1 = {
'id': '20170101',
'name': 'Jordan',
'age': 20,
'gender': 'male'
}
student2 = {
'id': '20170202',
'name': 'Mike',
'age': 21,
'gender': 'male'
}
result = collection.insert([student1, student2])
print(result)
# 返回的结果是对应的_id的集合,运行结果:
# [ObjectId('5932a80115c2606a59e8a048'), ObjectId('5932a80115c2606a59e8a049')]
# 实际上在PyMongo 3.X版本中,insert()方法官方已经不推荐使用了,当然继续使用也没有什么问题,
# 官方推荐使用insert_one()和insert_many()方法将插入单条和多条记录分开。
student = {
'id': '20170101',
'name': 'Jordan',
'age': 20,
'gender': 'male'
}
result = collection.insert_one(student)
print(result)
print(result.inserted_id)
# 运行结果:
# <pymongo.results.InsertOneResult object at 0x10d68b558>
# 5932ab0f15c2606f0c1cf6c5
# 返回结果和insert()方法不同,这次返回的是InsertOneResult对象,我们可以调用其inserted_id属性获取_id。
# 对于insert_many()方法,我们可以将数据以列表形式传递即可,示例如下:
student1 = {
'id': '20170101',
'name': 'Jordan',
'age': 20,
'gender': 'male'
}
student2 = {
'id': '20170202',
'name': 'Mike',
'age': 21,
'gender': 'male'
}
result = collection.insert_many([student1, student2])
print(result)
print(result.inserted_ids)
# insert_many()方法返回的类型是InsertManyResult,调用inserted_ids属性可以获取插入数据的_id列表,运行结果:
# <pymongo.results.InsertManyResult object at 0x101dea558>
# [ObjectId('5932abf415c2607083d3b2ac'), ObjectId('5932abf415c2607083d3b2ad')]
# 查询,插入数据后我们可以利用find_one()或find()方法进行查询,find_one()查询得到是单个结果,find()则返回多个结果。
result = collection.find_one({'name': 'Mike'})
print(type(result))
print(result)
# 在这里我们查询name为Mike的数据,它的返回结果是字典类型,运行结果:
# <class'dict'>
# {'_id': ObjectId('5932a80115c2606a59e8a049'), 'id': '20170202', 'name': 'Mike', 'age': 21, 'gender': 'male'}
# 可以发现它多了一个_id属性,这就是MongoDB在插入的过程中自动添加的。
# 我们也可以直接根据ObjectId来查询,这里需要使用bson库里面的ObjectId。
from bson.objectid import ObjectId
result = collection.find_one({'_id': ObjectId('593278c115c2602667ec6bae')})
print(result)
# 其查询结果依然是字典类型,运行结果:
# {' ObjectId('593278c115c2602667ec6bae'), 'id': '20170101', 'name': 'Jordan', 'age': 20, 'gender': 'male'}
# 当然如果查询_id':结果不存在则会返回None。
# 对于多条数据的查询,我们可以使用find()方法,例如在这里查找年龄为20的数据,示例如下:
results = collection.find({'age': 20})
print(results)
for result in results:
print(result)
# 运行结果:
# <pymongo.cursor.Cursor object at 0x1032d5128>
# {'_id': ObjectId('593278c115c2602667ec6bae'), 'id': '20170101', 'name': 'Jordan', 'age': 20, 'gender': 'male'}
# {'_id': ObjectId('593278c815c2602678bb2b8d'), 'id': '20170102', 'name': 'Kevin', 'age': 20, 'gender': 'male'}
# {'_id': ObjectId('593278d815c260269d7645a8'), 'id': '20170103', 'name': 'Harden', 'age': 20, 'gender': 'male'}
# 返回结果是Cursor类型,相当于一个生成器,我们需要遍历取到所有的结果,每一个结果都是字典类型。
# 如果要查询年龄大于20的数据,则写法如下:
results = collection.find({'age': {'$gt': 20}})
# 在这里查询的条件键值已经不是单纯的数字了,而是一个字典,其键名为比较符号$gt,意思是大于,键值为20,这样便可以查询出所有
# 年龄大于20的数据。
# 在这里将比较符号归纳如下表:
"""
符号含义示例
$lt小于{'age': {'$lt': 20}}
$gt大于{'age': {'$gt': 20}}
$lte小于等于{'age': {'$lte': 20}}
$gte大于等于{'age': {'$gte': 20}}
$ne不等于{'age': {'$ne': 20}}
$in在范围内{'age': {'$in': [20, 23]}}
$nin不在范围内{'age': {'$nin': [20, 23]}}
"""
# 另外还可以进行正则匹配查询,例如查询名字以M开头的学生数据,示例如下:
results = collection.find({'name': {'$regex': '^M.*'}})
# 在这里使用了$regex来指定正则匹配,^M.*代表以M开头的正则表达式,这样就可以查询所有符合该正则的结果。
# 在这里将一些功能符号再归类如下:
"""
符号含义示例示例含义
$regex匹配正则{'name': {'$regex': '^M.*'}}name以M开头
$exists属性是否存在{'name': {'$exists': True}}name属性存在
$type类型判断{'age': {'$type': 'int'}}age的类型为int
$mod数字模操作{'age': {'$mod': [5, 0]}}年龄模5余0
$text文本查询{'$text': {'$search': 'Mike'}}text类型的属性中包含Mike字符串
$where高级条件查询{'$where': 'obj.fans_count == obj.follows_count'}自身粉丝数等于关注数
"""
# 这些操作的更详细用法在可以在MongoDB官方文档找到:
# https://docs.mongodb.com/manual/reference/operator/query/
# 计数
# 要统计查询结果有多少条数据,可以调用count()方法,如统计所有数据条数:
count = collection.find().count()
print(count)
# 或者统计符合某个条件的数据:
count = collection.find({'age': 20}).count()
print(count)
# 排序
# 可以调用sort方法,传入排序的字段及升降序标志即可,示例如下:
results = collection.find().sort('name', pymongo.ASCENDING)
print([result['name'] for result in results])
# 运行结果:
# ['Harden', 'Jordan', 'Kevin', 'Mark', 'Mike']
# 偏移,可能想只取某几个元素,在这里可以利用skip()方法偏移几个位置,比如偏移2,就忽略前2个元素,得到第三个及以后的元素。
results = collection.find().sort('name', pymongo.ASCENDING).skip(2)
print([result['name'] for result in results])
# 运行结果:
# ['Kevin', 'Mark', 'Mike']
# 另外还可以用limit()方法指定要取的结果个数,示例如下:
results = collection.find().sort('name', pymongo.ASCENDING).skip(2).limit(2)
print([result['name'] for result in results])
# 运行结果:
# ['Kevin', 'Mark']
# 如果不加limit()原本会返回三个结果,加了限制之后,会截取2个结果返回。
# 值得注意的是,在数据库数量非常庞大的时候,如千万、亿级别,最好不要使用大的偏移量来查询数据,很可能会导致内存溢出,
# 可以使用类似find({'_id': {'$gt': ObjectId('593278c815c2602678bb2b8d')}}) 这样的方法来查询,记录好上次查询的_id。
# 更新
# 对于数据更新可以使用update()方法,指定更新的条件和更新后的数据即可,例如:
condition = {'name': 'Kevin'}
student = collection.find_one(condition)
student['age'] = 25
result = collection.update(condition, student)
print(result)
# 在这里我们将name为Kevin的数据的年龄进行更新,首先指定查询条件,然后将数据查询出来,修改年龄,
# 之后调用update方法将原条件和修改后的数据传入,即可完成数据的更新。
# 运行结果:
# {'ok': 1, 'nModified': 1, 'n': 1, 'updatedExisting': True}
# 返回结果是字典形式,ok即代表执行成功,nModified代表影响的数据条数。
# 另外update()方法其实也是官方不推荐使用的方法,在这里也分了update_one()方法和update_many()方法,用法更加严格,
# 第二个参数需要使用$类型操作符作为字典的键名,我们用示例感受一下。
condition = {'name': 'Kevin'}
student = collection.find_one(condition)
student['age'] = 26
result = collection.update_one(condition, {'$set': student})
print(result)
print(result.matched_count, result.modified_count)
# 在这里调用了update_one方法,第二个参数不能再直接传入修改后的字典,而是需要使用{'$set': student}这样的形式,
# 其返回结果是UpdateResult类型,然后调用matched_count和modified_count属性分别可以获得匹配的数据条数和影响的数据条数。
# 运行结果:
#
# <pymongo.results.UpdateResult object at 0x10d17b678>
# 1 0
# 我们再看一个例子:
condition = {'age': {'$gt': 20}}
result = collection.update_one(condition, {'$inc': {'age': 1}})
print(result)
print(result.matched_count, result.modified_count)
# 在这里我们指定查询条件为年龄大于20,然后更新条件为{'$inc': {'age': 1}},执行之后会讲第一条符合条件的数据年龄加1。
# 运行结果:
#
# <pymongo.results.UpdateResult object at 0x10b8874c8>
# 1 1
# 可以看到匹配条数为1条,影响条数也为1条。
# 如果调用update_many()方法,则会将所有符合条件的数据都更新,示例如下:
condition = {'age': {'$gt': 20}}
result = collection.update_many(condition, {'$inc': {'age': 1}})
print(result)
print(result.matched_count, result.modified_count)
# 这时候匹配条数就不再为1条了,运行结果如下:
#
# <pymongo.results.UpdateResult object at 0x10c6384c8>
# 3 3
# 可以看到这时所有匹配到的数据都会被更新。
# 删除
# 删除操作比较简单,直接调用remove()方法指定删除的条件即可,符合条件的所有数据均会被删除,示例如下:
result = collection.remove({'name': 'Kevin'})
print(result)
# 运行结果:
#
# {'ok': 1, 'n': 1}
# 另外依然存在两个新的推荐方法,delete_one()和delete_many()方法,示例如下:
result = collection.delete_one({'name': 'Kevin'})
print(result)
print(result.deleted_count)
result = collection.delete_many({'age': {'$lt': 25}})
print(result.deleted_count)
# 运行结果:
# <pymongo.results.DeleteResult object at 0x10e6ba4c8>
# 1
# 4
# delete_one()即删除第一条符合条件的数据,delete_many()即删除所有符合条件的数据,返回结果是DeleteResult类型,
# 可以调用deleted_count属性获取删除的数据条数。
# 更多
# 另外PyMongo还提供了一些组合方法,如find_one_and_delete()、find_one_and_replace()、find_one_and_update(),
# 就是查找后删除、替换、更新操作,用法与上述方法基本一致。
# 另外还可以对索引进行操作,如create_index()、create_indexes()、drop_index()等。
# 详细用法可以参见官方文档:http://api.mongodb.com/python/current/api/pymongo/collection.html
# 另外还有对数据库、集合本身以及其他的一些操作,在这不再一一讲解,可以参见
# 官方文档:http://api.mongodb.com/python/current/api/pymongo/