Multi-byte word problem with TrimStrings Middleware. #40577
Comments
|
Ping @allowing |
|
Hey @nshiro , I can't replicate this issue... I used an expanded version from your code: <?php
$str = 'あいうえおかきくけこさしすせそたちつてとなにぬねのはひふへほまみむめもやゆよらをわがぎぐげござしずぜぞだぢづでどばびぶべぼぱぴぷぺぽ'
. 'アイウエオカキクケコサシスセソタチツテトナニヌネノハヒフヘホマミムメモヤユヨラヲワガギグゲゴザジズゼゾダヂヅデドバビブベボパピプペポ';
// split a string into each words. (This part is not related with the problem)
$words = preg_split('//u', $str);
// Maybe try adding this to your code sample
echo '<meta charset="utf-8">', PHP_EOL;
echo '<table border="1">', PHP_EOL;
foreach ($words as $word) {
echo '<tr>', PHP_EOL;
// raw word
echo '<td>', $word, '</td>', PHP_EOL;
echo '<td>', bin2hex($word), '</td>', PHP_EOL;
// raw trim
echo '<td>', trim($word), '</td>', PHP_EOL;
echo '<td>', bin2hex(trim($word)), '</td>', PHP_EOL;
// trim with just an space
echo '<td>', trim($word, " "), '</td>', PHP_EOL;
echo '<td>', bin2hex(trim($word, " ")), '</td>', PHP_EOL;
// trim as PR #38117
echo '<td>', trim($word, " \t\n\r\0\x0B"), '</td>', PHP_EOL;
echo '<td>', bin2hex(trim($word, " \t\n\r\0\x0B")), '</td>', PHP_EOL;
// trim as I use in my projects
// I add the \x08 to the default parameter as described into PHP docs
// https://www.php.net/manual/en/function.trim
echo '<td>', trim($word, " \n\r\t\v\x00\x08"), '</td>', PHP_EOL;
echo '<td>', bin2hex(trim($word, " \n\r\t\v\x00\x08")), '</td>', PHP_EOL;
echo '</tr>', PHP_EOL;
}
echo '</table>', PHP_EOL;I got these results on firefox:
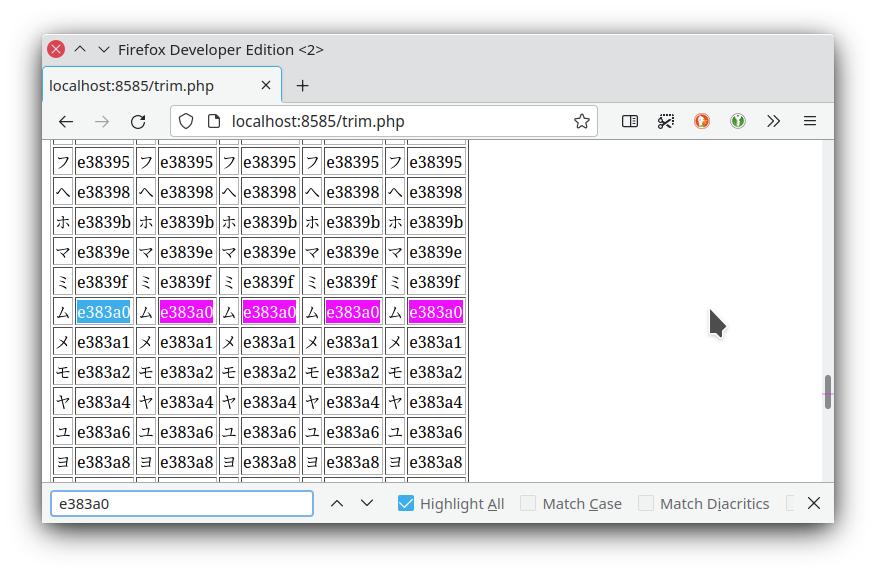
And these results on chromium:
Note I added the Also check if your code editor is saving the file with UTF-8 encoding:
|




|
@rodrigopedra Looks like NBSP is replaced with the normal space in the github website. Please check the below. The problem still happens. I used your script (not all).
I also added another version that can be reproduced quickly. Please see the first comment. |

|
@nshiro thanks for the heads up, maybe when I copied and pasted the code, either my browser, OS or editor converted the NBSP to a regular space. So I was looking into my recent projects and I actually use a newer approach to deal with NBSP. I use <?php
$str = 'あいうえおかきくけこさしすせそたちつてとなにぬねのはひふへほまみむめもやゆよらをわがぎぐげござしずぜぞだぢづでどばびぶべぼぱぴぷぺぽ'
. 'アイウエオカキクケコサシスセソタチツテトナニヌネノハヒフヘホマミムメモヤユヨラヲワガギグゲゴザジズゼゾダヂヅデドバビブベボパピプペポ';
// split a string into each words. (This part is not related with the problem)
$words = preg_split('//u', $str);
// adding two more test characters
$words[] = ' だ '; // 2x NBSP before, 2x regular spaces after
$words[] = ' だ '; // 2x regular spaces before, 2x NBSP after
$words[] = ' だ '; // NBSP + regular space before and after
$words[] = ' ム '; // 2x NBSP before, 2x regular spaces after
$words[] = ' ム '; // 2x regular spaces before, 2x NBSP after
$words[] = ' ム '; // NBSP + regular space before and after
// Maybe try adding this to your code sample
echo '<meta charset="utf-8">', PHP_EOL;
echo '<table border="1">', PHP_EOL;
foreach ($words as $word) {
echo '<tr>', PHP_EOL;
// raw word
echo '<td>', $word, '</td>', PHP_EOL;
echo '<td>', bin2hex($word), '</td>', PHP_EOL;
// raw trim
echo '<td>', trim($word), '</td>', PHP_EOL;
echo '<td>', bin2hex(trim($word)), '</td>', PHP_EOL;
// trim with just an space
echo '<td>', trim($word, " "), '</td>', PHP_EOL;
echo '<td>', bin2hex(trim($word, " ")), '</td>', PHP_EOL;
// trim as PR #38117
echo '<td>', trim($word, " \t\n\r\0\x0B"), '</td>', PHP_EOL;
echo '<td>', bin2hex(trim($word, " \t\n\r\0\x0B")), '</td>', PHP_EOL;
// trim as I **used** in my projects
// I add the \x08 to the default parameter as described into PHP docs
// https://www.php.net/manual/en/function.trim
echo '<td>', trim($word, " \n\r\t\v\x00\x08"), '</td>', PHP_EOL;
echo '<td>', bin2hex(trim($word, " \n\r\t\v\x00\x08")), '</td>', PHP_EOL;
// transform I now use in my projects
$value = preg_replace('~^\s+|\s+$~iu', '', $word);
echo '<td>', $value, '</td>', PHP_EOL;
echo '<td>', bin2hex($value), '</td>', PHP_EOL;
echo '</tr>', PHP_EOL;
}
echo '</table>', PHP_EOL;You can see I added some additional cases to test it better, and the results are these:
I sent PR #40600 to modify the |

|
@rodrigopedra Thank you for your support. |
|
ping @nshiro and @foremtehan Could you take a look at my comment on PR #40600 about supporting the word-joiner? I didn't want to spam a closed PR to avoid annoying the maintainers. |
Description:
In 9.x, the trimString middleware removes NBSP. #38117
This is causing the problem. When dealing with multi-byte words (in my case Japanese), we have some problems. A few words are garbled.
When I put
だorムin the end of text, those words will be garbled.Steps to Reproduce (quick version)
Add below to the welcome.blade.php.
Access the url.
http://localhost/?name=やま
http://localhost/?name=やまだ
(Replace
localhostto your domain. やま or やまだ may be encoded in the URL field of your browser.)You can see やま is ok. But if you add だ, it's not working.
Steps To Reproduce: (Original version)
[Caution]
You cannot just copy and paste the below. NBSP is replaced with the normal space.
Please use NBSP as the second argument of the trim function.
You can copy NBSP from the real source code. (Please don't copy from the github website.)
I guess the reason is that
だis likee381a0andムis likee383a0and the NBSP is like U+00A0 in Unicode.So If I put
だin the end of text, the last part of worda0is trimmed and the word is garbled.We (Japanese) also use chinese characters which I didn't looked into.
Thank you for reading.
The text was updated successfully, but these errors were encountered: