Cleaner EBNF grammar #155
Comments
|
I like these versions: rule:
rule1
rule2 rule
: rule1
| rule2The first one is cleaner and the positions of the alternatives are easy to rearrange. But I'm worried that it's not clear enough that each line is a different option. The second one is a little bit weird, but it might work. I'll have to give it some thought, to make sure it won't collide with other concepts. |
|
Yeah, I do agree, the first one is the "optimal" one from the whole set of EBNF grammars (as it doesn't contain redundant/verbose elements, it's the most pythonic one :)) Also, did you look this repo, it contains a lot of ebnf grammars ready to go... it'd be cool if they could be used out of the box with lark, or maybe converting them automatically to lark... Guess adding more additional arguments to the Lark constructor to specify which type of ebnf you're dealing with would be ugly. I mean, I guess this is some sort of tradeoff... usually you want your functions/constructor/ui/gui to be as minimal as possible so they become clear as water for users, quoting:
Anyway, just give it some thoughts, I like to bring to the table new use-cases or improvements about usability ;) B. NS: When I said "converting them" automatically I meant maybe creating some sort of script (without modifying the lark core so the code doesn't become more complex without any real reason) |
Yes, that's a good idea. I'd say converting them is the way to go. However, Not all of them can be converted; many of them require code that resides in the grammar to work correctly. The conversion script can be added to lark.tools. |
|
I'm concerned that the could be understood as an "empty" Right Hand Side but I think we should have some way of being explicit that the right hand side matches "nothing" or no input. Since "[someterminal]" means that the someterminal is optional, perhaps if we use the syntax [] to mean an optional "empty". |
|
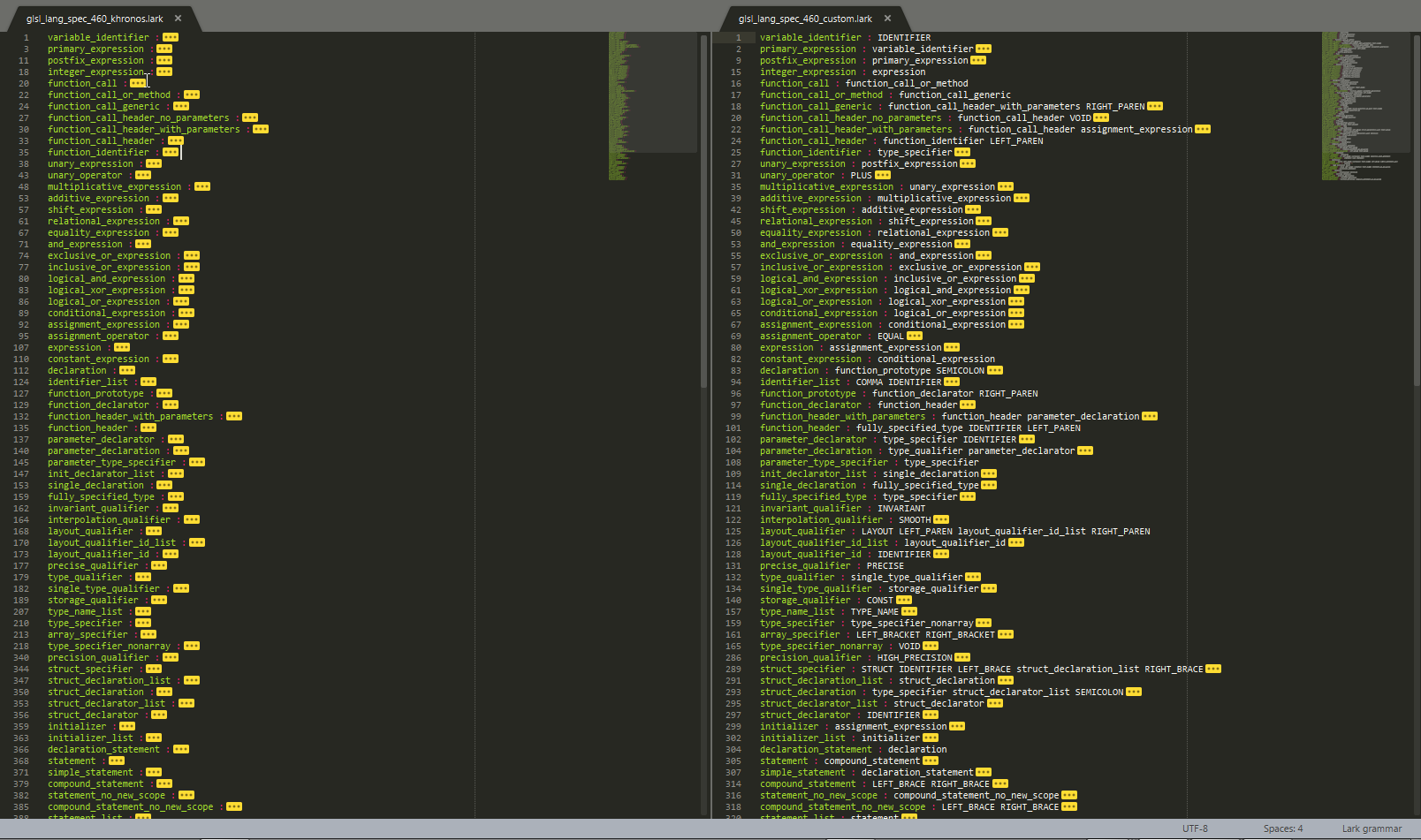
Guys, just for the sake of making my point clearer (sometimes the best way to prove something is by presenting visual samples) I want you to take a look to the below comparison between the syntax used here and the lark one: GLSLangSpec.4.60.original_ebnf
GLSLangSpec.4.60.lark_ebnf
Now, you tell me, which one is easier to understand and work with (improving, tweaking, ...)? You can also see a ST side by side comparison here
@erezsh : Well, my background is a lot of years coding on c/c++ and when I started using python many years ago I thought I wouldn't survive without braces... nowadays is the other way around, each time i see redundant tokens like braces I become sad ;) @whitten : Just for the record, I think that particular syntax is the worst from the whole set of proposals (worst=less elegant and less cleaner) NS: I haven't checked correctness (just a fast adaptation), so not sure if you'd transform this: like: nor this: like: guess that's just wrong syntax... |
{kind=link}
|
Ideally, you'd be able to express the same rule on different ways, for instance:
The idea here is you're giving the user the freedom to create hacky small compact grammars if he wants to do so or... more clean ones (even if a little bit more verbose one) |
|
Yep, that's what I was planning. |
|
I suggest one more way how to write multiple right-sides of the rule. The main reason for such format (currently, it is rejected because of the duplicity of the left-side) is that you can easilly add comments with explanation for every line. I already have a (naive) preprocessor for that. |
|
@marxsk Line comments are already possible >>> from lark import Lark
>>> p=Lark("""
... // Comment
... start: "a"
... // Another comment
... | "b"
... // And C
... | "c"
... """)
>>> |
|
Could the lark grammar be reimplemented in Lark? |
|
@gideongrinberg It kinda is. We have a mirror that should match exactly what the actual parser accepts: lark.lark, but that is not what is being used internally. That is still being parsed with the lalr parser, but the rules are encoded here |
|
I just had a crazy thought. What if Lark accepted a |
|
@erezsh That actually sounds like a good idea. I would suggest that the argument takes a |
|
@MegaIng It would be interesting to try! Though seems like it's just a single function, So passing It will require a bit of work, because currently there is a deviation of structure between |
We need standards. That's probably a bad idea in case I wanted to read other's code BUT it could be a good idea because it allows people who don't know Lark's grammar, but instead something like ANTLR, to be able to write a grammar. We could have a libraries of possible default grammar-grammar-grammars. |
|
@ThatXliner Well, if they produce a Tree that corresponds to lark.lark, I imagine the reconstructor should be able to automatically generate a working lark grammar. In theory, at least. But I agree that it might become confusing, if suddently everyone used their own syntax. |
Since "[someterminal]" means that the someterminal is optional, perhaps if we use the syntax [] to mean an optional "empty". I also think that at times it is easier to write the grammar with rules where one of the alternatives is "empty". However, I would much prefer that common.lark declare an EMPTY terminal. It could even be managed as a special case when processing a grammar. (I am pretty sure that |
|
@brupelo Is actually implying parenthesis by using the line break. The above is actually. I can understand the thinking that following the rule declaration having the rest of the line empty means that the definition of the rule is an indented block. This is very YAML-like. Note: I really don't like the ANTLR Note: about notation, regardless of the multiline format used to define a rule I think it is imperative that the colon always be used to indicate the preceding string is either a rule or terminal. If it is true that currently having nothing on the line after a rule declaration is an error then allowing the format could be okay. I think that being explicit about what the alternatives are matches the YAML list construct where list item starts with "- " and in this case a rule alternative would start with '| ". If the above was added along with a predefined EMPTY terminal and documentation reflected the use of EMPTY when that is what you mean then having nothing after the colon on the line shouldn't be confusing. Now if Lark supported inline rule definitions (even more like YAML) I would not be happy. |
Would it be possible to modify the current ebnf grammar so instead the current
syntax where you're forced to have the first rule and colon after the rule name on
the same line:
you could have indented and clean blocks like this (fornmat used on glsl specs):
or maybe (not very clean one):
or:
or (inspired from Antlr4 ):
Rationale: That way the EBNF grammar will become much more readable and not only that, you'll be able to fold long grammars easily on your favourite text editor because the grammar now has proper indentation, example here.
Guess it's a matter to tweak a bit this file, even if you don't like the idea, could you explain how you'd do so?
Thanks.
The text was updated successfully, but these errors were encountered: