Learning pyspark and AWS through analyzing my Strava history with Apache Spark 1.6.1
- Bootstrap actions and configuration files that install
ipython notebookwithpysparkandpandason AWS EMR - A
StravaLoaderclass that creates a DataFrame from all my Strava activities stored in s3 (or locally) - An iPython Notebook that..
- Computes moving speed
- Filters tracking points at rest
- Identifies "activity blocks" by looking for pauses longer than 10 minutes between tracking points
- Flattens the dataset and saves tracking point dataset as parquet
- Aggregates data to activity block level and computes metrics like average speed, average heart rate and saves activity block dataset as parquet
- A Zeppelin Notebook for data exploration and visualization of the two data sets
See the notebook for details. The following illustrations are for road cycling activities.
#####Average heart rate (y) at different speeds in km/h (x) for three different athletes (not only me)
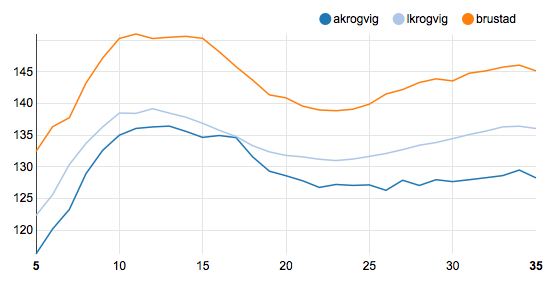
Looks like the toughest part of cycling is going up hill (lower speeds).
#####Average speed in km/h (y) versus total length in km (x) of activities for three athletes
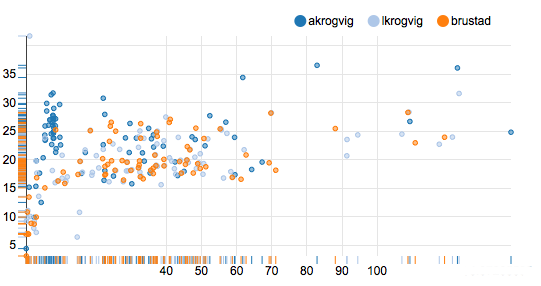
Looks like different athletes have different cycling habits.
Activities are stored in the following structure
- strava-activities
- athlete1
- [id]-[activity type].gpx
- athlete2
- [id]-[activity type].gpx
- ...
- athlete1
In a pyspark program:
from classes import StravaLoader
df = StravaLoader().get_dataset()
In a pyspark shell:
from classes import StravaLoader
df = StravaLoader(sc=sc, hiveContext=sqlContext).get_dataset()