This is our official implementation for the paper:
If you use the codes, please cite our paper . Thanks!
Multi-feedback pairwise ranking method via Adversarial training (AT-MPR) for recommender to enhance the robustness and overall performance in the event of rating pollution.
The code has been tested running under Python 3.6 The required packages are as follows:
-
TensorFlow 1.13
-
Numpy 1.14
-
Pandas 0.24
This command shows the effect of MPR by adding adversarial perturbation on MPR model for dataset ml-1m in epoch 500 (--adv_epoch). The first 500 epochs are MPR, followed by adversarial training MPR.
python AT-MPR.py --dataset ml-1m --adv_epoch 500 --epochs 1000 --eps 0.5 --reg_adv 1 --ckpt 1 --verbose 10 --beta 1 --sampling 'uniform' Some important arguments:
 |
 |
-
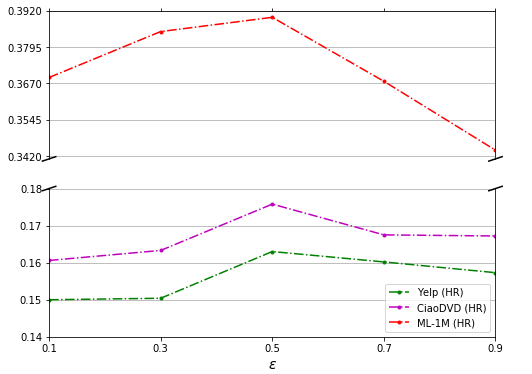
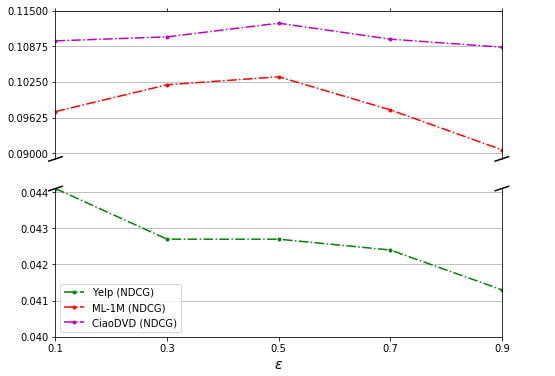
eps: Used to adjust the intensity of the confrontation, experiments show that the effect is best at0.5(see figure, above). -
beta: The proportion of implicit feedback in data is the best when1is realized. -
sampling: Provide two different sampling methodsnon-uniform,uniformamong whichuniformperforms best inMovieLens.
More Details:
Use python main.py -h to get more argument setting details.
-h, --help show this help message and exit
--path [PATH] Input data path.
--dataset [DATASET] Choose a dataset.
--verbose VERBOSE Evaluate per X epochs.
--epochs EPOCHS Number of epochs.
--adv_epochs The epoch # that starts adversarial training (before that are normal MPR training).
......
We provide three processed datasets: Yelp(yelp), MovieLens 1 Million (ml-1m) and Ciao (CiaoDVD) in Data
train.rating:
- Train file.
- Each Line is a training instance: userID, itemID, rating
test.rating:
- Test file.
- Each Line is a testing instance: userID, itemID, rating
Update: Jun 4, 2021